
- 1Ollama教程——入门:开启本地大型语言模型开发之旅_ollama中文文档
- 2机器学习实验二-----决策树构建
- 3STM32F401RCT6电子元器件芯片LQFP64 32位微控制器MCU单片机
- 4信息收集模块(四)masscan介绍和使用教程
- 5Linux 显存占用清理(自用)_linux权限不够想使用命令释放显存
- 6给Python新手安利几个超实用的学习刷题网站_python不会的题去哪搜
- 7门控循环单元(Gate Recurrent Unit,GRU)_双向门控循环单元
- 8idea中输入法被锁定如何清除
- 9Git一个仓库包含多个不同的项目VUE(老项目的基础上,新建分支放新项目)_git上一个仓库放多个项目源码ke'yi'makeyima
- 10基于STM32的超声波测距(外部中断+定时器)_stm32 ultrasound
【论文阅读】SynDiff Unsupervised Medical Image Translation with Adversarial Diffusion Models
赞
踩
Unsupervised Medical Image Translation with Adversarial Diffusion Models 论文大致翻译和主要内容讲解
摘要:
通过源-目标通道转换对缺失图像进行填充可以提高医学成像协议的多样性。合成目标图像的普遍方法包括通过生成性对抗网络(GAN)的一次映射。然而,隐含地描述图像分布的Gan模型可能会受到样本保真度有限的影响。为了提高医学图像翻译的性能,我们提出了一种基于对抗性扩散模型的新方法SynDiff。为了捕捉图像分布的直接相关性,SynDiff利用一个条件扩散过程,逐步将噪声和源图像映射到目标图像上。为了在推理过程中快速和准确地进行图像采样,在反向扩散方向上采用对抗性投影进行大的扩散步骤。为了能够在不成对的数据集上进行训练,设计了一个周期一致的体系结构,其中耦合了扩散和非扩散模块,这些模块在两个通道之间进行双边转换。
介绍:GAN:这种隐含的表征可能会受到学习偏差的影响,包括过早收敛和模式崩溃。此外,GAN模型通常采用快速单点采样过程而没有中间步骤,这固有地限制了网络执行的映射的可靠性。
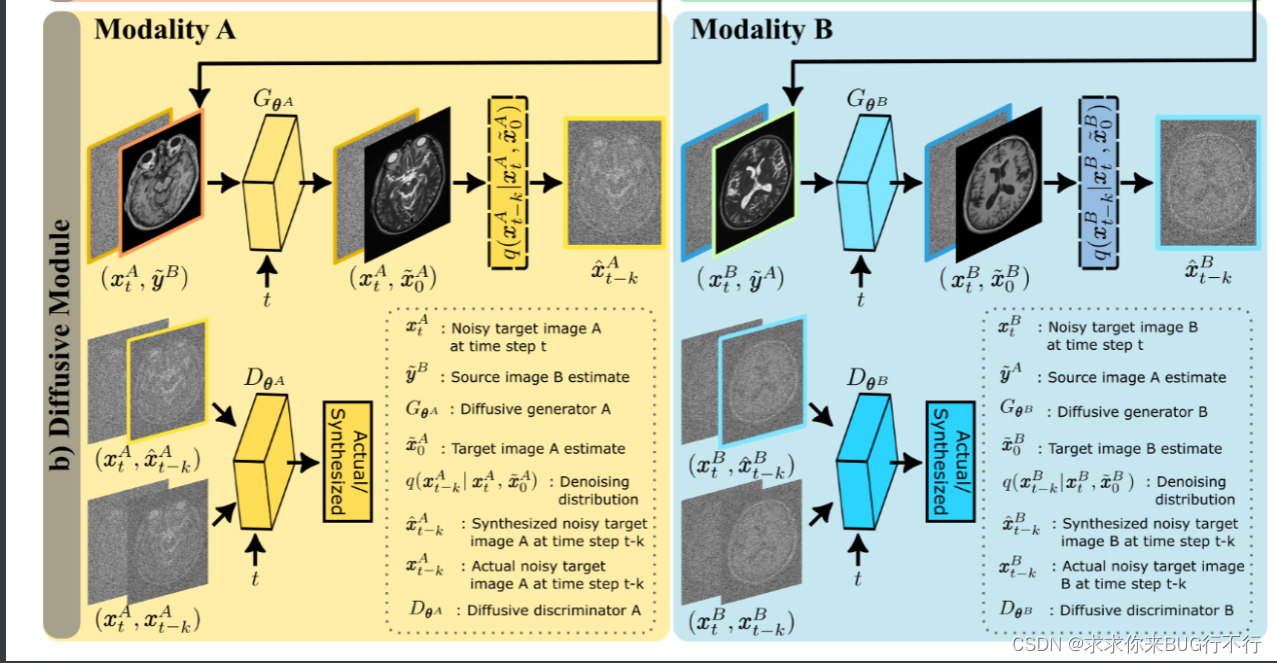
SynDiff采用了步长较大的快速扩散过程以提高效率。(1)通过一种新颖的源条件对抗投影器实现了在逆扩散步骤中的精确采样,该投影器在源图像的引导下对目标图像样本进行去噪。(2)为了实现无监督学习,设计了一种循环一致性架构,在两种模态之间具有双向耦合的扩散和非扩散过程的情况。这里分别对应图一和图二。
贡献:
我们引入了第一个对抗扩散模型用于高保真医学图像合成的文献。
我们介绍了第一个基于扩散的无监督医学图像翻译的方法,使训练的源目标模态的不配对数据集。
我们提出了一种新的源条件对抗投影仪,以捕获大步长的反向转移概率,有效的图像采样。
相关工作:
介绍一些GAN方法,通过其模式崩溃,多样性以及可靠性的缺乏引渡到扩散模型。由于逐步随机抽样过程和显式似然特征,扩散模型可以提高网络映射的可靠性,以提供增强的样本质量和多样性。源域和目标域底层有着很重要的信息,因此本文使用条件扩散将其引导。SynDiff利用条件扩散过程,其中将来自实际源图像的高质量结构信息作为条件输入提供给反向扩散步骤。之后介绍DDGAN和UNIT-DDPM,UMM-CGSM.
方法:
首先介绍了DiffusionModel。介绍了大致推导和公式讲解。
之后介绍SynDiff。

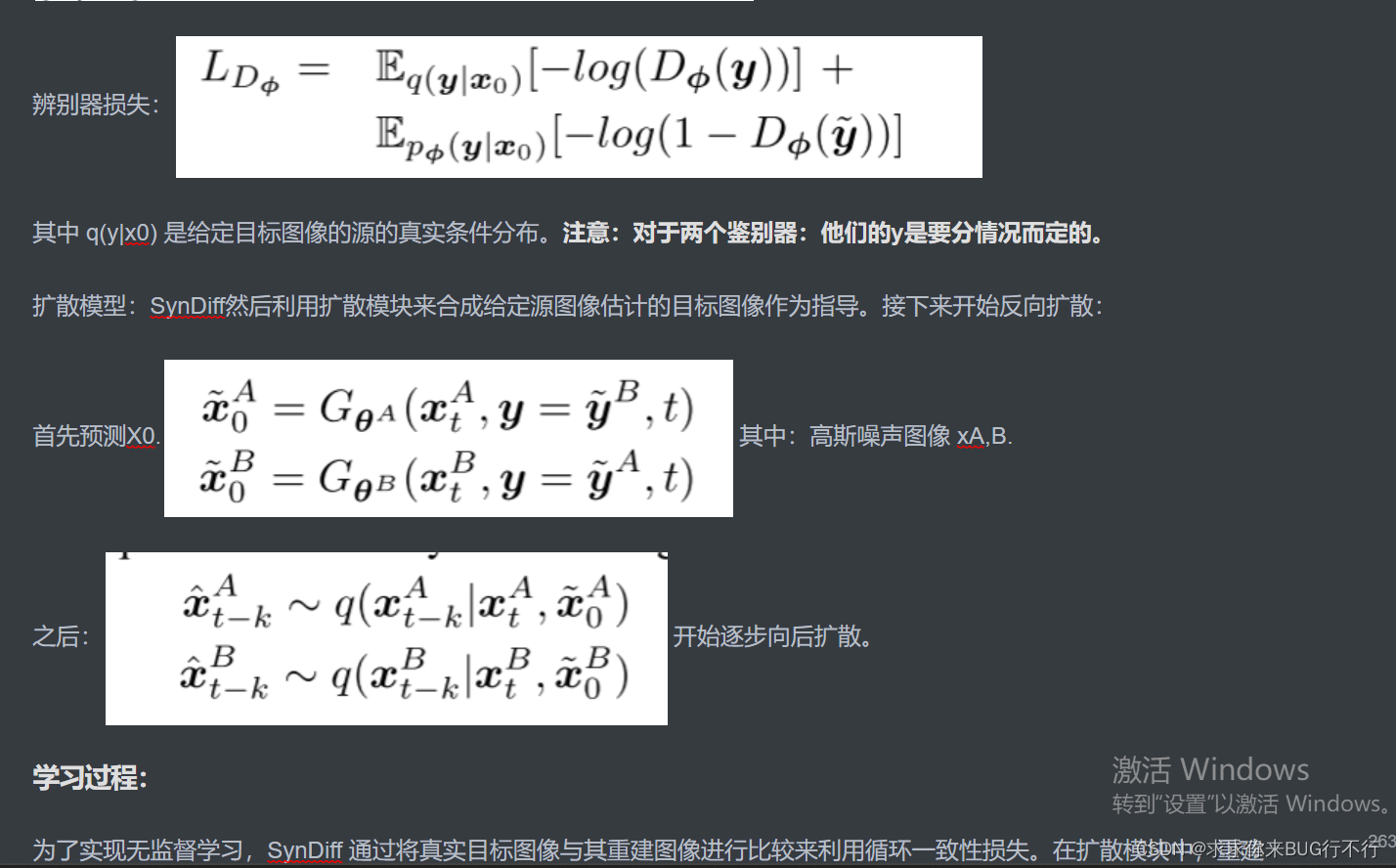
Regular Diffusion Model :X0是我们的目标域。首先加噪到高斯噪声;y是源域,在反向过程的时候,我们将源域信息添加进去作为指导条件,希望逐步去噪得到的图像里面由我们的源域信息,从而更好的生成目标域。
Adversarial diffusion model:反向过程如图所示。通过某一个时刻t的(Xt,y)通过生成器生成X0^(预测的目标图像)。然后将Xt,预测的X0通过反向扩散得到预测的Xt-k。然后将真实的Xt,Xt-k和预测的Xt-k通过辨别器来进行辨别。
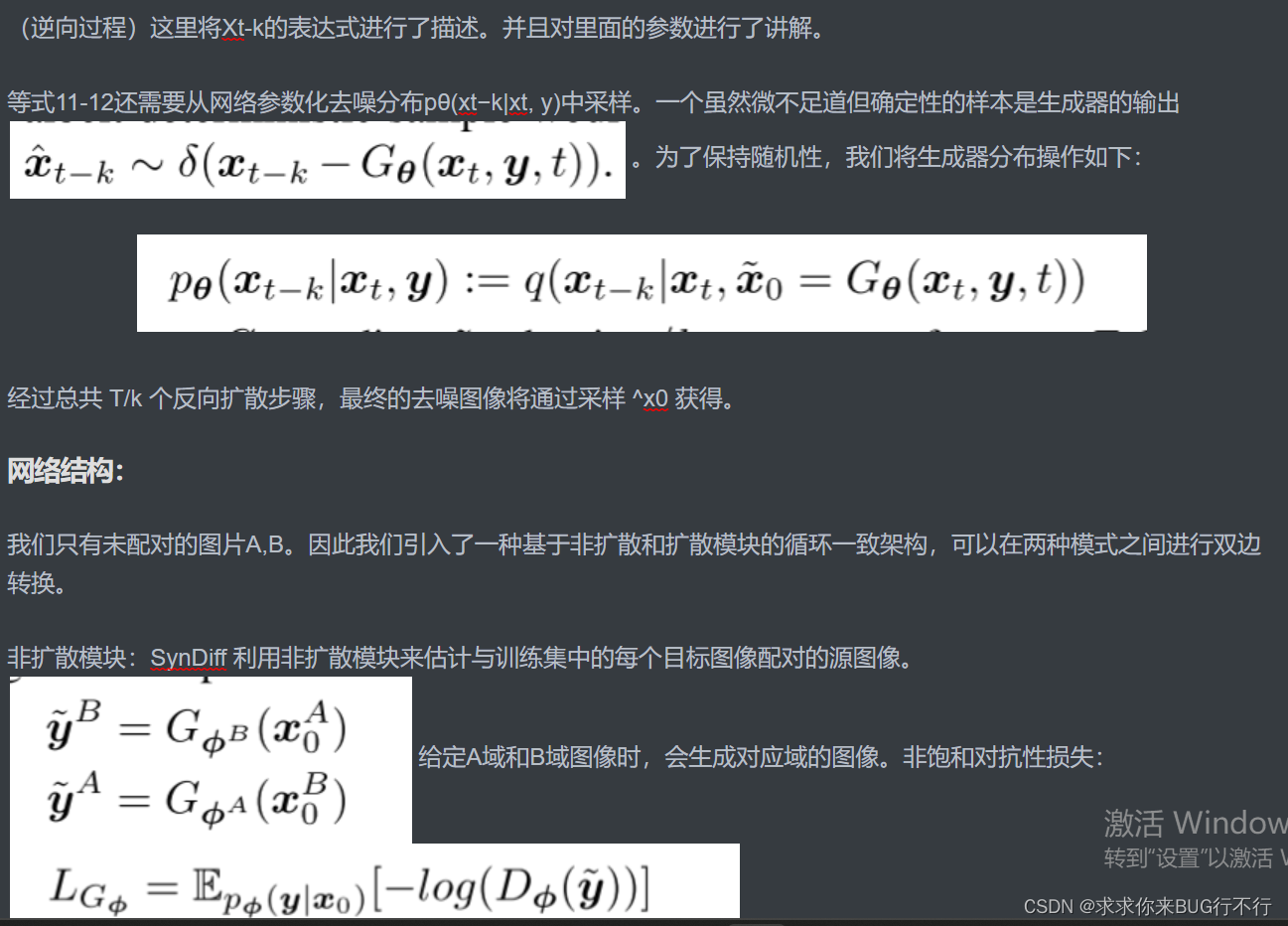
为了生成A域的图片,则我们还需要源域B的图片,但是在实际中可能没有配对的图像,因此我们需要一个非扩散模型的生成器来从A生成一个源域B的图像。为了生成B域的,则我们首先需要从B生成A域的源域图像;
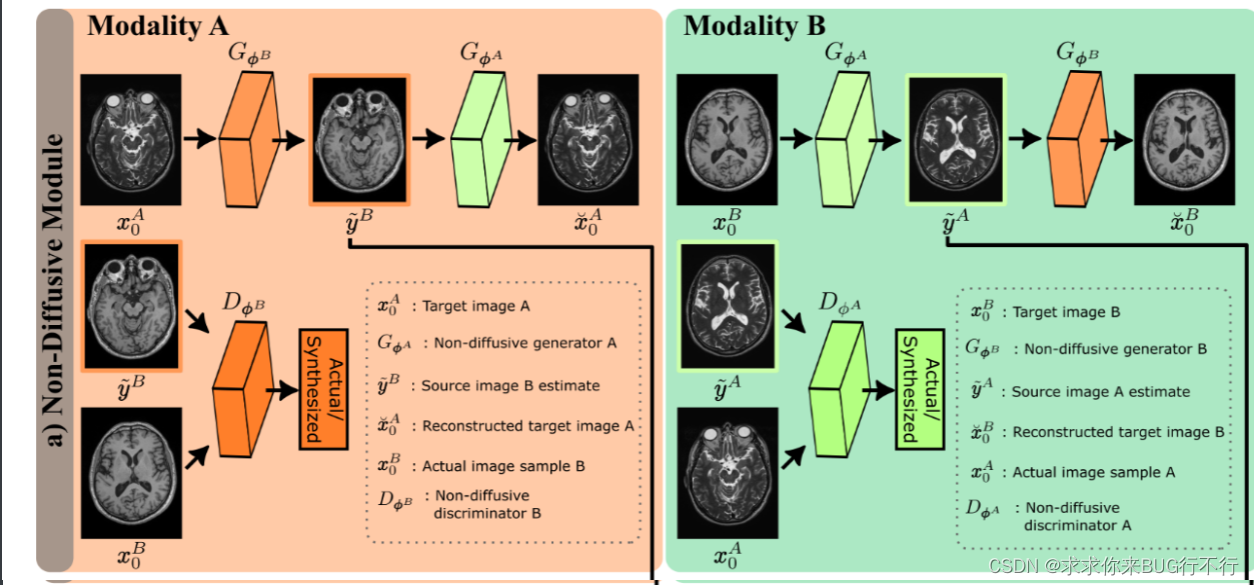
最上面两个图表示了A域B域分别作为目标域时候的操作。当A为目标域时:先生成B域源域的图像,然后又生成A域目标域的图像。将B域源域的图像和label送进辨别器。
最下面两个图表示了不同的域的逆向扩散过程。 当A为目标域时,传入目标域噪声,预测的源域图像通过生成器A预测出最终的目标图像,然后通过扩散过程得到Xt-k。将Xt,预测的Xt-k和label送入鉴别器。
对抗性扩散过程:
常规的扩散模型需要T步,很费时间。本文使用如下公式:

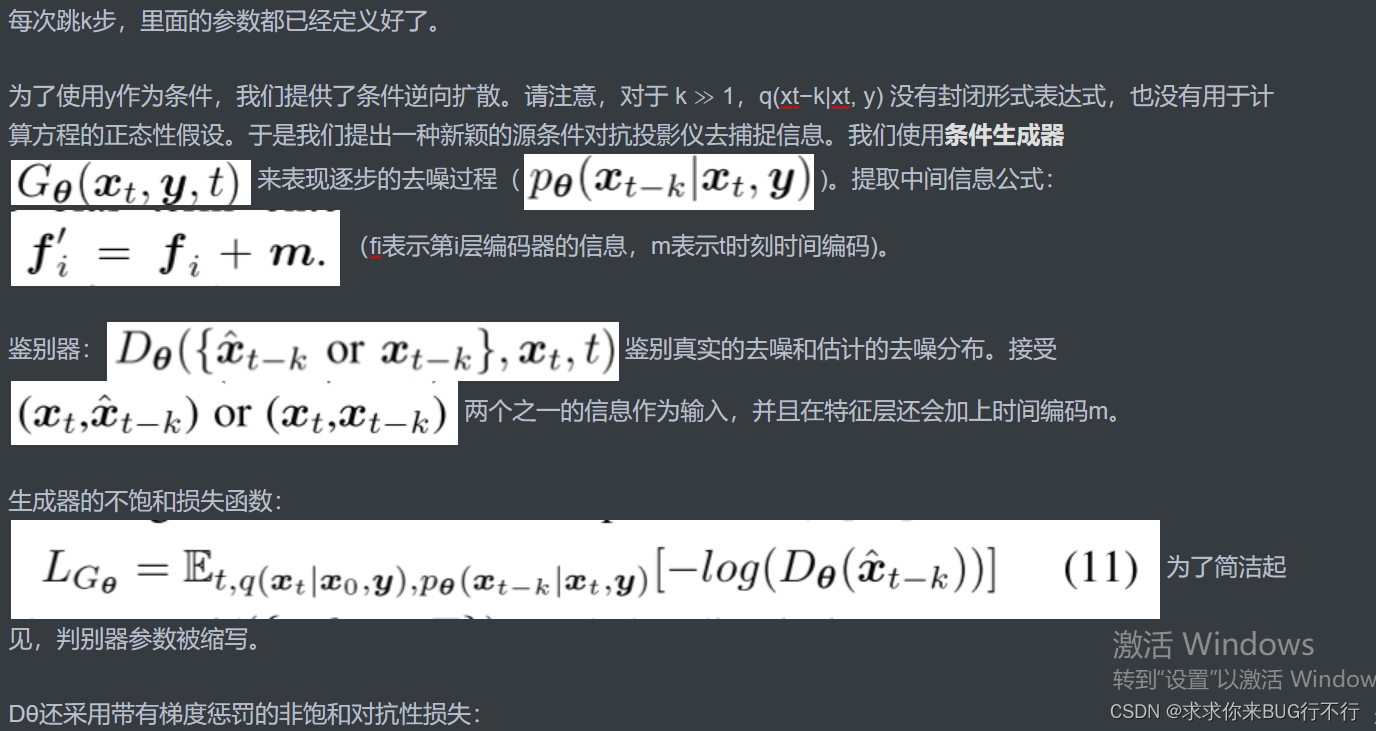



训练步骤(自己结合代码所写):
都是操作的两个域,举例子就举一个方向的即可。
首先训练DD(Diffusion Discriminator),固定生成器
1.真实数据
根据真实数据A生成正向采样的XAt,XAt+1。
通过DD来鉴别这个两个真实的(XAt,t,XAt+1)
期望这个值越大越好。所以加了负号。
2.假数据
通过NDG(NonDiffusionGenerator)来生成真实A,B对应的另外一个域的数据
然后通过DG生成XA0 传入(真实的XAt,预测的XB(源域),t1,潜在变量)
然后通过(预测的XA0,真实XAt+1,t1)来预测XAt.
通过DD来判断假的(预测的XAt,t1,真实的XAt+1)
期待这个值越小越好。
现在就对DD参数进行更新。
然后训练NND(NonDiffusionDiscriminator),固定生成器
1.真实数据
通过NND来鉴别真实的A,B数据。 disc_non_diffusive_cycle1(real_data1)
2.假数据
通过NNG来生成B对应的A域数据。x1_0_predict = gen_non_diffusive_2to1(real_data2)
通过NND来鉴别假的A,B数据。
值越小越好。
接下来对生成器进行训练,固定鉴别器。
通过真实的A生成真实的XAt,XAt+1。 x1_t, x1_tp1 = q_sample_pairs(coeff, real_data1, t1)
通过NDG将B预测到A,再把A预测回B。
通过DG(真实的XAt+1,预测B,t1,潜在变量z1)生成预测的XA。
通过预测的XA,真实的XAt+1采样得到XAt.
通过DD来鉴别假的(采样的XAt,t1, 真实的XAt+1) 但是生成器希望这个生成的数据接近真实的,所以越大越好。
通过NDG将B预测到A的图片通过NND进行辨别。


