
- 1笔记 GWAS 操作流程2-4:哈温平衡检验
- 2自动化测试脚本 Selenium WebDriver(Java)常用 API 汇总
- 3记录一下Termux的配置过程_termux github
- 4Hadoop3.1.3安装教程_单机/伪分布式配置
- 5【数据库系统工程师】1.1计算机硬件基础知识_系统工程师硬件知识
- 6Android studio开发的App闪退问题解决方法之一
- 7python音乐管理系统 计算机专业毕业设计源码83260_数据库音乐管理系统
- 8安装、破解Navicat Premium 12.0.18
- 9谷粒商城学习笔记(17.秒杀系统)_谷粒商城 优惠营销系统
- 102022年甘肃省职业院校技能大赛“网络搭建与应用”赛项_网络搭建技能大赛
WAIC2024:图像内容安全黑科技助力可信AI发展_图像安全领域(1)
赞
踩
先自我介绍一下,小编浙江大学毕业,去过华为、字节跳动等大厂,目前阿里P7
深知大多数程序员,想要提升技能,往往是自己摸索成长,但自己不成体系的自学效果低效又漫长,而且极易碰到天花板技术停滞不前!
因此收集整理了一份《2024年最新网络安全全套学习资料》,初衷也很简单,就是希望能够帮助到想自学提升又不知道该从何学起的朋友。
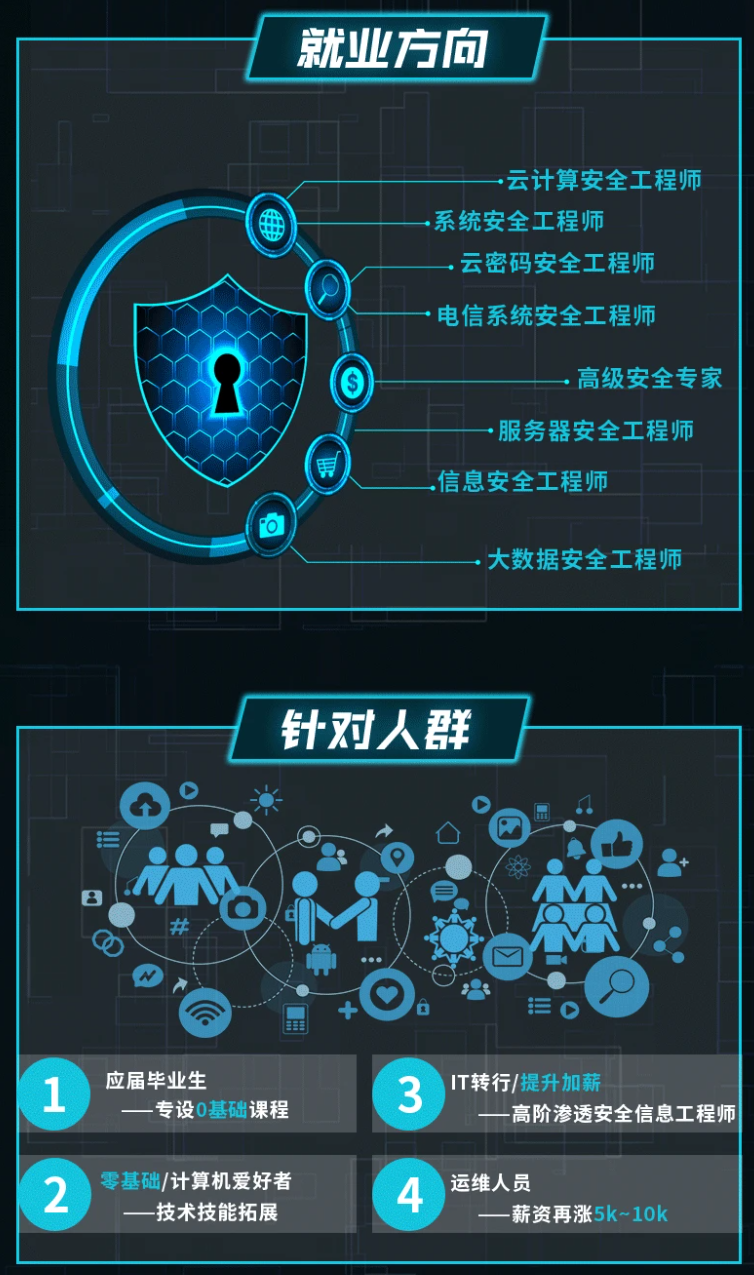
既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,涵盖了95%以上网络安全知识点,真正体系化!
由于文件比较多,这里只是将部分目录截图出来,全套包含大厂面经、学习笔记、源码讲义、实战项目、大纲路线、讲解视频,并且后续会持续更新
如果你需要这些资料,可以添加V获取:vip204888 (备注网络安全)

正文
0 写在前面
2023世界人工智能大会(WAIC)已圆满结束,恰逢全球大模型和生成式人工智能蓬勃兴起之时,今年参会的人们更加关注AIGC技术在未来可以如何作用于人们的生活。

自AIGC技术兴盛以来,生成式造假也让人们倍感忧虑。
图像是信息的重要载体,也是信息保护的重点关注对象。图像编辑软件的发展和普及降低了虚假图像的制作门槛,大量基于虚假图片产生的诈骗案件、网络暴力事件在全球范围内造成了恶劣的影响。图像内容的安全与可信性也成为了公众关注的焦点,但图像领域的“可信AI”才刚刚起步。
在本次世界人工智能大会可信AI论坛上,合合信息展示了“三大技术,一项标准”,探索AI在图像内容安全领域可信化发展的多重可能
1 AI图像篡改检测
**篡改文本检测(TTD,tampered text detection)**作为多媒体信息安全领域的一个新兴研究方向,是指通过对文本图像中纹理特征的分析,捕捉真实文本和篡改文本之间的纹理差异性,以确定文本图像中文字区域的真伪性。常见的应用场景有:谣言检测流水、合同造假识别、欺诈图像识别、学历造假检测、保单PS检测等。
篡改文本检测任务有两个主要挑战。
- 局部纹理差异性捕捉困难。篡改文本与真实文本仅存在局部纹理差异;
- 真实和篡改文本检测精度平衡困难。
P图是常见的图像篡改手段之一。去年的世界人工智能大会上,合合信息PS篡改检测技术首次亮相,像素级起底修改痕迹,覆盖身份证、护照等多种证照识别类目,吸引了社会各界关注。该技术基于深度学习的图像篡改检测技术及相关系统,通过学习图像被篡改后统计特征的变化,智能捕捉图像在篡改过程中留下的细微痕迹,并以热力图的形式展示图像区域篡改地点,相关技术已在银行、保险等领域落地应用
今年图像篡改检测“黑科技”持续优化升级,应用面也拓展至截图篡改检测。此前,图像篡改检测的技术研究对象主要集中于自然场景图像,然而,真正为人们的生活带来风险的通常是被篡改的资质证书、文档、截图等。

合合信息AI图像篡改检测技术可检测包括转账记录、交易记录、聊天记录等多种截图,无论是从原图中“抠下”关键要素后移动“粘贴”至另一处的“复制移动”图片篡改手段,还是“擦除”、“重打印”等方式,图像篡改检测技术均可“慧眼”识假
这类截图篡改检测比传统篡改检测更困难,原因在于,与自然图像相比,截图的背景没有纹路和底色,整个截图没有光照差异,难以通过拍照时产生的成像差异进行篡改痕迹判断,现有的视觉模型通常难以充分发掘原始图像和篡改图像的细粒度差异特征。
2 生成式图像鉴别
相较传统的文本检测任务,生成式篡改文本检测任务需要进一步区分篡改和真实文本。由于真实和篡改文本分类难度不一致,训练过程中网络无法平衡两类的学习过程,导致在测试过程中两类检测精度差异较大。上述挑战极大地限制了篡改文本检测方法的性能。因此,如何准确地捕捉局部纹理差异性,同时平衡篡改和真实类别学习难度,是目前篡改文本检测研究的重要方向。
该任务的难点主要分为两点
- 生成出来的图像场景繁多,不能穷举,不能通过细分来一一训练解决;
- 有些生成图和真实图片的相似度过高,很贴近于人类的判断,对于机器而言,真伪判定只会更难
为此,合合信息提出了一种基于HRNet的编码器-解码器结构的图像真实性鉴别模型,结合图像本身的信息包括但不限于噪声、频谱等,能够在不用穷举图片的情况下,利用多维度特征来捕捉真实图片和生成式图片细粒度的视觉差异,达到高精度鉴别目的。模型结构如下图所示

2.1 主干特征提取通道
上述模型的第一个通道由若干主干提取网络层组成
**主干提取网络(Backbone Network)**在计算机视觉任务中扮演着关键的角色,通过一系列的卷积层、池化层和激活函数等操作,从原始图像中提取出各种特征,这些特征具有较好的局部感受野和平移不变性,能够捕捉到图像的结构和纹理信息,负责提取图像特征的主要组成部分。

主干网络的目标是将输入的图像转化为高级语义特征表示,通常是一系列的特征图。通过多层的卷积和非线性激活函数,主干网络可以学习到图像中的抽象特征表示。这些特征表示具有层次化的结构,能够逐渐提高语义表达能力,从低级的边缘、角点到高级的物体形状和语义信息,为后续的任务提供了更丰富和有意义的输入。同时,主干网络通常采用多层卷积和池化操作,可以在不同的层次上提取特征。这样的设计使得网络对于不同尺度的目标具有一定的感知能力,能够处理从小物体到大物体的尺度变化。在一些任务中,主干网络还可以进行特征融合操作,将来自不同层次的特征进行组合,以获取更全局和综合的特征表示。例如,通过连接或级联多个分辨率的特征图,可以获得更好的目标检测或语义分割结果。
2.2 注意力模块
**注意力机制(Attention Mechanism)**在计算机视觉任务中发挥着重要的作用。它是一种模拟人类视觉系统中注意力机制的方法,通过对输入的图像或特征进行加权,将注意力集中在具有重要信息的区域上,从而提高任务的性能和效果。

举例而言,在目标检测任务中,注意力机制能够帮助模型更关注感兴趣的目标区域,提高检测的准确性和鲁棒性。通过将注意力权重应用于特征图中的不同位置,可以突出目标的位置并抑制背景信息;在图像分类任务中,注意力机制可以提高模型对图像中重要区域的关注度,减少对无关区域的注意力分配。通过将注意力权重应用于特征图的不同通道,可以选择性地突出重要的图像特征,提高分类的准确性;在语义分割任务中,注意力机制可以帮助模型更好地理解图像的语义结构。通过对特征图的每个像素位置应用注意力权重,可以增强重要的语义区域并抑制非重要区域,从而提高分割的精度和细节。
而在本文介绍的图像生成任务中,注意力机制可以用于生成具有更好质量和多样性的图像。通过对生成器模型的输入特征进行加权,可以指导生成过程集中在重要的特征或区域上,生成更真实的图像结果进行对抗训练。
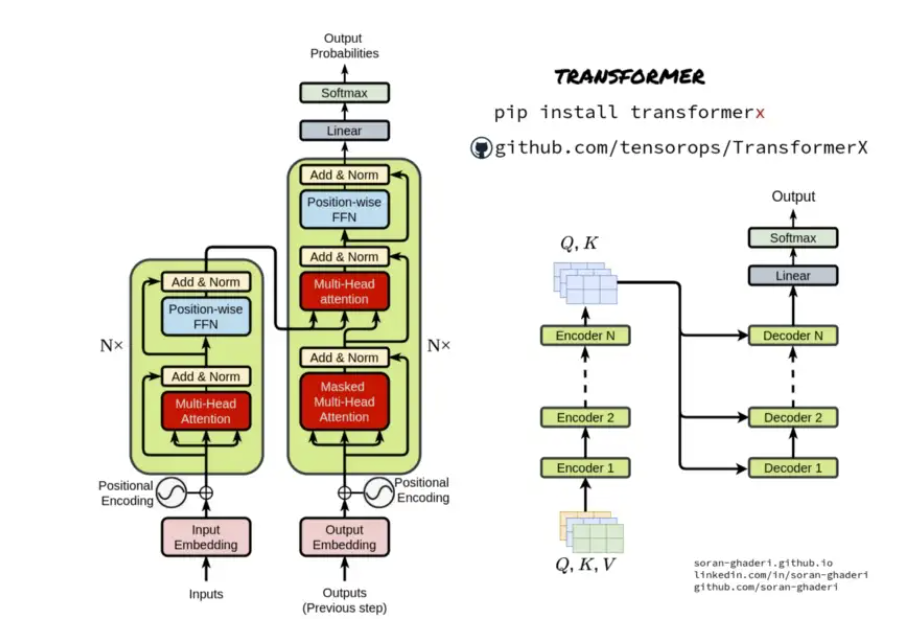
现在热门的Transformer也正是基于注意力机制构建
2.3 纹理增强模块
对于纹理缺失的截图图像鉴别而言,纹理增强模块扮演着重要的角色。它的作用是通过增强图像的纹理信息,提供更丰富、更清晰的视觉特征,从而改善图像分析和理解的效果。
纹理增强模块首先对输入图像进行预处理,包括去噪、平滑等操作,以减少噪声对后续处理的影响;接着利用各种纹理特征提取算法,如局部二值模式(Local Binary Patterns, LBP)、**方向梯度直方图(Histogram of Oriented Gradients, HOG)**等,提取图像中的纹理信息。根据提取的纹理特征,使用图像增强算法对图像进行增强,如调整对比度、增加锐度等,使纹理信息更加清晰和鲜明。最后,根据具体任务的需求,可以对增强后的图像进行后处理,如去除无关的纹理信息、进一步提取图像特征等。
总之,纹理增强模块可以帮助算法在低对比度、模糊、噪声等不良环境下更好地工作,提升算法的鲁棒性和性能。
本人从事网路安全工作12年,曾在2个大厂工作过,安全服务、售后服务、售前、攻防比赛、安全讲师、销售经理等职位都做过,对这个行业了解比较全面。
最近遍览了各种网络安全类的文章,内容参差不齐,其中不伐有大佬倾力教学,也有各种不良机构浑水摸鱼,在收到几条私信,发现大家对一套完整的系统的网络安全从学习路线到学习资料,甚至是工具有着不小的需求。
最后,我将这部分内容融会贯通成了一套282G的网络安全资料包,所有类目条理清晰,知识点层层递进,需要的小伙伴可以点击下方小卡片领取哦!下面就开始进入正题,如何从一个萌新一步一步进入网络安全行业。
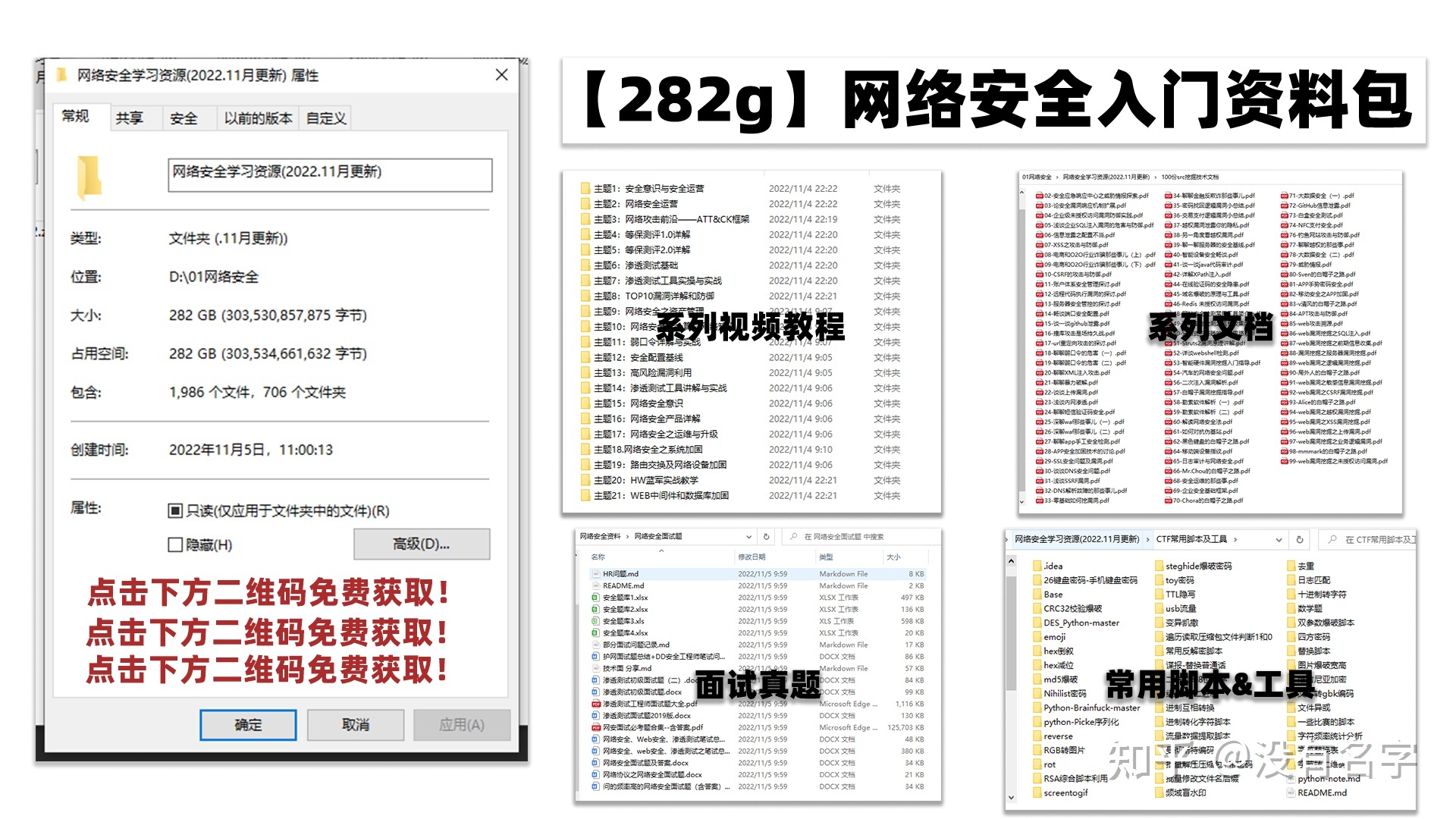
学习路线图
其中最为瞩目也是最为基础的就是网络安全学习路线图,这里我给大家分享一份打磨了3个月,已经更新到4.0版本的网络安全学习路线图。
相比起繁琐的文字,还是生动的视频教程更加适合零基础的同学们学习,这里也是整理了一份与上述学习路线一一对应的网络安全视频教程。
网络安全工具箱
当然,当你入门之后,仅仅是视频教程已经不能满足你的需求了,你肯定需要学习各种工具的使用以及大量的实战项目,这里也分享一份我自己整理的网络安全入门工具以及使用教程和实战。
项目实战
最后就是项目实战,这里带来的是SRC资料&HW资料,毕竟实战是检验真理的唯一标准嘛~

面试题
归根结底,我们的最终目的都是为了就业,所以这份结合了多位朋友的亲身经验打磨的面试题合集你绝对不能错过!
网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
需要这份系统化的资料的朋友,可以添加V获取:vip204888 (备注网络安全)

一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!
需要这份系统化的资料的朋友,可以添加V获取:vip204888 (备注网络安全)*
[外链图片转存中…(img-5Py968XH-1713184427363)]
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!

