
- 1【学习笔记】《卓有成效的管理者》 第四章 如何发挥人的长处_卓有成效的管理者第四章如何发挥人的长处
- 240种顶级思维模型,学会任何1种都让你受用无穷,赶紧点赞收藏
- 3简单介绍agv仓储叉车基本原理及操作方法_agv叉车怎么行驶
- 4【自然语言处理】【大模型】BLOOM:一个176B参数且可开放获取的多语言模型_bloom-176b
- 5bottle微框架从注册到应用(一)———基础配置_bottle框架
- 6ETL第八章无人售货机零售项目实践_大数据etl——无人售货机零售项目实战
- 7OpenHarmony实战:小型系统平台驱动移植
- 8《青少年成长管理2024》016 “成长七要素之二:情感”2/4
- 9Azure OpenAI 语音转语音聊天_azure openai 语音转语音聊天 restful
- 10深度学习之前馈神经网络(前向传播和误差反向传播)
Vision-Language Models for Vision Tasks: A Survey
赞
踩
论文地址:https://arxiv.org/pdf/2304.00685.pdf
项目地址:https://github.com/jingyi0000/VLM_survey
一、综述动机
-
视觉语言模型,如CLIP,以其独特的训练方式显著简化了视觉识别任务的流程。它减少了对大量精细标注数据的依赖,使得研究者能够更高效地开展研究工作。
-
近年来,大量研究论文证明了研究者对视觉语言模型的浓厚兴趣。然而,目前尚缺乏一篇全面、系统的综述来梳理这一领域的研究进展、挑战和未来方向。因此,本文旨在填补这一空白,为研究者提供一个清晰、全面的视角。
二、为什么要用VLMs?
视觉识别范式的发展可以广泛地分为五个阶段,包括:
- Traditional Machine Learning and Prediction:使用手工设计的特征和传统机器学习算法进行训练和预测,需要大量的人工参与和专业知识.
- Deep Learning from Scratch and Prediction: 使用深度神经网络(DNN)进行端到端的训练和预测,和第一阶段相比,该范式使用DNN代替了人工设计的特征,实现了计算机视觉任务的巨大跨越。不过这方法需要大量标注数据,并且容易出现过拟合问题。
- Supervised Pre-training, Fine-tuning and Prediction:使用大规模标注数据进行监督式预训练,然后在特定任务上微调并进行预测。和第二阶段相比,该范式在用于特定任务时,可以通过微调的方式来更好地利用有限的标注数据。
- Unsupervised Pre-training, Fine-tuning and Prediction:使用无标注数据进行无监督式预训练,然后在特定任务上微调并进行预测。相比于第三阶段的监督式方法,更好地利用未标注数据。
- VLM Pre-training and Zero-shot Prediction:使用视觉-语言相关性进行大规模无监督式预训练,并且可以在各种视觉识别任务中进行零样本预测。和第四阶段相比,这种方法不需要针对特定任务进行微调即可取得出色的效果。
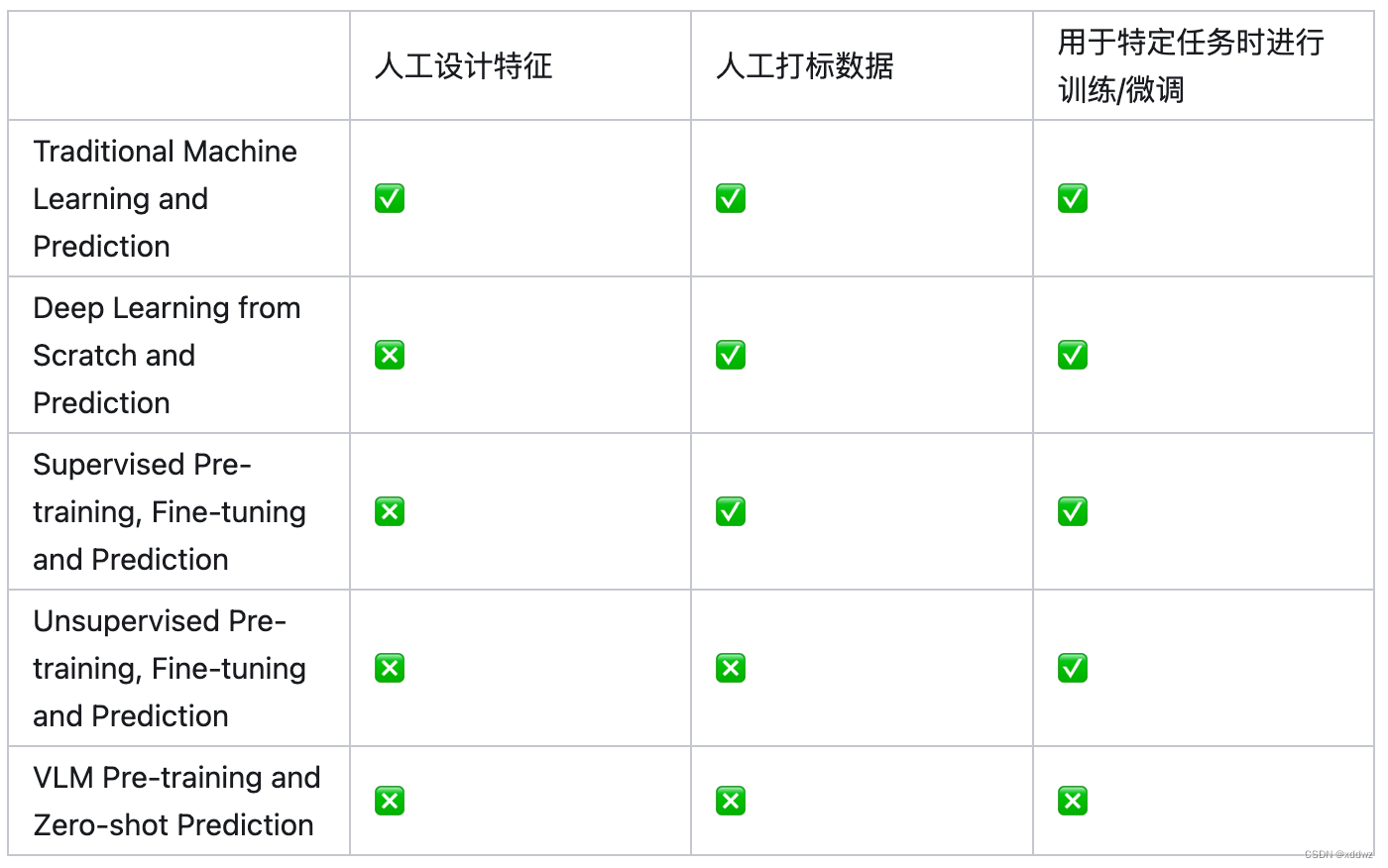
各个范式的演进过程就是一步步减少中间环节依赖(如人工设计特征、大量人工打标数据、用于特定任务时进行训练/微调)的过程,也是模型的泛化性逐渐提升的过程。VLM Pre-training and Zero-shot Prediction 的范式使得模型训练时不需要人工设计特征,也不需要海量打标数据,并且在用于下游任务时不需要针对特定任务进行微调,直接zero-shot就能取得不错的效果。能实现这一效果的关键就在于强大的预训练VLMs。
三、VLMs视觉语言模型预训练方法的总结与对比
目前主流的以CLIP为典型代表的Vision-Language Model(VLM)预训练方法可以大致分为3个关键模块:
- 文本特征提取模块,通常采用Transformer结构及其一系列变体作为基础结构。
- 图像特征提取模块,通常采用CNN(以ResNet结构为典型代表)或者Transformer(如ViT、MAE等结构)来提取图像特征。
- 特征融合模块
在VLM预训练模型中,最关键的问题是将文本和图像这两种模态的信息建立联系,所以下面对其中的特征融合模块做详细介绍。
特征对齐模块中,以目标函数进行分类的话,大致可以分为三类:
-
基于对比学习的方法(Pre-Training with Contrastive Objectives):也称对比式,这类方法通过对比学习来训练模型,使其在特征空间中能够将配对的图像和文本拉近,同时将不相关的样本推远。根据对比学习的输入类型,我们又可以进一步细分为基于图像对比学习、基于图像-文本对比学习和基于图像-文本-标签对比学习的方法。
-
基于生成任务的方法(Pre-training with Generative Objectives):也称生成式,这类方法通过训练模型进行图像生成、文本生成或跨模态生成来学习语义特征。它们可以进一步细分为基于掩码图像建模、基于掩码语言建模、基于掩码跨模态建模和基于图像到文本生成的方法。
-
基于对齐目的的方法(VLM Pre-training with Alignment Objectives):也称对齐式,这类方法旨在将图像和文本的特征进行匹配,包括全局的图像-文本匹配和局部的图像区域-单词匹配。
一些常见的VLM预训练方法如下图所示,从下图可以看出,典型的目标函数选择按照对应的方法数量多少可以分为以下几种:
- 纯对比式目标函数(18篇文章),以CLIP、ALIGN、SLI等为代表。
- 对比式和生成式相结合(6篇文章),以DeCLIP、FLAVA等为代表。
- 对比式和对齐式相结合(3篇文章),以FILIP、nCLIP、RegionClip。
- 纯对齐式(2篇文章),以GLIP、DetCLIP为代表。
- 纯生成式(1篇文章),以PaLI为代表。
对比式、生成式、对齐式大杂烩(1篇),以FIBER为代表。
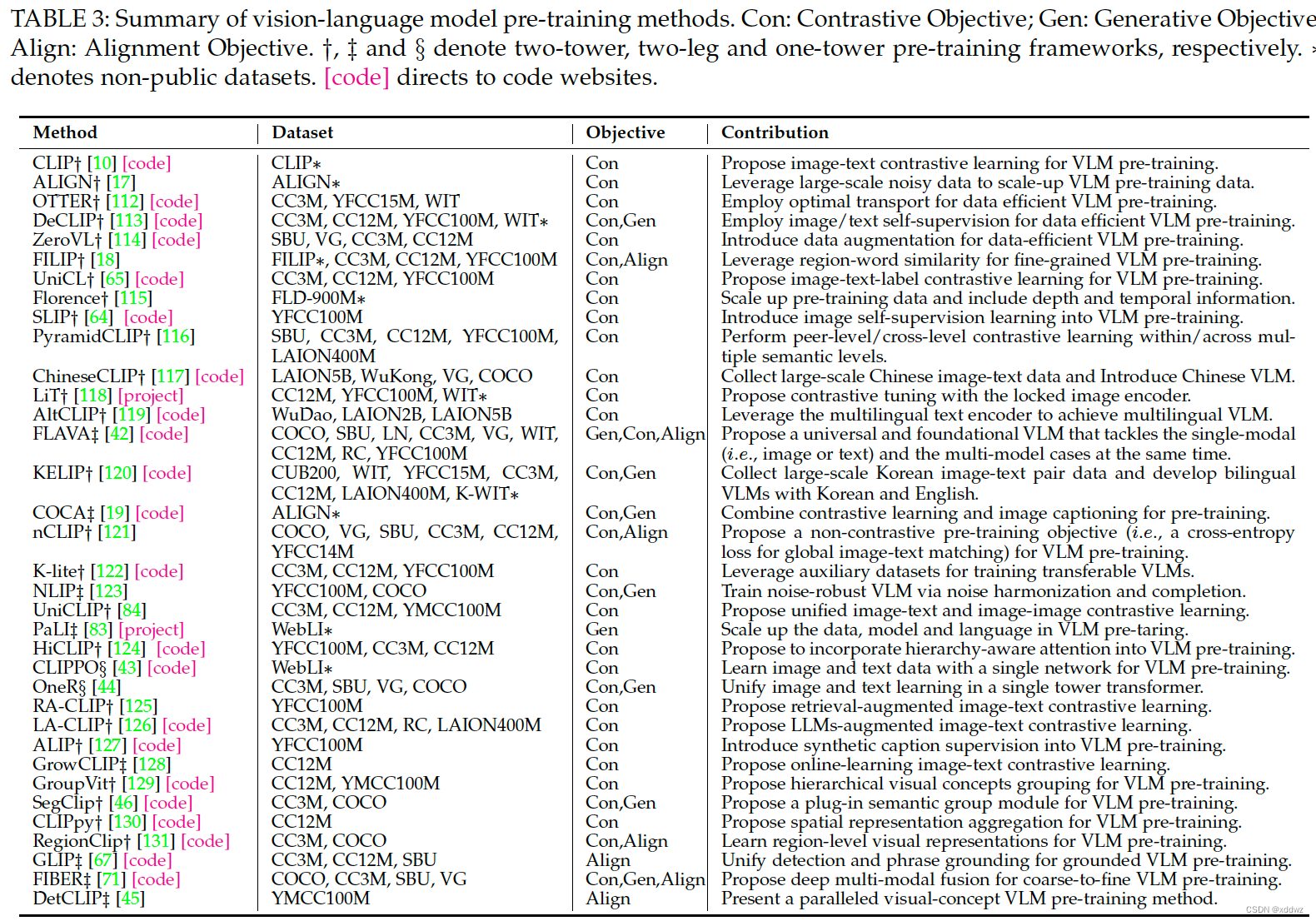
三种目标函数简介
1.对比式
对比式目标函数的目的是希望在特征空间使得正样本对之间的距离尽可能接近,而正负样本对之间的距离尽可能远。
VLM预训练中主要有以下三种模式的对比式目标函数:
Image Contrastive Learning
通常用InfoNCE及其变体作为图像对比学习的目标函数
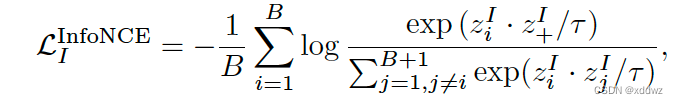
Image-Text Contrastive Learning
通常由两部分构成,一部分为图像特征到文本特征的InfoNCE,一部分为文本特征与其对应的图像的特征的InfoNCE,将这两者结合作为最终的损失函数。
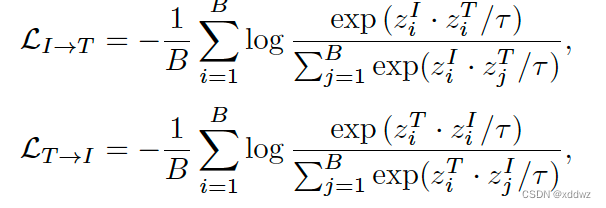
Image-Text-Label Contrastive Learning
在Image-Text Contrastive的基础上还需要加上label的信息,这里
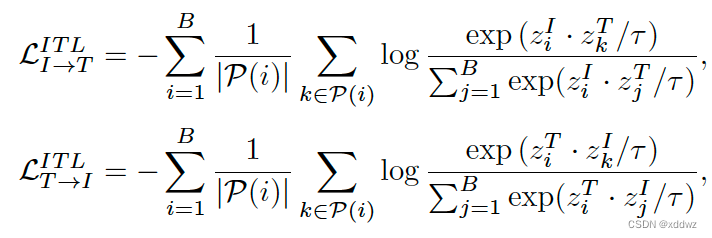
2.生成式
主要通过生成误差来建立损失函数,包括几种形式:
- Masked Image Modelling
- Masked Language Modelling
- Masked Cross-Modal Modelling
- Image-to-Text Generation
3.对齐式
通过在嵌入空间中进行全局Image-Text匹配或局部Region-Word匹配来对齐图像文本对。
- Image-Text Matching
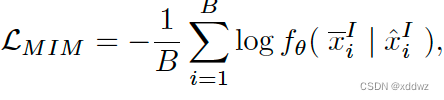
- Region-Word Matching
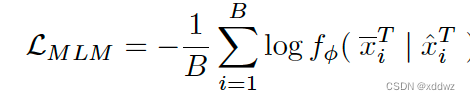
效果对比
这里主要目标是比较各个VLM预训练模型的能力,在所有任务(包括图像分类、分割、目标检测)上都是比较的zero-shot的结果。
预训练的VLM能够在下游任务中取得较好的zero-shot结果,具备优秀的泛化性能。这得益于三大因素:
-
- 大数据——采用图文对这种监督方式,更方便收集大量数据进行训练(如LiT中的4B数据和COCA中的4.8B数据),使得VLM具有强大的泛化能力;
- 大模型——与传统的视觉识别模型相比,VLM通常采用更大的模型(例如COCA中的ViT-G,有2B个参数),这些模型提供了足够的容量来有效地从大数据中学习;
- 任务无关学习——VLM预训练中的监督通常是通用和任务无关的。与传统视觉识别中的任务特定标签相比,图像文本对中的文本提供了任务无关、多样化和信息丰富的语言监督,有助于训练出适用于各种下游任务的可泛化模型。
四、视觉语言模型迁移方法的总结与对比
虽然预训练的Vision-Language Model有着较好的泛化性,可以直接zero-shot用于下游任务,不过距离完美的效果还有一定gap,主要表现在两个方面:
- 不同下游任务的图像及文本分布可能存在差异
- 训练目标的差异,预训练模型通常是训练通用的任务无关的特征,而特定的任务需要结合一些任务相关的目标。
总的来说,VLM预训练得到的模型算是知识面很广的全才,能在特定下游任务上取得比较好的结果,但是还没有成为这一任务的专家。如果能在VLM的基础上,通过迁移学习的方式针对不同的下游任务进行一些微调,便能够在各个子任务中取得更好的效果。以下是几种比较常见的迁移学习的方式。
因此,除了直接应用预训练的视觉语言模型进行零样本预测外,迁移学习也是提高模型性能的重要手段。本文总结了视觉语言模型的迁移学习方法,主要包括提示调整方法、特征适配器方法和其他方法。
-
提示调整方法(Prompt Tuning):受自然语言处理中“提示学习”的启发,这种方法通过调整模型的提示来适应下游任务,而无需对整个模型进行微调。提示调整方法包括文本提示调整、视觉提示调整和文本-视觉提示调整。
-
特征适配器方法(Feature Adapter):这类方法通过在视觉语言模型上添加轻量级的特征适配器来进行微调,以适应下游任务的特定需求。
-
其他方法:除了上述两种方法外,还有一些研究通过直接微调视觉语言模型、更改模型架构或其他创新手段来进行迁移学习。
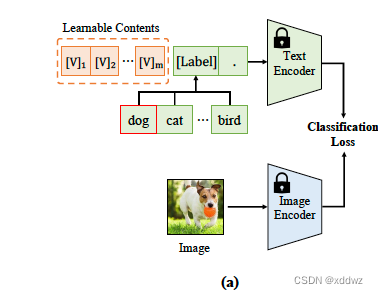
Text Prompt Tuning
顾名思义,这类方法主要在文本侧做文章,相比手动设计prompt或者进行prompt ensemble的方法,这类方法将text prompt部分设置为可学习的,然后结合特定任务的目标函数对prompt部分进行微。大致如下图所示:
Visual Prompt Tuning
和Text Prompt Tuning类似,不过这类方法是在图像侧施展拳脚,比如VP这篇论文加入了一个可学习的图像块,与原始图片像素级相加后作为Image Encoder的输入,并通过特定任务的目标函数进行学习。这种像素级别的调整对于dense类任务比较有效,比如目标检测、分割等。
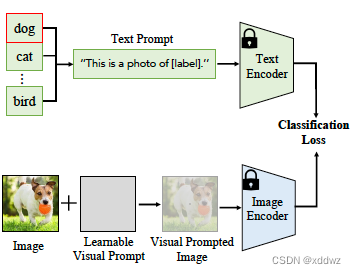
Text-Visual Prompt Tuning
既可以在文本侧做文章进行Prompt Tuning,又可以在图像侧进行Prompt Tuning,那么同时在图像和文本侧兜进行Prompt Tuning也是一件顺理成章的事情。
基于Feature Adaption进行迁移
prompt tuning主要是对输入的prompt(包括文本和图像)进行一些调整,而Feature Adaption方法主要是通过加入一个即插即用的“插件”的形式对特征进行调整。下图所示的方法就是一个典型的例子,图中的Feature Adapter结构可以设计成简单的多层感知机之类的网络去适配下游任务,同时加入残差连接的形式确保最差能退化到zero-shot的情况。这类方法的典型代表有Clip-Adapter、Tip-Adapter、SVL-Adapter。
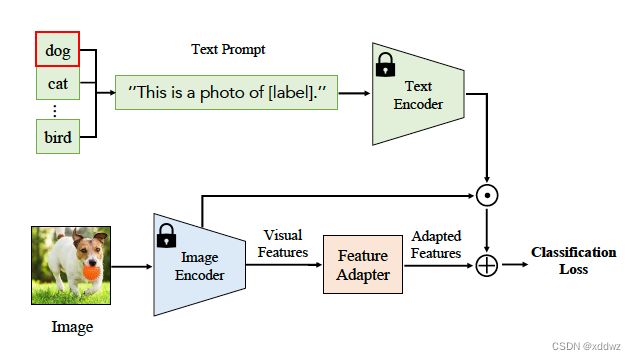
视觉语言模型知识蒸馏方法的总结与对比
视觉语言模型以其强大的视觉和文本概念理解能力,为复杂任务如目标检测和语义分割提供了新的解决思路。知识蒸馏作为一种有效的模型压缩和性能提升手段,在视觉语言模型的应用中发挥着关键作用。与视觉语言模型迁移方法不同,对视觉语言模型进行知识蒸馏的方法通常不受视觉语言模型架构的限制,并且大部分研究会利用当前最先进的检测或者分割架构的优势来达到更好的性能。在视觉语言模型的知识蒸馏方法中,本文根据应用场景的不同,将其分为两大类:开放词汇目标检测(Open-Vocabulary Object Detection)的知识蒸馏和开放词汇语义分割(Open-Vocabulary Semantic Segmentation)的知识蒸馏。
未来研究方向
在视觉语言模型的研究中,尽管已经取得了显著的进展,但仍有许多挑战和潜在的研究方向值得进一步探索。
对于视觉语言模型的预训练:
-
细粒度视觉语言关系建模:目前大多数视觉语言模型主要关注全局的图像-文本对应关系,但细粒度的视觉语言关系(如物体间的空间关系、属性关系等)对于理解图像内容同样至关重要。未来的研究可以探索如何更有效地建模这些细粒度关系,以进一步提升模型的性能。
-
统一视觉和语言特征的学习:Transformer的出现使得图像和文字可以通过相同的方式进行学习,这使得可以采用统一的Transformer架构处理图像和文字。与现有采用两个独立网络的视觉语言模型相比,统一视觉和语言学习可以实现跨模态的有效交流,并有效提升预训练的效率。
-
多语言和多文化的视觉语言模型:现有的视觉语言模型主要关注单一语言和文化背景下的图像理解。然而,随着全球化的发展,多语言和多文化的视觉语言理解变得越来越重要。未来的研究可以探索如何构建能够处理多种语言和文化背景的视觉语言模型,以满足更广泛的需求。
对于视觉语言模型的知识蒸馏,可以从两个方面进行探索。首先,可以同时对多个视觉语言模型进行知识蒸馏,通过协调多个视觉语言模型的知识蒸馏来获得更好的效果。其次,除了目标检测和语义分割等任务外,视觉语言模型的知识蒸馏还可以应用于其他视觉任务,如实例分割、姿态估计、视频理解等。未来的研究可以探索如何将这些方法扩展到更多的视觉任务中,以进一步提升视觉识别技术的性能和应用范围。
综上所述,视觉语言模型的研究仍具有广阔的前景和众多的挑战。未来的研究可以从预训练、迁移学习和知识蒸馏等多个方面进行深入探索,以推动视觉语言技术的发展和应用。

