
- 1python爬取高德地图道路交通状态数据代码_高德路网数据爬取
- 2【安路FPGA】从流水灯入门安路开发环境_安路cpld ip怎么用 csdn
- 3**office2016下安装mathtype报错:The MathType DLL cannot be found.Please reinstall Math
- 4问卷星使用入门指南:编程实现问卷星自动化_问卷调查软件可以插入代码吗
- 5SQL INSERT INTO TABLE SELECT指定插入字段的新用法
- 6NLTK和jieba这两个python的自然语言包(HMM,rnn,sigmoid
- 7fabirc的get或者put抛出的paramiko.ssh_exception.SSHException: Channel closed.
- 8基于STM32的人体心率血氧无线检测系统设计(一)_esp8266-01s max30102
- 9Rstudio devtools.install_github()下载失败解决_r语言devtools下载不了
- 10人工智能之产生式系统_产生式系统py
算法工程师的日常工作内容?你想知道的可能都在这里
赞
踩
击上方“AI算法与图像处理”,选择加"星标"或“置顶”
重磅干货,每天8:25送达

作者:Rebecca Vickery编译:AI算法与图像处理

导读
有很多小伙伴可能都对未来的工作内容有所好奇,不知道所谓的算法工程师到底日常在做什么,而我以后能不能胜任?
继续看下来,或许能解开你的疑惑~>_<

你有没有参加过Kaggle比赛?如果你正在学习,或者已经学过机器学习,那么很可能在某些时候你会参加一次。这绝对是将构建模型的技能应用于实践中的好方法,我在学习时花了很多时间在Kaggle比赛上。
下载一些数据(可能是一个或几个CSV文件)。
也许做一点数据清理,或者数据集可能已经足够干净了。
执行一些预处理,例如将分类数据转换为数字数据。
通过各种合适的模型运行数据,直到找到最佳模型。
花费很长时间在超参数调整,特征工程和模型选择上,因为一个非常小的改进可能意味着你在排行榜上升几个位置。
结束
但是,如果您正在为实际业务应用程序开发机器学习模型,则该过程将看起来完全不同。我第一次在业务场景中部署模型时,这些差异非常令人惊讶,特别是在工作中的某些阶段花了很多时间。在下面的文章中,我想描述在业务环境中开发模型的过程,并详细讨论这些差异和解释它们存在的原因。在商业案例中,工作流程将有更多的步骤,可能看起来像这样。
将业务问题翻译成数据问题。
考虑机器学习模型如何连接到现有的技术栈中。
花费大量时间提取,转换和清理数据。
花费大量时间进行探索性分析,预处理和特征提取。
建立模型。
选择能够以最少的工程量集成到现有技术栈中的最佳模型。
考虑到业务价值,优化模型直到“足够好”。
部署模型。
在生产中监控模型。
必要时重新训练。
构建版本2。
继续,直到模型不再有业务用途。
在本文的其余部分,我将详细介绍每个步骤。
您需要将业务问题翻译成数据问题
在Kaggle比赛中,要解决的问题将在前面明确定义。例如,在最近一项名为“Severstal:钢铁缺陷检测”的竞赛中,您将获得一些准备好的数据,并以数据问题的形式明确说明问题。
今天,Severstal使用来自高速摄像机获取的图像推进缺陷检测算法的改善。在本次竞赛中,您将通过对钢板上的表面缺陷进行定位和分类来帮助工程师改进算法。
在实际业务问题中,您不一定会被要求构建特定类型的模型。团队或产品经理更有可能遇到业务问题。这可能看起来像这样,有时甚至可能没有明确定义问题。
客户服务团队希望减少业务回复客户电子邮件,实时聊天和电话所需的时间,以便为客户创造更好的体验并提高客户满意度指标。
根据此业务要求,您需要与团队合作,在开始构建实际模型之前,计划并设计此问题的最佳解决方案。
发数据并未“清洗”(不干净的数据)
您使用的数据几乎肯定不会被“清洗”。通常会有缺失的值。日期可能格式错误。值,错误数据和异常值可能存在拼写错误。在你真正建立模型的任何地方之前,很可能花费大量时间来删除错误数据,异常值和处理缺失值。
您可能必须从不同来源中获取数据
同样,您需要的所有数据可能不是来自一个简单的来源。对于数据科学项目,您可能需要从以下任意组合中获取数据:SQL查询(有时跨多个数据库),第三方系统,Web抓取,API或来自合作伙伴的数据。与数据清理类似,这部分通常是项目中非常耗时的部分。
特征选择非常重要
在机器学习竞赛中,您通常会有一个给定的数据集,其中包含可在模型中使用的有限数量的变量。功能选择和工程仍然是必要的,但您首先要选择的变量数量有限。在处理现实问题时,您很可能会访问大量变量。作为数据科学家,您必须选择可能产生良好模型的数据点来解决问题。因此,您需要结合使用探索性数据分析,直觉和领域知识来选择正确的数据来构建模型。
发构建模型占流程中的最小的比重
与花费在选择,提取和清理数据的所有这些时间相比,实际构建模型所花费的时间将非常少。对于特别是模型的版本1,您可能希望将模型用作基线测试,那么您可能在第一个实例中仅花费少量时间进行模型选择和调整。一旦业务价值得到证实,您就可以投入更多时间来优化模型。
调整模型比您想象中要花费更少的时间
在Kaggle比赛中,花费数周时间调整模型以获得模型得分的小幅提升并不罕见。由于这个小小的改进可能会提升你在排行榜上的几个名次。例如,在当前的Severstal 竞赛中,排行榜上位置1和2之间的得分差异目前仅为0.002。绝对值得花时间来提高你的分数,因为它可能会给你带来最高奖金。
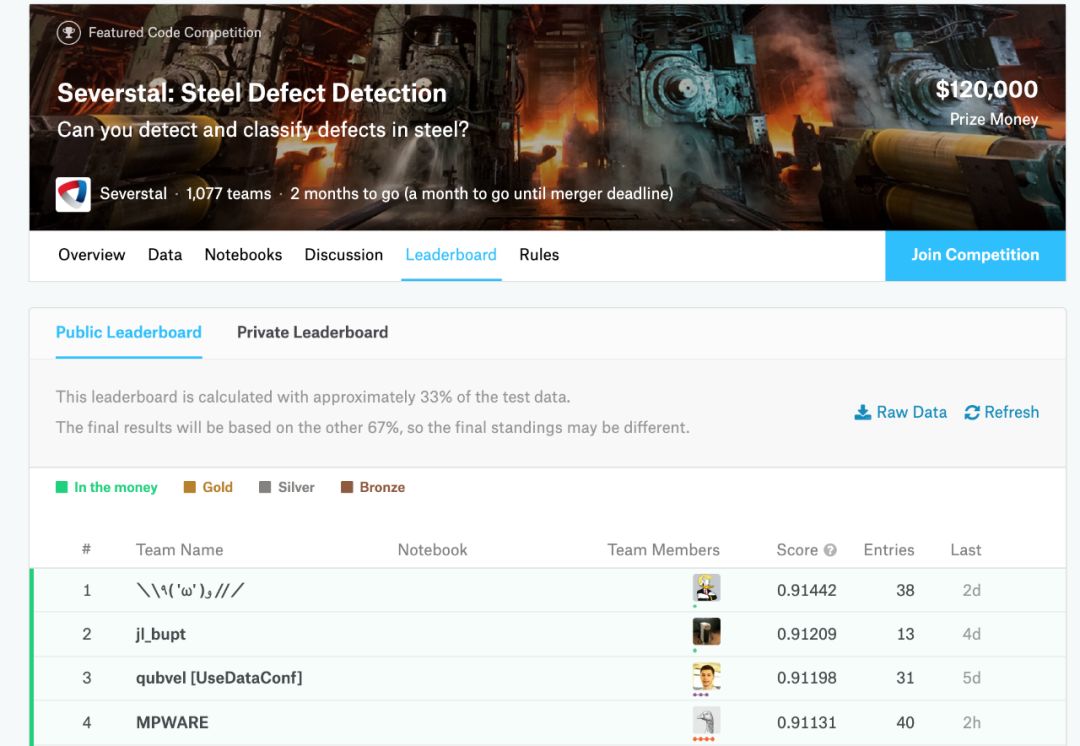
来源:Kaggle.com
在商业中,您花在调整模型上的时间是成本(烧钱的)。公司必须按照您在此任务上花费的天数或周数支付工资。与所有事物一样,需要以商业价值的形式回报这种投资。模型的业务用例不太可能提供足够的价值来证明花费数天的时间来提高模型的准确性,增量为0.002。实际上,您将调整模型直到它“足够好”而不是“最佳”。
您不一定会使用最好的模型
这引出了我的下一点,即你不会总是使用最好的模型或最新的深度学习方法。通常,您可以使用更简单的模型(如线性回归)来提供更多业务价值。这花费的时间更少(因此搭建模型的成本更低)并且更易于解释。
您的模型必须连接到某个终端(endpoint),例如网站。此终端的现有技术堆栈将对您将部署的模型类型产生很大影响。数据科学家和软件工程师经常会在最小化两端的工程工作方面做出妥协。如果您有一个新模型,这意味着要对现有部署流程或大量工程工作进行更改,那么您必须拥有一个非常好的业务案例来部署它。
工作并不止于此
一旦投入生产,就需要对模型进行监控,以确保其在训练和验证过程中的性能和检查模型降级情况。由于多种原因,模型的性能通常会随着时间的推移而降低。这是因为数据会随着时间的推移而变化,例如客户行为发生变化,因此您的模型可能会开始在这些新数据上表现不佳。因此,模型还需要定期重新训练以保持业务性能。
此外,大多数企业将拥有用于部署机器学习模型的测试和学习周期。因此,您的第一个模型通常是版本1,以形成性能基准。之后,您将对模型进行改进,可能会更改功能或调整模型,部署更好的版本并针对原始模型进行测试。
在此模型不再存在业务案例之前,这两个过程都可能正在进行。
结论
这篇文章的部分灵感来自Chip Huyen的推文。

招聘机器学习从业者很困难的部分原因是,我在这里讨论的许多在商业中部署机器学习的现实都没有在这些课程中讲授。这就是为什么我喜欢实用的第一种学习方法,以及为什么我认为工业实习,实习和初级数据科学角色如此重要。
然而,隧道尽头有光,因为这个领域的技术正在迅速发展,有助于实现数据清理和模型部署等流程的自动化。但是,我们还有很长的路要走,因此对于数据科学家来说,开发软件工程技能,提高沟通技巧,以及拥有弹性和持久的思维模式,以及典型的数据科学家技能组合仍然至关重要。
谢谢阅读
原文链接:https://towardsdatascience.com/machine-learning-in-real-life-eebcb08f099c?source=user_profile---------0-----------------------
end

交流群
扫码添加助手,可申请加入AI_study交流群。一定要备注:研究方向+地点+学校/公司+昵称(如目标检测+上海+上交+卡卡西),不根据格式申请,一律不通过。
【目前已有众多知名高校学生和从业者在群里面学习成长,期待你的加入】

推荐阅读:



