
- 1antd upload 文件上传状态控制 与from 表单数据绑定 问题记录_antd的upload组件上传excel文件放在form表单提交拿不到文件
- 2输入正整数n求出前1-n整数和_编写一个程序,输入一个正整数n,输出前n个自然数之和。
- 3网页常见布局案例解析+代码_简单页面布局代码
- 4【循环神经网络系列】三、GRU_使用gru神经网络的结构
- 5python小波包分解_小波分解和小波包分解
- 6互联网大厂面经分享_值得买科技公司面试
- 7一、列表简介(1)_列表中必须有元素,不能为空,这句话对不对
- 8Mysql ERROR 1040: Too many connections连接数满_connect error (1040) too many connections
- 9oracle 复制工具类,oracle 常用工具类及函数
- 10flask各种版本的项目,终端命令运行方式的实现
使用pymupdf实现PDF内容搜索并显示功能_python 定位到pdf中关键词并高亮显示
赞
踩
简介:
在日常工作和学习中,我们可能需要查找和提取PDF文件中的特定内容。本文将介绍如何使用Python编程语言和wxPython图形用户界面库来实现一个简单的PDF内容搜索工具。我们将使用PyMuPDF模块来处理PDF文件,并结合wxPython构建一个用户友好的界面。
C:\pythoncode\new\pdffindcontent.py
准备工作
在开始之前,请确保已经安装了Python和相应的模块。可以使用pip来安装wxPython和PyMuPDF模块,具体安装方法可以参考官方文档。
创建GUI界面
我们首先需要创建一个GUI界面,以便用户选择要搜索的PDF文件并输入要查找的内容。我们使用wxPython库来创建界面。
def __init__(self, parent, title): super(PDFSearchFrame, self).__init__(parent, title=title, size=(800, 600)) panel = wx.Panel(self) vbox = wx.BoxSizer(wx.VERTICAL) # 选择文件按钮 file_picker = wx.FilePickerCtrl(panel, style=wx.FLP_OPEN|wx.FLP_FILE_MUST_EXIST) file_picker.Bind(wx.EVT_FILEPICKER_CHANGED, self.on_file_selected) vbox.Add(file_picker, 0, wx.EXPAND|wx.ALL, 10) # 输入框和按钮 hbox = wx.BoxSizer(wx.HORIZONTAL) self.search_text = wx.TextCtrl(panel) search_button = wx.Button(panel, label='搜索') search_button.Bind(wx.EVT_BUTTON, self.on_search) hbox.Add(self.search_text, 1, wx.EXPAND|wx.ALL, 5) hbox.Add(search_button, 0, wx.ALL, 5) vbox.Add(hbox, 0, wx.EXPAND|wx.ALL, 10) # 显示框 self.display_text = wx.TextCtrl(panel, style=wx.TE_MULTILINE|wx.TE_READONLY) vbox.Add(self.display_text, 1, wx.EXPAND|wx.ALL, 10) panel.SetSizer(vbox) self.Show()

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
在上述代码中,我们创建了一个名为PDFSearchFrame的窗口类,它继承自wxPython的wx.Frame类。在该类的构造函数中,我们创建了界面的各个组件,包括选择文件按钮、输入框和搜索按钮以及显示框。
PDF内容搜索和提取
接下来,我们需要在代码中添加PDF内容搜索和提取的功能。我们将使用PyMuPDF模块来处理PDF文件。
# 导入所需模块 import wx import fitz def on_search(self, event): search_text = self.search_text.GetValue() if not search_text or not self.pdf_path: return doc = fitz.open(self.pdf_path) matches = [] for page in doc: text = page.get_text().lower() if search_text.lower() in text: matches.append((page.number, text)) self.display_text.SetValue('') if matches: for page_num, text in matches: self.display_text.AppendText(f"Page {page_num}:\n{text}\n\n") else: self.display_text.AppendText("未找到匹配的内容。") doc.close()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
在上述代码中,我们在on_search方法中添加了PDF内容搜索和提取的代码。首先,我们使用fitz.open函数打开选择的PDF文件,并遍历每一页的文本内容。然后,我们将文本内容转换为小写,并检查搜索文本是否在其中。如果找到合适的匹配项,我们将它们存储在matches列表中。最后,我们将匹配的结果显示在显示框中,如果没有找到匹配的内容,则显示相应的提示信息。
全部代码
import wx import fitz class PDFSearchFrame(wx.Frame): def __init__(self, parent, title): super(PDFSearchFrame, self).__init__(parent, title=title, size=(800, 600)) panel = wx.Panel(self) vbox = wx.BoxSizer(wx.VERTICAL) # 选择文件按钮 file_picker = wx.FilePickerCtrl(panel, style=wx.FLP_OPEN|wx.FLP_FILE_MUST_EXIST) file_picker.Bind(wx.EVT_FILEPICKER_CHANGED, self.on_file_selected) vbox.Add(file_picker, 0, wx.EXPAND|wx.ALL, 10) # 输入框和按钮 hbox = wx.BoxSizer(wx.HORIZONTAL) self.search_text = wx.TextCtrl(panel) search_button = wx.Button(panel, label='搜索') search_button.Bind(wx.EVT_BUTTON, self.on_search) hbox.Add(self.search_text, 1, wx.EXPAND|wx.ALL, 5) hbox.Add(search_button, 0, wx.ALL, 5) vbox.Add(hbox, 0, wx.EXPAND|wx.ALL, 10) # 显示框 self.display_text = wx.TextCtrl(panel, style=wx.TE_MULTILINE|wx.TE_READONLY) vbox.Add(self.display_text, 1, wx.EXPAND|wx.ALL, 10) panel.SetSizer(vbox) self.Show() def on_file_selected(self, event): self.pdf_path = event.GetPath() def on_search(self, event): search_text = self.search_text.GetValue() if not search_text or not self.pdf_path: return doc = fitz.open(self.pdf_path) matches = [] for page in doc: text = page.get_text().lower() if search_text.lower() in text: matches.append((page.number, text)) self.display_text.SetValue('') if matches: for page_num, text in matches: self.display_text.AppendText(f"Page {page_num}:\n{text}\n\n") else: self.display_text.AppendText("未找到匹配的内容。") doc.close() if __name__ == '__main__': app = wx.App() PDFSearchFrame(None, title="PDF搜索") app.MainLoop()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
运行程序
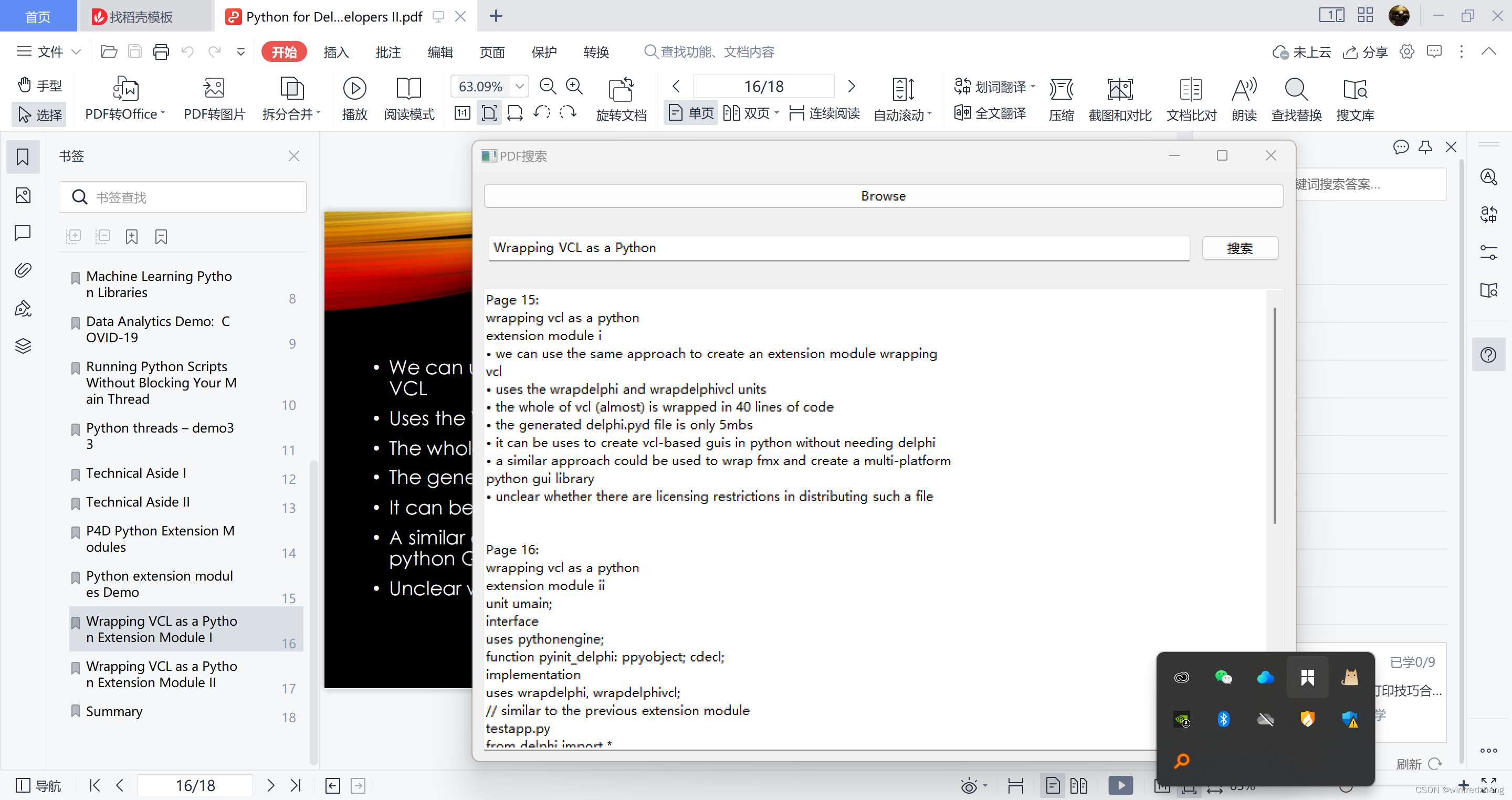
完成以上步骤后,我们可以保存并运行这个程序。一个具有搜索功能的PDF内容搜索工具的窗口将会弹出。我们可以选择要搜索的PDF文件,输入要查找的内容,并点击搜索按钮。程序将会将匹配的结果显示在显示框中,包括找到的页面号和相应的文本内容。
总结:
本文介绍了如何使用Python和wxPython库来实现一个简单的PDF内容搜索工具。通过结合PyMuPDF模块和wxPython图形界面,我们能够方便地选择PDF文件,并在输入框中输入要查找的内容。程序将搜索匹配的内容,并将找到的页面内容提取到显示框中。这个工具可以帮助我们快速查找和提取PDF文件中的特定内容,提高工作效率。
关键词:Python、wxPython、PDF、内容搜索、PyMuPDF


