
- 1笔记 GWAS 操作流程2-4:哈温平衡检验
- 2自动化测试脚本 Selenium WebDriver(Java)常用 API 汇总
- 3记录一下Termux的配置过程_termux github
- 4Hadoop3.1.3安装教程_单机/伪分布式配置
- 5【数据库系统工程师】1.1计算机硬件基础知识_系统工程师硬件知识
- 6Android studio开发的App闪退问题解决方法之一
- 7python音乐管理系统 计算机专业毕业设计源码83260_数据库音乐管理系统
- 8安装、破解Navicat Premium 12.0.18
- 9谷粒商城学习笔记(17.秒杀系统)_谷粒商城 优惠营销系统
- 102022年甘肃省职业院校技能大赛“网络搭建与应用”赛项_网络搭建技能大赛
InstantID_instant_id
赞
踩
只需一张照片,无需模型训练,短短几十秒内,生成多种风格强烈的写真,还能保持面貌特征不变!
一张照片,为深度学习巨头们定制人像图片,主题驱动的文本到图像生成,通常需要在多张包含该主题(如人物、风格)的数据集上进行训练,这类方法中的代表工作包括 DreamBooth、Textual Inversion、LoRAs 等,但这类方案因为需要更新整个网络或较长时间的定制化训练,往往无法很有效地兼容社区已有的模型,并无法在真实场景中快速且低成本应用。而目前基于单张图片特征进行嵌入的方法(FaceStudio、PhotoMaker、IP-Adapter),要么需要对文生图模型的全参数训练或 PEFT 微调,影响原本模型的泛化性能,缺乏与社区预训练模型的兼容性,要么无法保持高保真度。
为了解决这些问题,来自 InstantX 团队的研究人员提出了 InstantID,该模型不训练文生图模型的 UNet 部分,仅训练可插拔模块,在推理过程中无需 test-time tuning,在几乎不影响文本控制能力的情况下,实现高保真 ID 保持。
-
论文标题:InstantID: Zero-shot Identity-Preserving Generation in Seconds
-
论文地址:https://arxiv.org/abs/2401.07519
-
代码地址:https://github.com/InstantID/InstantID
-
项目地址:https://instantid.github.io
InstantID 是一个高效的、轻量级、可插拔的适配器,赋予预训练的文本到图像扩散模型以 ID 保存的能力。作者通过(1)将弱对齐的 CLIP 特征替换为强语义的人脸特征;(2)人脸图像的特征在 Cross-Attention 中作为 Image Prompt 嵌入;(3)提出 IdentityNet 来对人脸施加强语义和弱空间的条件控制,从而增强 ID 的保真度以及文本的控制力。
下图为利用 InstantID 进行风格化的结果,输入仅为最左侧的人物图像。

文章的主要贡献如下:
(1) InstantID 作为一种全新的 ID 保留方法,有效弥补了训练效率与 ID 保真度之间的差距。
(2)InstantID 是可插拔的,与目前社区内文生图基础模型、LoRAs、ControlNets 等完全兼容,可以零成本地在推理过程中保持人物 ID 属性。此外,InstantID 保持了良好的文本编辑能力,使 ID 能够丝滑地嵌入到各种风格当中。
(3)实验结果表明,InstantID 不仅超越目前基于单张图片特征进行嵌入的方法(IP-Adapter-FaceID),还与 ROOP、LoRAs 等方法在特定场景下不分伯仲。它卓越的性能和效率激发了其在一系列实际应用中的巨大潜力,例如新颖的视图合成、ID 插值、多 ID 和多风格合成等。

在个性化图像生成领域,传统如 DreamBooth、Textual Inversion 和 LoRAs,通常依赖于在特定主题(例如人物或风格)的数据集上进行训练。这些方法虽然在生成特定主题图像方面表现出色,但由于需要对整个网络进行更新或进行长时间的定制化训练,它们在实际应用中往往难以与社区现有的预训练模型兼容,且难以实现快速和低成本的部署。与此同时,基于单张图片特征的嵌入方法,例如 FaceStudio、PhotoMaker 和 IP-Adapter,虽然避免了全面训练的需求,但它们要么需要对文生图模型进行全参数训练或PEFT微调,这可能会损害模型的泛化能力,要么在保持图像高保真度方面存在不足。
为了解决这些技术挑战,小红书 InstantX 团队提出 InstantID,该模型不训练文生图模型的 UNet 部分,仅训练可插拔模块,在推理过程中无需 test-time tuning,在几乎不影响文本控制能力的情况下,实现高保真 ID 保持。
InstantID 是一个高效的、轻量级、可插拔的适配器,赋予预训练的文本到图像扩散模型以 ID 保存的能力。重点工作分为以下几步:
Step 1: 将弱对齐的 CLIP 特征替换为强语义的人脸特征;
Step 2: 人脸图像的特征在 Cross-Attention 中作为 Image Prompt 嵌入;
Step 3: 提出 IdentityNet 来对人脸施加强语义和弱空间的条件控制,从而增强 ID 的保真度以及文本的控制力。
方法介绍
仅给定一张参考 ID 图像,InstantID 的目标是从单个参考 ID 图像生成具有各种姿势或风格的定制图像,同时保证高保真度。上图概述了我们的方法。它包含三个关键组成部分:(1) 鲁棒的人脸表征;(2) 具有解耦功能的交叉注意力,支持 Image Prompt;(3) IdentityNet,引入额外的弱空间控制对参考面部图像的复杂特征进行编码。
1. 由于 CLIP 只提供了弱语义表征,无法在人脸等强语义场景下直接应用,考虑了人脸识别领域已经相当成熟,所以我们采用预训练的人脸编码器来提取人脸特征。在本文中,我们使用来自 insightface 提供的 antelopev2 模型来提取人脸特征。
2. 如先前方法所述,预训练的文本到图像扩散模型中的图像提示功能能够增强了文本提示,特别是对于难以用文字描述的内容,因此,我们采用和 IP-Adapter 一致的具有解耦功能的交叉注意力机制,但差别在于我们使用人脸特征,而非 CLIP 表征。
3. 引入 IdentityNet 来对人脸图像进行编码。在实现中,IdentityNet 采用与 ControlNet 一致的残差结构,从而保持原始模型的兼容性。在 IdentityNet 中,主要有两个对于原版 ControlNet 的修改:1)只使用五个面部关键点,而不是细粒度的 OpenPose 面部关键点 (两个用于眼睛,一个用于鼻子,两个用于嘴巴)用于条件输入。2)我们消除文本提示并使用 ID 嵌入作为条件加入到 ControlNet 中的交叉注意力层。
-
只使用五个面部关键点,而不是细粒度的 OpenPose 面部关键点 (两个用于眼睛,一个用于鼻子,两个用于嘴巴)用于条件输入。
-
消除文本提示并使用 ID 嵌入作为条件加入到 ControlNet 中的交叉注意力层。从实验结果上来看,作者首先展示了方法的稳健性、可编辑性和兼容性,分别对应在空文本、编辑文本、额外使用 ControlNets 下的生成效果。可以看到,InstantID 仍然保持了较好的文本控制能力,同时与开源的 ControlNet 模型兼容。
同时该方法也支持多张图注入,来进一步提升效果。
实验结果
作者首先展示了方法的稳健性、可编辑性和兼容性,分别对应在空文本、编辑文本、额外使用 ControlNets 下的生成效果。可以看到,InstantID 仍然保持了较好的文本控制能力,同时与开源的 ControlNet 模型兼容。

同时该方法也支持多张图注入,来进一步提升效果。

InstantID 与目前社区内主流的三类方法进行对比。
(1)基于单图特征注入(IP-Adapter 与 PhotoMaker)。相比之下,IP-Adapter 具有可插拔性,兼容社区模型,且其 FaceID 版本的人脸保真度有明显提升,但是对于文本的控制能力出现明显退化;而近期新推出的 PhotoMaker,需要训练整个模型(虽然采用了 LoRA 的方式),风格退化问题减弱,但其人脸保真度未见明显提升,甚至不如 IP-Adapter-FaceID。而我们提出的 InstantID 兼顾了人脸保真度和文本控制能力。 whaosoft aiot http://143ai.com

(2)基于微调的人物 LoRAs

(3)非扩散模型的换脸模型 inswapper
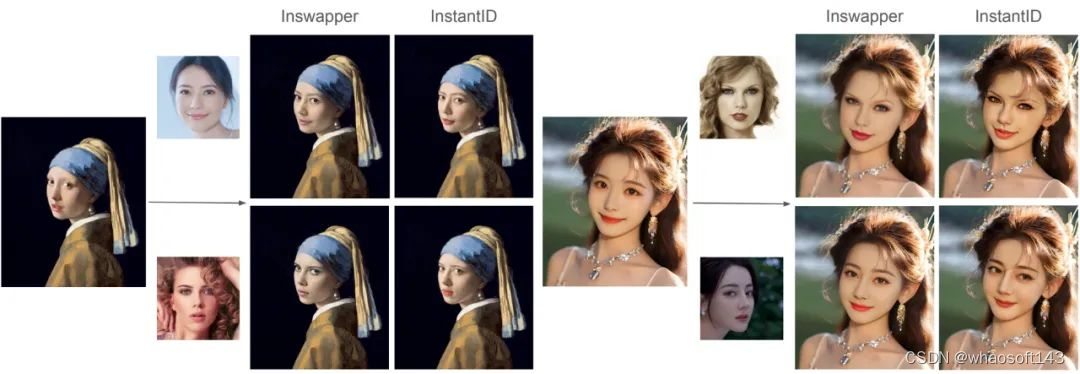
此外,InstantID 还支持了多视角生成、ID 插值、多 ID 生成,作为潜在应用场景。
(1)多视角生成

(2)ID 插值
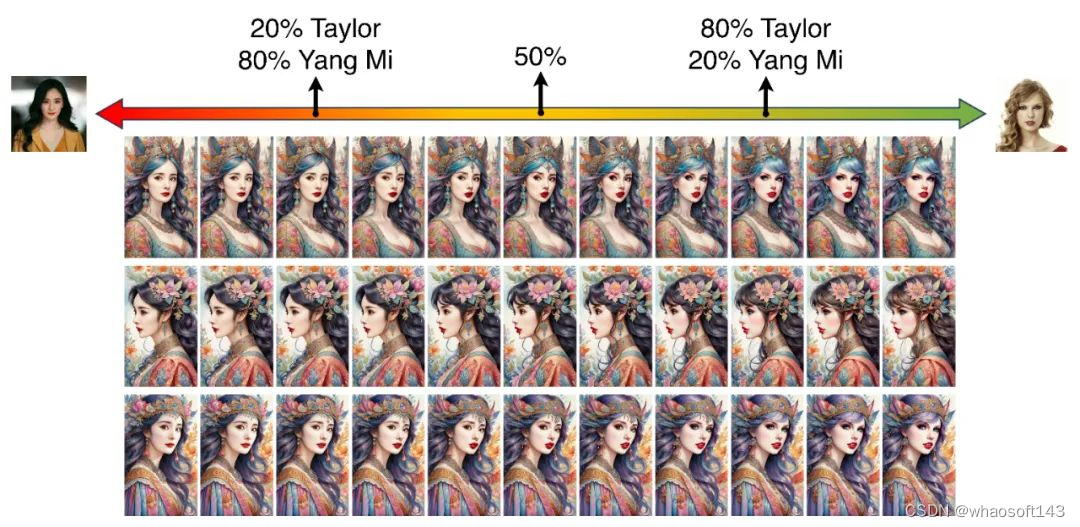
(3)多 ID + 多风格的生成

衍生应用玩法
基于高性能的人像注入和编辑能力,InstantID可以支持很多衍生应用玩法
(1)快速低门槛的真人写真

(2)夸张五官人像定制

(3)非人像混合定制


