
- 1adb命令 -- fastboot命令&OEM解锁_fastboot oem unlock
- 2鸿蒙HarmonyOS实战-ArkTS语言基础类库(并发)_arkts线程
- 3深度学习最常用的10个激活函数_激活函数一般用什么符号
- 4海尔wireless hd camera说明书_山西电容器纸介电常数测试仪说明书
- 5Text2SQL_DB-GPT-HUB微调
- 6【数字信号去噪】基于matlab鲸鱼算法优化VMD信号去噪(目标函数为包络熵局部极小值)【含Matlab源码 2091期】_包络熵优化
- 7字段约束与函数_字段约束1.1
- 8Three.js一起学-对比WebGL和Three.js的渲染流程_web 渲染3d模型
- 9小程序关联微信视频号_wx.openchannelsactivity
- 10python机器学习:决策树详解_决策树python
ROC曲线与AUC_标签外卷roc是什么意
赞
踩
ROC曲线
对于0,1两类分类问题,一些分类器得到的结果往往不是0,1这样的标签,如神经网络,得到诸如0.5,0,8这样的分类结果。这时,我们人为取一个阈值,比如0.4,那么小于0.4的为0类,大于等于0.4的为1类,可以得到一个分类结果。同样,这个阈值我们可以取0.1,0.2等等。取不同的阈值,得到的最后的分类情况也就不同。
如下面这幅图:
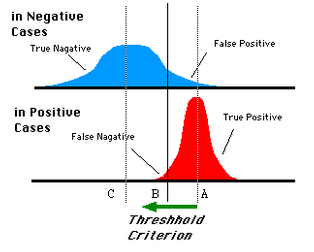
蓝色表示原始为负类分类得到的统计图,红色为正类得到的统计图。那么我们取一条直线,直线左边分为负类,右边分为正,这条直线也就是我们所取的阈值。
阈值不同,可以得到不同的结果,但是由分类器决定的统计图始终是不变的。这时候就需要一个独立于阈值,只与分类器有关的评价指标,来衡量特定分类器的好坏。
还有在类不平衡的情况下,如正样本90个,负样本10个,直接把所有样本分类为正样本,得到识别率为90%。但这显然是没有意义的。
如上就是ROC曲线的动机。
关于两类分类问题,原始类为positive,negative,分类后的类别为p,n。排列组合后得到4种结果,如下:
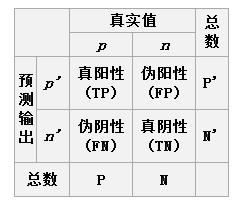
于是我们得到四个指标,分别为真阳,伪阳;伪阴,真阴。
ROC空间将伪阳性率(FPR)定义为 X 轴,真阳性率(TPR)定义为 Y 轴。这两个值由上面四个值计算得到,公式如下:
TPR:在所有实际为阳性的样本中,被正确地判断为阳性之比率。
TPR=TP/(TP+FN)
FPR:在所有实际为阴性的样本中,被错误地判断为阳性之比率。
FPR=FP/(FP+TN)
放在具体领域来理解上述两个指标。
如在医学诊断中,判断有病的样本。
那么尽量把有病的揪出来是主要任务,也就是第一个指标TPR,要越高越好。
而把没病的样本误诊为有病的,也就是第二个指标FPR,要越低越好。
不难发现,这两个指标之间是相互制约的。如果某个医生对于有病的症状比较敏感,稍微的小症状都判断为有病,那么他的第一个指标应该会很高,但是第二个指标也就相应地变高。最极端的情况下,他把所有的样本都看做有病,那么第一个指标达到1,第二个指标也为1。
我们以FPR为横轴,TPR为纵轴,得到如下ROC空间。
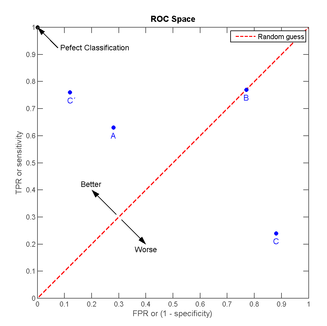
我们可以看出,左上角的点(TPR=1,FPR=0),为完美分类,也就是这个医生医术高明,诊断全对。
点A(TPR>FPR),医生A的判断大体是正确的。中线上的点B(TPR=FPR),也就是医生B全都是蒙的,蒙对一半,蒙错一半;下半平面的点C(TPR<FPR),这个医生说你有病,那么你很可能没有病,医生C的话我们要反着听,为真庸医。
上图中一个阈值,得到一个点。现在我们需要一个独立于阈值的评价指标来衡量这个医生的医术如何,也就是遍历所有的阈值,得到ROC曲线。
还是一开始的那幅图,假设如下就是某个医生的诊断统计图,直线代表阈值。我们遍历所有的阈值,能够在ROC平面上得到如下的ROC曲线。
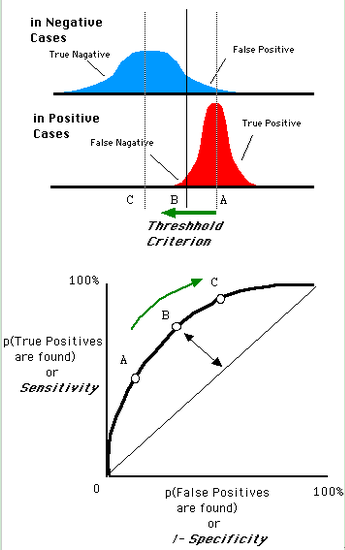
曲线距离左上角越近,证明分类器效果越好。
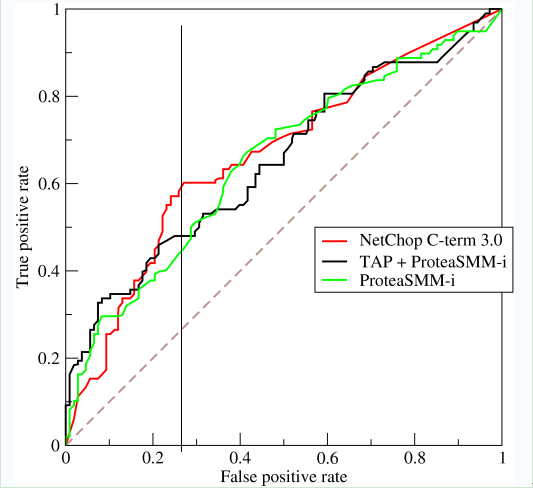
如上,是三条ROC曲线,在0.23处取一条直线。那么,在同样的低FPR=0.23的情况下,红色分类器得到更高的PTR。也就表明,ROC越往上,分类器效果越好。我们用一个标量值AUC来量化他。
AUC
AUC值为ROC曲线所覆盖的区域面积,显然,AUC越大,分类器分类效果越好。
AUC = 1,是完美分类器,采用这个预测模型时,不管设定什么阈值都能得出完美预测。绝大多数预测的场合,不存在完美分类器。
0.5 < AUC < 1,优于随机猜测。这个分类器(模型)妥善设定阈值的话,能有预测价值。
AUC = 0.5,跟随机猜测一样(例:丢铜板),模型没有预测价值。
AUC < 0.5,比随机猜测还差;但只要总是反预测而行,就优于随机猜测。
AUC的物理意义
假设分类器的输出是样本属于正类的socre(置信度),则AUC的物理意义为,任取一对(正、负)样本,正样本的score大于负样本的score的概率。
计算AUC:
第一种方法:AUC为ROC曲线下的面积,那我们直接计算面积可得。面积为一个个小的梯形面积之和。计算的精度与阈值的精度有关。
第二种方法:根据AUC的物理意义,我们计算正样本score大于负样本的score的概率。取N*M(N为正样本数,M为负样本数)个二元组,比较score,最后得到AUC。时间复杂度为O(N*M)。
第三种方法:与第二种方法相似,直接计算正样本score大于负样本的概率。我们首先把所有样本按照score排序,依次用rank表示他们,如最大score的样本,rank=n(n=N+M),其次为n-1。那么对于正样本中rank最大的样本,rank_max,有M-1个其他正样本比他score小,那么就有(rank_max-1)-(M-1)个负样本比他score小。其次为(rank_second-1)-(M-2)。最后我们得到正样本大于负样本的概率为
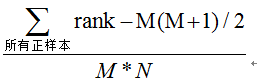
时间复杂度为O(N+M)。
MATLAB实现
MATLAB自带plotroc()方法,绘制ROC曲线,参数如下:
plotroc(targets,outputs);
第一个参数为测试样本的原始标签,第二个参数为分类后得到的标签。
两个为行或列向量,相同维数即可。
AUC matlab代码:
function [result]=AUC(test_targets,output)
%计算AUC值,test_targets为原始样本标签,output为分类器得到的标签
%均为行或列向量
[A,I]=sort(output);
M=0;N=0;
for i=1:length(output)
if(test_targets(i)==1)
M=M+1;
else
N=N+1;
end
end
sigma=0;
for i=M+N:-1:1
if(test_targets(I(i))==1)
sigma=sigma+i;
end
end
result=(sigma-(M+1)*M/2)/(M*N);

