
- 1unity编译时找不到AndroidSDK:Unable to list target platforms_unityexception: android sdk not found
- 2Django的数据库模型的CharField字段的max_length参数与中文字符数的关系探索(参数max_length的单位是字符个数还是字节数?)_django模型中charfield是以字节计数的码
- 3新拉取java 项目 怎么弄依赖_从gitHub上拉取并运行项目
- 4SpringBoot全局异常处理 | Java
- 5六、生成对抗网络(GAN)手写数字的识别_手写数字识别gan网络 可视化
- 6(01)ATF简介_atf开源吗
- 7Unity 3D游戏-塔防类游戏源码:重要方法和功能的实现_unity 塔防游戏源码
- 8数学建模_自来水管铺设问题_‘一级供水站数量选择’
- 9《ASP.NET Core微服务实战 在云环境中开发、测试和部署跨平台服务》之ASP.NET Core 基础_asp.net core微服务实战 pdf
- 10一文快速掌握IPv6基础知识及使用指南_ipv6组网详细指南
python重要知识点总结(黑马程序员)_python所有知识点
赞
踩
Python是靠缩进来判断归属的
1、if name == ‘main’
一个python文件通常有两种使用方法:
(1)第一是作为脚本直接执行。
(2)使用import到其他的python脚本中被调用(模块重用)执行。
if name == 'main’只有在文件作为脚本直接执行才会被执行,而import到其他脚本中是不会被执行的。
def some_function():
# 这个函数可以在其他脚本中重复使用。
if __name__ == '__main__':
# 这个代码块只会在脚本直接执行时运行,而不会在被导入时运行。
# 你可以在这里放置主要脚本逻辑。
# 通常,在这里调用函数或定义类并执行代码。
some_function()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
在 if name == ‘main’: 块下的任何代码只会在直接运行脚本时运行,但不会在将脚本作为模块导入到其他脚本中时运行。
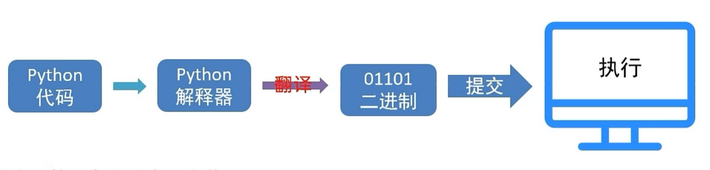
2、python解释器
Python解释器是一种计算机程序,它负责执行Python编程语言的代码。Python是一种解释性语言,这意味着Python代码不需要在运行之前编译成机器代码,而是由Python解释器逐行执行。
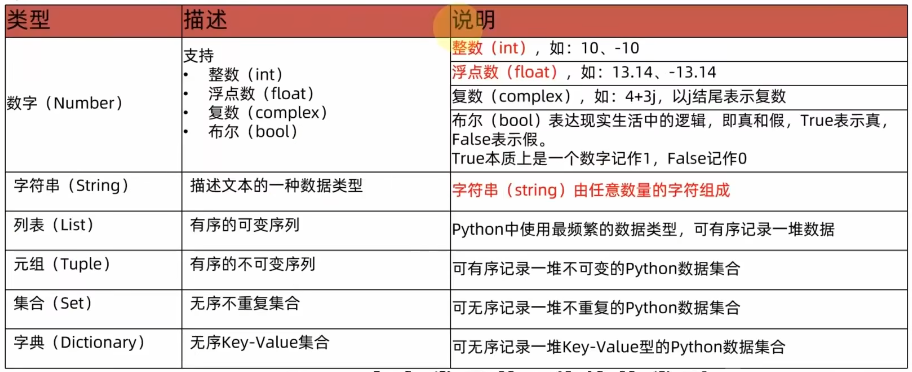
3、python中常用的6种数据类型
4、标识符
在python语句中,我们可以给变量、方法、类等起名字,这些名字我们把它统一的称为标识符。
命名规则:(1)英文(2)中文(不推荐)(3)数字(不可以用在开头)(4)下划线(_)
标识符命名规则:不可使用关键字

5、运算符
算术运算符

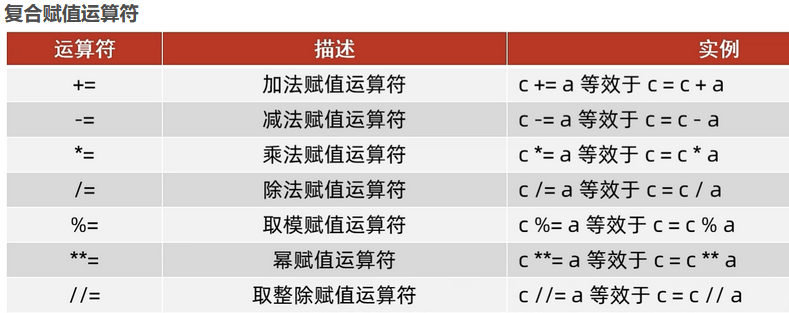
6、for循环的基础语法
for循环是一种轮询机制,是对一批内容进行逐个处理
for循环是将字符串的内容:依次取出。所以,for循环也被称之为遍历循环。for循环不可以构造出无限循环。
if __name__ == '__main__': # 定义字符串name name = "itheima" # for循环处理字符串 for x in name: print(x) ''' i t h e i m a '''

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
7、continue和break
continue:中止本次循环,直接进入下一次循环

if __name__ == '__main__':
#演示中断语句continue
for i in range(1,10):
print("1 ",end="")
continue
print("我是菜鸡")
'''
1 1 1 1 1 1 1 1 1
'''
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
break:直接结束循环:

if __name__ == '__main__':
#演示break的嵌套应用
for i in range(1,10):
print("1 ",end="")
break
print("我是菜鸡")
'''
1
'''
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
8、函数的基本定义语法
函数的定义:
def 函数名 (传入参数):
函数体
return 返回值 #其中传入参数与返回值可以没有
- 1
- 2
- 3
函数的调用:
函数名 ()
函数名(传入参数)
a = 函数名()
a = 函数名(传入参数)
- 1
- 2
- 3
- 4
函数的返回值定义语法
if __name__ == '__main__':
def add(a,b):
result = a + b
return result
r = add(1,2)
print(r)
"""
定义两数相加的函数功能。完成功能后,会将相加的结果返回给函数调用者
所以,变量r接收到了函数的执行结果
"""
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
函数的说明文档
if __name__ == '__main__':
# 主动返回None的函数
def add(x,y):
"""
add函数可以接收2个参数,进行2数相加的功能
:param x:形参x 表示相加的其中一个数字
:param y:形参y 表示相加的另一个数字
:return:返回值是2 数相加的结果
"""
result =x+y
print(f"和为{result}")
return result
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
函数的嵌套调用
if __name__ == '__main__': # 定义函数func_ _b def func_b(): print("---2---") # 定义函数func_ a,并在内部调用func_ b def func_a(): print("---1---") # 嵌套调用func_ .b . func_b() print("---3---") # 调用函数func_ a func_a() """ ---1--- ---2--- ---3--- """
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
函数A中,调用另外一个函数B,那么先把函数B中的任务都执行完毕之后才会回到上次 函数A执行的位置
9、None类型
10、Python中的数据容器:
数据容器根据特点的不同,如:
(1)是否支持重复元素
(2)是否可以修改
(3)是否有序,等
分为5类,分别是:列表(list) 、元组(tuple) 、字符串(str) 、集合(set) 、字典(dict)
'''
# 文本类型:str(字符串)
# 数字类型: int(整数),float(浮点数),complex(复数)
# 序列类型:list(列表)[],tuple(元组)(),range(范围),dic(字典)
# 套装类型:set(集合),frozenset(冻结集)
# 布尔类型:bool
# 二进制类型:bytes,bytearray,memoryview
'''
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
11、方法和函数
函数是一个封装的代码单元,可以提供特定功能。在python中,如果将函数定义为class(类)的成员,那么函数会称为:方法
# 函数
def add(x,y):
return x + y
#方法
class Student:
def add(self,x,y):
return x + y
- 1
- 2
- 3
- 4
- 5
- 6
- 7
方法和函数功能一样,有传入参数,有返回值,只是方法的使用格式不同:
函数的使用:num= add(1,2)
方法的使用:student = Student() num = student.add(1,2)
12、列表
#字面量
[元素1,元素2,元素3...]
#定义变量
变量名称 = [元素1,元素2,元素3...]
#定义空列表
变量名称 = []
变量名称 = list()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
if __name__ == '__main__':
# 定义一个嵌套的列表
my_list = [[1, 2, 3],[4, 5, 6]]
print(my_list)
print(type(my_list))
'''
[[1, 2, 3], [4, 5, 6]]
<class 'list'>
'''
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
列表的常见方法:
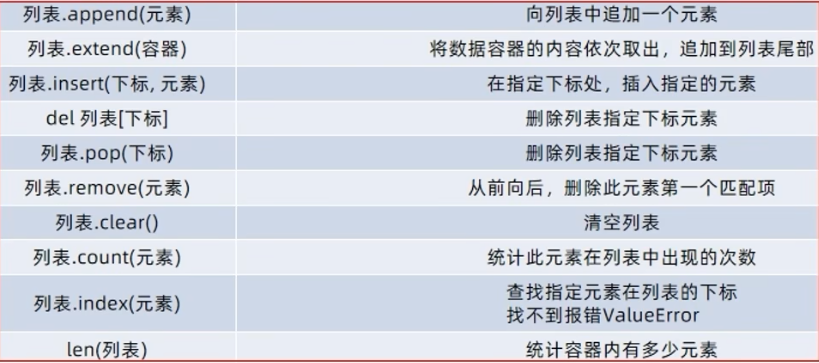
13、列表的循环遍历
#while循环 if __name__ == '__main__': my_list = [21,25,21,23,22,20] index = 0 while index < len(my_list): #通过index变量取出对应下标的元素 element = my_list[index] print(f"列表的元素:{element}") index+= 1 ''' index = 0 while index <len(列表): 元素 = 列表[index] 对元素处理 index += 1 '''
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
#for循环
def list_for_func():
my_list = [1,2,3,4,5]
for element in my_list:
print(f"列表的元素有:{element}")
list_for_func()
'''
for 临时变量 in 数据容器:
对临时变量进行处理
'''
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
14、元组
元组:同样可以存储不同类型元素,一旦完成定义,就不可以修改
元组遍历
if __name__ == '__main__':
t8 = ("python",1,34,90)
#while
index = 0
while index < len(t8):
print(f"元组的元素有:{t8[index]}")
index += 1
#for
for element in t8:
print(f"元组的元素有:{element}")
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
15、字符串
字符串操作
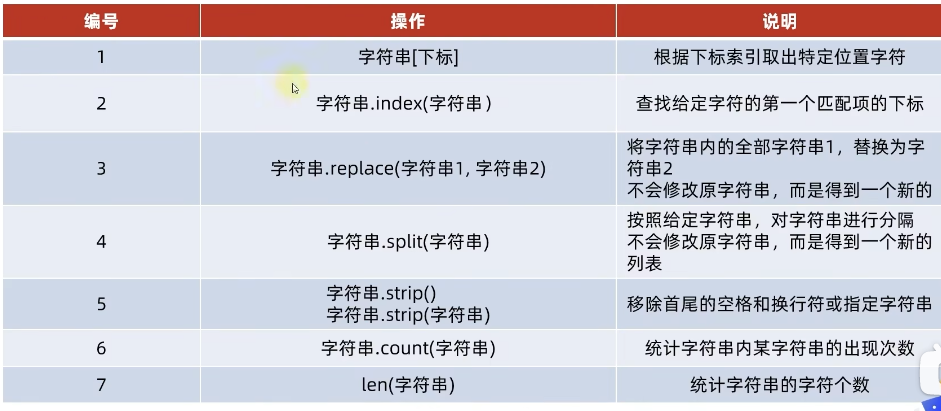 字符串的三种定义方式
字符串的三种定义方式
(1)单引号定义法:name = ‘黑马程序员’
(2)双引号定义法:name =“黑马程序员”
(3)三引号定义法:name=“”“黑马程序员”“”
三引号定义法:和多行注释的写法一样,同样支持换行操作。使用变量接收它,它就是字符串,不使用变量接收它,就可以作为多行注释使用
16、集合
列表:可修改、支持重复元素且有序
元组、字符串:不可以修改、支持重复元素且有序
集合:不支持元素的重复(自带去重功能)、并且内容无序 集合不支持下标索引,所以不支持使用while循环
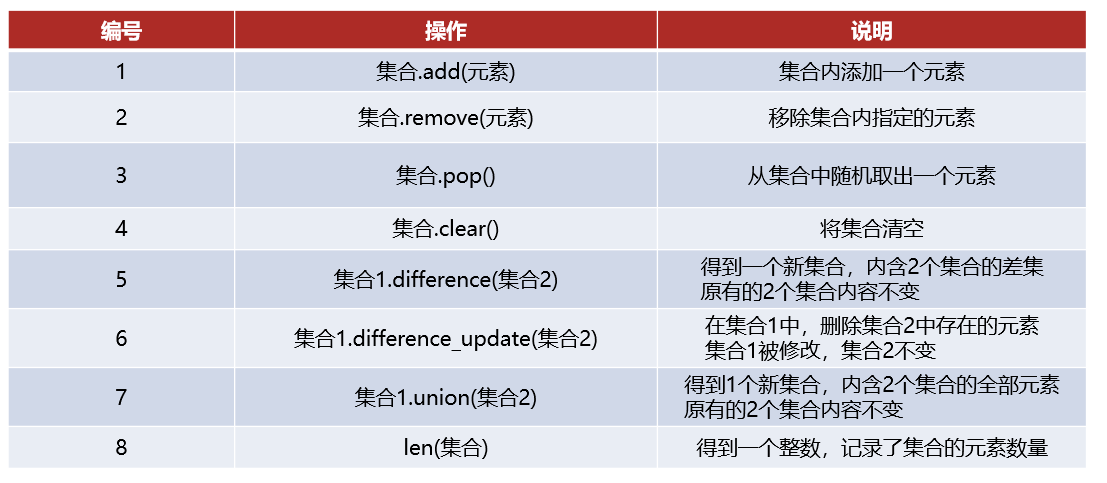
17、字典
定义:实现用Key取出Value的操作,使用{},不过存储的元素是一个个的:键值对
字典同集合一样,不可以使用下标索引,但是字典可以通过Key值来取得对应的Value
字典不支持下标索引,所以同样不可以用while循环遍历
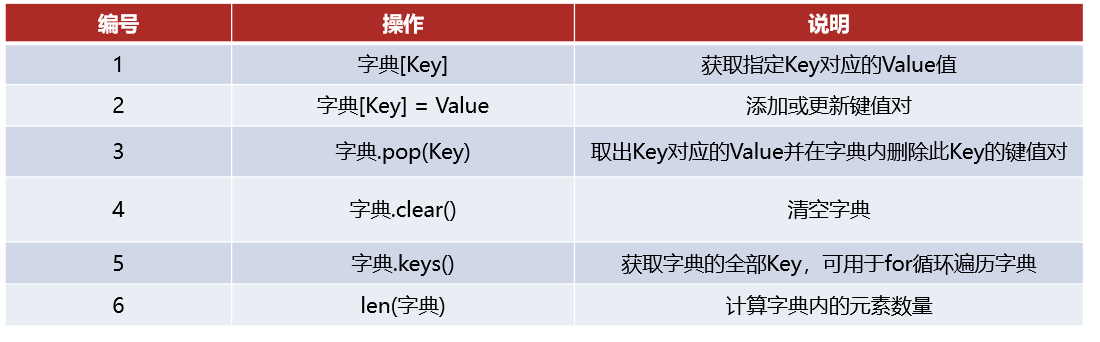
18、五类数据容器对比
数据容器可以从以下视角进行简单的分类:
(1)是否支持下标索引
支持:列表、元组、字符串-序列类型
不支持:集合、字典-非序列类型
(2)是否支持重复元素
支持:列表、元组、字符串-序列类型
不支持:集合、字典-非序列类型
(3)是否可以修改
支持:列表、集合、字典
不支持:元组、字符串
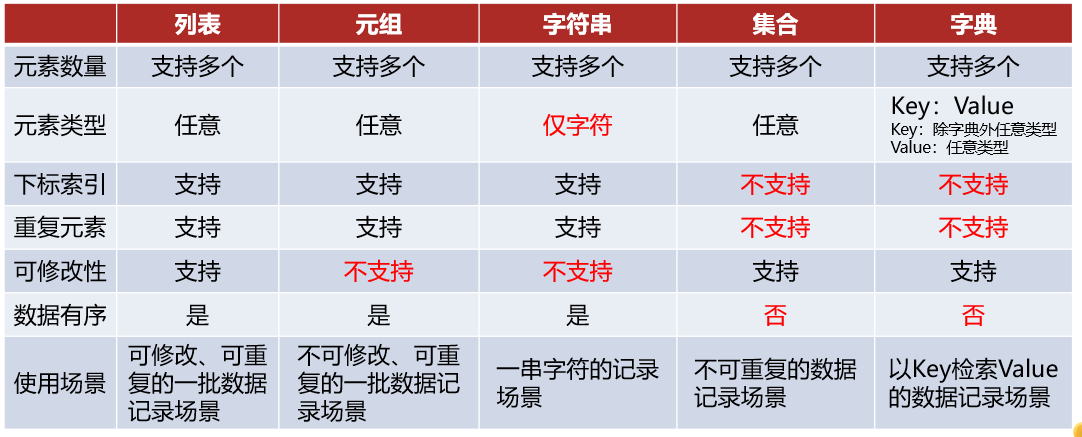
19、函数进阶
(1)函数的多返回值
import re if __name__ == '__main__': def return_num(): return 1 return 2 result = return_num() print(result) #结果 1 #只执行第一个return,原因是因为return可以退出当前函数,导致return下方的代码不执行 #一个函数有多个返回值 def test_return(): return 1,"hello",True x,y,z= test_return() print(x) #结果1 print(y) #结果2 print(z) #结果: #1 #hello #True #按照返回值的顺序,写对应顺序的多个多个变量接收即可,变量之间用逗号隔开,支持不同类型的数据return
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
(2)函数的多种参数使用形式
- 位置参数
#位置参数
def user_info(name,age,gender):
print(f'您的名字是{name},年龄是{age},性别是{gender}')
user_info('TOM',20,'男')
- 1
- 2
- 3
- 4
- 5
- 关键字参数
#关键字参数
def user_info(name,age,gender):
print(f"您的名字是:{name},年龄是:{age},性别是:{gender}")
#关键字传参:函数调用时,如果有位置参数时,位置参数必须在关键字的前面,但关键字参数之间不存在先后顺序
user_info(name="小明",age=20,gender="男")
#可以不按照固定顺序
user_info(age=20,gender="男",name="小明")
#可以和位置参数混用,位置参数必须在前,且匹配参数顺序
user_info("小明",age=20,gender="男")
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 缺省参数
#缺省参数:当调用函数时没有传递参数,就会使用默认是用缺省参数对应的值
def user_info(name,age,gender='男'):
print(f'您的名字是{name},年龄是{age},性别是{gender}')
user_info('Tom',20)
user_info('rose',18,'女')
- 1
- 2
- 3
- 4
- 5
- 6
- 不定长参数:当调用函数时不确定参数个数时,可以使用不定长参数
分为位置传递和关键字传递
#位置传递 def user_info(*args): print(args) user_info('Tom') user_info('Tom',18) #结果: #('Tom',) #('Tom', 18) #传进来的所有参数都会被args变量收集,他会根据传进参数的位置合并为一个元组,args是元组类型 #关键字传递 def user_info(**kwargs): print(kwargs) user_info(name='Tom',age=18,id=110) #结果 #{'name': 'Tom', 'age': 18, 'id': 110} #参数是"键=值"形式的情况下,所有的"键=值"都会被kwargs接受,同时会根据"键=值"组成字典
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
(3)匿名函数
- 函数作为参数传递:将函数传入的作用在于:传入计算逻辑,而非传入数据
#定义一个函数,接收另一个函数作为传入参数
def test_func(compute):
result = compute(1,2) #确定compute是函数
print(f"compute参数的类型是:{type(compute)}")
print(f"计算结果:{result}")
#定义一个函数,准备作为参数传入另一个函数
def compute(x,y):
return x+y
#调用,并传入函数
test_func(compute)
#结果
#compute参数的类型是:<class 'function'>
#计算结果:3
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- lambda匿名函数
函数的定义中:
1.def关键字,可以定义带有名称的函数
2.lambda关键字,可以定义匿名函数(无名称)
有名称的函数,可以重复使用
没有名称的匿名,只能临时使用一次
#定义一个函数,接收另一个函数作为传入参数
def test_func(compute):
result = compute(1,2)
print(f"计算结果:{result}")
#通过lambda匿名函数的形式,将匿名函数作为参数传入
test_func(lambda x,y:x+y)
#结果:3
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
20、文件编码概念
(1)文件的编码
计算机中有很多可用的编码:UTF-8、GBK、Big5等,将内容翻译成二进制,以及将二进制翻译回可识别内容。
计算机只认识0和1,所以需要将内容翻译成0和1才能保存在计算机中。同时也需要编码,将计算机保存的0和1,反向翻译回可以识别的内容。
(2)文件的读取
- 打开文件
open(name,mode,encoding)函数
name:是要打开的目标文件名的字符串(可以包含文件所在的具体路径)
mode:设置打开文件的模式(访问模式):只读、写入、追加等
encoding:编码格式(推荐使用UTF-8)
 1.read()方法。文件对象。read(num) num表示要从文件中读取的数据的长度,如果没有传入num个字符, 那么就表示读取文件中的所有的数据
1.read()方法。文件对象。read(num) num表示要从文件中读取的数据的长度,如果没有传入num个字符, 那么就表示读取文件中的所有的数据
2.readlines()方法:
readlines可以按照行的方式把整个文件中的内容进行一次性读取,并且返回的是一个一个列表,其中每一行的数据为一个元素。
f =open('python.txt') #f为文件对象
content = f.readlines()
print(content)
#关闭文件
f.close()
- 1
- 2
- 3
- 4
- 5
- 6
for循环读取文件行
for line in open("python.txt","r")
print(line)
#每一个line临时变量,就记录了文件的一行数据
- 1
- 2
- 3
3.with open语法
with open("python.txt",'r') as f:
f.readlines()
#通过在with open的语句块中对文件进行操作
#可以在操作完成后自动关闭close文件,避免遗忘掉close方法
- 1
- 2
- 3
- 4
- 5

(3)文件的写入
#文件的写出操作
f = open('python.txt','w')
f.write('helloworld')
f.flush() #将缓冲区的内容写入到文件中
- 1
- 2
- 3
- 4
(4)文件的追加
#文件的写出操作
f = open('python.txt','a')
f.write('helloworld')
f.write('\n月薪过万')
f.flush() #将缓冲区的内容写入到文件中
- 1
- 2
- 3
- 4
- 5
21、python异常、模块和包
(1)捕获所有异常
try:
f = open("D:/123.txt","r")
except Exception as e:
print("出现异常了")
#结果 出现异常了
- 1
- 2
- 3
- 4
- 5
(2)finally:表示没有异常都要执行
try:
f = open("D:/123.txt","r",encoding = "UTF-8")
except Exception as e:
print("出现异常了")
f = open("D:/123.txt","w",encoding ="UTF-8")
else:
print("好高兴,没有异常")
finally:
print("我是finally,有没有异常我都要执行")
f.close()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
(3)异常的传递性
#异常的传递性 def func1(): print("func1 开始执行") num = 1/0 print("func1 结束执行") def func2(): print("func2 开始执行") func1() print("func2 结束执行") def main(): try: func2() except Exception as e: print(f"出现异常了,异常的信息是:{e}") main() #结果 func2 开始执行 func1 开始执行 出现异常了,异常的信息是:division by zero
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22

