
- 1自然语言处理 - GloVe_自然语言处理glove
- 2终于来了!这份NLP算法工程师学习路线yyds!
- 3基于Tensorflow 2.x手动复现BERT_bert模型tensorflow版本
- 4【Prompt】7 个向 chatGPT 高效提问的方法_如何高效向gpt提问
- 5【动手学深度学习-pytorch】 9.4 双向循环神经网络
- 6matlab数学建模转换成c语言,【数学建模】十二(最后一篇):MATLAB CUMCM真题求解实例三:机理建模型...
- 7HTML期末大作业~仿小米商城网页设计模板(HTML+CSS+JavaScript)_小米商城html+css+js源码
- 8毕业设计——基于卷积神经网络(CNN)进行影评特征分析的电影推荐系统设计与实现(融合PMF模型进行推荐)
- 9AB测试是什么,怎么做AB测试
- 10ShuffleNet: An Extremely Efficient Convolutional Neural Network for Mobile Devices论文学习
对象存储使用案例_新版UFile上线:ZB时代的量贩式对象存储
赞
踩
随着5G+IoT时代来临,产生数据的主角除了人类还有海量的物理设备,相比4G移动互联网的短视频、直播等,会有更大量的数据产生。据IDC发布的《数据时代2025》的预测,全球每年产生的数据将从2018年的33ZB增长到2025年的175ZB,每年新增约20ZB,如果使用8T的磁盘,只保存一份副本,每年需要25亿块磁盘,数亿台主机。
这些数据大多以视频、图片、文本等非结构化形式存在,并需要妥善保存以做后续利用。为此,数据的存储载体需要具备随时随地上传、安全、可扩展以及低成本的特性。目前,对象存储是这些海量非结构化数据最好的存储载体。
UFile:做Costco式的对象存储
UFile是UCloud 2015年推出的对象存储产品。过去一年间,UFile从整体上做了一次较大升级,推出不少功能特性和优化,更好地满足用户对海量非结构化数据的需求。这一过程中,UFile将其产品理念概括为“成为Costco式的存储”,为什么是Costco式的?
图:UFile控制台界面
前段时间量贩式仓储会员店Costco在国内火爆开业,在一个既不缺线下商超、同时线上电商更是遍地开花,市场竞争异常激烈的中国市场,Costco靠什么去切入用户?雷军是这么评价Costco的:“Costco这么多年所向披靡的最重要原因就是抓住了其存在的本质,商品做到极好,价格做到极低,服务做到超预期。”
这个理念也同样适用于对象存储领域,UFile把用户最本质的需求概括为3点:极高的可靠性和性能、极低的成本以及极优的体验。
对象存储的三个典型案例
在介绍UFile之前,我们先来看看AI、大数据和IoT场景下的3个案例:
1
某传统金属件加工企业原本有这样一项业务:员工人力摘捡不合格产品。现在,该项业务转变为拍照取证+AI智能检测的方式,相较之前大大节省了企业的人力投入成本,并降低了人工检测的误差。同时也产生了一项新需求:所有图片数据需保存25年以供后续质保检验。

用户的需求:如何保证数据长时间存储的高可靠需求?
2
某大数据分析企业积攒了数个PB的大数据,在完成分析后这些数据的访问量降到较低,但在一段时间内仍需存储保留原始数据或者分析后的中间数据。对企业来讲,这数PB的数据存储将会是一笔不小的开销。

用户的需求:如何实现海量数据的低成本存储需求?
3
某城市地铁每天停运后都需要人工沿地铁进行检修,效率较低且需要大量人力的投入。因此计划引入IoT技术:在地铁中部署一些传感器,检测地铁的声音、温度、图像、视频等,数据使用4G网络随时随地上传到云端存储,解决人力工作成本并提高检修效率。

用户的需求:这些分散在地下各处的传感器如何方便、安全、低延时的进行数据的上传?
我们总结了这三个案例的关键字:高可靠、低成本、使用体验,下面我们来详细介绍UFile在这三方面所做的工作。
一 、数据高可靠
1、多副本+同构的冗余机制
首先,UFile采用3副本和纠删码技术,可以确保数据在两块磁盘损坏的时候数据不丢失。不同于类似Ceph异构的数据分布技术,UFile 3副本技术采用同构的数据分布方式,这种同构的数据分布可以保证数据更高的可靠性。
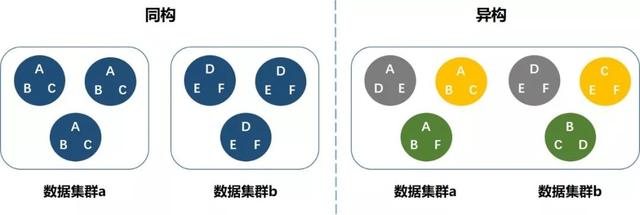
图:同构与异构数据分布对比
从上图可知,同构情况下只有集群a或者b同时损坏2种丢失数据的可能情况,而在异构结构下有6种丢失数据的组合情况,同构的可靠性显然更高。
2、跨地域的数据灾备
UFile是一个地域级别的存储产品,为了更好的提供数据灾备能力,UFile今年推出了跨地域的灾备功能:支持3个及以上的地域复制,复制方式包括链式结构(A->B->C)与技术实现更复杂的环式结构(A->B->C->A)。环状结构的优点是能够支持更多地域的读写,并满足就近读写业务的需求。
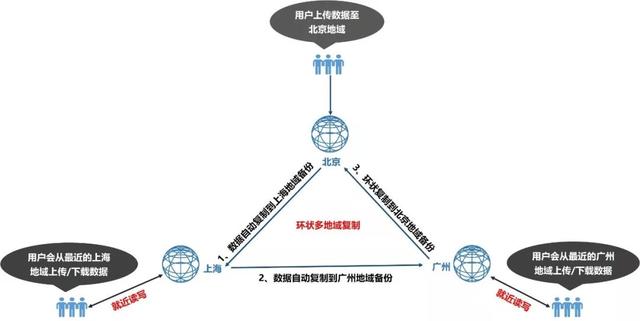
图:多地域复制及就近读写功能示意
3、故障处理机制的完善和创新
除此之外,UFile还在故障的快速发现和恢复上做了不少创新。除应用常规的硬件和软件层面的监控帮助用户快速发现数据异常外,UFile采用Set化的架构设计,当出现机器或磁盘故障时,可以将该Set集群设置为只读,从而降低该Set集群的业务负载,帮助恢复程序以最快的速度恢复故障磁盘或机器,大大提高数据的可靠性。
二 、业务低成本
1、对象级别的分层存储
UFile采用专门的存储机型,存储密度更高,单位存储的成本最低可降到计算机型的15%。同时采用纠删码技术,在确保数据可靠性的前提下,存储成本可降低到3副本冗余机制下的40%左右。
此外,UFile还对数据分层和数据生命周期管理进行了优化,致力于从数据分层存储的角度进一步降低用户存储的成本。
用户业务往往同时存在高频和低频访问的数据,而相同数据在不同生命周期也存在不同的访问频率。一个刚产生的高频访问的数据,随着时间的推移访问频率往往会逐渐减低,数个月后便可能从高频转为低频。不同访问频率的数据可采用不同成本的存储方案。
业内早期的解决方案是通过支持热、温、冷3种存储产品来满足不同频率访问数据的要求,用户分别在3种存储产品上创建Bucket,然后根据数据的访问频率放置到对应的Bucket。按照用户设置的时间规则,在不同时间点数据会在3种Bucket进行迁移。这种解决方案虽然解决了数据存储的成本问题,但是缺点在于对业务不太友好,需要业务感知这种变化。
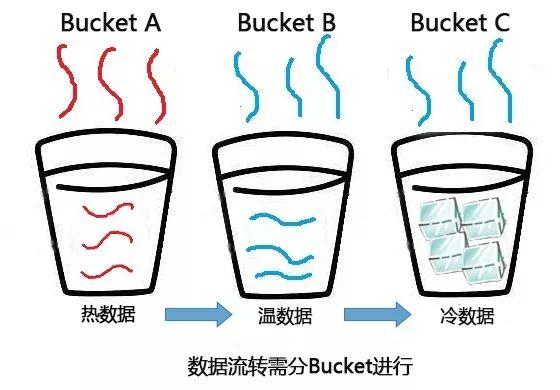
图:传统的分层存储数据流转示意
针对该问题,UFile在今年推出了对象级别的分层存储方案。和传统解决方案不一样的是,UFile支持同个Bucket中同时存在热、温、冷3种数据,用户可以将同个业务中的3种数据上传到同个Bucket,同时数据访问频率发生变化后还会保留在同个Bucket中。
这种方案对用户的业务更加友好,而且也为后续即将推出的数据自动化分层管理奠定了良好的基础。用户很多时候无法区分数据的冷、热程度,或者无法准确的预测数据什么时候开始变冷,而更好的做法是将这些工作交给后台程序自动完成,这样可以让用户享受到最低的存储成本。
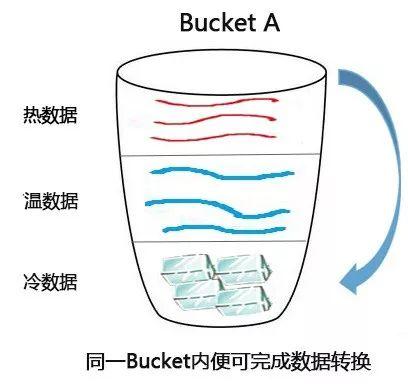
图:UFile分层存储方案数据流转示意
2、自建大数据存储与UFile归档存储的成本对比
我们回到开头的大数据用户的场景,该企业现有5PB的数据量,因为用户的数据访问频率较低,所以推荐采用UFile的归档存储方案,下表是使用自建大数据存储和UFile归档存储方案成本差异对比。
UFile归档存储
自建大数据存储
规格按需存储、无限扩展,采用EC技术,两块磁盘损坏下数据仍能保证可靠
购买多台UCloud容量型机型(磁盘最大的一款机型,单机48T)
计费标准0.03元/GB/月0.1元/GB/月1年的花销180万元/年单副本:600万元/年
三副本:1800万元/年
可节省成本
单副本:420万元/年三副本:1620万元/年
事实上,我们还没有考虑数据逐渐增长的过程,对象存储是按需付费的,实际使用多少资源才会支付多少费用,而自建大数据存储往往会存在资源和成本的空闲浪费。因此,针对海量数据的冷存储,UFile归档存储方案能够提供更高的性价比。
三 、产品体验优化
1、数据安全+高质量网络保证
移动设备和IoT设备都有随时随地上传的需求,而随时随地的上传则对数据安全和网络质量都提出了更高的要求。
针对该需求,首先UFile支持Https协议,支持用户使用公私钥或者Token的方式来随时随地的传输数据、确保数据的安全性。
其次,UFile已在全球10多个国家和地区分布有节点,覆盖国内主要城市和国外主要国家,按照规划UFile后续还将覆盖到更多地区和国家。国内外的数据节点均采用BGP机房或者运营商节点机房,能够提供高质量的网络保障,确保用户数据上传过程中的稳定和低延时。
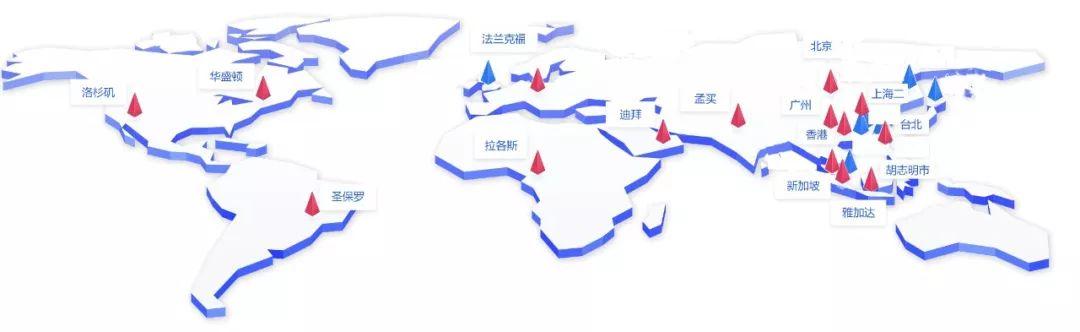
图:UFile全球数据中心分布
2、用户接入体验优化
目前UFile的SDK覆盖了主流的开发语言,并分别支持iOS和Android移动端。同时UFile还兼容了常用的S3协议,支持第三方用户态网络文件系统访问UFile,如S3fs、Goofys,这样用户可以像使用本地文件系统一样使用对象存储。相比本地文件系统,以UFile为存储池的用户态网络文件系统可以为用户带来更大的存储空间和更低的存储成本。
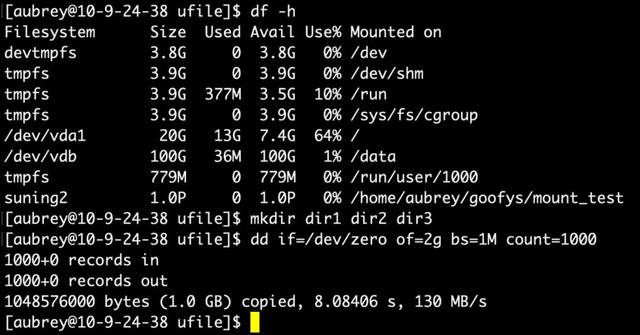
图:通过Goofys把某个Bucket挂载成文件系统并操作
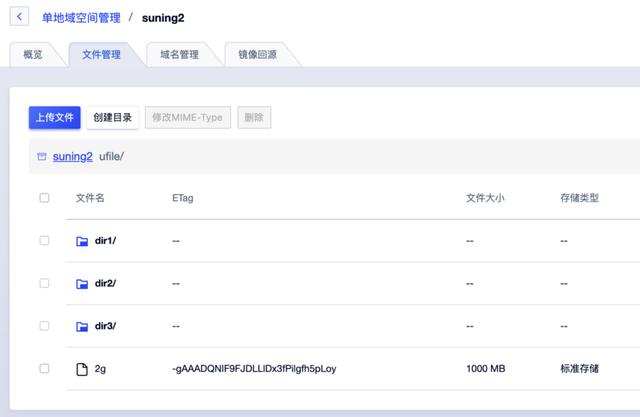
图:通过Goofys写UFile后的效果
3、各类应用场景下的定制化解决方案
此外,UFile还提供了各类常用应用场景和备份场景的定制化解决方案:
- 针对多媒体场景,UFile结合UCloud全球500多个CDN节点,给用户提供高质量的视频和图片类服务。
- 针对大数据场景,UFile推出了计算存储分离的方案,使用UFile来替代HDFS,计算层只需修改配置文件即可完成替换。
- 在UCloud今年推出的重量级数据分析产品USQL中便采用了计算存储分离的解决方案,对计算和存储都采用按需计费的方式,大大降低了大数据分析的成本。同时USQL依托于UFile强大的IO能力,以及无限存储容量,实现了海量数据的快速分析。
- 针对备份类的场景,UFile提供了Hadoop 冷数据备份场景、MySQL 数据库备份和恢复场景、ES 日志备份的场景、网站文件备份场景等解决方案,帮助用户轻松完成数据备份。
Hadoop 冷数据备份场景实例分析:
Step1
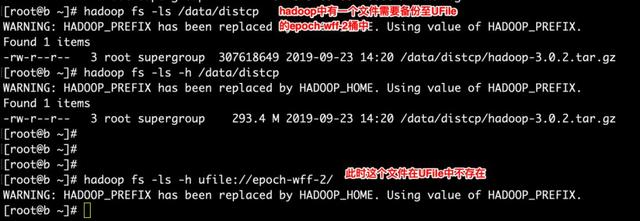
图:Hadoop集群中的文件在UFile的某个Bucket中不存在
Step2
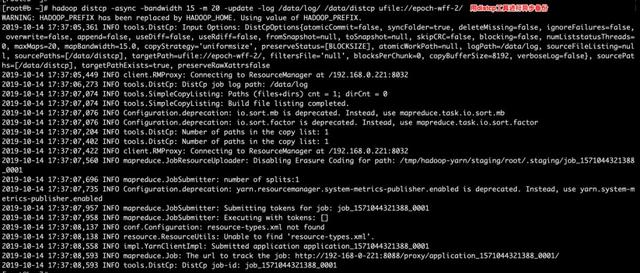
图:通过distcp工具备份至UFile的某个Bucket中
Step3
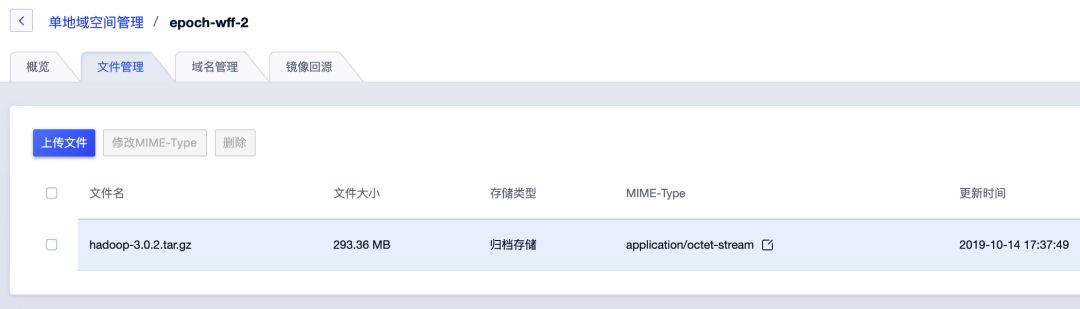
图:备份成功后可以在UFile控制台看到该文件
结语
最后,针对海量非结构化数据,除了数据高可靠、低成本以及良好的使用体验,还有一个非常重要的需求便是高性能。特别是在引入生命周期和目录功能后的列表查询场景以及类似网络摄像头的大量写入及删除类的场景,对索引和存储的性能提出较大的挑战。
UFile目前已经上线了目录功能和生命周期功能,大批量删除的性能也相比以往有较大的提升。后期我们还将专门介绍这两类场景下索引和存储的优化工作,敬请期待。



