
- 1Linux 复制命令cp
- 2ChatGPT的申请之路(2)_chatgpt continue with apple
- 32019年第十届C/C++ A组蓝桥杯省赛真题_2019蓝桥杯
- 4区块链基础知识(下):共识机制 附带图解、超详细教学 看不懂你打死我
- 5react开发者必备vscode插件【2024最新】_vscode react 插件
- 6计算机网络:传输控制协议(Transmission Control Protocol-TCP协议
- 740个flutter入门实例详解(一)_flutter 示例
- 8[附源码]java毕业设计酒店疫情防控系统_基于java的抗疫酒店管理系统毕业设计
- 9shell—for循环_shell for循环
- 10vm虚拟机vnc服务器 修改端口,如何在 vmware esxi 中开放 VNC功能及端口实现远程管理 完整篇(示例代码)...
开源模型Mistral 7B+Amazon SageMaker部署指南_mistral7b 需要多少内存
赞
踩
 一、Mistral 7B简述
一、Mistral 7B简述
Mistral AI 是一家总部位于法国的 AI 公司,其使命是将公开可用的模型提升至最先进的性能水平。他们专注于构建快速而安全的大型语言模型(LLM),此类模型可用于从聊天机器人到代码生成等各种任务。不久前其发布了一个开源模型Mistral 7B,支持英语文本生成任务并具备自然编码能力。它为实现低延迟进行过优化,并且相对其规模,该模型对内存的要求较低,可提供高吞吐量。该模型体积虽小,但功能强大,可支持从文本摘要和分类到文本完善和代码补全等多种使用案例。
Mistral 7B 的基础使用了 Transformer 的思想,其使用分组查询注意力和滑动窗口注意力来实现更快的推理(低延迟)并处理更长的序列。其中组查询注意力是一种结合了多查询和多头注意力的架构,以实现接近多头注意力的输出质量和与多查询注意力相当的速度。

滑动窗口注意力使用变压器的堆叠层来关注过去超出窗口大小的内容,以增加上下文长度。Mistral 7B 具有 8,000 个令牌的上下文长度,具有低延迟和高吞吐量,并且与较大的模型替代方案相比具有强大的性能,在 7B 模型大小下提供较低的内存要求,该模型在宽松的Apache 2.0 许可证下提供,可以不受限制地使用。
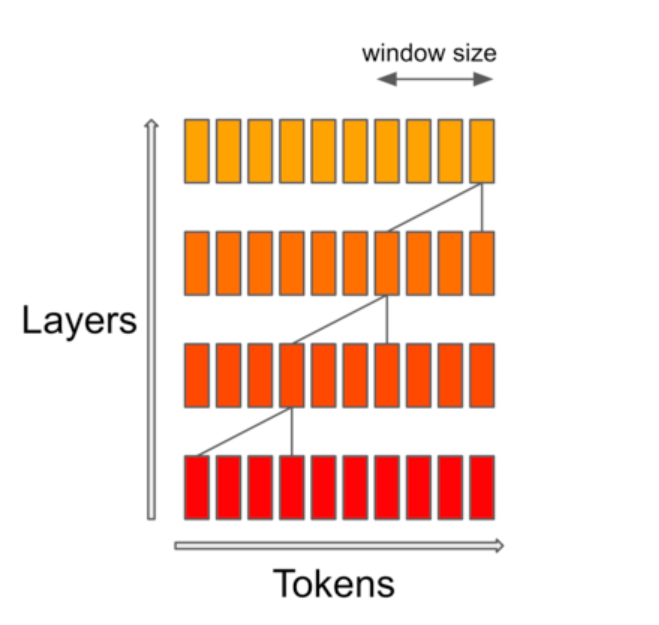
另外其还引入了稀疏专家组合Sparse Mixture of Experts (SMoE),Sparse Mixture of Experts (MoE)是允许通过仅激活每个token的整体模型的子集来将吞吐量与内存成本解耦的一种方法。这种方法的工作原理是将复杂的任务划分为更小、更易于管理的子任务,每个子任务都由专门的迷你模型或“专家”处理,在这种策略中,每个token被分配给一个或多个“专家”并且只由这些专家处理。其中:
-
专家层:较小的神经网络,经过训练,在特定领域具有很高的技能。每个专家处理相同的输入,但处理方式与其独特的专业相一致。
-
门控网络:这是MoE架构的决策者。它评估哪位专家最适合给定的输入数据。网络计算输入与每个专家之间的兼容性分数,然后使用这些分数来确定每个专家在任务中的参与程度。这些组件共同确保正确的专家处理正确的任务。
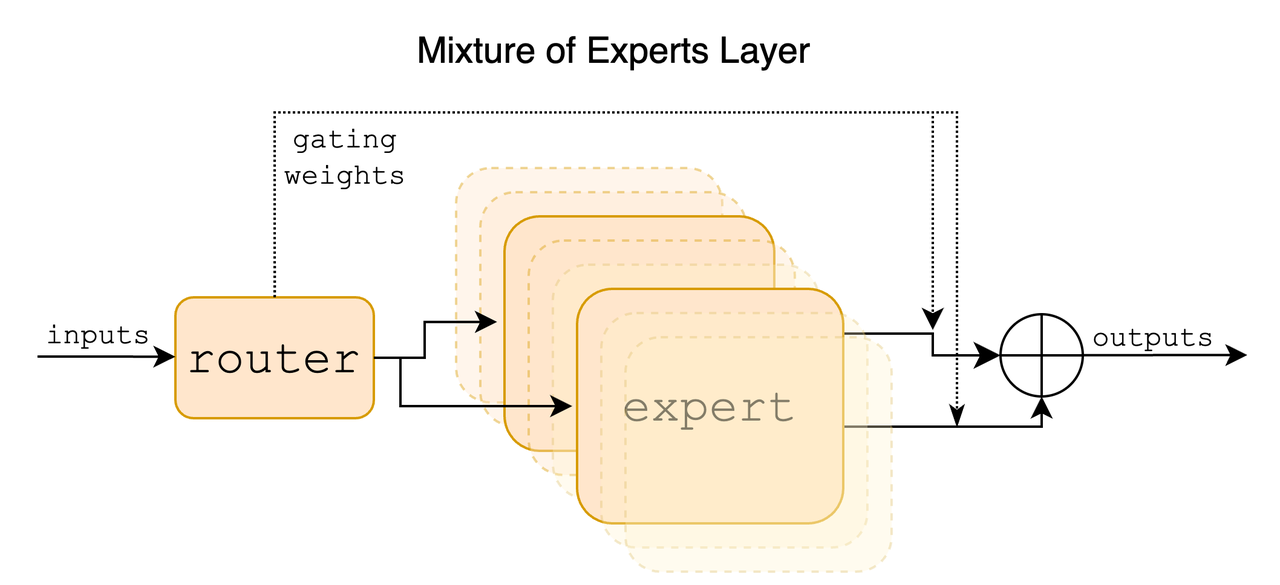
门控网络有效地将每个输入路由给最合适的专家,而专家则专注于他们的特定优势领域。这种协作培训带来了更加通用和强大的整体模型。
与其他模型相比,Mistral 7B具有:
-
在所有基准测试中优于Llama 2 13B
-
在许多基准测试中优于Llama 1 34B
-
在代码方面接近CodeLlama 7B的性能,同时在英语任务中表现良好
-
使用分组查询注意力(GQA)进行更快的推理
-
使用滑动窗口注意力(SWA)以更小的成本处理更长的序列
-
Apache 2.0许可证,可以无限制地使用。
二、使用Amazon SageMaker访问并部署Mistral 7B
现在已经可以通过Amazon SageMaker JumpStart一键部署由 Mistral AI 开发的 Mistral 7B 基础模型来运行推理,只需在Amazon SageMaker Studio中单击几下即可发现并部署 Mistral 7B,或者通过 SageMaker Python SDK 以编程方式发现和部署 Mistral 7B,从而利用Amazon SageMaker Pipelines、Amazon SageMaker Debugger或容器日志等 SageMaker 功能获得模型性能和 MLOps 控制。该模型部署在 AWS 安全环境中并受您的 VPC 控制,有助于确保数据安全。
首先进入SageMaker Studio 中:https://www.amazonaws.cn/sagemaker/studio/

访问 SageMaker JumpStart,进入 SageMaker JumpStart ,然后在Foundation Models: Text Generation carousel中找到Mistral 7B:
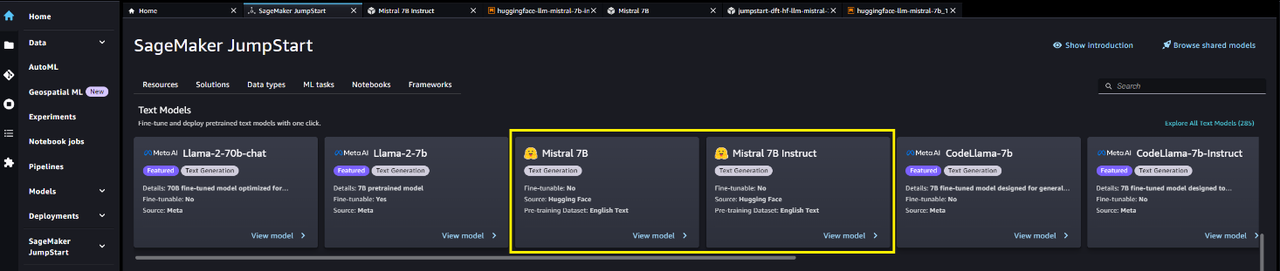
其次,选择模型卡来查看有关模型的详细信息,例如许可证、用于训练的数据以及如何使用。点击deploy开始部署。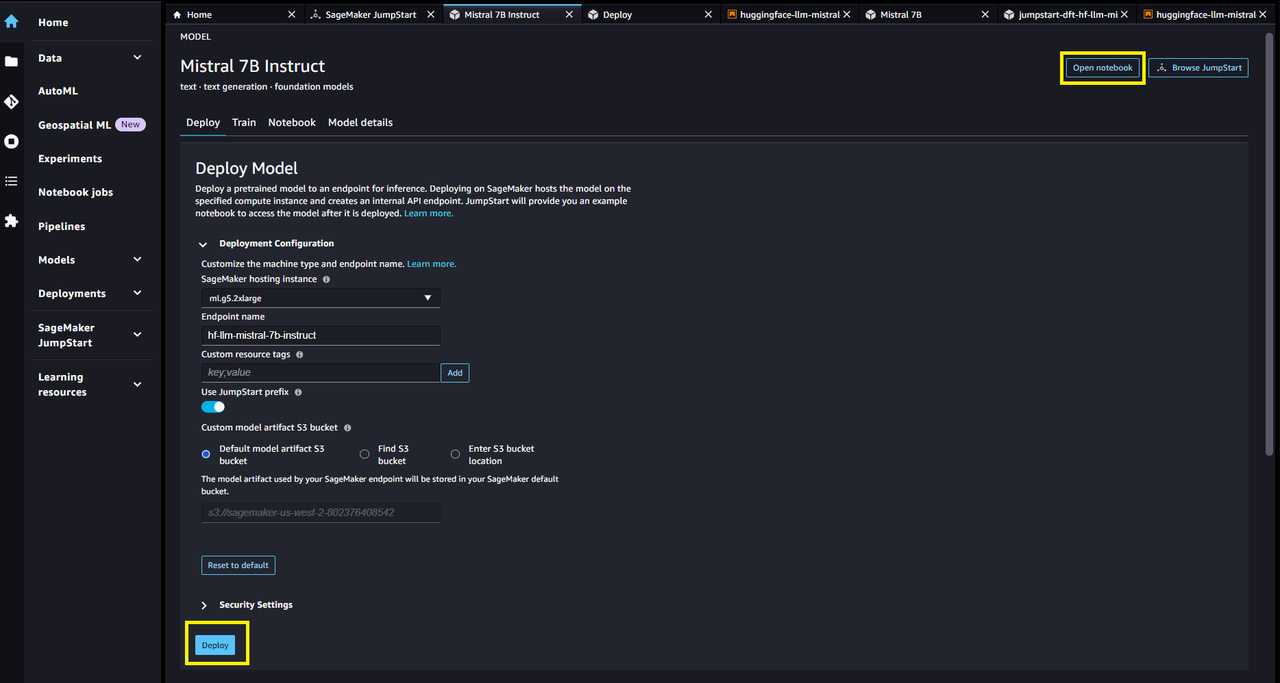
要使用笔记本进行部署,我们首先选择 Mistral 7B 模型,由model_id. 您可以使用以下代码在 SageMaker 上部署任何选定的模型:
- from sagemaker.jumpstart.model import JumpStartModel
- model = JumpStartModel(model_id="huggingface-llm-mistral-7b-instruct")
- predictor = model.deploy()
这会使用默认配置在 SageMaker 上部署模型,包括默认实例类型 (ml.g5.2xlarge) 和默认 VPC 配置。您可以通过在JumpStartModel中指定非默认值来更改这些配置。部署后,您可以通过 SageMaker 预测器对部署的终端节点运行推理:
- payload = {"inputs": "<s>[INST] Hello! [/INST]"}
- predictor.predict(payload)
另外,Mistral 7B 和 Mixtral 8x7B,很快将在 Amazon Bedrock 上推出,借助这两种 Mistral AI 模型,可以为使用案例灵活选择最优的高性能 LLM,在 Amazon Bedrock 上构建并扩展生成式 AI 应用程序。
参考资料:
官网:https://mistral.ai/news/announcing-mistral-7b/
https://generativeai.pub/mistral-ai-the-rising-star-in-conversational-ai-valued-at-2-billion-88d1b69d8fe0
仓库:https://github.com/mistralai/mistral-src
专家moe:https://zhuanlan.zhihu.com/p/674698482
钩子:https://mp.weixin.qq.com/s/XuWVdV90oDe0DOHjpT8zpw
![[ 云计算 | AWS 实践 ] Java 应用中使用 Amazon S3 进行存储桶和对象操作完全](https://img-blog.csdnimg.cn/direct/f6b4b45ef01445aa9a147e7c5f1a8f15.png?x-oss-process=image/resize,m_fixed,h_300,image/format,png)

