
- 1群晖(Synology)Plex 的服务找不到文件夹_plex 群晖 找不到电影
- 2【高并发优化手段】基于Springboot项目_springboot 并发调优
- 3Vue+ElementUI启动vue卡死的问题
- 4Type-C转HDMI线究竟有何妙用?乐得瑞Type-c转HDMI方案讲述_typec转hdmi
- 520年福州大学计算机录取名单,万满意20年福州大学法硕报考——连续3年录取名单分数线数据分析...
- 6C语言中关于文本文件的【回车】【换行】总结_c语言回车换行符怎么表示
- 7图解Janusgraph系列-并发安全,醍醐灌顶!_janusgraph zookeeper
- 8Wireshark 实验_在 cmd 中使用 ping 命令测试某一网站的连通性, 同时运行 wireshark 捕获对应的数
- 9艾萨克·牛顿
- 10进程控制:进程创建、等待、终止_2)熟悉进程的创建、控制、执行和终止等系统调用函数。
敲重点!最全大模型训练合集!
赞
踩

01
大模型训练总体架构
如何利用计算中心成千上百的AI加速芯片的集群,训练参数量超过百亿的大规模模型?并行计算是一种行之有效的方法,除了分布式并行计算相关的技术之外,其实在训练大模型的过程还会融合更多的技术,如新的算法模型架构和内存/计算优化技术等。
这篇文章梳理我们在大模型训练中使用到的相关技术点,主要分为三个方面来回顾现阶段使用多AI加速芯片训练大模型的主流方法。
-
分布式并行加速:并行训练主要分为数据并行、模型并行、流水线并行、张量并行四种并行方式,通过上述四种主要的分布式并行策略来作为大模型训练并行的主要策略。
-
算法模型架构:大模型训练离不开Transformer网络模型结构的提出,后来到了万亿级稀疏场景中经常遇到专家混合模型MoE都是大模型离不开的新算法模型结构。
-
内存和计算优化:关于内存优化技术主要由激活Activation重计算、内存高效的优化器、模型压缩,而计算优化则集中体现在混合精度训练、算子融合、梯度累加等技术上。
02
大模型训练的目标公式
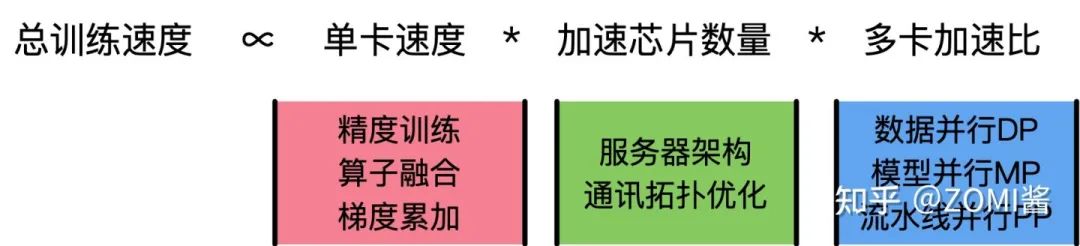
超大模型训练的总体目标就是提升总的训练速度,减少大模型的训练时间,你知道啦,毕竟训练一个大模型基本上从按下回车的那一刻开始要1到2个月,是很蛋疼的。下面主要看一下在大模型训练中的总训练速度的公式:

上面公式当中,单卡速度主要由单块AI加速芯片的运算速度、数据IO来决定;而加速芯片数量这个很清楚,数量越多增加训练速度;而多卡加速比则是有计算和通讯效率决定。
我们再把使用到技术跟这个公式关联在一起:
-
单卡速度:单卡速度既然是运算速度和数据IO的快慢来决定,那么就需要对单卡训练进行优化,于是主要的技术手段有精度训练、算子融合、梯度累加来加快单卡的训练性能。
-
加速芯片数量:理论上,AI芯片数量越多,模型训练越快。但是,随着训练数据集规模的进一步增长,加速比的增长并不明显。如数据并行就会出现局限性,当训练资源扩大到一定规模时,由于通信瓶颈的存在,增加计算资源的边际效应并明显,甚至增加资源也没办法进行加速。这时候需要通讯拓扑进行优化,例如通过ring-all-reduce的通讯方式来优化训练模式。
-
多卡加速比:多卡加速比既然由计算、通讯效率决定,那么就需要结合算法和集群中的网络拓扑一起优化,于是有了数据并行DP、模型并行MP、流水线并行PP相互结合的多维度混合并行策略,来增加多卡训练的效率。
总的来说呢,超大模型训练的目标就是优化上面的公式,提升总训练速度。核心思想是将数据和计算有关的图/算子切分到不同设备上,同时尽可能降低设备间通信所需的代价,合理使用多台设备的计算资源,实现高效的并发调度训练,最大化提升训练速度。
03
大模型训练的集群架构
这里的集群架构是为了机器学习模型的分布式训练问题。深度学习的大模型目前主要是在集群中才能训练出来啦,而集群的架构也需要根据分布式并行、深度学习、大模型训练的技术来进行合理安排。
在2012年左右Spark采取了简单直观的数据并行的方法解决模型并行训练的问题,但由于Spark的并行梯度下降方法是同步阻断式的,且模型参数需通过全局广播的形式发送到各节点,因此Spark的并行梯度下降是相对低效的。
2014年李沐提出了分布式可扩展的Parameter Server架构,很好地解决了机器学习模型的分布式训练问题。Parameter Server不仅被直接应用在各大公司的机器学习平台上,而且也被集成在TensorFlow,Pytroch、MindSpore、PaddlePaddle等主流的深度框架中,作为机器学习分布式训练最重要的解决方案之一。
目前最流行的模式有两种:
其中参数服务器主要是有一个或者多个中心节点,这些节点称为PS节点,用于聚合参数和管理模型参数。而集合通信则没有管理模型参数的中心节点,每个节点都是 Worker,每个Worker负责模型训练的同时,还需要掌握当前最新的全局梯度信息。
参数服务器模式
参数服务器架构Parameter Server,PS架构包括两个部分,首先是把计算资源分为两个部分,参数服务器节点和工作节点:
第二个部分就是把机器学习算法也分成两个方面,即1)参数和2)训练。
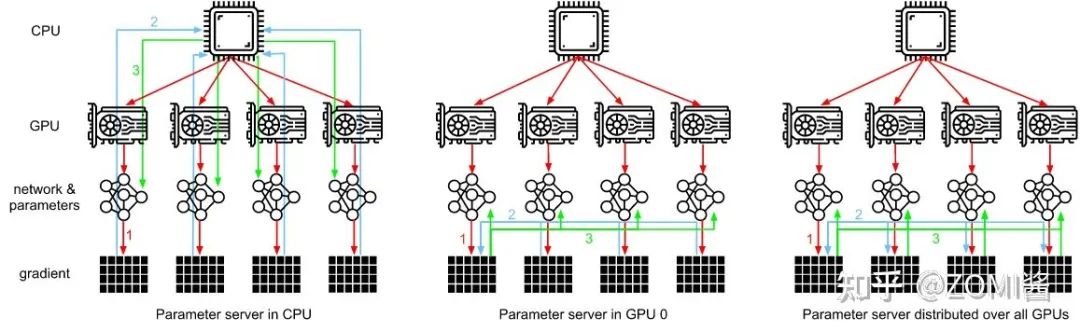
如图所示,PS架构将计算节点分为server与worker,其中,worker用于执行网络模型的前向与反向计算。而server则对各个worker发回的梯度进行合并并更新模型参数,对深度学习模型参数中心化管理的方式,非常易于存储超大规模模型参数。
但是随着模型网络越来越复杂,对算力要求越来越高,在数据量不变的情况下,单个GPU的计算时间是有差异的,并且网络带宽之间并不平衡,会存在部分GPU计算得比较快,部分GPU计算得比较慢。这个时候如果使用异步更新网络模型的参数,会导致优化器相关的参数更新出现错乱。而使用同步更新则会出现阻塞等待网络参数同步的问题。
GPU 强大的算力毋庸置疑可以提升集群的计算性能,但随之而来的是,不仅模型规模会受到机器显存和内存的制约,而且通信带宽也会由于集群网卡数量降低而成为瓶颈。
这个时候百度基于PS架构之上提出了Ring-All-Reduce新的通讯架构方式。

如图所示,通过异步流水线执行机制,隐蔽了 IO 带来的额外性能开销,在保证训练速度的同时,使训练的模型大小不再受制于显存和内存,极大提升模型的规模。而 RPC&NCCL 混合通信策略可以将部分稀疏参数采用 RPC 协议跨节点通信,其余参数采用卡间 NCCL 方式完成通信,充分利用带宽资源。
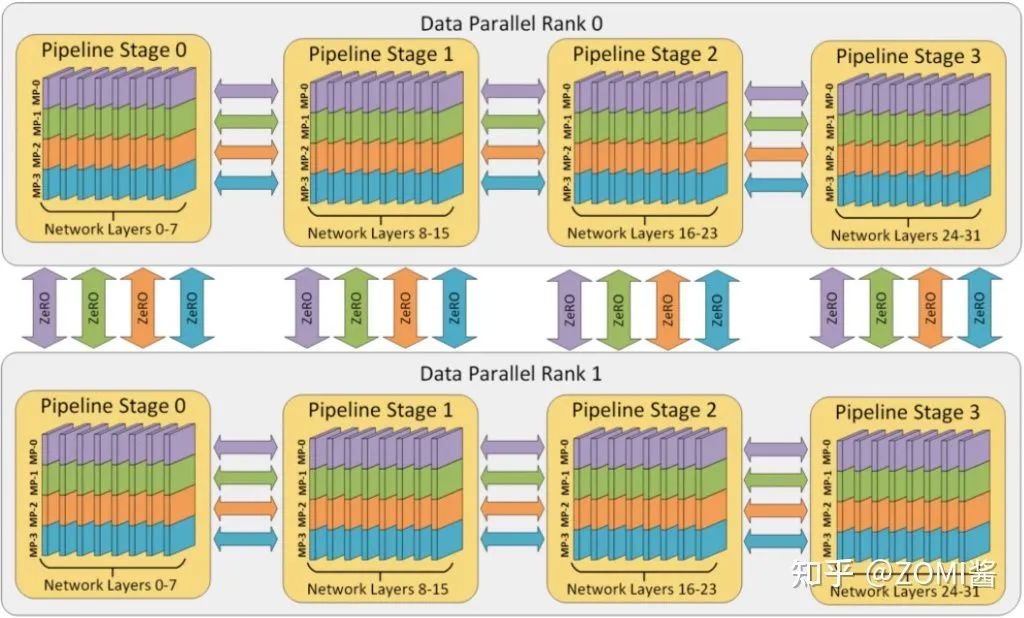
集合通讯模式
04
大模型训练相关论文
2022年学习大模型、分布式深度学习,不可能错过的AI论文,你都读过了吗?根据句上面的介绍,我们将会分为分布式并行策略相关的论文、分布式框架相关的论文、通讯带宽优化相关的论文等不同的维度对论文进行整理。并给出一个简单的解读,希望大家可以一起去分享好的思想。
分布式并行策略相关
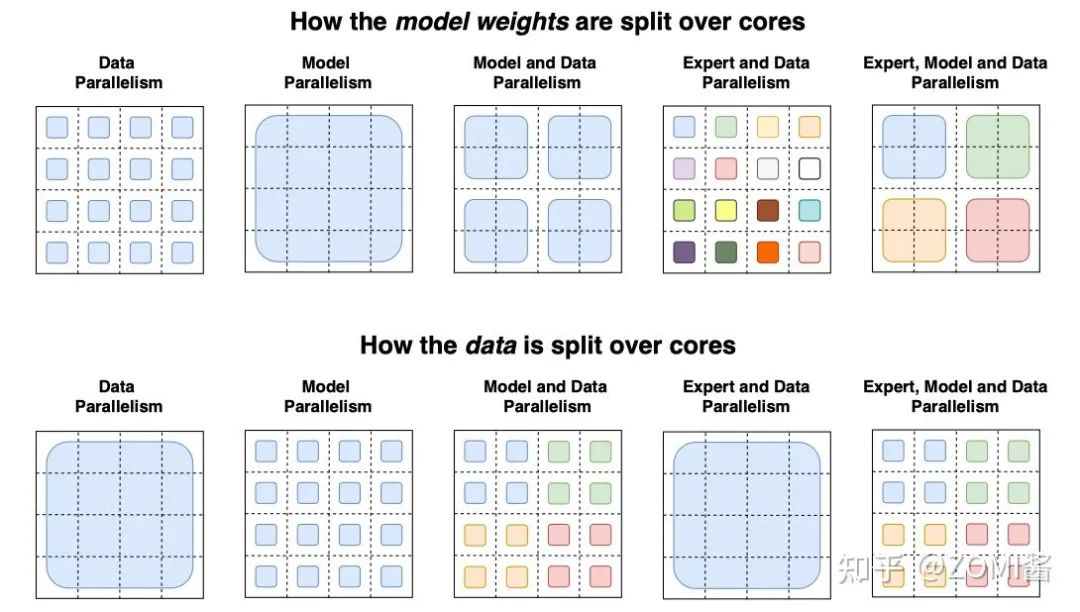
数据并行(Data Parallel,DP):数据并行训练加速比最高,但要求每个设备上都备份一份模型,显存占用比较高。
模型并行(Model Parallel,MP):模型并行,通信占比高,适合在机器内做模型并行且支持的模型类型有限。
流水线并行(Pipeline Parallel,PP):流水线并行,训练设备容易出现空闲状态,加速效率没有数据并行高;但能减少通信边界支持更多的层数,适合在机器间使用。
混合并行(Hybrid parallel,HP):混合并行策略的思想,集三种策略的优势于一身,实现取长补短。具体来说,先在单机内使用模型并行和分组参数切片组合的策略,这么选择的原因是这两个策略通信量较大,适合使用机器内的卡间通信。接着,为了承载千亿规模大模型,叠加流水线并行策略,使用多台机器共同分担计算。最后,为了计算和通讯高效,在外层又叠加了数据并行来增加并发数量,提升整体训练速度。这就是我们目前在AI框架中添加的并行策略,业界基本上都是使用这种方式。

并行相关的论文
下面就是并行相关的经典推荐论文,首先就是Jeff Dean在2012年的开创文章,然后介绍Facebook Pytroch里面使用到的数据并行中DDP、FSDP的策略。然而这并不够,因为有多重并行策略,于是NVIDIA推出了基于GPU的数据、模型、流水线并行的比较综述文章。实际上流水线并行会引入大量的服务器空载buffer,于是Google和微软分别针对流水线并行优化推出了GPipe和PipeDream。最后便是NVIDIA针对自家的大模型Megatron,推出的模型并行涉及到的相关策略。
- Large Scale Distributed Deep Networks.
2012年的神作,要知道那个时候神经网络都不多,这是出自于Google大神Jeff Dean的文章。主要是神经网络进行模型划分,因为推出得比较早,所以会稍微Naitve一点,但是作为分布式并行的开创之作,稍微推荐一下。
- Getting Started with Distributed Data Parallel.
- PyTorch Distributed: Experiences on Accelerating Data Parallel Training.
Facebook为Pytorch打造的分布式数据并行策略算法 Distributed Data Parallel (DDP)。与 Data Parallel 的单进程控制多 GPU 不同,在 distributed 的帮助下,只需要编写一份代码,torch 就会自动将其分配给n个进程,分别在 n 个 GPU 上运行。不再有主 GPU,每个 GPU 执行相同的任务。对每个 GPU 的训练都是在自己的过程中进行的。每个进程都从磁盘加载其自己的数据。分布式数据采样器可确保加载的数据在各个进程之间不重叠。损失函数的前向传播和计算在每个 GPU 上独立执行。因此,不需要收集网络输出。在反向传播期间,梯度下降在所有GPU上均被执行,从而确保每个 GPU 在反向传播结束时最终得到平均梯度的相同副本。
- Fully Sharded Data Parallel: faster AI training with fewer GPUs.
Facebook发布的FSDP(Fully Sharded Data Parallel),对标微软在DeepSpeed中提出的ZeRO,FSDP可以看成PyTorch中的DDP优化版本,本身也是数据并行,但是和DDP不同的是,FSDP采用了parameter sharding,所谓的parameter sharding就是将模型参数也切分到各个GPUs上,而DDP每个GPU都要保存一份parameter,FSDP可以实现更好的训练效率(速度和显存使用)。
- Efficient Large-Scale Language Model Training on GPU Clusters.
很好的一篇综述出品与NVIDIA,论文中, NVIDIA 介绍了分布式训练超大规模模型的三种必须的并行技术:数据并行(Data Parallelism)、模型并行(Tensor Model Parallelism)和流水并行(Pipeline Model Parallelism)。
- Automatic Cross-Replica Sharding of Weight Update in Data-Parallel Training.
在传统的数据并行中,模型参数被复制并在每次训练循环结束后被优化器更新。然而,当每个核的批量数不够大的时候,计算或许会变成一个瓶颈。例如,以MLPerf的BERT训练为例,在512个第三代TPU芯片上,LAMB优化器的参数更新时间可以占到整个循环时间的18%。Xu等人在2020年提出了参数更新划分技术,这种分布式计算技术首先执行一个reduce-scatter操作,然后使得每个加速器有整合梯度的一部分。这样每个加速器就可以算出相应的被更新的局部参数。在下一步,每个被更新的局部参数被全局广播到各个加速器,这样使得每个加速器上都有被更新的全局参数。为了获得更高的加速比,同时用数据并行和模型并行去处理参数更新划分。在图像分割模型中,参数是被复制的,这种情况下参数更新划分类似于数据并行。然后,当参数被分布后到不同的核之后,就执行多个并发的参数更新划分。

- PipeDream: Fast and Efficient Pipeline Parallel DNN Training.
微软研究院宣布了Fiddle项目的创立,其包括了一系列的旨在简化分布式深度学习的研究项目。PipeDreams是Fiddle发布的第一个侧重于深度学习模型并行训练的项目之一。其主要采用“流水线并行”的技术来扩展深度学习模型的训练。在 PipeDream 中主要克服流水线并行化训练的挑战,算法流程主要如下。首先,PipeDream 必须在不同的输入数据间,协调双向流水线的工作。然后,PipeDream 必须管理后向通道里的权重版本,从而在数值上能够正确计算梯度,并且在后向通道里使用的权重版本必须和前向通道里使用的相同。最后,PipeDream 需要流水线里的所有 stage 都花费大致相同的计算时间,这是为了使流水线得到最大的通量。
- GPipe: Easy Scaling with Micro-Batch Pipeline Parallelism.
GPipe是Google发明的论文,专注于通过流水线并行扩展深度学习应用程序的训练负载。GPipe 把一个L层的网络,切分成 K个 composite layers。每个composite layer 运行在单独的TPU core上。这K个 core composite layers只能顺序执行,但是GPipe引入了流水并行策略来缓解这个顺序执行的性能问题,把 mini-batch细分为多个更小的macro-batch,提高并行程度。GPipe 还用recomputation这个简单有效的技巧来降低内存,进一步允许训练更大的模型。
- Megatron-LM: Training Multi-Billion Parameter Language Models Using Model Parallelism.
- Efficient Large-Scale Language Model Training on GPU Clusters Using Megatron-LM.
出自NVIDIA,虽然这两篇文章都是在讲Megatron网络模型,实际上里面展开的都是模型并行等多维度并行的相关的技术点。其中第一篇论文共有两个主要的结论:1,利用数据和模型并行的分布式技术训练了具有3.9B参数的BERT-large模型,在GLUE的很多数据集上都取得了SOTA成绩。同时,还训练了具有8.3B参数的GPT-2语言模型,并在数据集Wikitext103,LAMBADA,RACE都上取得SOTA成绩。这篇论文,一方面体现了算力的重要性,另一方面体现了模型并行和数据并行技术关键性。这两项优化技术在加速模型训练和推断过程中至关重要。

05
大模型算法相关
必须了解的基础大模型结构
基础大模型结构基本上都是由Google贡献的,首先要看17年只需要Attention替代RNN序列结构,于是出现了第四种深度学习的架构Transformer。有了Transformer的基础架构后,在18年推出了BERT预训练模型,之后的所有大模型都是基于Transformer结构和BERT的预训练机制。后面比较有意思的就是使用Transformer机制的视觉大模型ViT和引入专家决策机制的MoE。
- Attention is all you need.
Google首创的Transformer大模型,是现在所有大模型最基础的架构,现在Transformer已经成为除了MLP、CNN、RNN以外第四种最重要的深度学习算法架构。谷歌在arxiv发了一篇论文名字教Attention Is All You Need,提出了一个只基于attention的结构来处理序列模型相关的问题,比如机器翻译。传统的神经机器翻译大都是利用RNN或者CNN来作为encoder-decoder的模型基础,而谷歌最新的只基于Attention的Transformer模型摒弃了固有的定式,并没有用任何CNN或者RNN的结构。该模型可以高度并行地工作,所以在提升翻译性能的同时训练速度也特别快。
- BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding.
Google发布的首个预训练大模型BERT,从而引爆了预训练大模型的潮流和趋势,这个不用介绍大家肯定有所听闻啦。BERT的全称为Bidirectional Encoder Representation from Transformers,是一个预训练的语言表征模型。它强调了不再像以往一样采用传统的单向语言模型或者把两个单向语言模型进行浅层拼接的方法进行预训练,而是采用新的masked language model(MLM),以致能生成深度的双向语言表征。BERT论文发表时提及在11个NLP(Natural Language Processing,自然语言处理)任务中获得了新的state-of-the-art的结果,令人目瞪口呆。
- An Image is Worth 16x16 Words: transformer for Image Recognition at Scale.
ViT Google提出的首个使用Transformer的视觉大模型,基本上大模型的创新算法都是出自于Google,不得不服。ViT作为视觉转换器的使用,而不是CNN或混合方法来执行图像任务。结果是有希望的但并不完整,因为因为除了分类之外的基于视觉的任务:如检测和分割,还没有表现出来。此外,与Vaswani等人(2017年)不同,与CNN相比,transformer 性能的提升受到的限制要大得多。作者假设进一步的预训练可以提高性能,因为与其他现有技术模型相比,ViT具有相对可扩展性。

- GShard: Scaling Giant Models with Conditional Computation and Automatic Sharding.
好像G开头的模型都是Google的了一样魔性。在 ICLR 2021 上,Google 的进一步将 MoE 应用到了基于 Transformer 的神经机器翻译的任务上。GShard 将 Transformer 中的 Feedforward Network(FFN)层替换成了 MoE 层,并且将 MoE 层和数据并行巧妙地结合起来。在数据并行训练时,模型在训练集群中已经被复制了若干份。GShard 通过将每路数据并行的 FFN 看成 MoE 中的一个专家来实现 MoE 层,这样的设计通过在多路数据并行中引入 All-to-All 通信来实现 MoE 的功能。
具有里程碑意义性的大模型
- GPT-3: Language Models are Few-Shot Learners.
OpenAI发布的首个百亿规模的大模型,应该非常具有开创性意义,现在的大模型都是对标GPT-3。GPT-3依旧延续自己的单向语言模型训练方式,只不过这次把模型尺寸增大到了1750亿,并且使用45TB数据进行训练。同时,GPT-3主要聚焦于更通用的NLP模型,解决当前BERT类模型的两个缺点:对领域内有标签数据的过分依赖:虽然有了预训练+精调的两段式框架,但还是少不了一定量的领域标注数据,否则很难取得不错的效果,而标注数据的成本又是很高的。对于领域数据分布的过拟合:在精调阶段,因为领域数据有限,模型只能拟合训练数据分布,如果数据较少的话就可能造成过拟合,致使模型的泛华能力下降,更加无法应用到其他领域。
- T5: Text-To-Text Transfer Transformer.
Google把T5简单的说就是将所有 NLP 任务都转化成Text-to-Text(文本到文本)任务。对于T5这篇论文,很Google的一篇文章啦,让我也很无力,毕竟财大气粗之外,还有想法,这就是高富帅。回到论文本身,T5意义不在烧了多少钱,也不在屠了多少榜,其中idea创新也不大,它最重要作用是给整个NLP预训练模型领域提供了一个通用框架,把所有任务都转化成一种形式。
- Swin Transformer: Hierarchical Vision Transformer using Shifted Windows.
微软亚研提出的Swin Transformer的新型视觉Transformer,它可以用作计算机视觉的通用backbone。在两个领域之间的差异,例如视觉实体尺度的巨大差异以及与文字中的单词相比,图像中像素的高分辨率,带来了使Transformer从语言适应视觉方面的挑战。

超过万亿规模的稀疏大模型
- Modeling Task Relationships in Multi-task Learning with Multi-gate Mixture-of-Experts.
Google发布的多任务MoE。多任务学习的目的在于用一个模型来同时学习多个目标和任务,但常用的任务模型的预测质量通常对任务之间的关系很敏感(数据分布不同,ESMM 解决的也是这个问题),因此,google 提出多门混合专家算法(Multi-gate Mixture-of-Experts)旨在学习如何从数据中权衡任务目标(task-specific objectives)和任务之间(inter-task relationships)的关系。所有任务之间共享混合专家结构(MoE)的子模型来适应多任务学习,同时还拥有可训练的门控网路(Gating Network)以优化每一个任务。
- Switch transformers: Scaling to trillion parameter models with simple and efficient sparsity.
Google重磅推出首个万亿参数的超大规模稀疏语言模型Switch Transformer。声称他们能够训练包含超过一万亿个参数的语言模型的技术。直接将参数量从GPT-3的1750亿拉高到1.6万亿,其速度是Google以前开发的语言模型T5-XXL的4倍。

06
内存和计算优化
最后就是优化方面的,其中主要是并行优化器、模型压缩量化、内存复用优化、混合精度训练等方面的优化,下面各列了几个最经典的文章。
- Accurate, Large Minibatch SGD: Training ImageNet in 1 Hour.
一篇17年关于优化器的老文章,文章的一个重要的结论很简单,就是一个线性缩放原则,但里面分析的不错,讲到了深度学习中很多基本知识的一个理解。本文从实验的角度进行细致的分析。虽然文章分析的是如何在更大的batch上进行训练,但同样的道理本文也可以用在像我一样的贫民党,当我们没有足够的GPU或者显存不足的时候到底该怎么调节一些参数。
内存优化相关论文:
- Training Deep Nets with Sublinear Memory Cost.
陈天奇这个名字可能圈内人都会比较熟悉了,在2016年的时候提出的,主要是对神经网络做内存复用。这篇文章提出了一种减少深度神经网络训练时内存消耗的系统性方法。主要关注于减少存储中间结果(特征映射)和梯度的内存成本,因为在许多常见深度架构中,与中间特征映射的大小相比,参数的大小相对较小。使用计算图分析来执行自动原地操作和内存共享优化。更重要的是,还提出了一种新的以计算交换内存的方法。
- Gist: Efficient data encoding for deep neural network training.
Gist是ISCA'18的一篇顶会文章,不算是新文章了,但是引用量在系统文章中算是非常高的,看完之后发现实验果然扎实,值得学习。主要思想还是围绕如何降低神经网络训练时候的显存使用量。Gist面向数据压缩,发掘训练模式以及各个层数据的特征,对特定数据进行不同方案的压缩,从而达到节省空间的目的。

- Adafactor: Adaptive learning rates with sublinear memory cost.
AdaFactor,一个由Google提出来的新型优化器,AdaFactor具有自适应学习率的特性,但比RMSProp还要省显存,并且还针对性地解决了Adam的一些缺陷。说实话,AdaFactor针对Adam所做的分析相当经典,值得我们认真琢磨体味,对有兴趣研究优化问题的读者来说,更是一个不可多得的分析案例。
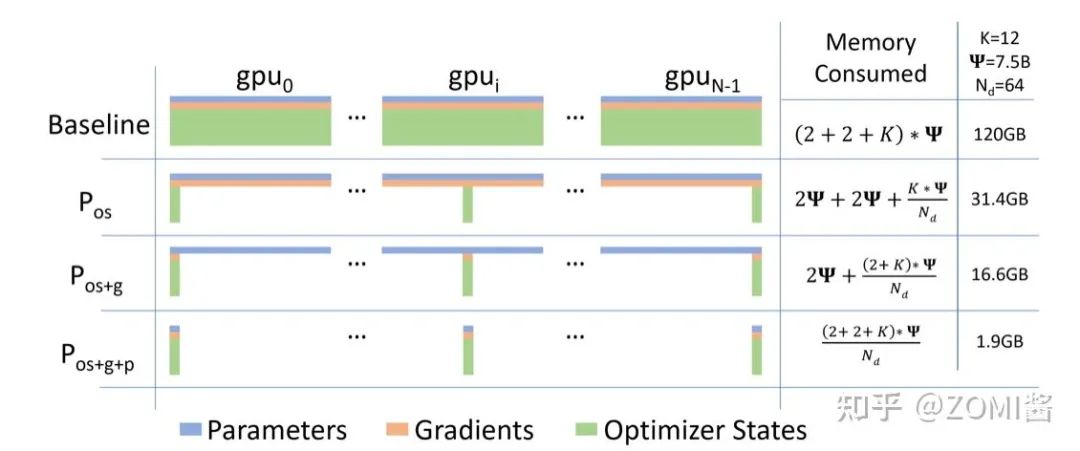
- ZeRO: Memory Optimization Towards Training A Trillion Parameter Models Samyam.
微软提出很经典很经典的一个算法了,为了这个算法还基于Pytroch开发了一个分布式并行DeepSpeed框架。现有普遍的数据并行模式下的深度学习训练,每一台机器都需要消耗固定大小的全量内存,这部分内存和并不会随着数据的并行而减小,因而,数据并行模式下机器的内存通常会成为训练的瓶颈。这篇论文开发了一个Zero Redundancy Optimizer (ZeRO),主要用于解决数据并行状态下内存不足的问题,使得模型的内存可以平均分配到每个gpu上,每个gpu上的内存消耗与数据并行度成反比,而又基本不影响通信效率。
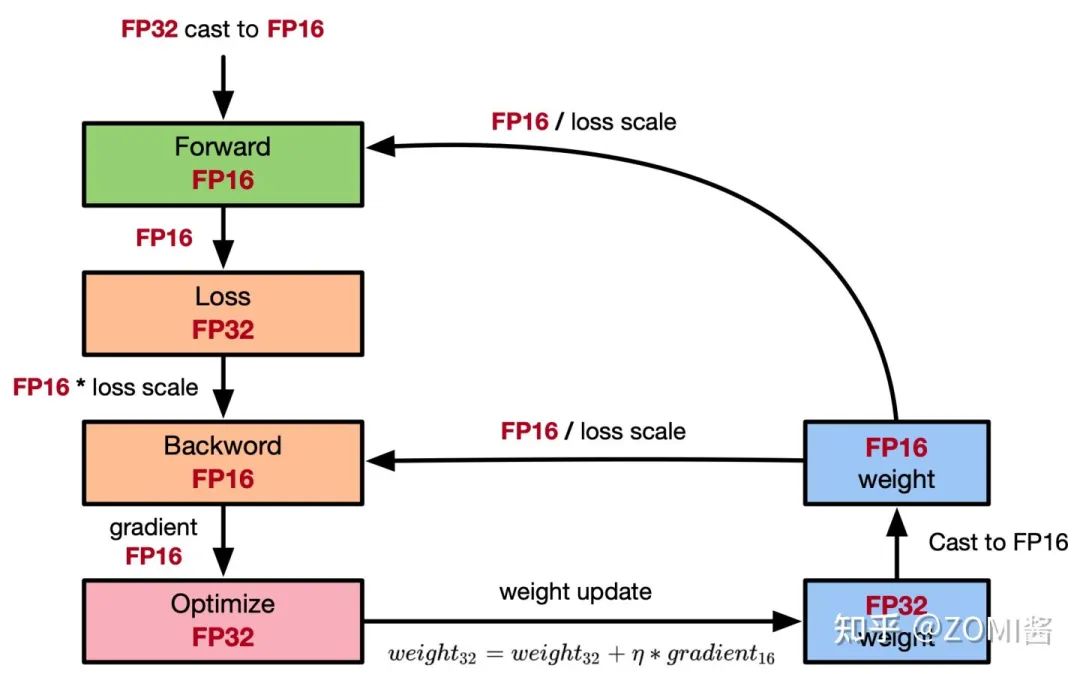
- Mixed precision training.
混合精度的文章,参考ZOMI酱写得全网最全-混合精度训练原理啦,里面的内容都在文章中。
底层系统架构相关
- Parameter Server for Distributed Machine Learning.
亚马逊首席科学家李沐在读书时期发表的文章。工业界需要训练大型的机器学习模型,一些广泛使用的特定的模型在规模上的两个特点:1. 深度学习模型参数很大,超过单个机器的容纳能力有限;2. 训练数据巨大,需要分布式并行提速。这种需求下,当前类似Map Reduce的框架并不能很好适合。于是李沐大神在OSDI和NIPS上都发过文章,其中OSDI版本偏向于系统设计,而NIPS版本偏向于算法层面。关于深度学习分布式训练架构来说是一个奠基性的文章。
- More Effective Distributed ML via a Stale Synchronous Parallel Parameter Server.
- GeePS: Scalable deep learning on distributed GPUs with a GPU-specialized parameter server.
分布式深度学习可以采用BSP和SSP两种模式。1为SSP通过允许faster worker使用staled参数,从而达到平衡计算和网络通信开销时间的效果。SSP每次迭代收敛变慢,但是每次迭代时间更短,在CPU集群上,SSP总体收敛速度比BSP更快,但是在GPU集群上训练,2为BSP总体收敛速度比SSP反而快很多。
- Bandwidth Optimal All-reduce Algorithms for Clusters of Workstations.
- Bringing HPC Techniques toDeep Learning.
百度在17年的时候联合NVIDIA,提出了ring-all-reduce通讯方式,现在已经成为了业界通讯标准方式或者是大模型通讯的方式。过去几年中,神经网络规模不断扩大,而训练可能需要大量的数据和计算资源。为了提供所需的计算能力,我们使用高性能计算(HPC)常用的技术将模型缩放到数十个GPU,但在深度学习中却没有充分使用。这种ring allreduce技术减少了在不同GPU之间进行通信所花费的时间,从而使他们可以将更多的时间花费在进行有用的计算上。在百度的硅谷AI实验室(SVAIL)中,我们成功地使用了这些技术来训练最先进的语音识别模型。我们很高兴将Ring Allreduce的实现发布为TensorFlow的库和补丁程序,并希望通过发布这些库,我们可以使深度学习社区更有效地扩展其模型。

MindSpore官方资料
GitHub : https://github.com/mindspore-ai/mindspore
Gitee : https : //gitee.com/mindspore/mindspore
官方QQ群 : 486831414

