
- 1Kmeans和谱聚类算法(python实现sklearn)_kmeans python sklearn
- 2颜色的十六进制编码_荧光黄十六进制
- 3HarmonyOS应用开发者高级认证--96分
- 4Vision-Language Models for Vision Tasks: A Survey
- 5分布式关系数据库中间件swiftdb (类似mycat、cobar中间件)_swift中间件
- 635岁程序员的职业分水岭:挑战还是机遇?
- 7机器学习的特征选择方法
- 8谈谈甲方视角下网络安全产品及安全建设_甲方安全产品运营
- 9宝塔快速反代openai官方的API接口,实现国内调用open ai_openai反向代理
- 10数据分析三件客 numpy,pandas,matplotlib的简单介绍-numpy模块_numpy、pandas、matplotlib
【动手学深度学习-pytorch】 9.4 双向循环神经网络
赞
踩
在序列学习中,我们以往假设的目标是: 在给定观测的情况下 (例如,在时间序列的上下文中或在语言模型的上下文中), 对下一个输出进行建模。 虽然这是一个典型情景,但不是唯一的。 还可能发生什么其它的情况呢? 我们考虑以下三个在文本序列中填空的任务。
我___。
我___饿了。
我___饿了,我可以吃半头猪。
根据可获得的信息量,我们可以用不同的词填空, 如“很高兴”(“happy”)、“不”(“not”)和“非常”(“very”)。 很明显,每个短语的“下文”传达了重要信息(如果有的话), 而这些信息关乎到选择哪个词来填空, 所以无法利用这一点的序列模型将在相关任务上表现不佳。 例如,如果要做好命名实体识别 (例如,识别“Green”指的是“格林先生”还是绿色), 不同长度的上下文范围重要性是相同的。 为了获得一些解决问题的灵感,让我们先迂回到概率图模型。
双向模型
如果我们希望在循环神经网络中拥有一种机制, 使之能够提供与隐马尔可夫模型类似的前瞻能力, 我们就需要修改循环神经网络的设计。 幸运的是,这在概念上很容易, 只需要增加一个“从最后一个词元开始从后向前运行”的循环神经网络, 而不是只有一个在前向模式下“从第一个词元开始运行”的循环神经网络。 双向循环神经网络(bidirectional RNNs) 添加了反向传递信息的隐藏层,以便更灵活地处理此类信息。 图9.4.2描述了具有单个隐藏层的双向循环神经网络的架构。
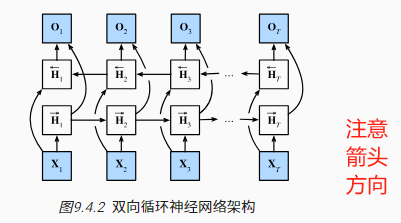
定义
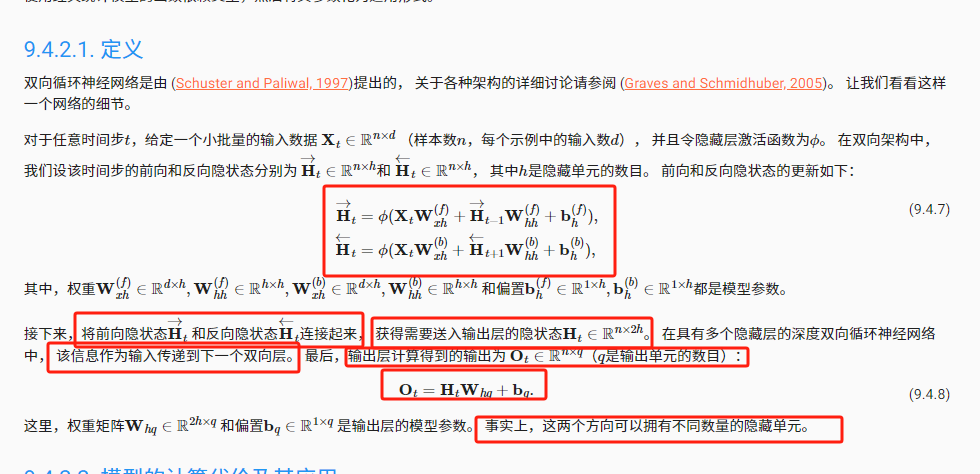
将前向隐状态 和反向隐状态连接起来, 获得需要送入输出层的隐状态H
模型的计算代价及其应用

双向层的使用在实践中非常少,并且仅仅应用于部分场合。 例如,填充缺失的单词、词元注释(例如,用于命名实体识别) 以及作为序列处理流水线中的一个步骤对序列进行编码(例如,用于机器翻译)
总结
-
在双向循环神经网络中,每个时间步的隐状态由当前时间步的前后数据同时决定。
-
双向循环神经网络与概率图模型中的“前向-后向”算法具有相似性。
-
双向循环神经网络主要用于序列编码和给定双向上下文的观测估计。
-
由于梯度链更长,因此双向循环神经网络的训练代价非常高。
-
双向层的使用在实践中非常少,并且仅仅应用于部分场合。 例如,填充缺失的单词、词元注释(例如,用于命名实体识别) 以及作为序列处理流水线中的一个步骤对序列进行编码(例如,用于机器翻译)

