
热门标签
热门文章
- 1python+numpy实现DNN神经网络框架(底层原理)_python ndn
- 2Prometheus监控云上MySQL_mysql_global_status_questions
- 3centos7配置zookeeper本地模式与集群模式的详细教程_zookeeper standalone 启动
- 4prometheus 监控mysql数据库_prometheus监控mysql
- 5C语言实现二叉树_c语言2叉树数组实现
- 6xtrabackup全量备份与全量恢复_xtrabackup 全量恢复
- 7flask-17 flask-sqlalchemy查询
- 8RabbitMQ灵活运用,怎么理解五种消息模型_rabbitmq五种消息模型
- 9Softmax中温度(temperature)参数_softmax temperature
- 104000万蛋白结构训练,西湖大学开发基于结构词表的蛋白质通用大模型,已开源
当前位置: article > 正文
BERT和GPT模型简介_bert gpt
作者:Gausst松鼠会 | 2024-05-07 00:05:22
赞
踩
bert gpt
1. 引言
从现在的大趋势来看,使用某种模型预训练一个语言模型看起来是一种比较靠谱的方法。从之前 AI2 的 ELMo,到 OpenAI 的 fine-tune transformer,再到 Google 的 BERT、GPT,全都是对预训练的语言模型的应用。
本文将主要介绍 BERT 和 GPT 这两种常见语言模型及其应用场景,较少涉及具体原理的讲解(自身水平不足)。
2. BERT
2.1 简介
BERT 在2018年出现,被认为是 NLP 的 ImageNet 时刻,可以最好地表示单词和句子,增强对自然语言的理解,进而最好地捕捉基本语义和关系,有效增强了很多下游 NLP 任务的性能。BERT 可以理解为一个非常大的已经训练好的语言模型,涵盖了尽可能多的知识,能够作为很多任务的前置处理模块,类似预处理模块。
BERT 开发的两个步骤:第 1 步,你可以下载预训练好的模型(这个模型是在无标注的数据上训练的,可免费下载)。然后在第 2 步只需要关心模型微调即可。
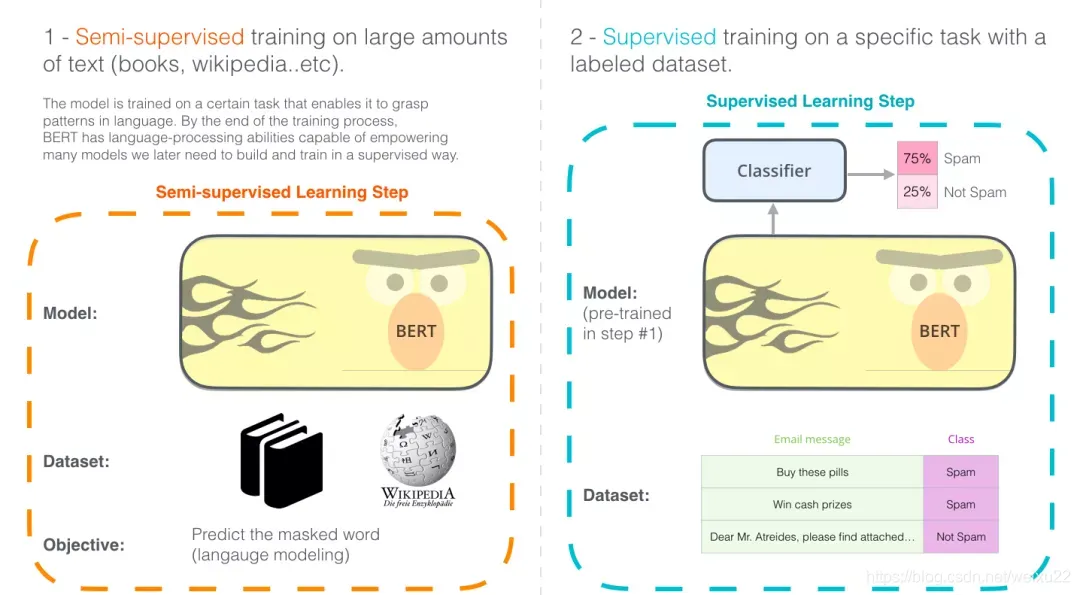
BERT 模型都有大量的 Encoder 层,BASE 版本由 12
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/Gausst松鼠会/article/detail/546493
推荐阅读
相关标签

