
- 1Jinjia2-语法入门
- 2react+Antd表单用Form.Item互相校验_antd + vue循环form-item的校验并在其中一项给值后清除另一项的校验
- 3远程显示协议对比:RemoteFX vs. HDX vs. PCoIP
- 4【机器学习】特征选择之最小冗余最大相关性(mRMR)与随机森林(RF)_最小冗余最大相关matlab代码
- 5GPT SOVITS项目 一分钟克隆 (文字输出)
- 6python的异步编程async_python comm.spider_communal @async
- 7不归类
- 8明翰游戏学笔记V0.2(持续更新)
- 9Kubectl 常用命令, 开发人员常用k8s命令_kubectl delete job
- 10二十.python中的输入函数(两种方法)_python怎么输入函数
【机器学习】Python实现时间序列的分类预测
赞
踩
作者:Tinz Twins 来源:DeepHub IMBA
本文将以股票交易预测作为示例项目。我们用 AI 模型预测股票第二天是涨还是跌。在此背景下,比较了分类算法 XGBoost、随机森林和逻辑分类器。文章的另外一个重点是数据准备,我们必须如何转换数据以便模型可以处理它。
在本文中,我们将遵循 CRISP-DM 流程模型,以便我们采用结构化方法来解决业务案例。CRISP-DM 特别适用于潜在分析,通常在行业中用于构建数据科学项目。
另外就是我们将使用 Python 包 openbb。这个包以包含了一些来自金融部门的数据源,我们可以方便的使用它。
首先就是安装必须的库:
pip install pandas numpy “openbb[all]” swifter scikit-learn业务理解
首先应该了解我们要解决的问题, 在我们的例子中,可以将问题定义如下:
预测股票代码 AAPL 的股价第二天会上涨还是下跌。然后就是应该考虑手头有什么样的机器学习模型的问题。我们想预测第二天股票是上涨还是下跌。所以这是一个分类问题(1:股票第二天上涨或 0:股票第二天下跌)。在分类问题中,我们预测一个类别。在我们的例子中,是一个 0 类和 1 类的二元分类。
数据理解和准备
数据理解阶段侧重于识别、收集和分析数据集。第一步,我们下载 Apple 股票数据。以下是如何使用 openbb 执行此操作:
- data = openbb.stocks.load(
- symbol = 'AAPL',
- start_date = '2023-01-01',
- end_date = '2023-04-01',
- monthly = False)
- data
该代码下载 2023-01-01 和 2023-04-01 之间的数据。下载的数据包含以下信息:
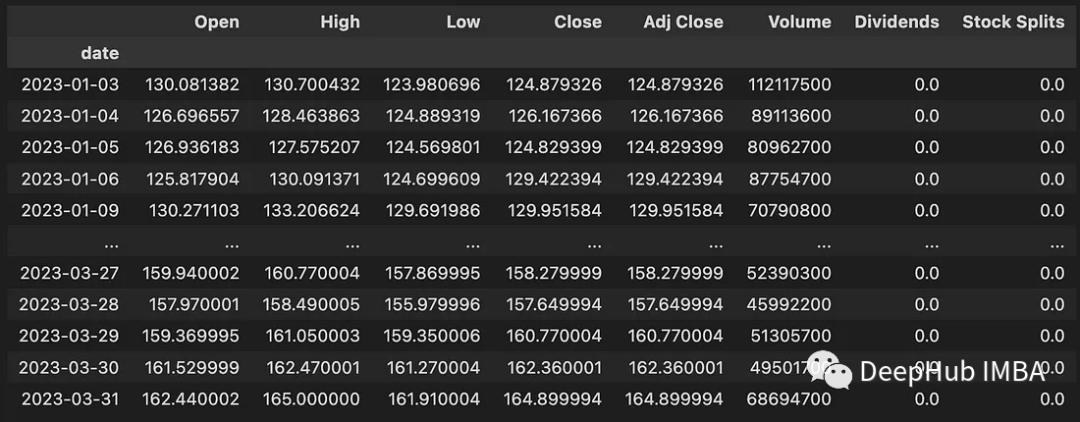
Open:美元每日开盘价
High:当日最高价(美元)
Low:当日最低价(美元)
Close:美元每日收盘价
Adj Close:与股息或股票分割相关的调整后收盘价
Volume:交易的股票数量
Dividends:已付股息
Stock Splits:股票分割执行
我们已经下载了数据,但是数据还不适合建模分类模型。所以仍然需要为建模准备数据。所以需要编写了一个函数来下载数据,然后对其进行转换以进行建模。以下代码显示了此功能:
- def get_training_data(symbol, start_date, end_date, monthly_bool=True, lookback=10):
- data = openbb.stocks.load(
- symbol = symbol,
- start_date = start_date,
- end_date = end_date,
- monthly = monthly_bool)
- data = get_label(data)
- data_up_down = data['up_down'].to_numpy()
- training_data = get_sequence_data(data_up_down, lookback)
- return training_data
这里面包含的第一个函数时get_label():
- def encoding(n):
- if n > 0:
- return 1
- else:
- return 0
- def get_label(data):
- data['Delta'] = data['Close'] - data['Open']
- data['up_down'] = data['Delta'].swifter.apply(lambda d: encoding(d))
- return data
他的主要工作是:计算收盘价和开盘价之间的差值。然后我们用 1 标记股价上涨的所有日期,股价下跌的所有日期都标记为 0。另外的up_down列包含股票价格在特定日期是上涨还是下跌。这里使用 swifter.apply() 函数替代 pandas apply()是因为 swifter 提供多核支持。
第二个函数是get_sequence_data()。参数 lookback 指定预测中包含过去多少天。get_sequence_data()代码如下 :
- def get_sequence_data(data_up_down, lookback):
- shape = (data_up_down.shape[0] - lookback + 1, lookback)
- strides = data_up_down.strides + (data_up_down.strides[-1],)
- return np.lib.stride_tricks.as_strided(data_up_down, shape=shape, strides=strides)
这个函数有两个参数:data_up_down 和 lookback。它返回一个新的 NumPy 数组,该数组表示具有指定窗口大小的 data_up_down 数组的滑动窗口视图,该窗口大小由 lookback 参数确定。为了说明这个函数是如何工作的,我们看一个小例子。
get_sequence_data(np.array([1, 2, 3, 4, 5, 6]), 3)结果如下:
- array([[1, 2, 3],
- [2, 3, 4],
- [3, 4, 5],
- [4, 5, 6]])
在下文中,我们下载 Apple 股票的数据并对其进行转换以进行建模。我们使用 10 天的回溯期。
- data = get_training_data(symbol = 'AAPL', start_date = '2023-01-01', end_date = '2023-04-01', monthly_bool = False, lookback=10)
- pd.DataFrame(data).to_csv("data/data_aapl.csv")
数据已经准备完毕了,我们开始建模和评估模型。
建模
将数据读入数据并生成测试和训练数据。
- data = pandas.read_csv("./data/data_aapl.csv")
- X=data.iloc[:,:-1]
- Y=data.iloc[:,-1]
- X_train, X_test, y_train, y_test = train_test_split(X, Y, test_size=0.33, random_state=4284, stratify=Y)
逻辑回归:
该分类器是基于线性的模型,通常用作基线模型。我们使用scikit-learn的实现:
- model_lr = LogisticRegression(random_state = 42)
- model_lr.fit(X_train,y_train)
- y_pred = model_lr.predict(X_test)
XGBoost 是为速度和性能而设计的梯度提升决策树的实现。它属于树提升算法,将许多弱树分类器依次连接。
- model_xgb = XGBClassifier(random_state = 42)
- model_xgb.fit(X_train, y_train)
- y_pred = model_xgb.predict(X_test)
随机森林:
随机森林构建多个决策树。这种方法称为集成学习,因为多个学习器是相互连接的,该算法属于bagging方法。首字母缩写词“bagging”代表引导聚合。 这里也使用scikit-learn的实现:
- model_rf = RandomForestClassifier(random_state = 42)
- model_rf.fit(X_train, y_train)
- y_pred = model_rf.predict(X_test)
评估
在对模型进行建模和训练之后,我们需要检查模型在测试数据上的性能。测量指标是 Recall、Precision 和 F1-Score。下表显示了结果。
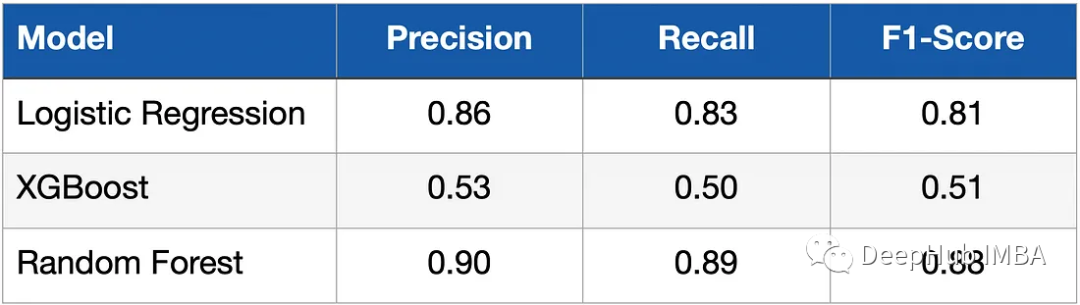
可以看到逻辑分类器(逻辑回归)和随机森林取得了明显优于XGBoost模型的结果, 这是什么原因呢?这是因为数据比较简单,只有几个维度的特征,并且数据的长度也很小,我们所有的模型也没有进行调优。
总结
我们这篇文章的主要目的是介绍如何将股票价格的时间序列转换为分类问题,并且演示如何在数据处理时使用窗口函数将时间序列转换为一个序列,至于模型并没有太多的进行调优,所以对于效果评估来说越简单的模型表现得就越好。

- 往期精彩回顾
-
-
-
-
- 适合初学者入门人工智能的路线及资料下载(图文+视频)机器学习入门系列下载机器学习及深度学习笔记等资料打印《统计学习方法》的代码复现专辑机器学习交流qq群955171419,加入微信群请扫码

