
- 1SpringBoot+Vue校园外卖配送系统_外卖系统软件工程
- 2转载:性能测试之新一代服务器性能测试工具Gatling_gatling bench
- 3运行EVO问题汇总:AttributeError: module ‘numpy‘ has no attribute ‘typeDict‘_attributeerror: module 'numpy' has no attribute 't
- 4OpenCV python下载和安装_python下载opencv库
- 5pix4d计算机配置速度,实测大疆智图(DJI Terra)与Pix4D,Smart3D正射三维成果对比...
- 6Python-VBA函数之旅-getattr函数_vba getattr函数
- 7Enterprise Architect(EA)画UML之用例图,敲详细讲解+实战举例_ea用例图
- 8升级openssl
- 9免费使用ChatGPT中文网站推荐_gpt-3官网
- 10VSCode下使用github初步_vscode使用github,万字长文轻松彻底入门Flutter_vscode登录github账号
大模型微调方法:冻结方法 Freeze、P-Tuning 系列、LoRA、QLoRA_大模型微调中full和freeze和lora
赞
踩
冻结方法 Freeze
方法意思是,只用少部分参数训练,把模型的大部分参数冻结。
只要设置微调层的参数:
# 遍历模型的所有参数和名称
for name, param in model.named_parameters():
# 指定冻结层,(layers.27, layers.26, layers.25, layers.24, layers.23)之外的所有参数
if not any(nd in name for nd in ["layers.27", "layers.26", "layers.25", "layers.24", "layers.23"]):
# 将参数的 requires_grad 属性设置为False,即冻结该参数
param.requires_grad = False
- 1
- 2
- 3
- 4
- 5
- 6
举例,当应用 Transformer 模型进行糖尿病问答任务时,微调前面的层和后面的层会产生不同的影响:
微调前面的层:
- 浅层特征捕捉:前面的层更接近输入,可能更多地关注输入的表面特征,例如词语的形态和局部关系。在糖尿病问答任务中,这些浅层特征可能有助于捕捉病人的病史、症状等基本信息。
- 通用特征学习:前面的层在预训练过程中学习了通用的语言特征,这些特征在医学任务中也可能有用。通过微调前面的层,模型可以将这些通用特征应用于糖尿病领域,以提高模型对于糖尿病相关问题的理解能力。
微调后面的层:
- 高级语义捕捉:后面的层能够捕捉更长距离的依赖关系和全局语义。在糖尿病问答任务中,后面的层可以帮助模型理解和捕捉更复杂的医学概念、治疗方案、病理机制等高级语义信息。
- 领域特定知识:后面的层可以通过微调来适应糖尿病领域的特定知识和术语。例如,模型可以学习如何解释血糖、胰岛素、糖尿病并发症等特定概念,从而提供更准确和专业的回答。
总的来说,微调前面的层可以利用浅层特征和通用语义特征,更好地理解基本信息和一般性问题。而微调后面的层则能够更好地捕捉高级语义和领域特定知识,提供更专业和深入的回答。选择微调哪些层取决于任务的需求和数据的特点,可以根据具体情况进行调整。
一般 Freeze 微调,仅微调 Transformer 后几层的全连接层参数,冻结其ta所有参数。
因为大模型已经学习到了丰富的语言表示能力,包括词义、语法和语境信息。
因此,只微调后几层的全连接层参数,可以保留预训练模型的大部分知识,同时通过微调来适应具体任务的特定要求。
Freeze 主要解决的问题:
-
确保模型学习到的知识能够充分利用:在使用预训练模型进行微调时,通常会对整个模型进行端到端的微调。然而,预训练模型已经学习到了丰富的语言表示和知识,直接对整个模型进行微调可能会导致预训练模型学习到的知识被覆盖或忽略。
-
减少微调过程中的计算资源和时间消耗:无梯度更新,低成本训练。
缺点:
- 训练不充分
- 先前能力会遗忘
P-Tuning 系列
P-Tuning(参数微调)是一种针对特定任务的方法,标记和优化预训练模型的特定参数,适应任务需求。
Prefix-Tuning
论文地址:Prefix-Tuning
代码地址:https://github.com/XiangLi1999/PrefixTuning
P-Tuning 是一种通用的参数微调方法,可以用于各种任务和领域。
Prefix Tuning 是用于生成式任务的参数微调 P-Tuning 的方法,通过在输入序列前添加特定标记或提示信息来指导生成式模型的输出。
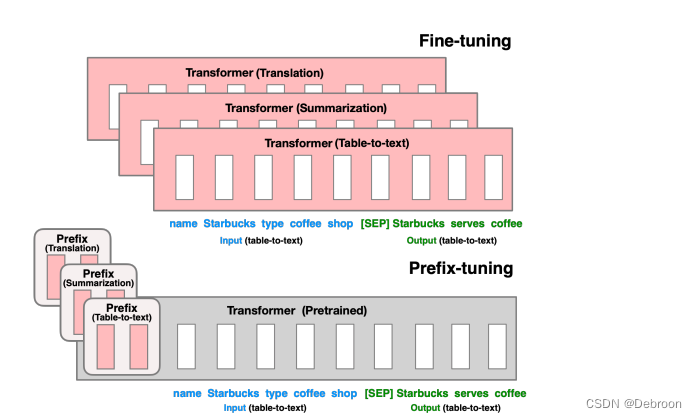
如上图:
- 翻译任务(Translation)
- 摘要任务(Summarization)
- 表格转文本任务(Table-to-text)
是通过在输入序列前面添加一个特定的 Prefix token(比如一个单词、一个短语或一个标记),来为模型提供额外的向量表示信息。

编码器 Encoder 前面加 Prefix token ,是为了帮助模型更好地理解输入的含义
解码器 Decoder 前面加 Prefix token,是为了约束输出的范围或方向,从而产生更合理的生成结果。
prefix部分到底使用多少个虚拟token,直接影响模型微调的参数量级,以及处理长文本的能力。
- 默认的prefix长度为10。
Prefix-Tuning 主要解决的问题:
- 精确控制生成文本的问题:在某些应用场景中,我们需要对生成的文本进行精确的控制,以满足特定的要求或约束。而传统的预训练语言模型往往在生成文本时缺乏控制性,无法准确地生成满足特定要求的文本。
- 快速适应下游任务:当需要将预训练语言模型应用到特定的下游任务时,通常需要进行微调或迁移学习。然而,传统的微调方法可能需要大量的标记样本和计算资源,且微调后的模型可能仍然存在学习和泛化的挑战。
Prompt Tuning
论文地址:https://arxiv.org/pdf/2104.08691.pdf
Prompt 就是指根据输入文本,给予模型一个任务相关的线索或提示。
是 Prefix-Tuning 简化版。
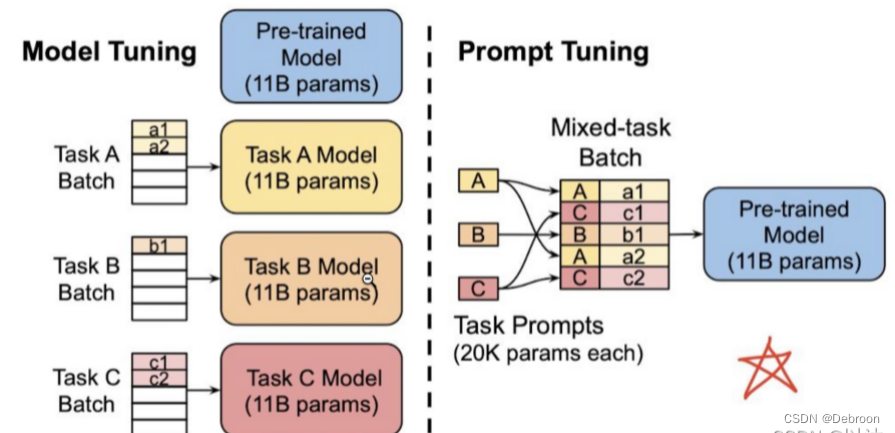
-
左侧图表示了基于 Pretrain+Fine-Tuning 的训练范式,这是传统的方式。对于每个下游任务,需要单独训练一个完全独立的模型,并且每个任务都有自己独立的一套模型参数。每个任务都需要从头开始进行预训练和微调,导致训练过程非常耗时和资源密集。
-
右侧图表示了基于 Prompt Tuning 的训练范式,这是一种更高效的方式。对于不同的任务,只需要通过插入不同的Prompt参数来指导模型生成任务相关的输出。
随着模型参数量的增加,Prompt Tuning 的方法会逼近全参数微调的结果。
通过引入任务相关的提示(prompt),不仅解决了一个模型适应不同的任务要求,还能解决解决零样本和少样本问题,帮助模型在没有足够标记样本的情况下进行准确的预测。
同时,通过在下游任务中插入提示,ta能够缓解预训练模型的雷同问题,使模型更倾向于根据任务要求生成正确的输出。
P-Tuning v1
- 论文地址:P-Tuning v1
P-tuning v1 代码地址:https://github.com/THUDM/P-tuning
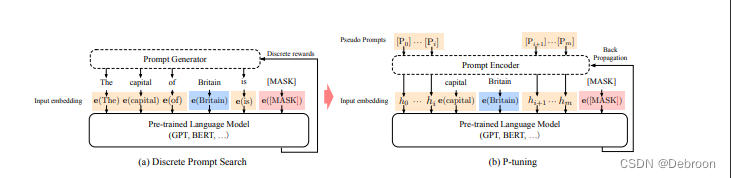
- a图:离散式的 Prompt Tuning
- b图:隐式的 P-Tuning
P-Tuning v1 是一种使用可微的虚拟标记替换离散标记的方法,该方法仅将虚拟标记添加到输入层,并使用 prompt 编码器(BiLSTM+MLP)对虚拟标记进行编码学习。
- 类似 Prefix-Tuning,添加向量
- 学习prompt的两大挑战:超越局部优化、关联性,用轻量神经网络学习prompt embedding:两层LSTM+MLP
举个例子,假设我们有一个语言模型,ta可以根据输入的句子生成一个合适的回答。
现在我们想让这个模型能够回答一些关于动物的问题,如 狗是什么动物?、猫有几条腿?。
传统的做法是为每个问题设计一个模板,将问题中的关键词替换为特定的标记,然后训练模型来预测这些标记。
-
狗是什么动物?
设计模板:[动物]是什么动物?,其中 “[动物]” 是一个特定的标记。
-
花是什么植物?
设计模板:[植物]是什么植物?,其中 “[植物]” 是一个特定的标记。
但是这样的模版需要手动设计,费时费力。
而 P-Tuning v1 可通过训练来自动构建这些模版。
将这些模版转化为可训练的连续参数。
可用一个特殊的标记来代表问题,比如 [QUESTION],然后通过训练来优化这个标记的参数。
比如,当输入 狗是什么动物?时,模型会根据提示:[QUESTION] 是什么动物?
- 来生成回答 狗是一种哺乳动物。
当输入 花是什么植物?时,模型会根据提示:[QUESTION] 是什么植物?
- 来生成回答 花是美丽植物。
P-Tuning v2
- 论文地址:P-Tuning v2
P-Tuning v2 代码地址:https://github.com/THUDM/P-tuning-v2
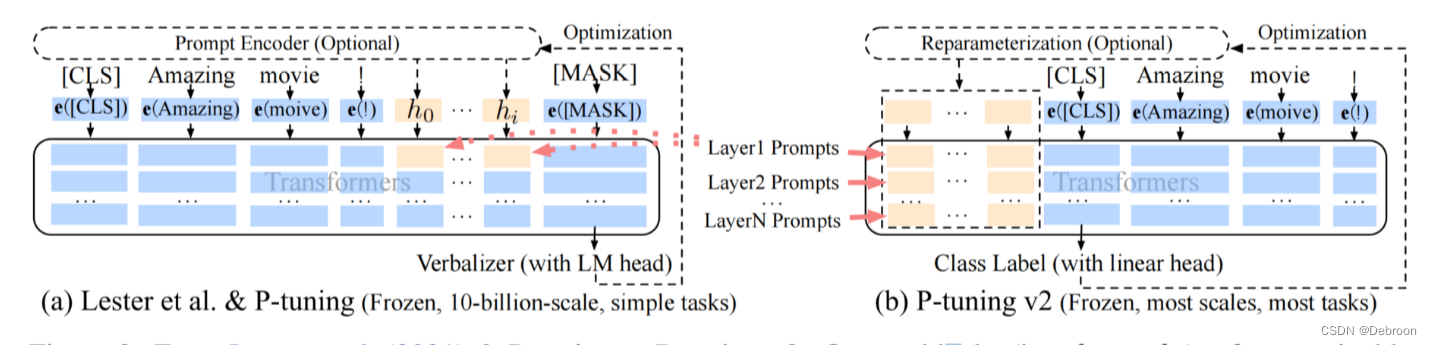
- a 图:黄色块只存在第一层(只加入了第一层)
- b 图:黄色块存在每一层(每层都加了)
之前的 Prompt Tuning、P-Tuning v1 方法存在两个主要问题:
-
缺乏模型参数规模和任务通用性:
-
缺乏任务普遍性:尽管 Prompt Tuning 在某些自然语言理解基准测试中表现出优势,但对于硬序列标记任务(如序列标注)的有效性尚未得到验证。
改进方案:
-
采用多任务学习方法:在基于多任务数据集的提示上进行预训练,并适配到下游任务。这样可以更好地初始化连续提示的伪标记,提供更好的初始化效果。
-
去掉重参数化的编码器:以前的方法利用重参数化功能来提高训练速度和鲁棒性(例如,用于prefix-tunning的 MLP 和用于 P-tuning的 LSTM)。在 P-tuning v2 中,作者发现重参数化的改进很小,尤其是对于较小的模型,同时还会影响模型的表现
-
-
-
缺乏模型参数规模小时不佳、深度提示优化:
-
缺乏规模通用性:当模型参数规模超过 100 亿时,Prompt Tuning 方法表明提示优化可以与全量微调方法相媲美。但对于较小的模型(100M到1B),提示优化和全量微调之间存在很大差异,限制了提示优化的适用性。
-
促进参数更新:传统的预训练模型中,只有最后一层或者少数几个层的参数会被更新,而其他层的参数保持不变。而在P-Tuning V2中,每一层都有可微调的参数,可以通过训练过程来更新,以适应特定任务的要求。
-
促进信息传递:在传统的预训练模型中,只有部分层参与微调和任务学习,这可能导致模型在不同层之间的信息传递受限。在 Prompt Tuning 中,连续提示仅插入到 Transformer 的第一层输入嵌入序列中,而在接下来的Transformer层中,连续提示位置的嵌入是由之前的 Transformer 层计算得到的。
改进方案:
- 在每一层都加入提示标记 作为输入,而不仅仅是在输入层加入。让模型能够在每一层都参与学习过程,更好地理解问题的提示并生成准确的回答。
-
P-Tuning v2 微调 ChatGLM2-6B
详情,请猛击:https://blog.csdn.net/qq_56591814/article/details/133049185
LoRA
论文地址:https://arxiv.org/abs/2106.09685
项目代码:https://github.com/microsoft/LoRA
Lora方法,插入少量参数,只在新插入的参数上进行微调,达到加速效果。
冻结预训练模型权重,将可训练的秩分解矩阵注入到 Transformer 层每个权重中。
相当于增加了一个分路。
- 线性层 A:将数据从 d 维降到 r 维
- 线性层 B:将数据从 r 维升到 d 维
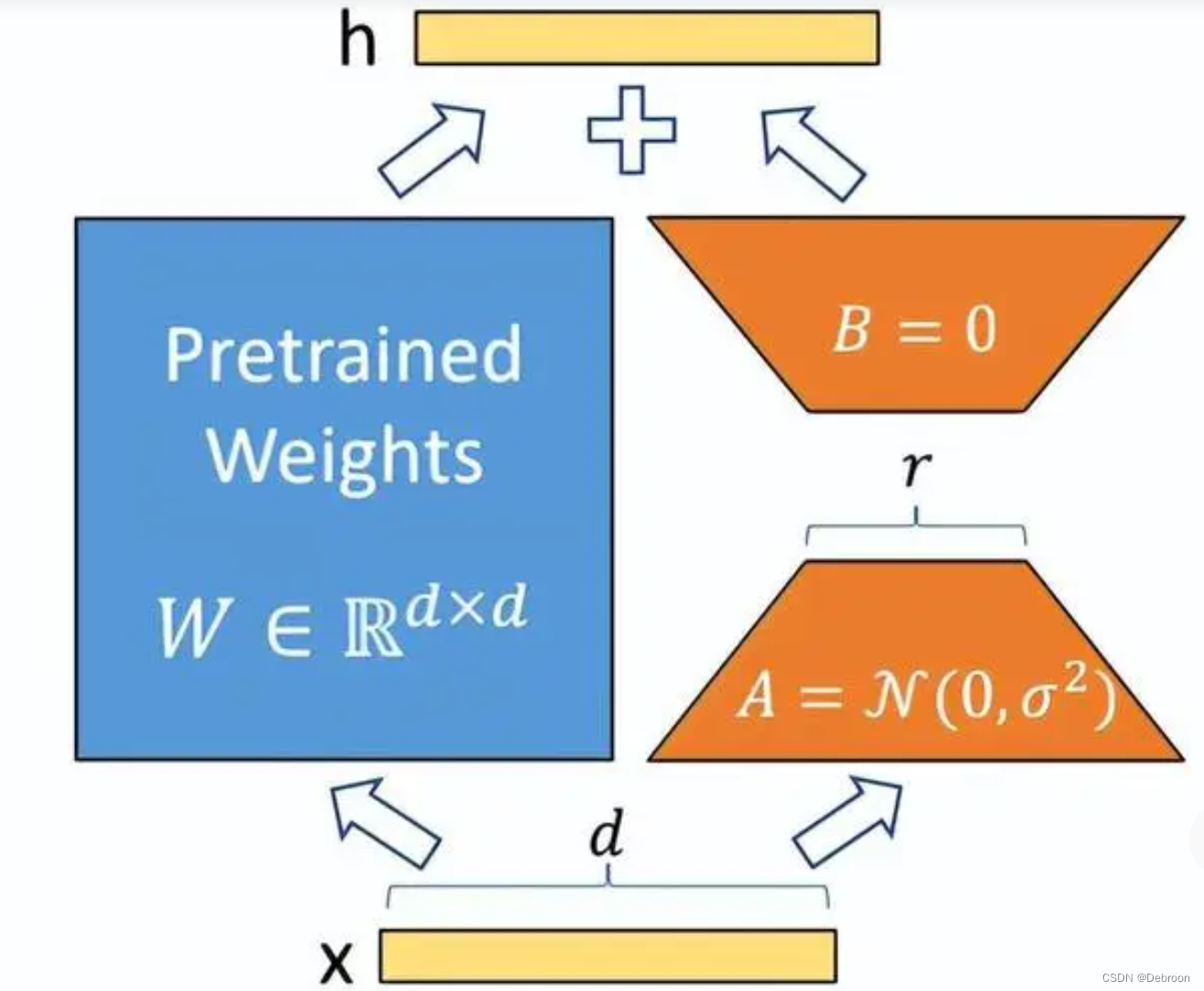
模型的输入输出维度不变,输出时将 B、预训练语言模型的参数叠加。
用随机高斯分布初始化A,用 0 矩阵初始化B,保证训练的开始此旁路矩阵依然是 0 矩阵。
Lora 类似于残差连接,同时使用这个旁路的更新来模拟 full finetuning 的过程。
LoRA 的最大优势是速度更快,使用的内存更少,可以在消费级(RTX 系列)硬件上运行。
在多卡训练时,Lora也是效率很高的,在多卡训练中,LoRA的速度优势主要体现在两个方面:
-
计算效率:由于LoRA只需要计算和优化注入的低秩矩阵,因此它的计算效率比完全微调更高。
在多卡训练中,LoRA可以将注入矩阵的计算和优化分配到多个GPU上,从而加速训练过程。
-
通信效率:在多卡训练中,通信效率通常是一个瓶颈。
由于 LoRA 只需要通信注入矩阵的参数,因此通信效率比完全微调更高。
在多卡训练中,LoRA可以将注入矩阵的参数分配到多个GPU上,从而减少通信量和通信时间。
因此,LoRA在多卡训练中通常比完全微调更快。
LoRA 也可以与其他方法相结合,例如 prefix-tuning。
QLoRA
论文地址:https://arxiv.org/abs/2305.14314
QLoRA 是 LoRA 改进版本。
可以在不降低任何性能的情况下,微调量化为 4 bit 模型的方法。
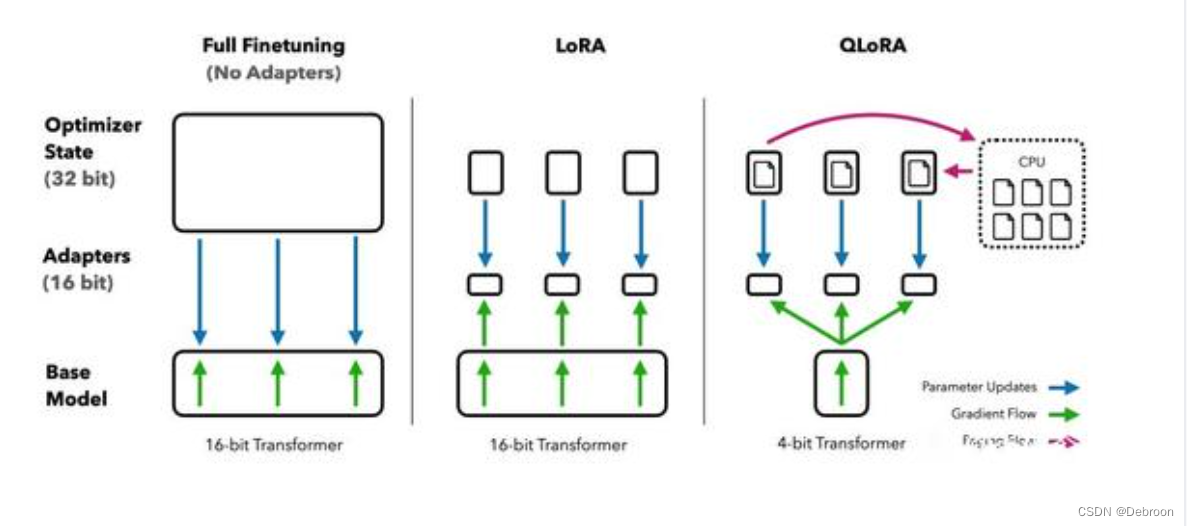
- 提出了一个数据类型:4bit NormalFloat,这是一个对于正态分布权重来说在信息理论上是最优的新数据类型。
- 提出双量化:对第一次量化后的那些常量再进行一次量化,减少存储空间。
- 提出 Paged Optimizers 分页优化器:降低显存压力,用的参数才加载 GPU,进行CPU和GPU之间自动分页到分页的传输,类似于 CPU 内存和磁盘之间的常规内存分页。
- 增加 Adapter:在注意力层的(query、value)全连接层插入适配器,增加训练参数,弥补损失精度。
尽管量化过程中会存在性能损失,但通过适配器微调,完全可以恢复这些性能。
- 一些任务,4bit 量化版本比完整版本更好。
- 之前用百川2-13B、百川2-13B 4bits 测试视神经问题(和颅脑相关,要去神经科),原版回答去看眼科,量化版本回答先去眼科排查,再去神经科检查,量化版本更有逻辑、全面。
- 然后我测了一下医学问题,百川2-13B 4bits 对比 ChatGLM、Chatgpt、星火晓医、商汤大医、医联Medgpt也不差啊。
QLoRA会增加运行时间成本(时间比LoRA长),但ta是一种很好的节省内存的方法。

