
- 1卷积神经网络的结构组成与解释(详细介绍)
- 2error in xxx setup command: use_2to3 is invalid._error in feedparser setup command: use_2to3 is inv
- 3毕业设计:热门旅游景点大数据分析系统+可视化 +贝叶斯预测模型 旅游大数据 (附源码)✅_景点酒店数据集
- 4uniapp中vue写微信小程序的生命周期差别
- 5分布式结构化数据表Bigtable
- 6Thrift协议_thrift协议和http协议
- 7Spring Boot:基本应用和源码解析_springboot源码工程
- 8深度学习+CRF解决NER问题
- 9GO: 快速升级Go版本_go 升级版本
- 10Golang 企业级web后端框架_go 后端框架
[翻译] 可视化神经网络机器翻译模型(Seq2Seq模型的注意力机制)_如何显示翻译模型的结果
赞
踩
Seq2Seq模型是深度学习模型,在机器翻译、文本摘要和图像字幕等任务中取得了很大的成功。谷歌翻译于 2016 年底开始在生产环境中使用这种模型。这些模型在两篇开创性论文中进行了解释(Sutskever et al., 2014, Cho et al., 2014)。
然而,我发现要充分理解模型以实现它,需要解开一系列相互叠加的概念。我认为如果以视觉方式表达这些想法会更容易理解。这就是我在这篇文章中的目标。您需要对深度学习有一定的了解才能读完这篇文章。
Seq2Seq模型是一种以一个序列(单词、字母、图像特征等)为输入并输出另一个序列的模型。一个训练有素的模型会像这样工作:
在神经网络机器翻译中,输入是一系列单词,一个接一个地处理。同样,输出是一系列单词:
再深入一层
Seq2Seq模型的内部是由编码器和解码器组成的,编码器处理输入序列中的每个元素,它将捕获的信息编译成一个向量(称为上下文),处理完整个输入序列后,编码器将上下文发送到解码器,解码器开始逐项生成输出序列。
这同样适用于机器翻译的情况。
在机器翻译任务中,上下文是一个向量(基本上是一个数字数组)。编码器和解码器往往都是循环神经网络。
https://www.youtube.com/watch?v=UNmqTiOnRfg
上下文是一个浮点向量。在这篇文章的后面,我们将通过为具有更高值的单元格分配更亮的颜色来可视化向量。
您可以在设置模型时设置上下文向量的大小。它基本上是编码器 RNN 中隐藏单元的数量。这些可视化显示了一个大小为 4 的向量,但在现实世界的应用程序中,上下文向量的大小可能是 256、512 或 1024。
按照设计,RNN 在每个时间步都有两个输入:一个输入(在编码器的情况下,输入句子中的一个词)和一个隐藏状态。然而,这个词需要用一个向量来表示。要将单词转换为向量,我们需要使用一类称之为“Word Embedding”的算法。这些将单词转换为向量空间,捕获单词的大量含义/语义信息。(例如:国王-男人+女人=王后)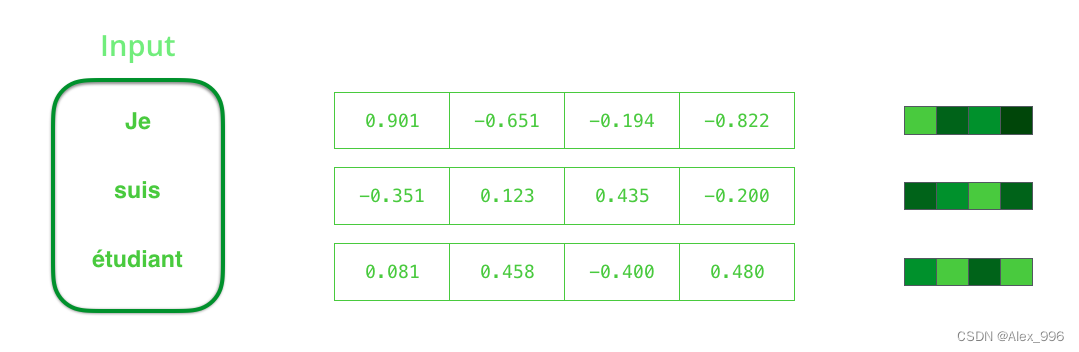
我们需要在处理输入词之前将它们转换为向量,该转换是使用词嵌入算法完成的。我们可以使用预训练的嵌入或在我们的数据集上训练我们自己的嵌入。嵌入大小为 200 或 300 的向量是典型的,为简单起见,我们显示大小为 4 的向量。
现在我们已经介绍了我们的主要向量/张量,让我们回顾一下 RNN 的机制并建立一种视觉语言来描述这些模型:
下一个 RNN 步骤采用第二个输入向量和隐藏状态 #1 来创建该时间步的输出。在后面的文章中,我们将使用这样的动画来描述神经机器翻译模型中的向量。
在下面的可视化中,编码器或解码器的每个脉冲都是 RNN 处理其输入并为该时间步生成输出。由于编码器和解码器都是 RNN,每一步 RNN 都会进行一些处理,它会根据其输入和之前看到的输入更新其隐藏状态。
让我们看看编码器的隐藏状态。注意最后一个隐藏状态实际上是我们传递给解码器的上下文。
解码器还保持一个隐藏状态,它从一个时间步传递到下一个时间步。我们只是没有在此图中将其可视化,因为我们现在关注模型的主要部分。
现在让我们看看另一种可视化Seq2Seq模型的方法。该动画将更容易理解描述这些模型的静态图形。这称为“展开”视图,我们不显示一个解码器,而是为每个时间步显示它的副本。这样我们就可以查看每个时间步的输入和输出。
现在来看注意力机制
事实证明,上下文向量是这类模型的瓶颈,这使得模型处理长句子变得具有挑战性。Bahdanau 等人在2014 年和 Luong 等人在2015 年提出了一个解决方案。这些论文引入并改进了一种称为“注意力”的技术,极大地提高了机器翻译系统的质量。Attention 允许模型根据需要关注输入序列的相关部分。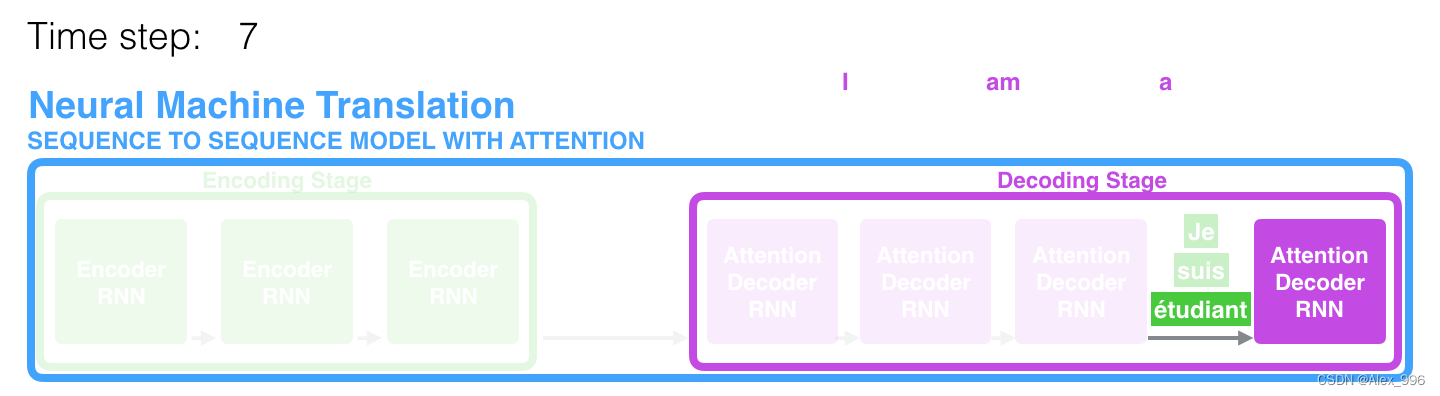
在时间步 7,注意力机制使解码器能够在生成英文翻译之前将注意力集中在单词“étudiant”(法语中的“student”)上。这种从输入序列的相关部分放大信号的能力使得注意力模型比没有注意力的模型产生更好的结果。
让我们继续研究这种高度抽象的注意力模型。注意力模型在两个主要方面不同于经典的Seq2Seq模型:
- 编码器将更多数据传递给解码器。编码器没有传递编码阶段的最后一个隐藏状态,而是将所有隐藏状态传递给解码器:

- 注意解码器在产生其输出之前会执行额外的步骤。为了关注与此解码时间步长相关的输入部分,解码器执行以下操作:
- 查看它接收到的一组编码器隐藏状态——每个编码器隐藏状态与输入句子中的某个词最相关;
- 给每个隐藏状态打分(我们暂时忽略打分的方式),该评分生成在解码器端的每个时间步进行;
- 将每个隐藏状态乘以其 softmax 分数,从而放大高分数的隐藏状态,并淹没低分数的隐藏状态;

现在让我们在下面的可视化中把整个事情放在一起,看看注意力过程是如何工作的:
- 注意力解码器 RNN 接受 标记的嵌入和初始解码器隐藏状态;
- RNN 处理其输入,产生一个输出和一个新的隐藏状态向量 (h4),输出被丢弃;
- 注意力机制:我们使用编码器隐藏状态和 h4 向量来计算这个时间步的上下文向量 (C4);
- 将 h4 和 C4 连接成一个向量;
- 通过一个前馈神经网络(与模型联合训练的)传递这个向量;
- 前馈神经网络的输出表示该时间步的输出字;
- 下一个时间步骤重复

这是查看在每个解码步骤中我们关注输入语句的哪一部分的另一种方法:
请注意,该模型不仅仅是将输出的第一个词与输入的第一个词对齐,它实际上从训练阶段学习了如何对齐该语言对中的单词(在我们的示例中为法语和英语)。关于这种机制的精确程度的一个例子来自上面列出的注意力论文:
您可以看到模型在输出“欧洲经济区”时如何正确关注。在法语中,这些词的顺序与英语相反(“européenne économique zone”)。句子中的每个其他单词都以类似的顺序排列。
如果您觉得自己已经准备好学习实现,请务必查看 TensorFlow 的神经机器翻译 (seq2seq) 教程。
原文链接:Visualizing A Neural Machine Translation Model (Mechanics of Seq2seq Models With Attention)

