
- 1tomcat安装、部署JSPGOU项目、Tomcat多实例
- 2惠氏桥测量电阻_pt1000测量电路
- 3对 Python 代码使用的词语标记化器 tokenize,你懂了吗?【Python|标准库|tokenize】_python tokenize
- 4git-常用命令
- 5阿里通义灵码实测使用,强大,好用!_阿里灵码
- 6用knn算法对鸢尾花数据集进行分类
- 7模拟电路设计(10)--- 运算放大器简介_模拟集成电路中运放的内部结构图
- 8如何使用RxJava 2.x开发Android应用?_反应式编程实战:使用rxjava 2.x开发android应用
- 9人工智能基础部分15-自然语言处理中的数据处理上采样、下采样、负采样是什么?_文本 下采样的区别
- 10编译MOTR的时候,报错:error: cannot call member function ‘void std::basic_string<_CharT, _Traits, _Alloc>::_R_msda.ms_deform_attn_forward
大数据毕业设计hadoop+spark知识图谱音乐推荐系统 音乐评论情感分析 音乐爬虫可视化 音乐数据分析 大数据毕设 机器学习 深度学习 人工智能 计算机毕业设计
赞
踩
| 课题名称 | 基于Spark的音乐推荐系统的设计与实现 | ||||
| 学生姓名 | 专业班级 | 学号 | |||
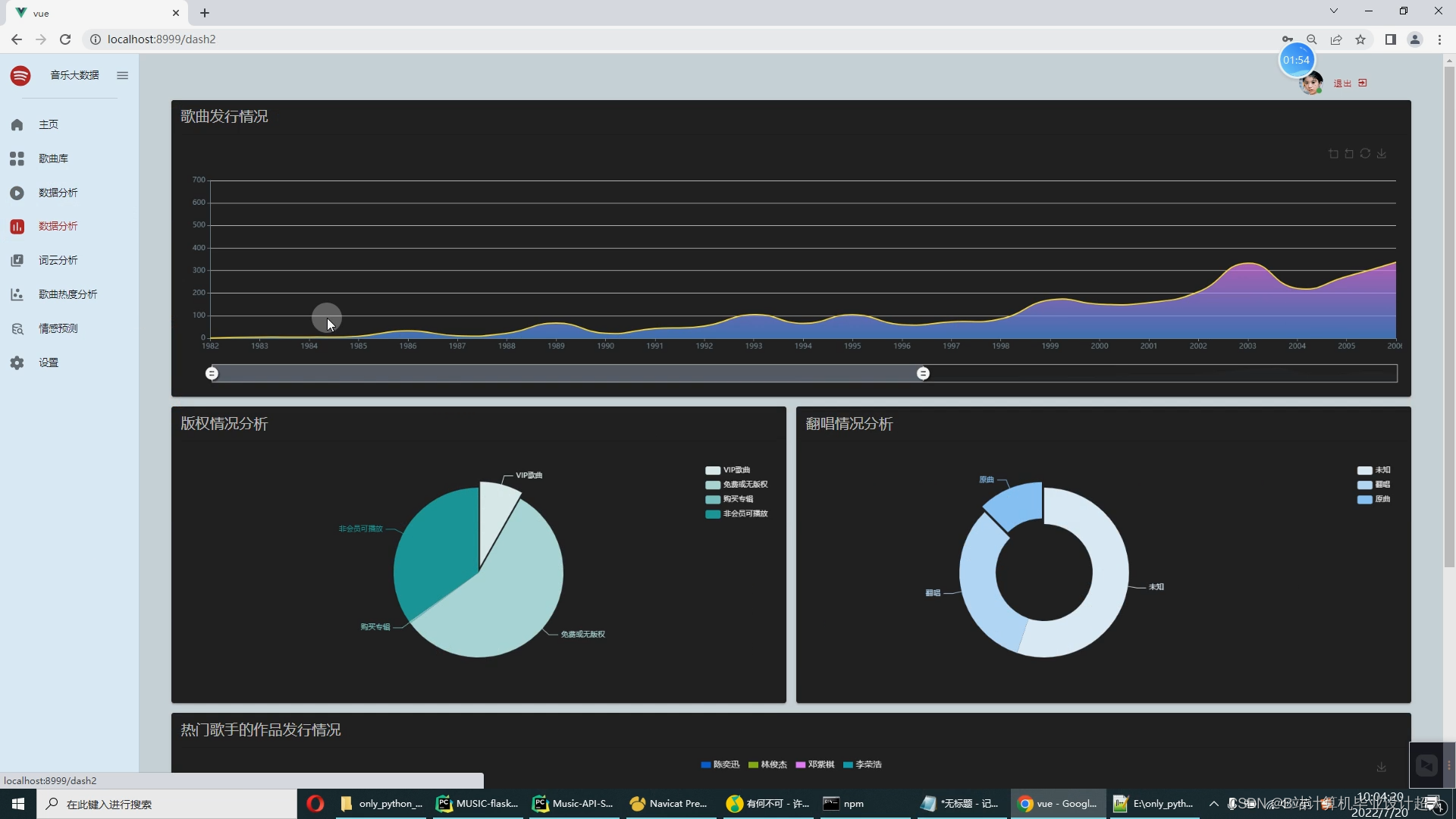
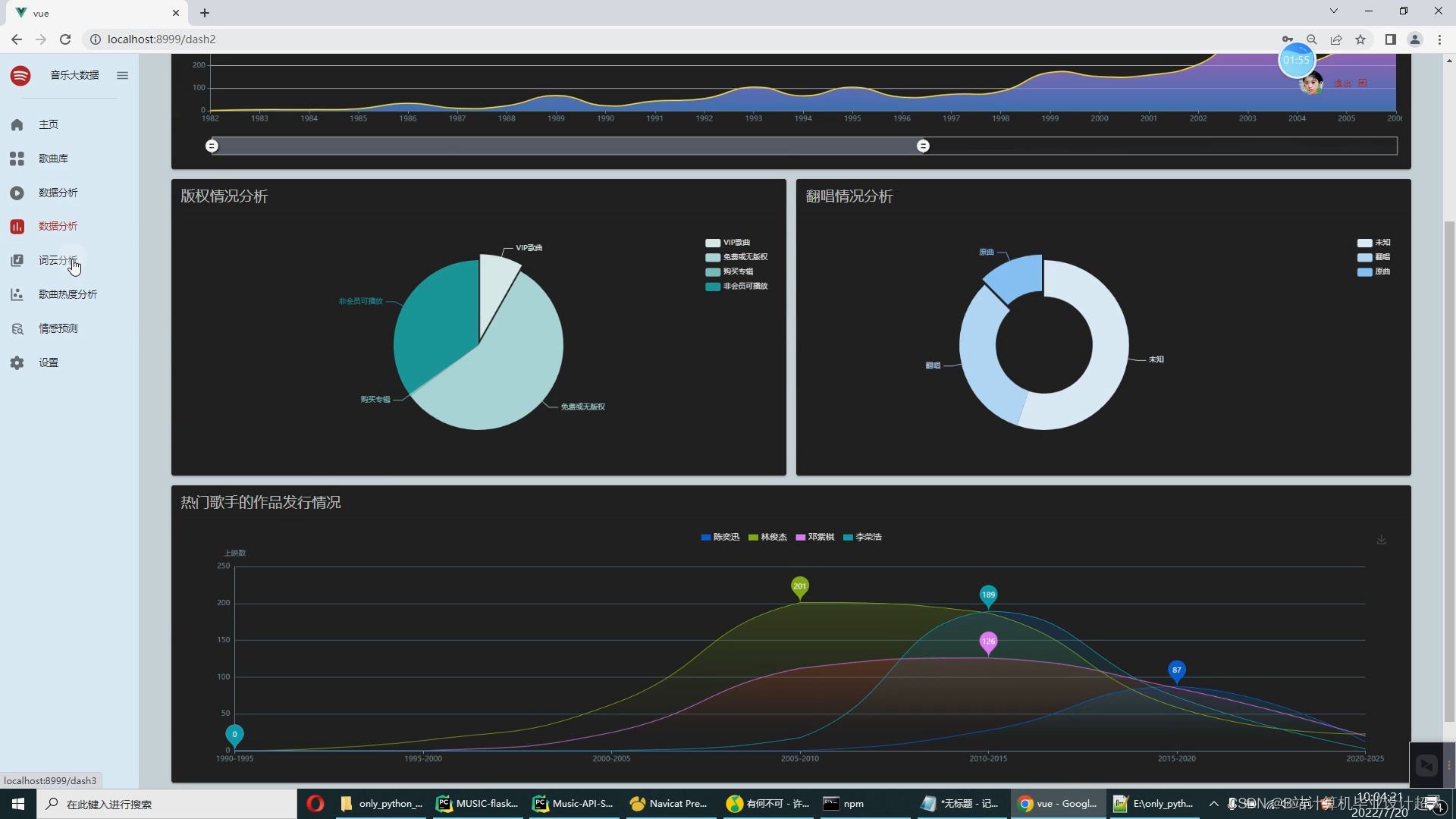
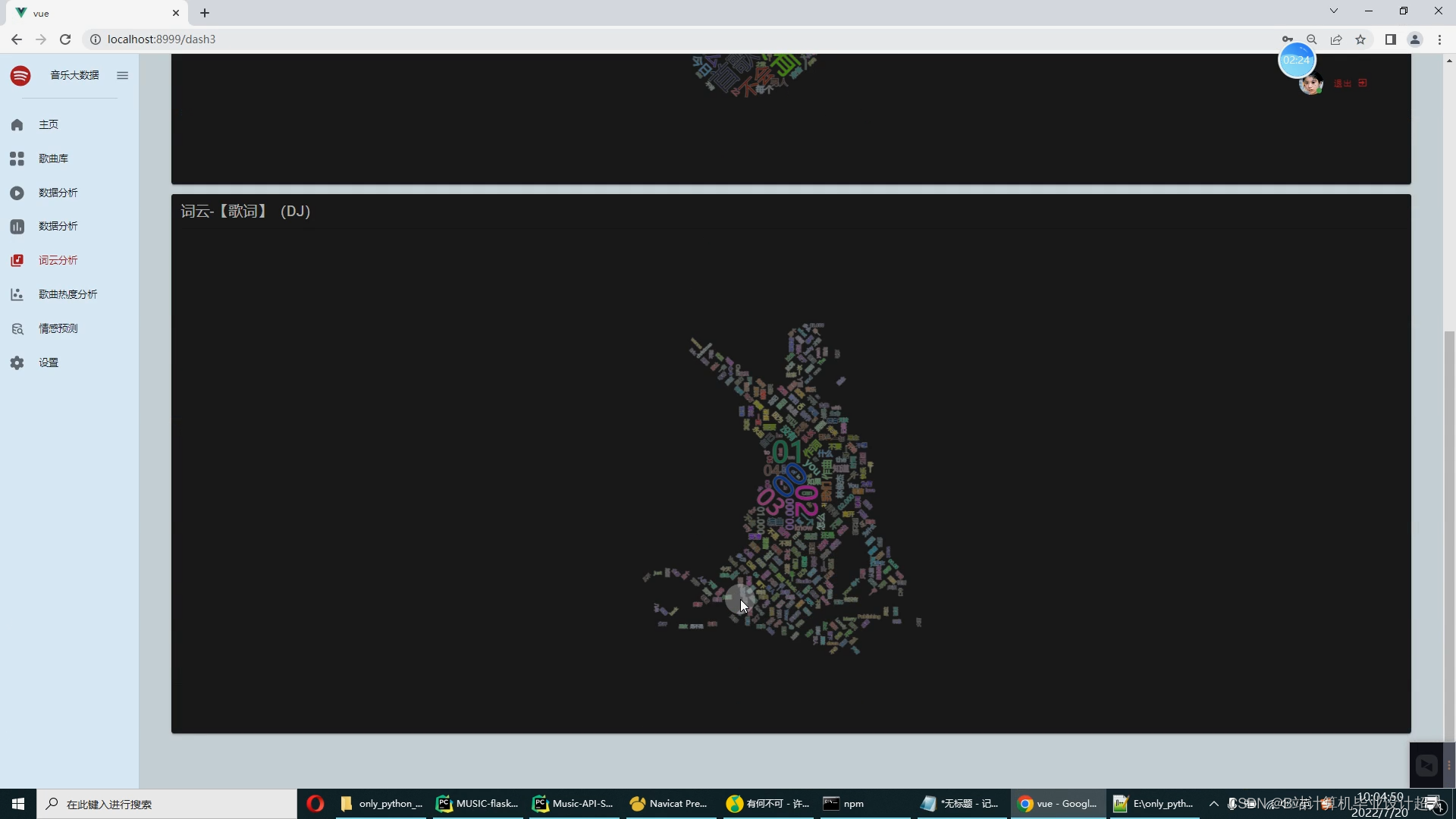
| 开题报告: 1.调研资料准备情况 音乐软件已成为绝大部分网络用户的网络设备中的必备软件,随着网络上的音乐资源的数量日渐庞大,设计个性化音乐的推荐系统成为一个非常实用的命题。本系统的最高目标就是为每一个用户推荐与其兴趣爱好契合度较高的音乐。 推荐系统的目的:让用户更快更好的获取到自己需要的内容;让内容更快更好的推送到喜欢它的用户手中;让网站(平台)更有效的增加用户粘性。 2.国内外研究现状 1.国外应用现状 如今,国外的很多唱片发行公司都在积极走向数字化,“索尼精选Hi-Res音乐”早在2014年10月就已开启高解析度数字音乐并开启付费下载业务,用音乐的高质量需求来驱动用户对正版音乐的付费下载,对此索尼精选也为广大发烧友和爱乐人提供FLAC格式Hi-Res音频,以及DSD等更高音质的正版专辑和单曲。硬件设备的迭代以及5G网络的迅猛发展,使得用户们的听歌场景日趋丰富,而当代人对于碎片化时间的利用率也越来越高,为满足消费者多样化的品鉴需求,索尼精选也不断完善流媒体内容池,丰富平台音乐类型。索尼精选凭借在Hi-Res音乐领域的专业度和权威性,以及广爱乐人的喜爱,成为了“最佳数字音乐平台”的奖项得主。 索尼精选的成功在于深度掌握了市场需求,高质量地满足了喜爱音乐人群的需求,并结合数据分析将用索尼精选的数字化推向了另一个高度。对此而言中国音乐无疑是索尼音乐可开拓的市场,无论是硬件还是数字音乐的收听,还是这些需求拉动的付费行为,丰富平台的音乐类型和音乐商城的发展,在引进世界各地合作伙伴的好音乐的同时,平台也基于数据挖掘不断推出更符合中国爱乐人审美的音乐内容,不断发展扩大市场范围。 2.国内应用现状 目前国外内有对音乐数据分析主要是集中于个性化音乐推荐的实现,常使用KNN算法、协同过滤算法等进行个性化推荐,最后实现大屏可视化的展示,与音乐可视化分析系统相比较为全面,而且实现了与大数据的紧密结合,以音乐平台的数据为基础实现的可视化分析系统在唱片公司的决策过程中运用较少。 3.设计的目的、要求 论文主要研究的是基于协同过滤算法(基于用户、基于物品两种形式)而开发的音乐可视化推荐系统。设计思路是用户通过登陆进入系统,根据用户的历史收藏、浏览等埋点日志数据,以此来初步确定用户欣赏音乐的倾向。另外,用户还可以从大家的推荐中搜索自己喜爱的音乐,或者从个性化推荐音乐列表中找到适合自己的音乐。除此之外,系统可以实现直观的可视化统计图表,如:歌手数量、歌曲数量、歌词数、评论数、歌手歌曲分析、歌手专辑分析、歌手平均热度排名、专辑平均热度排名、歌曲发行情况、版权情况分析、翻唱情况分析、热门歌手作品发行情况、词云分析、歌曲热度分析等。支持对歌曲评论的情感分析。具体内容如下: 1、音乐大屏幕展示端: 用户来源分布统计,歌手排行,歌手数量,歌曲数量,用户数量,播放数量,收藏数量,下载数量,充值金额排行,歌曲排行榜,数据统计图,播放量统计图。 用户注册、短信验证、用户登录、音乐库列表,最热歌曲列表展示,推荐歌曲列表,相似用户列表,收藏列表,金额充值,沙箱支付。 Python爬虫+机器学习离线分析数据 4.思路与预期成果 毕业设计和论文要包括需求分析、系统实现和系统测试的过程,完成系统核心功能的开发与测试环节。论文内容要求包括中英文摘要,绪论和结论,正文达到一万字,格式按照沈阳工学院毕业设计(论文)管理规定要求书写。 5.工作任务分解 第1-2周:搜集查阅资料,对项目进行调研,完成开题报告。 第3-4周:进行系统需求分析、功能设计、开发环境准备和论文部分初稿内容撰写。 第5周:进行数据库设计、界面设计以及论文初稿内容的撰写。 第6-11周:进行系统模块的代码编写和论文初稿内容的撰写。 第12-13周:进行系统测试,撰写此部分论文初稿。 第14-15周:修改与完善论文,参加答辩。 6.完成设计(论文)所具备的条件
7.存在的问题 用户权限开发,系统的管理人对使用该系统的不同用户不同的权限进行界定和管理;管理人员分为两类,如下:
用户分为三类,如下:
8.社会调查计划 本软件目前计划有网页版和App版,主要功能有歌曲播放、歌曲热榜、音乐推荐、音乐收藏、相似用户推荐。 软件的目标用户是有听歌需求和听歌习惯的人群,用户来源广泛,涵盖各个年龄段。iiMedia Research(艾媒咨询)数据显示,中国在线音乐用户中有42.5%日均听歌时长在半到一小时之间,有近30%的用户每日听歌两小时及以上,本软件的预期每日使用时间为人均一小时。 | |||||
| 指导教师意见: 同意 指导教师: 日 期:2022年01月13日 | |||||


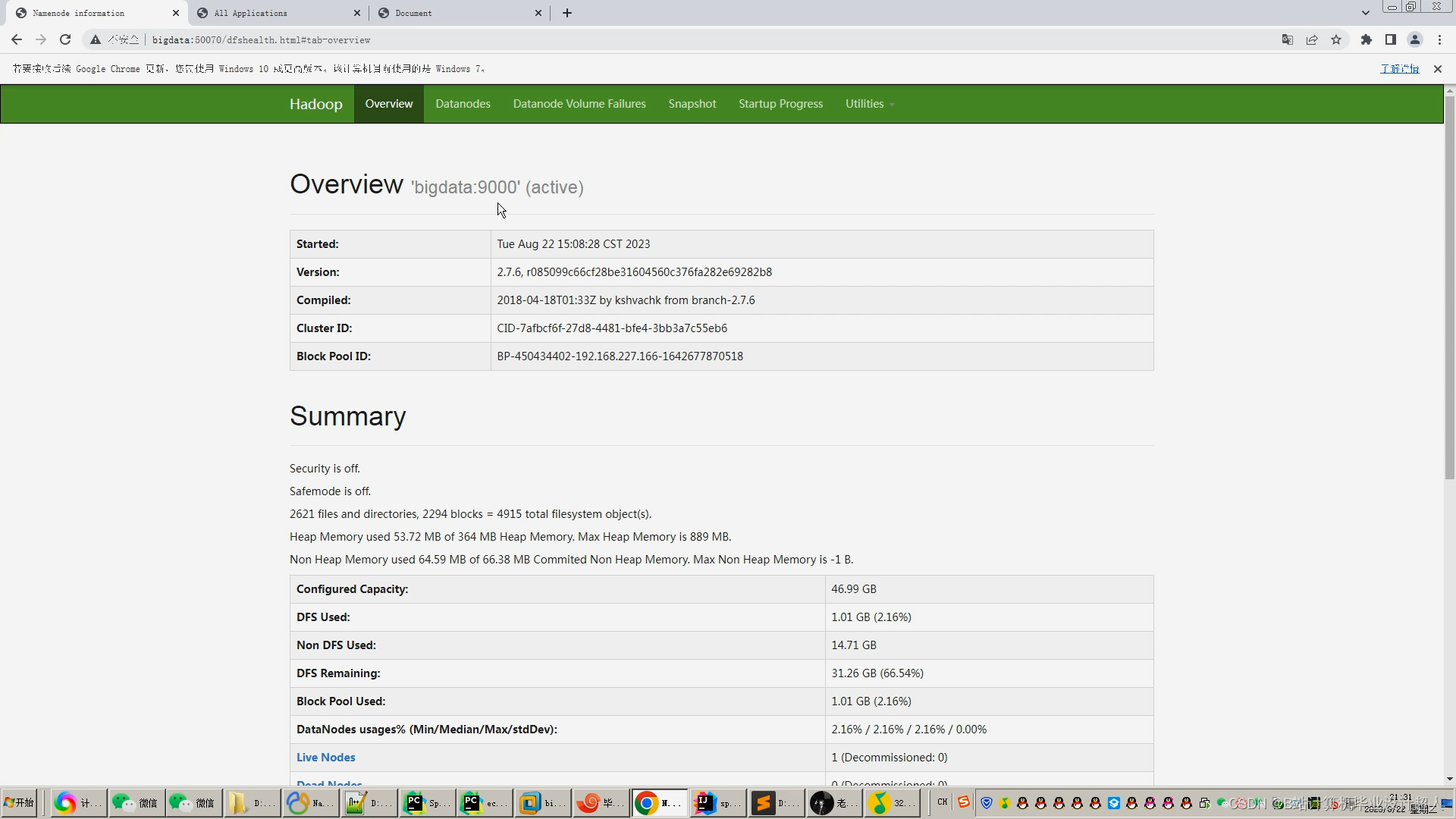

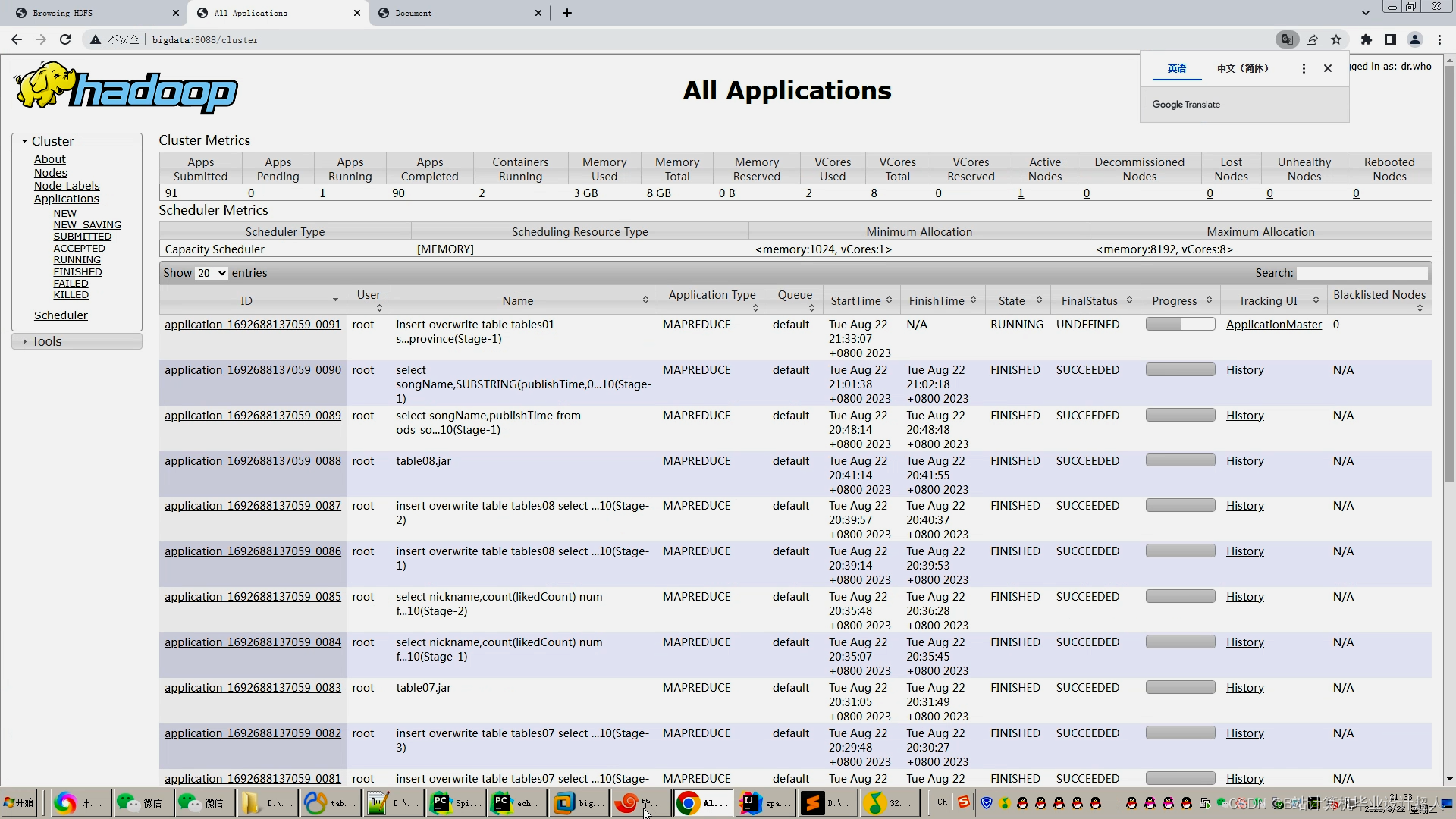

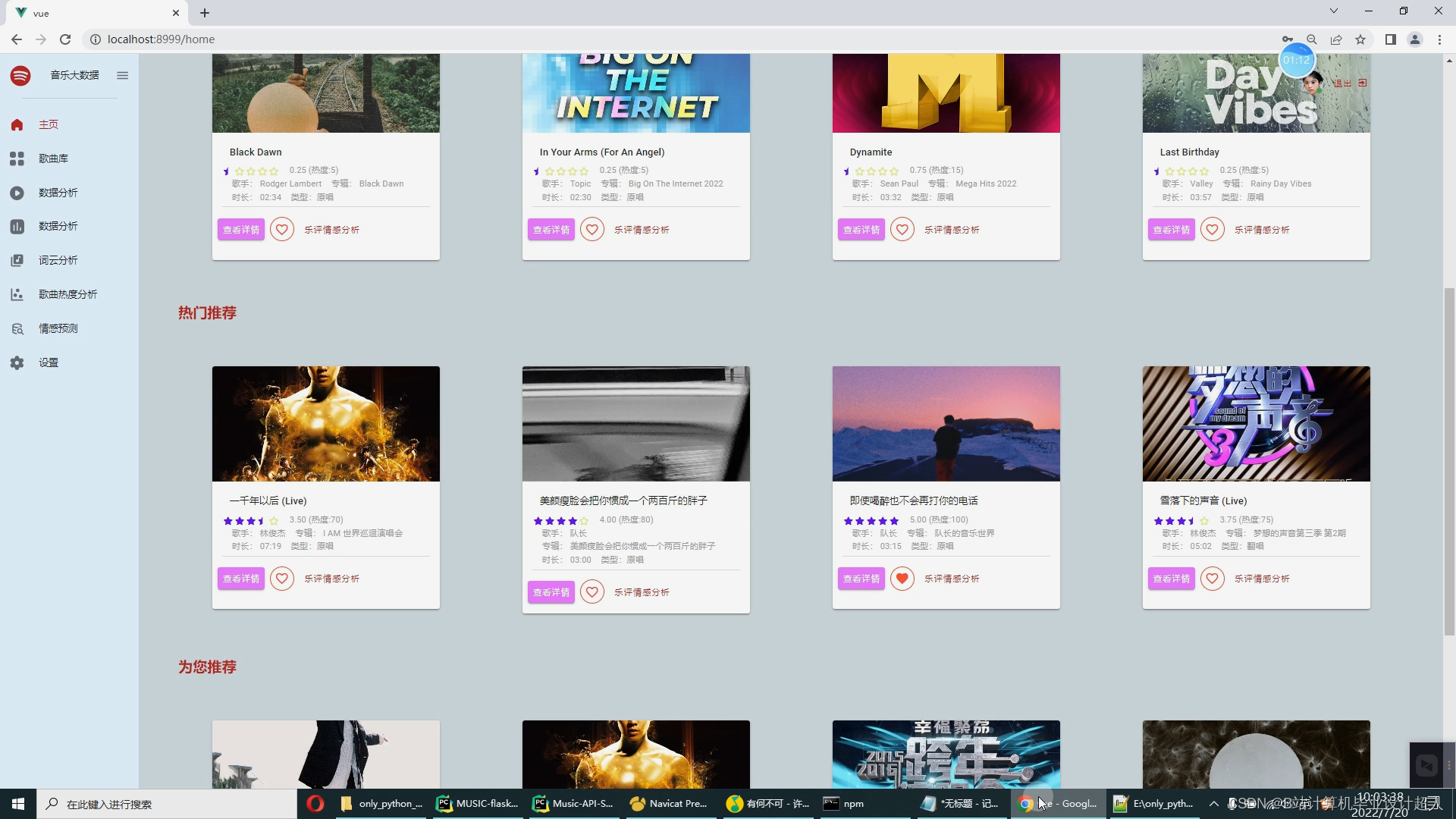
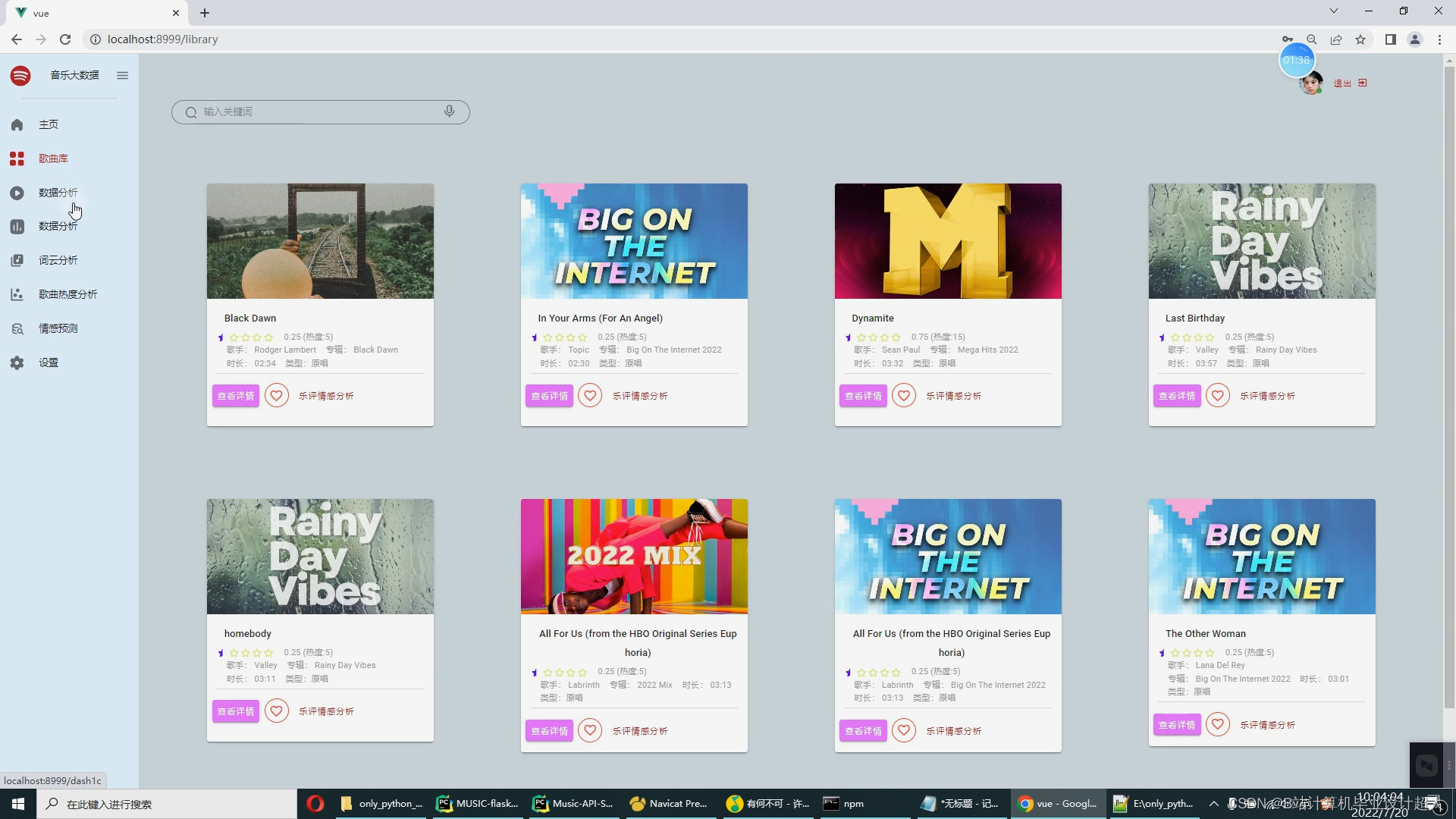

核心算法代码分享如下:
- import csv
-
- import pymysql
- import requests
- connect = pymysql.connect(host="bigdata",port=3306, user="root",
- password="123456", database="hive_zhaopin")
-
- cur = connect.cursor()
- cur.execute("select * from job "
- )
- rv = cur.fetchall()
- lines=0
- total=0
- for result in rv:
- total=total+1
- job_id=result[0]
- job_name=result[1]
- job_salary=result[2]
- job_degree=result[3]
- job_work_year=result[4]
- job_company_size=result[5]
- job_company_type=result[6]
- job_city=result[7]
- job_date=result[8]
-
- #job_name去掉特殊符号
- job_name = job_name.strip().replace(',', ',').replace('"', '').replace("'", '').replace("\n", '').replace('\r', '').replace('\t', '')
- #job_company_size job_company_type
- if job_company_size==None or len(job_company_size)==0 or job_company_size=='':
- continue
- else:
- job_company_size = job_company_size.strip().replace(',', ',').replace('"', '').replace("'", '').replace("\n", '').replace('\r', '').replace( '\t', '')
- if job_company_type==None or len(job_company_type)==0 or job_company_type=='':
- continue
- else:
- job_company_type = job_company_type.strip().replace(',', ',').replace('"', '').replace("'", '').replace("\n", '').replace('\r', '').replace( '\t', '')
-
- job_date=job_date.strftime("%Y-%m-%d")
- print('数据清洗',job_id,job_name,job_salary,job_degree,job_work_year,job_company_size,job_company_type,job_city,job_date)
-
- job_file = open("jobs.csv", mode="a+", newline='', encoding="utf-8")
- job_writer = csv.writer(job_file)
- job_writer.writerow(
- [job_id,job_name,job_salary,job_degree,job_work_year,job_company_size,job_company_type,job_city,job_date])
- job_file.close()
- lines= lines+1
- print('处理数据量',total)
- print('正常数据量',lines)


