
- 1QGroundControl之安装调试_qgroundcontrol安装教程
- 2[NLP]自然语言理解概述_文字是自然语言还是形式语言
- 3数据结构:打造高效的通讯录项目
- 4MySQL索引学习篇_索引的分类、测试100万数据有无索引查询速度对比、索引深入(聚集索引 、索引的数据结构 、B树和B+树的区别 B+树的优势 、MyISAM 和 InnoDB 索引组织的区别 )_一百万数据查询二叉树和b树,哪个快
- 5数据结构——单向链表(C语言实现)
- 6SAP GUI for Mac安装及登陆配置
- 7AI人工智能在建筑智能化工程设计的应用_ai在工程设计中的应用
- 8【详解|彻底搞懂el-table和列表过滤】vue列表过滤和el-table的实现
- 9Mybatis-Plus实现乐观锁_mybatis-plus使用乐观锁
- 10Leetcode动态规划—完全背包问题_完全背包问题 leetcode
Milvus 2.0 数据插入与持久化_milvus 插入数据
赞
踩
编者按:本文详细介绍了Milvus 2.0 数据插入流程以及持久化方案。
Milvus 2.0 整体架构介绍

上图是 Milvus 2.0 的一个整体架构图,从最左边 SDK 作为入口,通过 load balancer 把请求发到 Proxy 这一层。接着 Proxy 会和最上面的 coordinator service(包括 root coord 、 root query、data 和 index)通过和他们进行交互,然后把 DDL 和 DML 写到我们的 message storage 里。
在下方的 worker nodes:包括 query node、data node 和 index node, 会从 message storage 去消费这些请求数据。query node 负责查询,data node 负责写入和持久化,index node 负责建索引和加速查询。
最下面这一层是数据存储层 (object storage),使用的对象存储主要是 MinIO、S3 和 Azure Blob,用来储存 log、delta 和 index file。
数据写入相关的组件介绍
![]()
Proxy
Proxy 作为一个数据请求的入口,它的作用从一开始接受 SDK 的插入请求,然后把这些请求收到的数据哈希到多个桶里,然后向 data coord (data coordinator) 去请求分配 segment 的空间。(Segment 是 Milvus 数据存储的一个最小的单元,后文会详细介绍)接下来的一步就是把请求到的空间的这一部分数据插入到 message storage 里面。插入到 message storage 之后,这些数据就不会再丢失了。
![]()
接下来我们看数据流的一些细节:
-
Proxy 可以有多个
-
Collection 下有 V1、V2、V3、V4 的 VChannel
-
C1、C2、C3、C4 就是一些 PChannel,我们叫它物理 channel
-
多个 V channel 可以对应到同一个 PChannel
-
每一个 proxy 都会对应所有的 VChannel:对于一个 collection 不同的 proxy 也需要负责这个 collection 里边的所有的 channel。
-
为了避免 VChannel 太多导致资源消耗太大,多个 VChannel 可以对应一个 PChannel
![]()
Data coord
Data coord 有几个功能:
-
分配 segment 数据 把 segment 空间分配到 proxy 后,proxy 可以使用这部分空间来插入数据。
-
记录分配空间及其过期时间 每一个分配都不是永久的,都会有一个过期时间。
-
Segment flush 逻辑 如果这个 segment 写满,就会落盘。
-
Channel 分配订阅 一个 collection 可以有很多 channel 。哪些 channel 被哪些 data node 消费则需要 data coord 来做一个整体的分配。
Data node
Data node 有几个功能:
-
消费来自这个数据流的数据,以及进行这个数据的序列化。
-
在内存里面缓存写入的数据,然后达到定量之后把它自动 flush 到磁盘上面。
总结:Data coord 管理 channel 与 segment 的分配;Data node 主要负责消费和持久化。
![]()
Data node 与 channel 的关系
如果一个 collection 有四个 channel 的话,可能的分配关系就是两个 data node 各消费两个 VChannel。这是由 data coord 来分配的。那为什么一个 VChannel 不能分到多个 data node 上?因为这样的话就会导致会这个数据被消费多次,进而导致一个 segment 数据的重复。
Root coord & Time tick
Time tick(时间戳)在 Milvus 2.0 中算是一个非常重要的概念,它是整个系统推进的一个关键的概念;Root coord 是一个 TSO 服务的作用,它负责的是全局时钟的分配,每个请求都会对应一个时间戳。Time tick 是递增的,表示系统推进到哪个时间点,与写入和查询都有很大关系;Root coord 负责分配时间戳,默认 0.2 秒。
Proxy 写入数据的时候,每一个请求都会带一个时间戳。Data node 每次以时间戳为区间进行消费。以上图为例,箭头方向就是这个数据写入的一个过程, 126578 这些数字就是时间戳的一个大小。Written by 这一行代表 proxy 写入, P1 就是 proxy 1。如果以 time tick 为区间来进行消费的话,在 5 这个区间之前,我们第一次读的话是只会读到1、2 这两个消息。因为 6 比 5 大,所以他们在下一次 5 到 9 这个区间被消费到。
Data allocation 数据分配
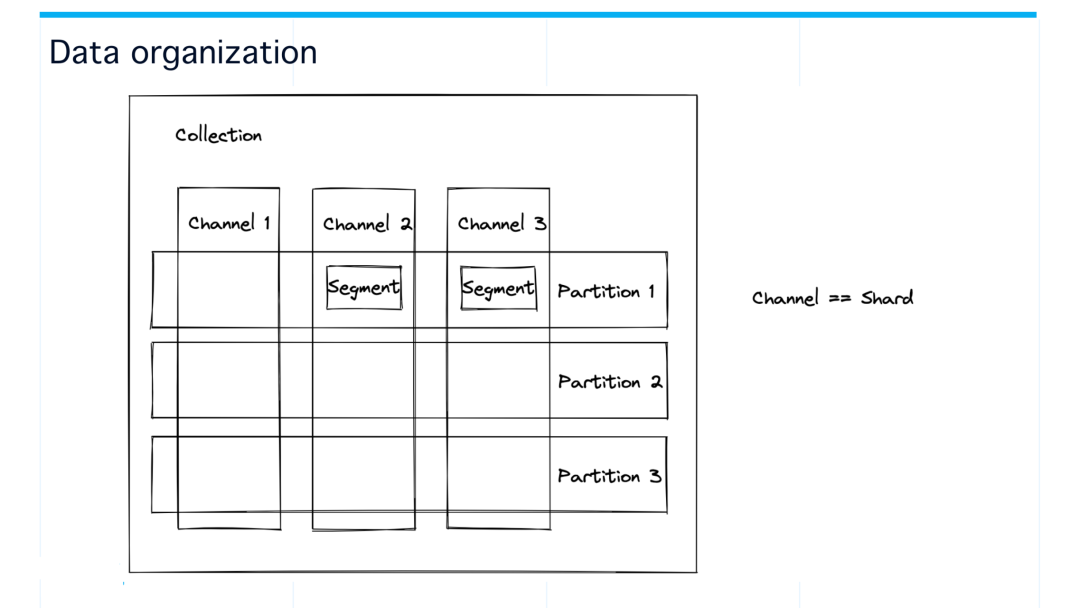
数据组织结构
Collection,partition, channel 和 segment 的关系:
-
Collection:最外层是一个 collection (相当于表的概念), collection 里面会分多个 partition。
-
Partition:每个 partition 以时间为单位去划分;partition 和 channel 是一个正交的关系,就是每一个 partition 和每一个 channel 会定义一个 segment 的位置。(备注:channel 和 shard 是一样的概念:我们文档里可能有些地方写的是 shard,shard 这个概念和 channel 是等价的。为了前后统一,我们这里统称为 channel 。)
-
Segment:Segment 是由 collection+partition+channel 这三者一起来定义的。segment 是数据分配的一个最小的单元。索引以 segment 为单位创建,查询也会以 segment 为单位在不同的 query node 上做 load balance。在 segment 内部会有一些 binlog,就是当我们消费数据之后,会形成一个 binlog 文件。

Segment 在内存中的状态有 3 种,分别是 growing、sealed 和 flushed。Growing:当新建了一个 segment 时就是 growing 的状态,它在一个可分配的状态。Sealed:Segment 已经被关闭了,它的空间不可以再往外分配。Flushed:Segment 已经被写入磁盘
Growing segment 内部的空间可以分为三部份:
-
Used (已经使用的空间):已经被 data node 消费掉。
-
Allocated:Proxy 向 data coord deletor 去请求 segment 分配出的空间。
-
Free:还没有用到的空间。
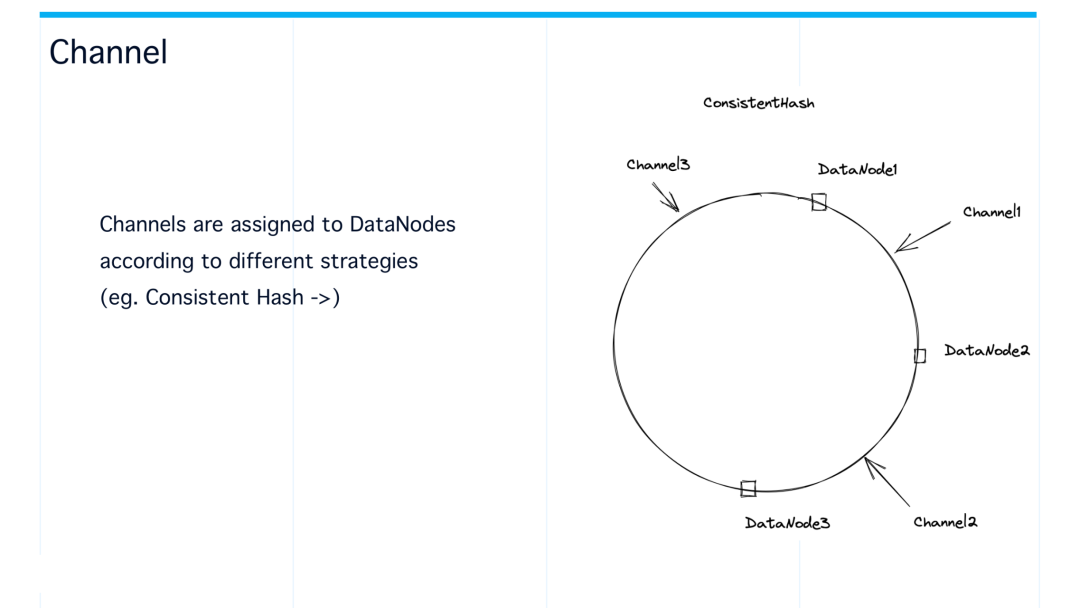
一致性哈希 现在系统内部的一个默认的策略是通过一致性哈希来做分配。就是每个 channel 先做一个哈希,然后在这个环上找一个位置,然后通过顺时针找到离它最近的一个节点,把这个 channel 分配给这个 data node,比如说 channel 1 分给 data node 2, channel 2 分给 data node 3。
-
Channel:
-
Data node 启动/下线
-
Proxy 请求分配 segment 空间时
-
Channel 的分配逻辑为何?每一个 collection 它会分为多个 channel,然后每一个 channel 都会给到一个 data node 去消费这里面的数据,然后我们会有比较多的策略去做这个分配。Milvus 内部目前实现了 2 种分配策略:
-
那什么时候分配 Channel?
-
尽量将同一个 collection 的 channel 分布到不同的 data node 上,且不同 data node 上 channel 数量尽量相等,以达到负载均衡。如果 data coord 通过一致性希这种方案来做的话,data node 的增减,也就是它上线或者下线都会导致一个 channel 的重新分配。然后我们是怎么做的呢?Data coord 通过 etcd 来 watch data node 状态,如果 data node 上下线的话会通知到 data coord,然后 data coord 会决定这个 channel 之后分配到哪里。
-
![]()
什么时候进行数据分配?
这个流程首先从 client 开始 (如上图所示)
-
插入请求,然后产生一个时间戳- t1。
-
Proxy 向 data coord 发送一个分配 segment 的请求。
-
Data coord 进行分配,并且把这个分配的空间存到 meta server 里面去做持久化。
-
Data coord 再把分配的空间返回给 proxy, proxy 就可以用这部分空间来存储数据。从图中我们可以看到有一个 t1 的插入请求,而我们返回的那个 segment 里面有一个过期时间是 t2。从这里就可以看到,其实我们的 t1 一定是小于 t2。这一点在后面的文章将详细解释。
![]()
如何分配 segment?
当我们 data coord 在收到分配的请求之后,如何来做分配?
首先我们来了解 insert request 包含了什么?它包含了 CollectionID、PartitionID、Channel 和 NumOfRows。
Milvus 目前有多个策略:
默认的策略:如果目前有足够空间来存这些 rows,就优先使用已创建的 segment 空间;如果没有,则新建 segment。如何判断空间足够?前文我们讲到 segment 有三部分,一个是已经使用的部分,一个是已经分配的部分,还有空余的部分,所以,空间=总大小-已经使用-已分配的,结果可能比较小,分配空间随着时间会过期,free 部分也就会变大。
1 个请求可以返回 1 或多个 segment 空间,我们 segment 最大的大小是在 data_coord.yaml 这个文件里有清楚定义。
![]()
数据过期的逻辑
-
每一次分配出去的空间都会带一个过期时间(time tick 可比较)
-
数据 insert 时会分配一个 time tick,然后再请求 data coord 分配 segment,所以这个 time tick 一定小于 T。
-
过期的时间默认是 2000 毫秒,这个是通过这 data_coord.yaml 里的 segment.assignmentExpiration这个参数来定义的。
![]()
何时 seal segment?
上面提到的分配一定是针对对 growing 这个状态的 segment,那什么时候状态会变成 sealed?
Sealed segment 表示这个 segment 的空间不可以再进行分配。有几种条件可以 seal 一个 segment:
-
空间使用了达到上限(75%)。
-
收到 flush collection 要把这个 collection 里面所有的数据都持久化,这个 segment 就不能再分配空间了。
-
Segment 存活时间太长。
-
太多 growing segment 会导致 data node 内存使用较多,进而强制关闭存活时间最久的那一部分 segment。

何时落盘?
Flush 是把 segment 的数据持久化到对象存储。
我们需要等待它所被分配到的空间过期,然后我们才能去执行 flush 操作。Flush 完了之后,这个 segment 就是一个 flushed segment。
那这个等待具体的操作为何?
Data node 上报消费到的 time tick ,接着与分配出去空间的 time tick 做比较,如果 time tick 较大,说明这部分空间已经可以释放了。如果比最后一次分配的时间戳大,说明分配出去空间都释放了,不会再有新的数据写入到这个 segment,可以 flush。

常见的问题和细节
-
我们怎么保证所有的数据都被消费了之后,这个 segment 才被 flush?Data node 会告诉 data coord 目前 channel 消费到那个时间戳,time tick 表示之前的数据都已经消费完了,这时候关闭是安全的。
-
在 segment flush 之后,如何保证没有数据再写入?因为 flush 和 sealed 的这个状态的 segment 都不会再去分配空间了,所以它就不会再有数据写入。
-
Segment 大小是严格限制在 max size 这个空间吗?无严格限制,因为 segment 可以容纳多少条数据是估算得到的。
-
怎么估算的呢?通过 schema 来估算。
-
如果用户频繁的调用 flush 会发生什么事?会生成很多小的 segment,导致查询效率受影响。
-
Data node 在重启之后,如何避免数据被消费多次?Data coord 会记录最新 segment 的数据在 message channel 中的位置,下次分配 channel 时,告诉 data node segment 已经消费的位置,data node 再进行过滤。(不是全量过滤)
-
什么时候来创建索引?
-
用户手动调用 SDK 请求
-
Segment flush 完毕后会自动触发
文件结构及数据持久化
![]()
Data node flush
Data node 会订阅 message store,因为我们的插入请求都是在 message store 里面。通过订阅它就可以不断地去消费这个 insert message, 接着我们会把这个插入请求放到一个内存的 buffer 里面。在积累到一定的大小后,它会被 flush 到一个对象存储里面。(对象存储里面存储的就是 binlog。)
因为这个 buffer 的大小是有限的,所以不会等到 segment 全部消费完了之后再往下写,这样的话容易造成内存紧张。
![]()
文件结构
Binlog 文件的结构和 MySQL 相似。
Binlog 主要有两个作用,第一个就是通过 binlog 来恢复数据,第二个就是索引创建。
Binlog 里面分成了很多 event,每个 event 都会有两部分,一个是 event header 和 event data。Event header 存的就是一些元信息,比如说创建时间、写入节点 ID、event length 和 NextPosition (下个 event 的偏移量)
Event data 分成两部分,一个是 fixed part (固定长度部分的大小);另一个是 variable part (可变部分的大小),是为我们之后做扩展来保留的一部分。
![]()
INSERT_EVENT 的 event data 固定的部分主要有三个,StartTimestamp、EndTimestamp 和 reserved。Reserved 也就是保留了一部分空间来扩展这个 fixed part。Variable part 存的就是实际的插入数据。我们把这个数据序列化成一个 Parquet 的形式存到这个文件里。
![]()
Binlog 持久化
如果 schema 里有 12345 多列,Milvus 会以列存的形式来存 binlog。
从上图来看,第一个是 primary key 的 binlog,再来是 Time Stamp 这个 column,再往后是 schema 里面定义的 12345 每一个 column,它存在 MinIO 里的个路径是这样定义的:首先是一个租户的 ID,之后是一个 insert log,然后再往后是 collection、partition、segment ID、field ID 和 log index。log index 是一个 unique ID。反序列化时把多个 binlog merge 起来。
最近发布的版本中,有用户反馈说需要指定ID进行删除,于是我们实现了细粒度删除( delete by ID )的功能,自此我们可以高效的来删除指定的内容了,而不用进行等待啥的;同时我们增加了 compaction 功能,它可以把 delete 已经释放了的一部分空间做释放,同时把小的 segment 合并起来,提高查询效率。
目前,为了解决用户在数据量较大且数据是逐条插入的情况下的低效问题,我们正在做一个 bulk load 的功能,让用户把数据组织成一定形式之后,可以将它一次加载到我们的系统里面。
如果你在使用的过程中,对 Milvus 有任何改进或建议,欢迎在 GitHub 或者各种官方渠道和我们保持联系~
Zilliz 以重新定义数据科学为愿景,致力于打造一家全球领先的开源技术创新公司,并通过开源和云原生解决方案为企业解锁非结构化数据的隐藏价值。
Zilliz 构建了 Milvus 向量数据库,以加快下一代数据平台的发展。Milvus 数据库是 LF AI & Data 基金会的毕业项目,能够管理大量非结构化数据集,在新药发现、推荐系统、聊天机器人等方面具有广泛的应用。

阅读原文,解锁更多应用场景


