
- 1基于神经辐射场(Neural Radiance Fileds, NeRF)的三维重建- 简介_神经辐射场三维重建
- 2AI视频教程下载:用ChatGPT自动化各种工作任务
- 3违规停放智能监测摄像机
- 4使用 LLaMA Factory 微调 Llama-3 中文对话模型_llama-factory可视化 微调llama3
- 5在Rancher中修改K8S服务参数的万金油法则_rancher 修改nodeport
- 6C语言字符串拷贝函数详解及示例代码
- 7编程小白必看!Visual Studio 2022详细安装使用教程(C/C++编译器)
- 8第一章——Java基础(八)——数组进阶_package step4; import java.util.arrays; import jav
- 9【免费题库】华为OD机试 - 找数字(Java & JS & Python & C & C++)_小扇和小船今天又玩起来了数字游戏,小船给小扇一个正整数n <=n<=1e9),小扇需要找
- 10手机与windows大文件高速传输方法 自用_如何把手机windows里面的文件和成一个大文件
基于python旅游景点评论数据分析系统+可视化+LDA主题分析+NLP情感分析+Bayes评论分类 计算机毕业设计✅_python对游客评论分词
赞
踩
博主介绍:✌全网粉丝10W+,前互联网大厂软件研发、集结硕博英豪成立工作室。专注于计算机相关专业毕业设计项目实战6年之久,选择我们就是选择放心、选择安心毕业✌感兴趣的可以先收藏起来,点赞、关注不迷路✌
毕业设计:2023-2024年计算机毕业设计1000套(建议收藏)
毕业设计:2023-2024年最新最全计算机专业毕业设计选题汇总
1、项目介绍
项目技术说明:
python语言、Flask框架、MySQL数据库、Echarts可视化、
评论多维度分析、NLP情感分析、LDA主题分析、Bayes评论分类
2、项目界面
(1)评论年月时间分析
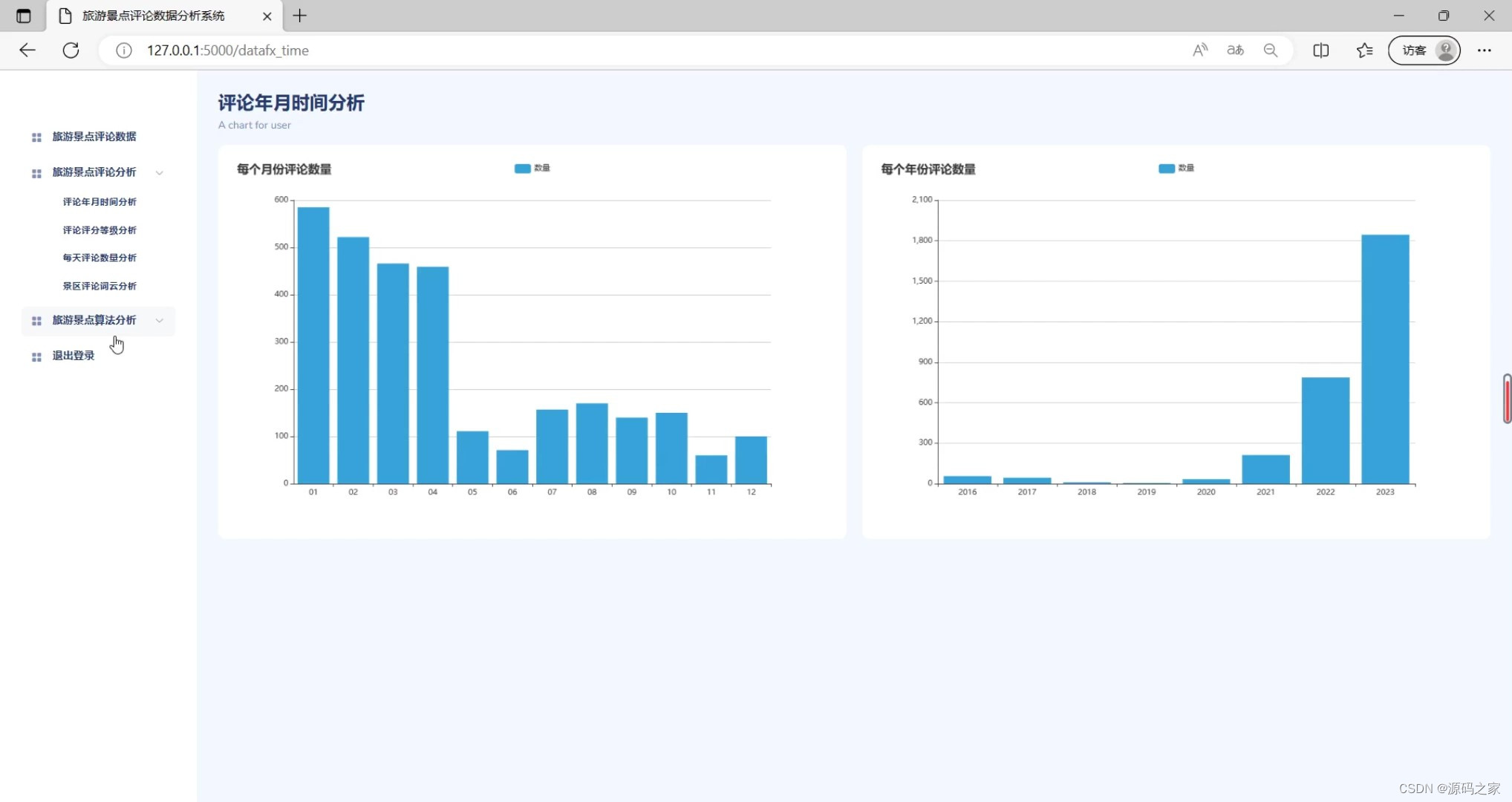
(2)评论评分等级分析
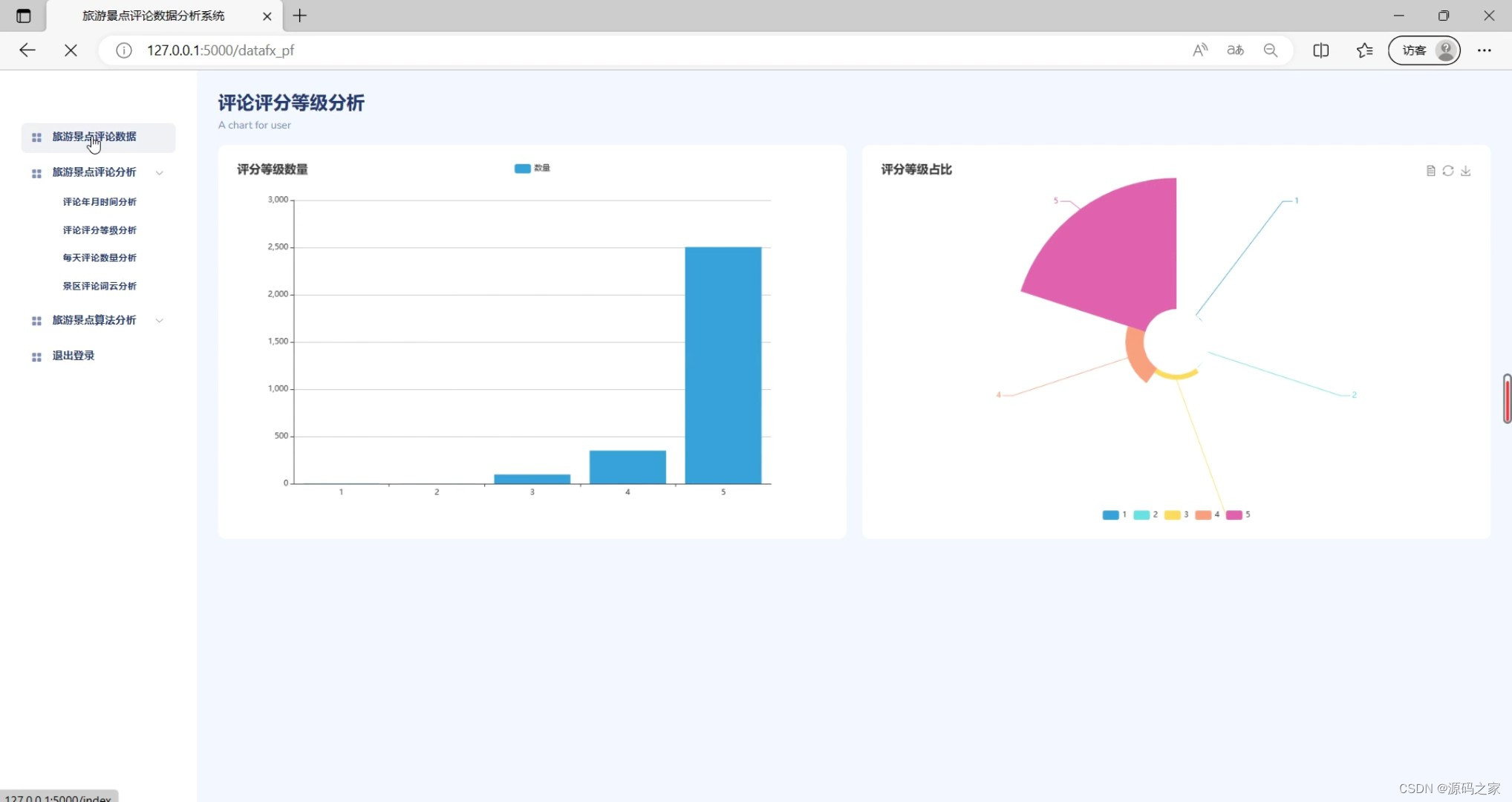
(3)旅游景点评论数据
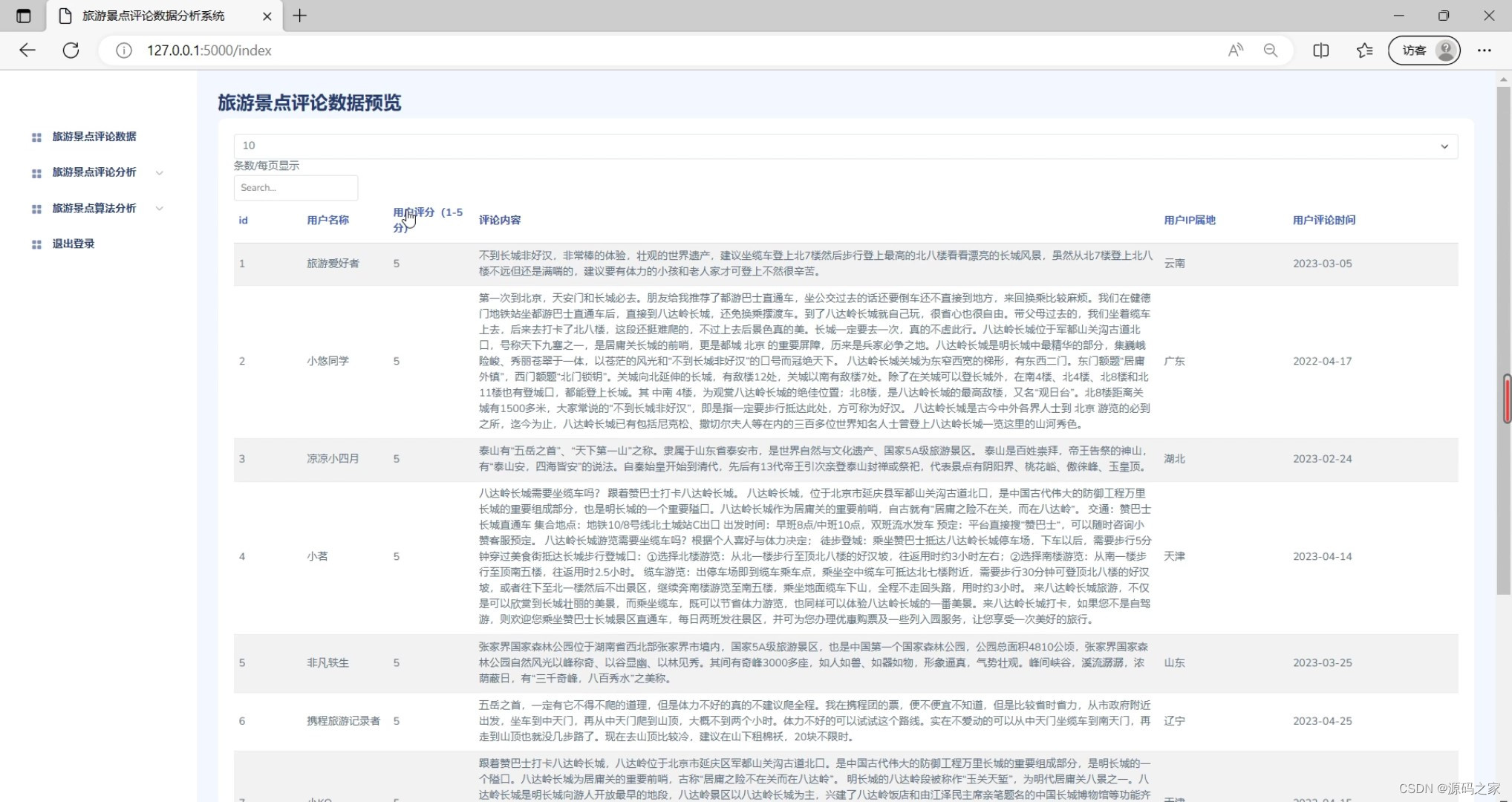
(4)评论数据分析
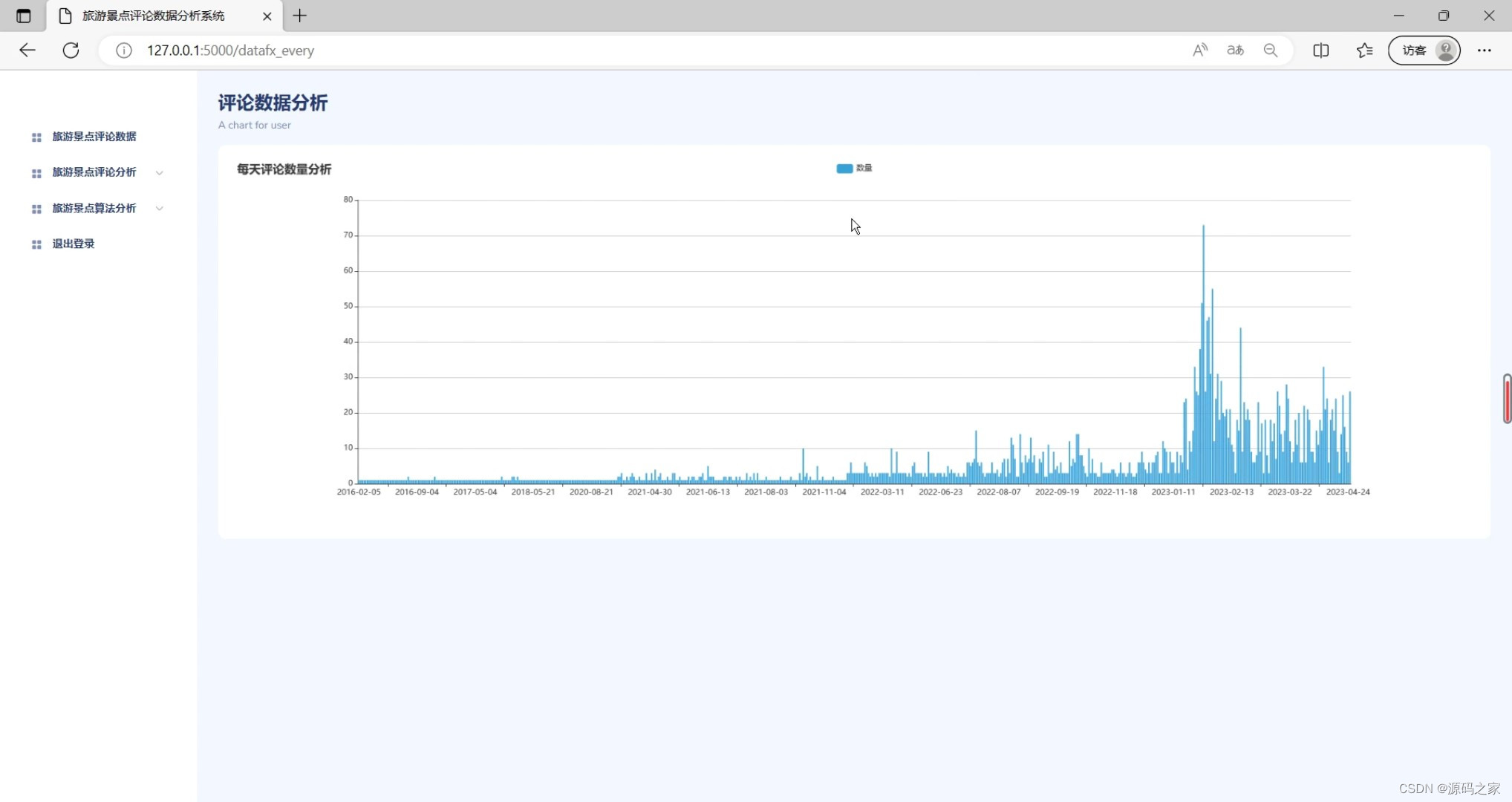
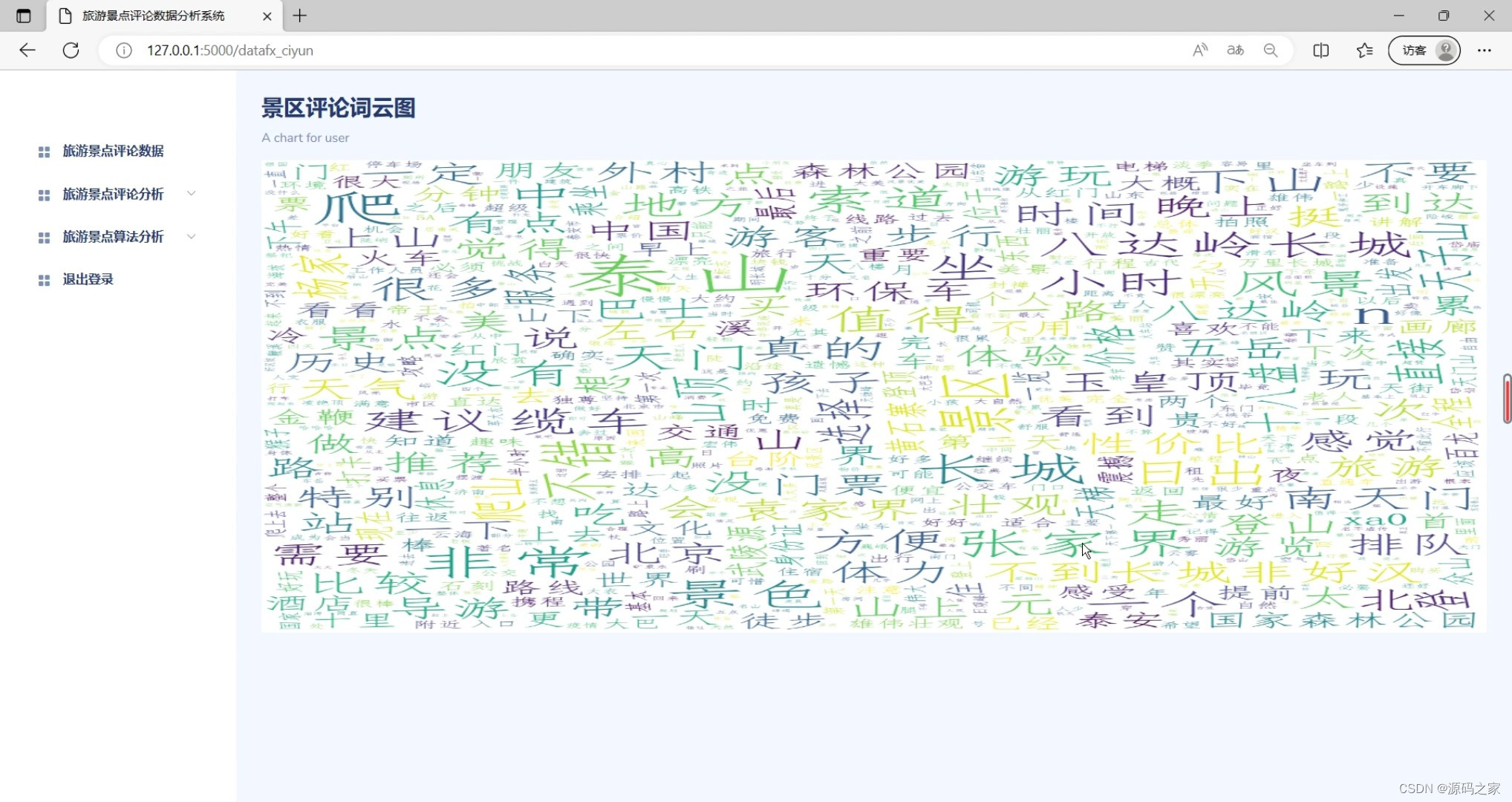
(5)景区评论词云图分析
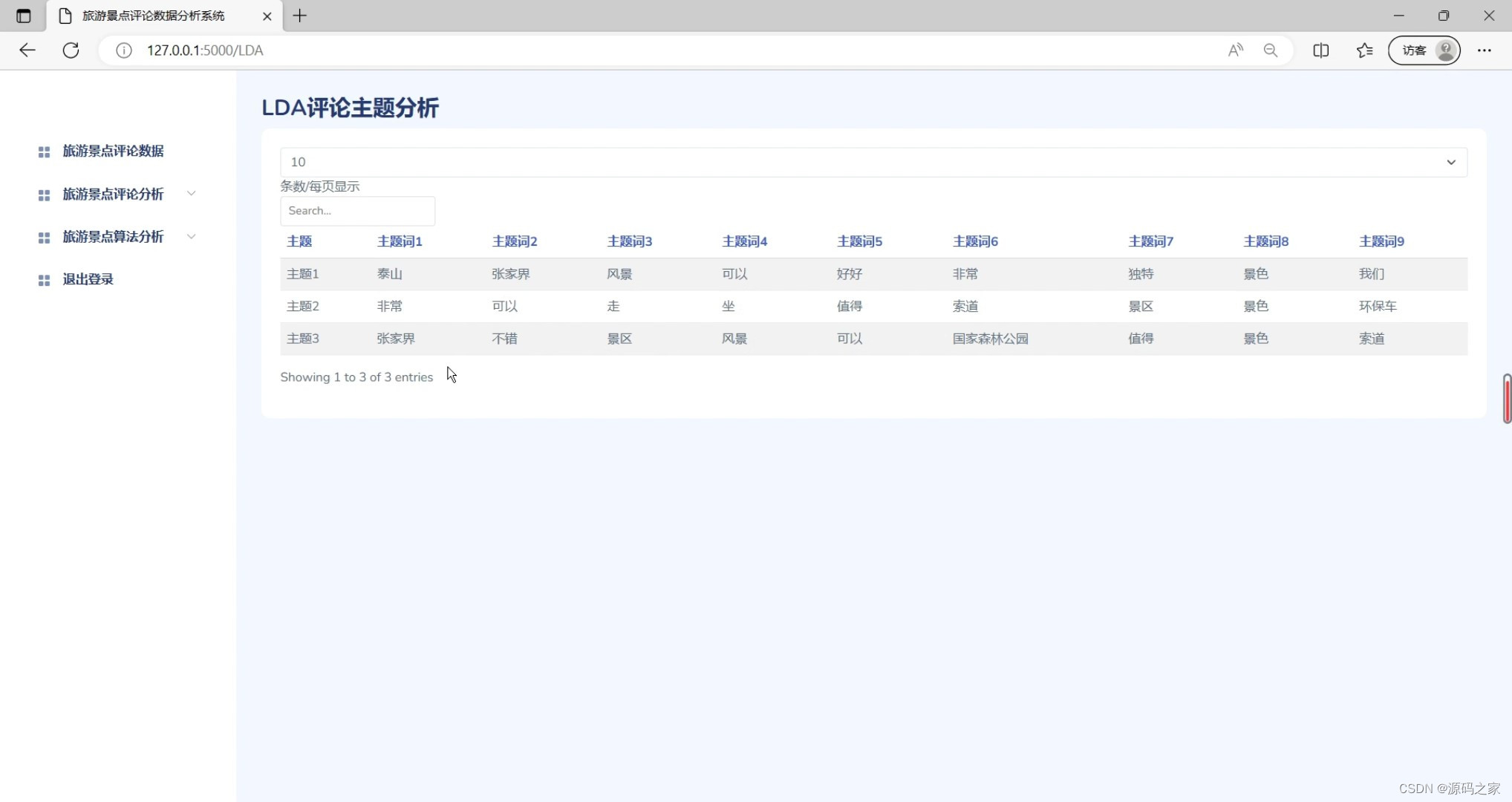
(6)LDA评论主题分析
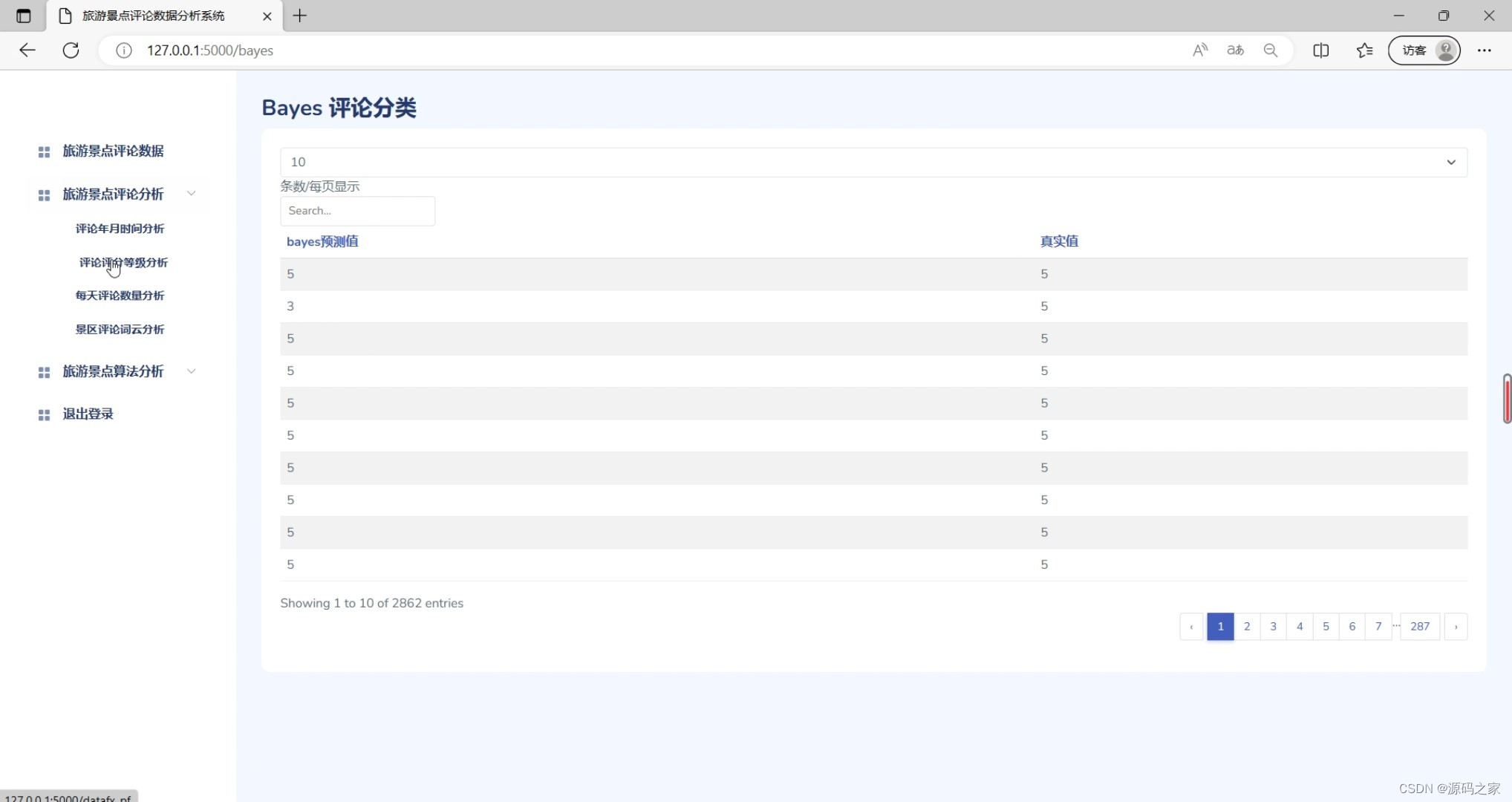
(7)Bayes评论分类
(8)注册登录界面
3、项目说明
1、情感分析
对人们对产品、服务、组织、个人、问题、事件、话题及其属性的观点、情 感、情绪、评价和态度的计算研究。文本情感分析(Sentiment Analysis)是自然语言处理(NLP)方法中常见的应用,也是一个有趣的基本任务,尤其是以提炼文本情绪内容为目的的分类。它是对带有情感色彩的主观性文本进行分析、处理、归纳和推理的过程。
本文将介绍情感分析中的情感极性(倾向)分析。所谓情感极性分析,指的是对文本进行褒义、贬义、中性的判断。在大多应用场景下,只分为两类。例如对于“喜爱”和“厌恶”这两个词,就属于不同的情感倾向。
1、情感分析
·最常用于微博、微信、用户论坛等语境下的短文本分析
·大量的文本预处理技术需求[ 网页解析,文本抽取,正则表达式等 ]
·情感分析的特殊性
·文本长度相对较短
·语境比较独特
·需要提取的信息量较为特别(·否定词,歧义词可能导致明显误判·新词出现速度很快·分词很难做到尽善尽美)
2、
1.基于词袋模型的分析
基于词典进行情感分析
·情感字典(sentiment dictionary)
·还行1 *不错2 ·不好-2太差了-3
·否定词的处理:前向搜索若干词条,以进行翻转
·情感得分的计算
·加载情感字典为Dict
·遍历句子中的词条,将对应的分值相加
·分值之和作为该句的情感得分
·所有句子的情感得分的平均值作为该文本的情感得分
基于词袋模型进行情感分析
·用金标准得到已准确分类的训练样本
·以词袋模型为基础,将情感分析完全看作是文本分类的一个简单实例来进行处理
·可按照分类进行预测,也可按照情感分值进行预测·需要对模型准确率和速度进行权衡
·效果较词典模型更好,但仍然忽略了上下文的关联信息
·可以考虑使用bigram或者trigram方式抽取词条,以同时考虑否定词和程度副词的影响
·可以考虑使用关键词进行模型拟合
4、核心代码
import pandas as pd import jieba import pymysql import re sql = 'select id,nickname, score, content, productColor, creationTime from data ' con = pymysql.connect(host='127.0.0.1', user='root', passwd='123456', port=3306, db='comment', charset='utf8') df = pd.read_sql(sql,con) postive = pd.read_sql(sql,con) postive = postive[postive['score'] == 5].drop_duplicates() print(postive) negtive = pd.read_sql(sql,con) negtive = negtive[negtive['score'] == 1].drop_duplicates() print(negtive) # 文本去重(文本去重主要是一些系统自动默认好评的那些评论 ) # 文本分词 mycut = lambda s: ' '.join(jieba.cut(s)) # 自定义分词函数 po = postive.content.apply(mycut) ne = negtive.content.apply(mycut) # 停用词过滤(停用词文本可以自己写,一行一个或者用别人整理好的,我这是用别人的) with open(r'stopwords.txt', encoding='utf-8') as f: #这里的文件路径最好改成自己的本地绝对路径 stop = f.read() stop = [' ', ''] + list(stop[0:]) # 因为读进来的数据缺少空格,我们自己添加进去 po['1'] = po[0:].apply(lambda s: s.split(' ')) # 将分词后的文本以空格切割 po['2'] = po['1'].apply(lambda x: [i for i in x if i not in stop]) # 过滤停用词 # 在这里我们也可以用到之前的词云图分析 # post = [] # for word in po: # if len(word)>1 and word not in stop: # post.append(word) # print(post) # wc = wordcloud.WordCloud(width=1000, font_path='simfang.ttf',height=800)#设定词云画的大小字体,一定要设定字体,否则中文显示不出来 # wc.generate(' '.join(post)) # wc.to_file(r'..\yun.png') ne['1'] = ne[0:].apply(lambda s: s.split(' ')) ne['2'] = ne['1'].apply(lambda x: [i for i in x if i not in stop]) from gensim import corpora, models # 负面主题分析 neg_dict = corpora.Dictionary(ne['2']) neg_corpus = [neg_dict.doc2bow(i) for i in ne['2']] neg_lda = models.LdaModel(neg_corpus, num_topics=3, id2word=neg_dict) # 正面主题分析 pos_dict = corpora.Dictionary(po['2']) pos_corpus = [pos_dict.doc2bow(i) for i in po['2']] pos_lda = models.LdaModel(pos_corpus, num_topics=3, id2word=pos_dict) pos_theme = pos_lda.show_topics() # 展示主题 pos_theme = pos_lda.show_topics() # 取出高频词 pattern = re.compile(r'[\u4e00-\u9fa5]+') pattern.findall(pos_theme[0][1]) pos_key_words = [] for i in range(3): pos_key_words.append(pattern.findall(pos_theme[i][1])) pos_key_words = pd.DataFrame(data=pos_key_words, index=['主题1', '主题2', '主题3']) pos_key_words.to_csv('lda.csv') from snownlp import SnowNLP import pandas as pd import pymysql def main(): sql = 'select id,nickname, score, content, productColor, creationTime from data order by creationTime' con = pymysql.connect(host='127.0.0.1', user='root', passwd='123456', port=3306, db='comment', charset='utf8') df = pd.read_sql(sql, con) df.drop_duplicates(keep='first', inplace=True) df = df.dropna() content = df['content'].tolist() contentlist = [] for x in content: contentlist.append(SnowNLP(x).sentiments) df['nlp'] = contentlist df = df[['nickname', 'score', 'content', 'nlp']] df.to_csv('nlp.csv') print(df) main()

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
Copyright © 2003-2013 www.wpsshop.cn 版权所有,并保留所有权利。

