华为鸿蒙的问题,采集知乎上关于华为鸿蒙的问题和回答
赞
踩
知乎作为一个知识问答和分享的平台,每当有热点事件发生,上面都会有一些精辟言论,有助于我们快速了解事件的一些情况。我们想要研究华为鸿蒙发布以来的讨论热点,就选取从知乎上收集数据。
采集数据就用到了集搜客的快捷采集应用,这里会用到三个应用“知乎_关键词搜索结果列表_内容”、“知乎_独立问题所有回复采集”和“知乎_专栏文章详情”,下面介绍一下操作。
1.找到数据网址,用集搜客爬虫采集数据
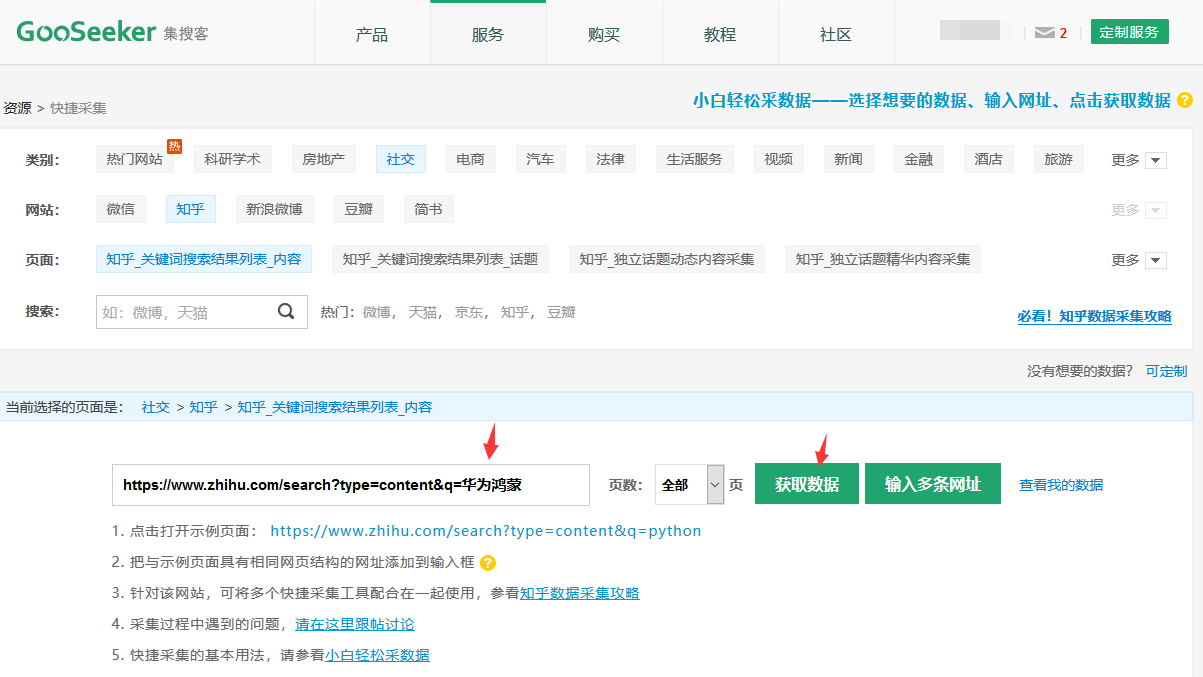
首先要找出关于鸿蒙的问题,在知乎的综合版块上搜索“鸿蒙”,拷贝搜索网址
https://www.zhihu.com/search?type=content&q=%E5%8D%8E%E4%B8%BA%E9%B8%BF%E8%92%99
把网址添加到集搜客的快捷采集“知乎_关键词搜索结果列表_内容”,启动爬虫采集。
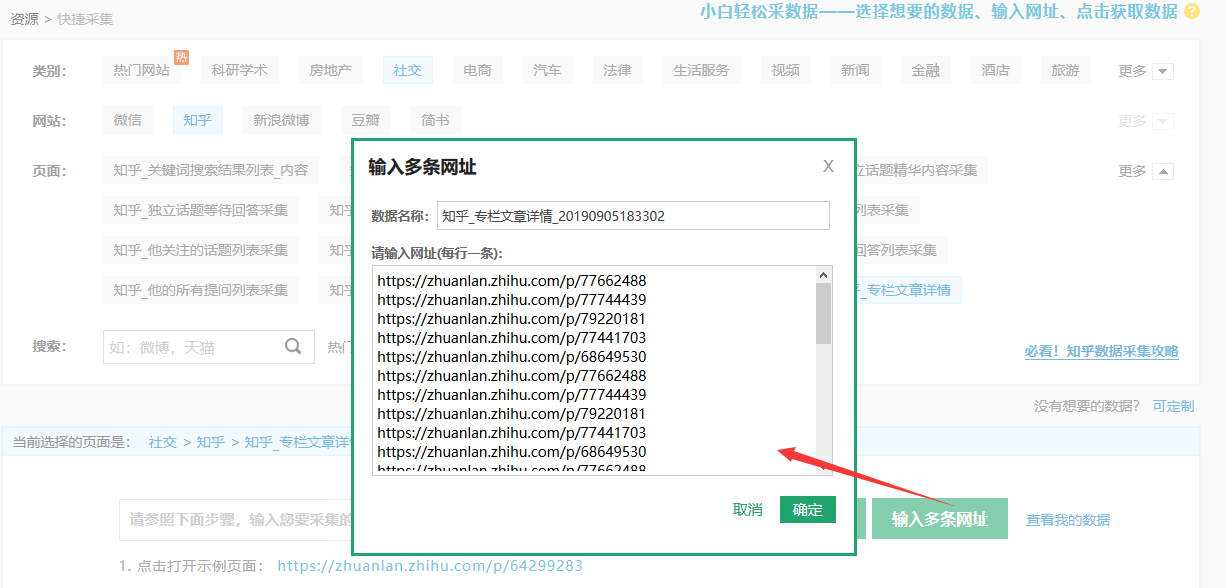
导出数据,采到的数据里不仅有问答类的,还有专栏文章,这两种网页结构不同,所以下一步,要分别对问题的每一个回答内容和专栏文章做采集。
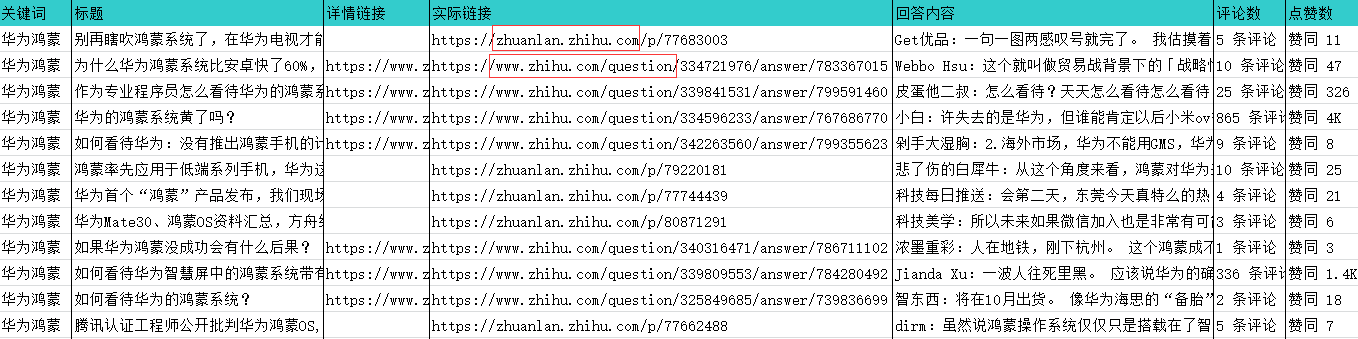
从上表的“详情链接”列拷贝出带有question的问答网址,添加到快捷采集“知乎_独立问题所有回复采集”;再从“实际链接”列筛选出带有zhuanlan的专栏网址,添加到“知乎_专栏文章详情”,然后启动采集。
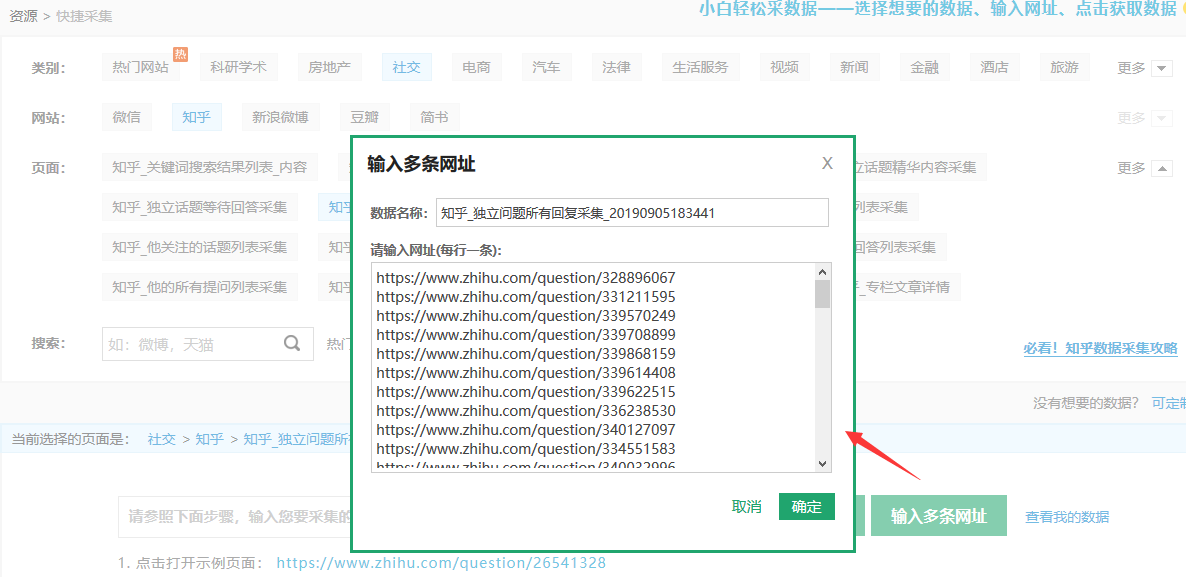
考虑到样本数据的完整性,我们会把问答类数据和专栏文章放一起分析。首先要把数据导出来,后面会把数据导入到集搜客的分词检索系统进行分词处理和分类,所以需要按照它要求的Excel表字段进行规整。
2.数据汇总
问答数据中,问题和回答是一对多的数据关系,需要把标题、回答用户、用户一句话介绍这3列合并到新的标题列里,再删掉原来的3列;专栏文章虽然不是一对多关系,但是也有这3列字段,所以要做同样的处理。
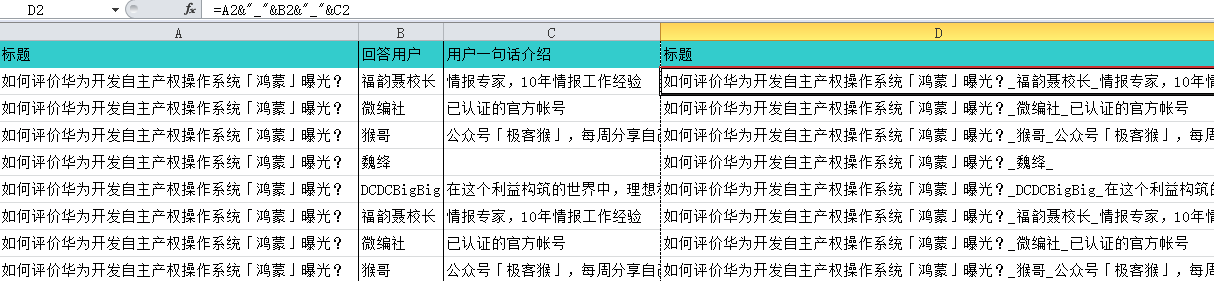
把问答数据和专栏文章的数据,拷贝汇总到一张新表里。按要求修改列名,再增加“序号”列,让数字自增填充,这一列会非常有用,可以用它来关联分词数据表和分类数据表;还要增加“网站来源”列,分别填“知乎问答”、“知乎专栏”加以区分。

3.数据过滤处理
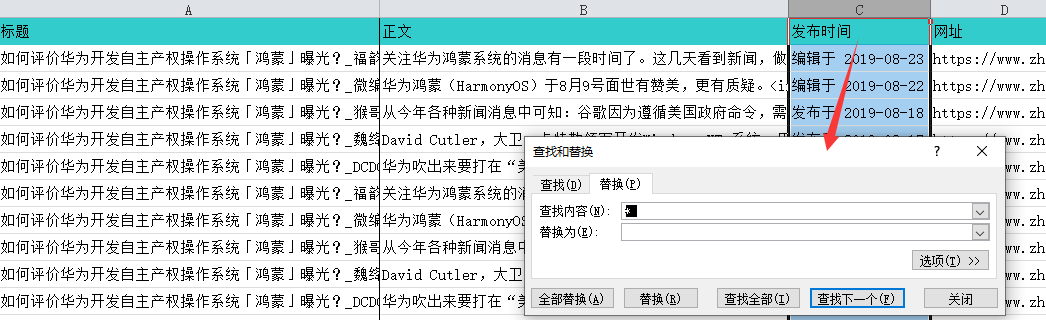
下面是对数据进行过滤。把“发布时间”列用替换功能,整理成统一的时间格式;再过滤掉鸿蒙发布以前的数据。

“正文”的数据里有图片的一些代码,对分词可能会有影响,所以这里用替换功能把它过滤掉。

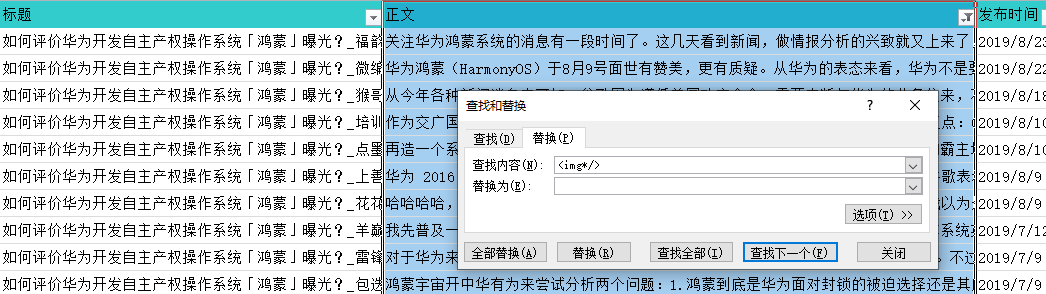
过滤了图片代码后,发现有些数据的“正文”是空的,所以还要筛选出这些数据然后删除。
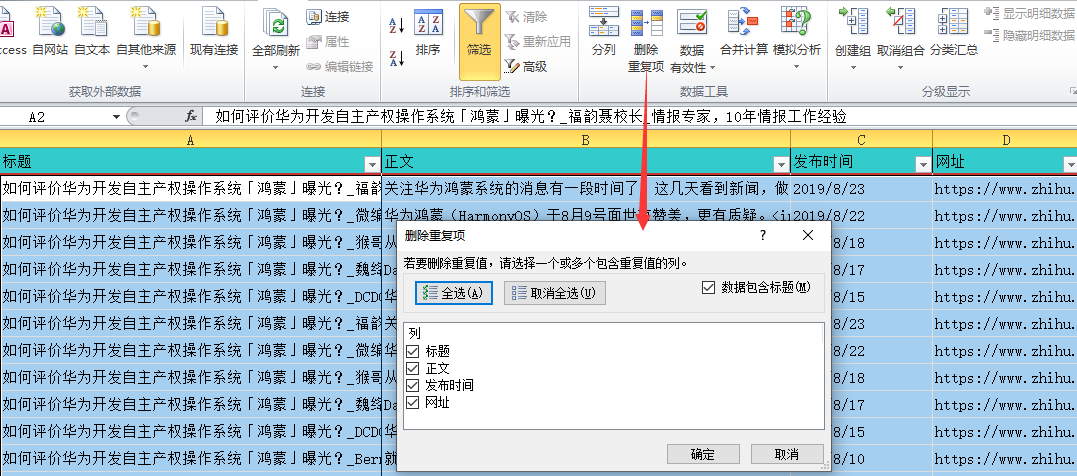
最后是去重,选中几列,然后点“删除重复项”来过滤重复。经过以上的处理,最终汇总得到6208条数据。