
- 1游戏行业渠道商管理平台:赋能游戏发行商的数字化解决方案_游戏渠道商
- 2超级好用 VMWare14 安装Mac OS10.12系统(图解)_vmware mac os 10.12
- 3Arthas诊断工具(三)监控命令_arthas监控方法
- 4最好用的六款虚拟机软件_虚拟机那家强
- 5第十四届蓝桥杯国赛 C++ B 组 C 题——班级活动(AC)_蓝桥杯十四届国赛c++b组题解
- 6Android布局属性大全
- 7『网络安全科普』Windows安全之HOOK技术机制
- 8Doris(一)-简介、架构、编译、安装和数据表的基本使用
- 9SQL Server 2005性能排错白皮书(Part 1)---From MS Customer Support Service部门 _a time out occurred while waiting to optimize the
- 10面试ssss
PromptBERT: 利用Prompt改善BERT的句子表示_prompt bert
赞
踩

背景
今天继续关注句子表示学习。之前笔者一直觉得Prompt就是概念炒作(可能我比较菜),不觉得能有啥大的发展。但是近一年来,类似的论文层出不穷,不注意都难。今天这篇论文让我对Prompt有了很大的改观。
首先,回顾句子表示学习中存在的问题:
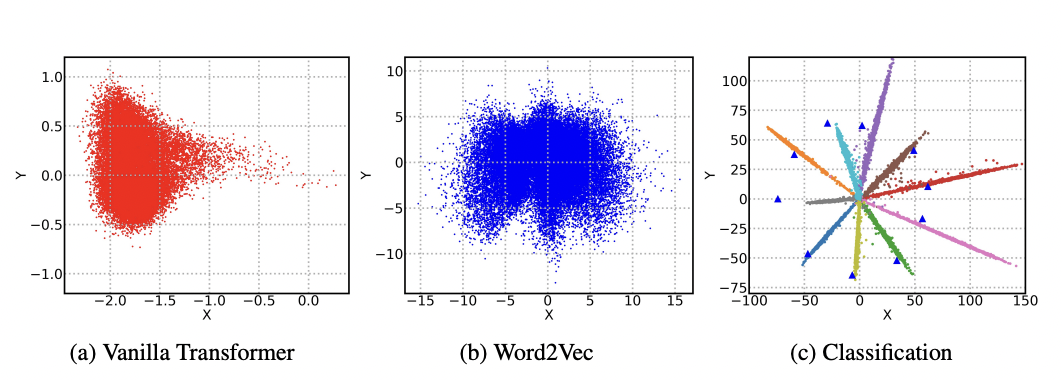
BERT直接出来的向量存在各向异性(anisotropic)。通俗讲,就以下两个问题:
- 向量分布不均匀分布,且充斥在一个狭窄的锥形空间下(上图a所示)。
- 低频词离原点远,分布稀疏,高频词向量离原点近,分布紧密。
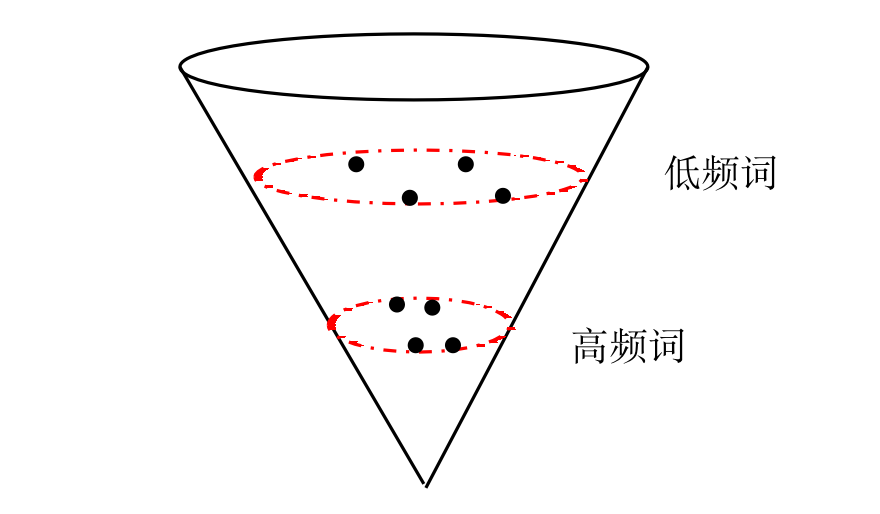
针对低频和高频分布的情况,会存在这样的问题: 假设有一对词“讨厌”、“反感”。如果在训练语料中,反复出现“讨厌”,而“反感”出现的次数极少,则会导致这两个词的向量距离很大。其实,最理想的词向量分布就是上面图b(Word2Vec)的情形,比较均匀。
针对以上的问题,有各种各样的解决方案。如:Bert-flow、Bert-whitening、SimCSE等等。今天,这篇论文PromptBERT同样也是针对句子表示学习的优化。下面看一下模型的具体结构。
模型
本文对异向性的认识
首先,论文的开始也提到了词频对词向量表示学习的影响,另外也提到英文大小写、子词等也会有影响。接着,作者通过人工去除这种偏置做实验,发现效果好很多,甚至好于Bert-flow和Bert-whitening。但是,这种人工去除偏置的方法很麻烦,另外有些词出现的次数很少,但是它在某个短句中意义重大,如果直接去除,肯定不可行。基于此,作者就想到了利用Prompt,直接基于提示产生词向量。
在讲模型之前,再看一下本文对于异向性的一个认识(很有说服力)。在通用的语料中,如果随机抽若干句子,计算它们之间的平均余弦相似度,如果越接近于1,说明异向性越严重,如果接近于0,说明同向性很好。平均余弦相似度计算公式如下:
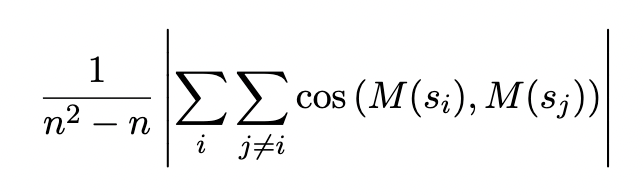
其中 s i ∈ { s 0 , s 1 , . . . , s n } s_i\in{\{s_0, s_1, ..., s_n\}} si∈{s0,s1,...,sn}, s j ∈ { s 0 , s 1 , . . . , s n } s_j\in{\{s_0, s_1, ..., s_n\}} sj∈{s0,s1,...,sn},就是句子集合中随机的两条句子。 M代表通过什么方法获取的词向量。 下面是一些模型的效果:
可以发现这些模型的异向性非常严重。
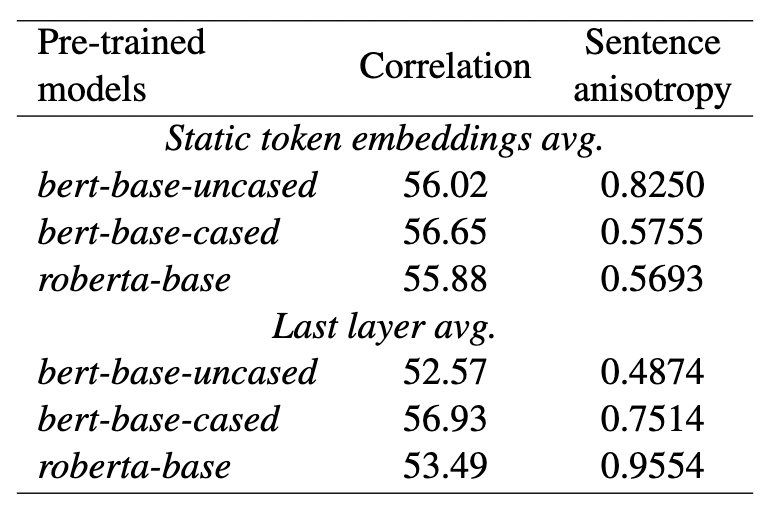
另外,论文也调研了一下词嵌入的偏置问题(词频对表示学习是否有影响?)
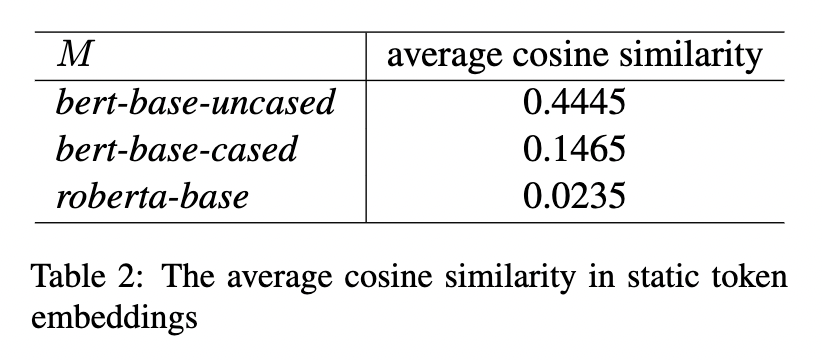
上表是随机抽取若干词,计算他们之间的平均个余弦相似度。可以发现roberta-base的效果比bert好些。作者在文中还可视化了各种特征(词频、大小写、子词)等对嵌入的影响,若感兴趣,可以进一步看看文中的一些描述。
模型结构
方法1: 直接获取Prompt的表示
在这种方法中,作者有给了两种实现方式:
- 设计一种模板 “[X] means [MASK]” 其中 [X] 是我们输入的句子,然后将填充后模板塞进行一个预训练完的模型(如BERT),得到最终[MASK]表示,即当前句子的向量表示。如下公式所示:
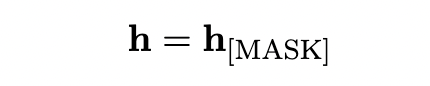
- 基于上述1得到 h [ M A S K ] h_{[MASK]} h[MASK],然后使用MLM任务的分类头,得到top-k个token的概率值,接着从embedding矩阵中取出这些词的向量进行加权平均。具体计算如下:
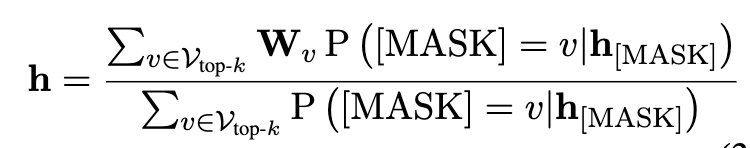
其中 W v W_v Wv是embedding词向量矩阵。 v v v就是top-k中的某个token,分子相当于就是取出top-k个词的词向量进行直接对应位加和。分母的 P ( [ M A S K ] = v ∣ h [ M A S K ] ) P([MASK]=v|h_{[MASK]}) P([MASK]=v∣h[MASK])是预测出某个token的概率,相当于是将top-k个词的概率累加。最后就得到了句子的表示向量。
另外作者也做了模板搜索,实验结果如下:

不同模板之间的差距还挺大的。Prompt真是玄学呀。
方法二:基于提示的模板去噪对比学习
是这个方法驱使我读这篇论文的。众所周知,在SimCSE中,是通过Dropout进行数据增广,得到对应的正例对。而在本文中,是通过不同的模板,得到对应的正例对([MASK]向量),然后基于这种正例进行对比学习。
损失函数如下:
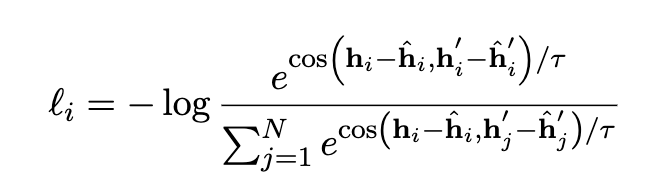
分子部分是计算正例之间的cos,分母是计算当前样本与其他正负例之间的cos。我们以分子为例,cos里面有两部分,如果都不减 h ^ \hat h h^,相当于是两个正例的表示,本文指的是同一句话通过不同的两个模板得出的向量表示。之所以后面要减去 h ^ \hat h h^,是因为作者想消去模板引来的偏置。 h ^ \hat h h^就是将纯模板塞进模型,得到的向量表示。
至此论文就讲完了。如果对方法二还有疑问的话,可以参考我的一个实现: https://github.com/shawroad/Semantic-Textual-Similarity-Pytorch/tree/main/PromptBert
实验
首先,作者给出一个没有微调的实验,即采用上述方法一得出的结果,如下所示:
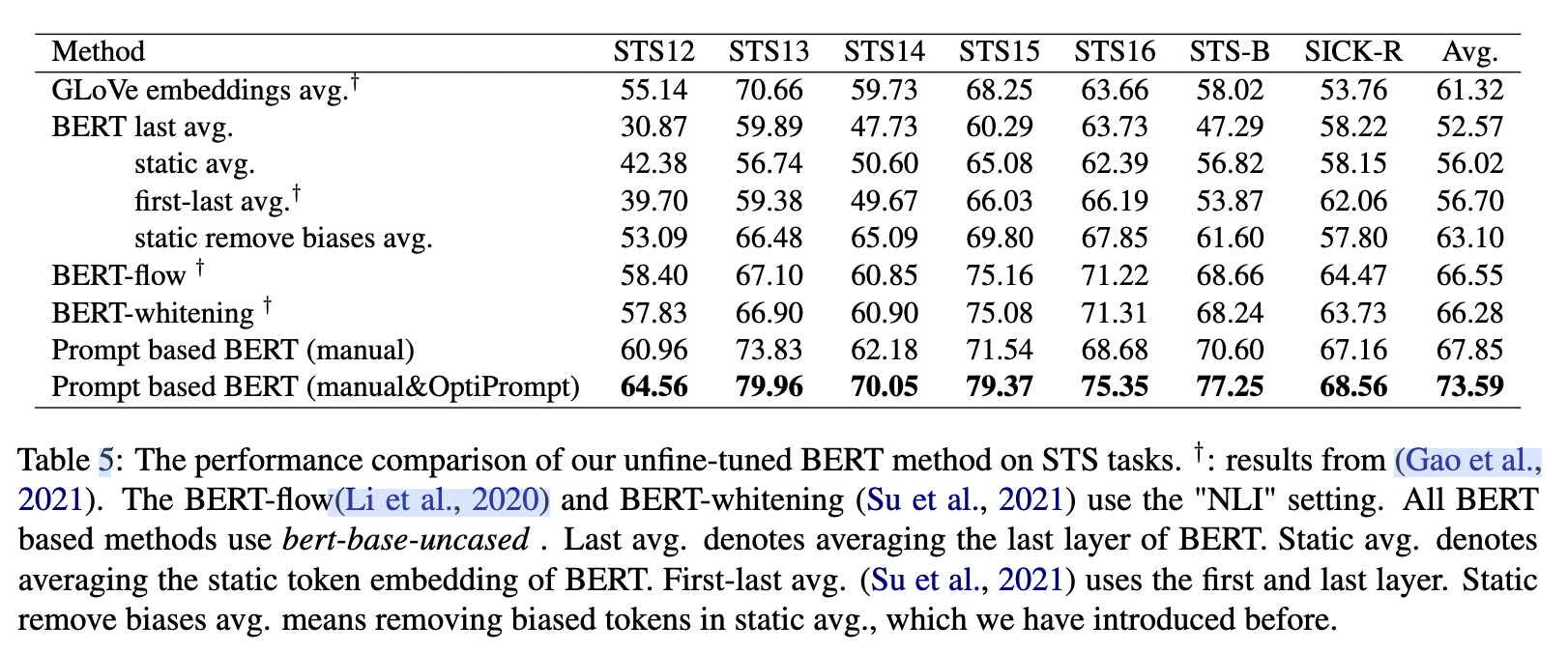
可以发现,效果确实惊人。提升非常大。OptiPrompt是指用了模板搜索。
接着作者给出了微调之后的结果,也就是采用上述方法二进行对比学习的结果,如下所示:
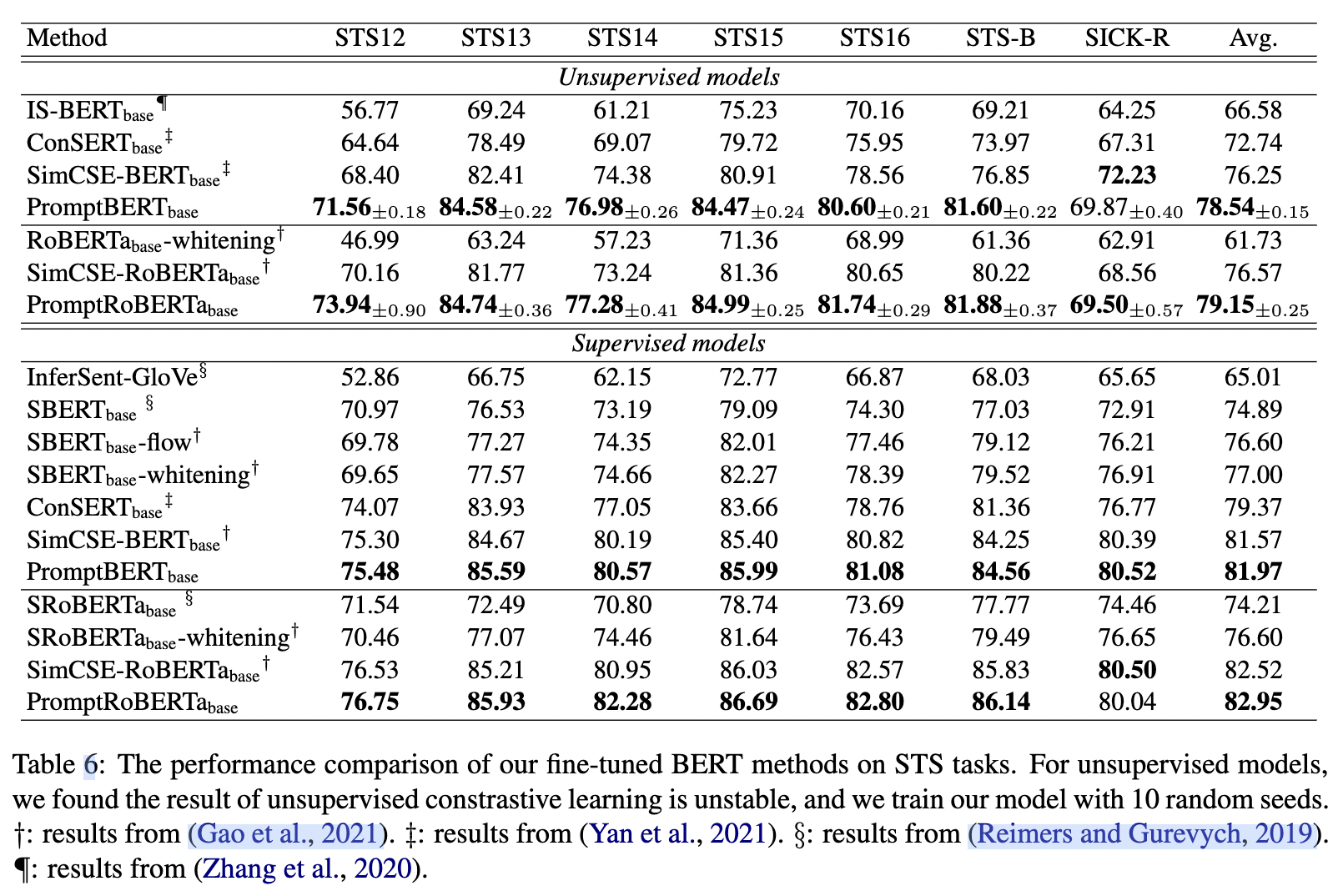
可以发现,无监督的效果远远高于之前的方法。有监督也略高于之前的simcse。

