
- 1SAP_MM_采购信息记录_PA认证总结_sap采购信息记录tcode
- 2HBase RowKey 的设计原则?_描述hbase的rowkey的设计原则
- 3HBase之Rowkey设计总结及易观方舟实战篇_h(key)=k%x,x的值
- 4利用RunnerGo数据大屏强化测试管理与决策_数据大屏测试数据
- 5mybaits-plus 相关yml配置详解
- 6UML模型图之类图——以图书馆管理系统为例_图书管理系统类图
- 7mysql左链表右链表区别_MySql链表语句--博客园老牛大讲堂
- 8[Qt的学习日常]--信号和槽
- 9mysql实战11 | 怎么给字符串字段加索引?
- 10【网络安全---漏洞复现】shiro550反序列化漏洞原理与漏洞复现和利用(基于vulhub,保姆级的详细教程)
点云分割论文阅读01--FusionVision
赞
踩
FusionVision: A Comprehensive Approach of 3D Object Reconstruction and Segmentation from RGB-D Cameras Using YOLO and Fast Segment Anything
FusionVision:使用 YOLO 和 Fast Segment Anything 从 RGB-D 相机重建和分割 3D 对象的综合方法
toread:Real-time 3D Object Detection from Point Clouds using an RGB-D Camera
Abstract
在计算机视觉领域,鉴于不同的环境条件和不同的物体外观所产生的固有复杂性,将先进技术集成到 RGB-D 相机输入的预处理中提出了重大挑战。因此,本文介绍了 FusionVision,这是一种适用于 RGB-D 图像中对象的鲁棒 3D 分割的详尽管道。传统的计算机视觉系统主要针对 RGB 相机,因此在同时捕获精确的物体边界和在深度图上实现高精度物体检测方面面临着局限性。为了应对这一挑战,FusionVision 采用了一种集成方法,将最先进的对象检测技术与先进的实例分割方法相结合。这些组件的集成可以对 RGB-D 数据进行整体(对从颜色 RGB 和深度 D 通道获得的信息进行统一分析)解释,有助于提取全面且准确的对象信息,以改进对象 6D 等后处理姿态估计、同步定位和建图 (SLAM) 操作、精确的 3D 数据集提取等。所提出的 FusionVision 管道采用 YOLO 来识别 RGB 图像域内的对象。随后,应用创新的语义分割模型 FastSAM 来描绘对象边界,从而产生精细的分割掩模。这些组件之间的协同作用及其与 3D 场景理解的集成确保了对象检测和分割的紧密融合,从而提高了 3D 对象分割的整体精度。
1. Introduction
点云处理的重要性已在各个领域激增,例如机器人[1,2]、医疗领域[3,4]、自动驾驶[5,6]、计量[7,8,9]等。在过去几年中,视觉传感器的进步带来了显着的改进,使这些传感器能够提供周围环境的实时 3D 测量,同时保持良好的精度 [10, 11]。因此,点云处理通过促进强大的对象检测、分割和分类操作,形成了众多应用的重要枢纽。
在计算机视觉领域,两个广泛研究的支柱很突出:对象检测和对象分割。这些子领域在过去几十年中吸引了研究界的关注,帮助计算机理解视觉数据并与之交互[12,13,14]。对象检测涉及识别和定位图像或视频流中的一个或多个对象,通常采用先进的深度学习技术,例如卷积神经网络(CNN)[15]和基于区域的CNN(R-CNN)[16]。对实时性能的追求导致了更高效模型的开发,例如 Single Shot MultiBox Detector (SSD) [17] 和 You Only Look Once (YOLO) [18],它们展示了准确性和速度之间的平衡性能。另一方面,对象分割超越了检测过程,允许描绘每个已识别对象的精确边界[19]。分割过程可以更好地理解视觉场景并在给定图像中精确定位对象。在文献中,两种分割类型是有区别的:语义分割为每个像素分配一个类标签[20],而实例分割则区分同一类的各个实例[21]。
最流行的目标检测模型之一是(YOLO)。 YOLO 的最新已知版本是 YOLOv8,它是一种实时目标检测系统,使用单个神经网络同时预测边界框和类概率 [22, 23]。它的设计速度快、准确,适合自动驾驶汽车和安全系统等应用。 YOLO 的工作原理是将输入图像划分为一个单元格网格,其中每个单元格预测固定数量的边界框,然后使用定义的置信度阈值对这些边界框进行过滤。然后调整剩余边界框的大小并重新定位以适合它们预测的对象。最后一步是对剩余的边界框执行非极大值抑制[24]以消除重叠的预测。 YOLO 使用的损失函数是两个术语的组合:定位损失和置信度损失。定位损失衡量预测的边界框坐标和地面实况坐标之间的差异,而置信度损失衡量预测的类概率和地面实况类别之间的差异。
另一方面,SAM [25]是最近流行的用于图像分割任务的深度学习模型。它基于医疗应用中常用的 U-Net 架构 [26,27,28]。 U-Net是专门为图像分割而设计的CNN,由编码器和解码器组成,编码器和解码器通过跳跃连接连接[29]。编码器负责从输入图像中提取特征,而解码器则处理分割掩模的生成。跳跃连接允许模型使用编码器在不同抽象级别学习到的特征,这有助于生成更准确的分割掩模。 SAM 之所以受欢迎,是因为它在各种图像分割基准和许多领域(例如医学领域 [30])以及其他已知数据集(例如 PASCAL VOC 2012 [31])上实现了最先进的性能。它在分割城市环境中常见的复杂对象(例如建筑物、道路和车辆)时特别有效。该模型跨不同数据集和任务的泛化能力极大地促进了其受欢迎程度。
科学界仍在广泛研究 YOLO 和 SAM 的使用并在 2D 计算机视觉任务中进行现场应用 [32,33,34]。然而,在本文中,我们重点研究两种最先进算法在 RGB-D 图像上的参与可能性。 RGB-D 相机是深度感应相机,可捕获场景的 RGB 通道(红、绿、蓝)和 D 映射(深度信息)(示例如图 1 所示)。这些相机使用红外 (IR) 投影仪和传感器来测量物体与相机的距离,从而以足够的精度为 RGB 图像提供额外的深度维度。例如,根据 F. Pan 等人的说法。 [35],在用于面部扫描的 RGB-D 相机上评估了 0.61 ± 0.42 mm 的估计精度。与传统 RGB 相机相比,RGB-D 相机具有多项优势,包括:
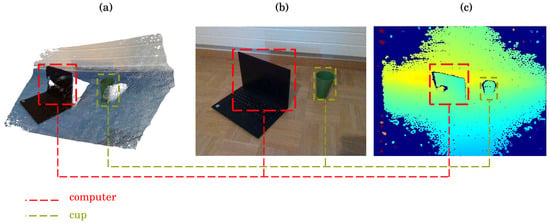
图 1. RGB-D 相机场景捕获和 3D 重建示例。 (a) 从 RGB-D 深度通道进行 3D 重建。 (b) 从 RGB 传感器捕获 RGB 流。 © 使用 ColorMap JET 进行深度视觉估计(较近的物体用绿色表示,较远的物体用深蓝色区域表示)。
(1)改进的对象检测和跟踪 [36]:RGB-D 相机提供的深度信息可以实现更准确的对象检测和跟踪,即使在具有遮挡和变化的照明条件的复杂环境中也是如此。
(2)3D 重建 [37, 38]:RGB-D 相机可用于创建对象和环境的 3D 模型,从而实现增强现实 (AR) 和虚拟现实 (VR) 等应用。
(3)人机交互[39, 40]:RGB-D相机提供的深度信息可用于检测和跟踪人体运动,从而实现更自然、直观的人机交互。
RGB-D 相机具有广泛的应用,包括机器人、计算机视觉、游戏和医疗保健。在机器人技术中,RGB-D 相机用于对象操纵 [41]、导航 [42] 和映射 [43]。在计算机视觉中,它们用于 3D 重建 [37]、对象识别和跟踪 [44, 45]。所有这些算法都利用深度信息来处理 3D 数据而不是图像。点云处理可以提高对象跟踪的准确性,从而提高有关其在 3D 空间中的位置、方向和尺寸的知识。与传统的基于图像的系统相比,这具有明显的优势。此外,由于使用了红外照明,RGB-D 技术还能够超越各种照明条件[46]。
本文介绍了 RGB-D 以及对象检测和分割领域的贡献。主要贡献在于 FusionVision 的开发和应用,这是一种将最初为 2D 图像提出的模型与 RGB-D 类型数据链接起来的方法。具体来说,已经实施、验证和调整了两个已知模型,以便通过使用英特尔实感摄像头的深度和 RGB 通道来处理 RGB-D 数据。这种组合增强了对场景的理解,从而实现了 3D 对象隔离和重建,而没有失真或噪音。此外,还集成了点云后处理技术,包括去噪和下采样,以消除由反射率或不准确的深度测量引起的异常和失真,从而提高FusionVision管道的实时性能。代码和预训练模型可在 https://github.com/safouaneelg/FusionVision/ 上公开获取(于 2024 年 2 月 28 日访问)。
本文的其余部分安排如下。尽管所提出的管道具有独特性,并且缺乏与本文提出的方法类似的方法,但第 2 节中讨论的相关工作很少。第 3 节给出了 FusionVision 管道的详细而全面的描述,其中讨论了这些过程一步步。接下来,第 4 节介绍和讨论了框架的实施和结果。最后,第 5 节总结了本文的研究结果。
2.Related Work
前面提到的YOLO和SAM模型主要是针对2D计算机视觉操作而提出的,缺乏对RGB-D图像的适应性。因此,物体的 3D 检测和分割超出了它们的能力,从而需要 3D 物体检测方法。在此背景下,针对 RGB-D 相机的 3D 对象检测和分割研究的方法很少。谭Z.等人。 [47]提出了一种用于 3D 对象定位的改进的 YOLO(版本 3)。该方法旨在使用单个 RGB-D 相机从点云实现实时高精度 3D 物体检测。作者提出了一种结合 2D 和 3D 物体检测算法的网络系统,以改善实时物体检测结果并提高速度。所使用的两种最先进的对象检测方法的组合是 [48] 从 RGB 传感器执行对象检测和 Frustum PointNet [49],这是一种使用视锥体约束来预测物体的 3D 边界框的实时方法。目的。方法框架可概括如下(图2):
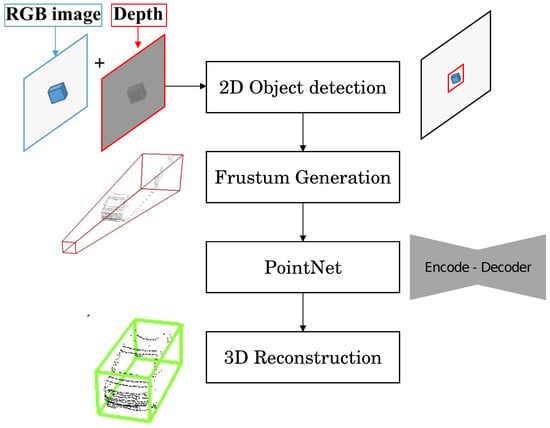
图 2. 用于 3D 对象重建和定位的复杂 YOLO 框架 [47]。
1.该系统首先从单个 RGB-D 相机获取 3D 点云以及 RGB 流。
2.2D 对象检测算法用于检测和定位 RGB 图像中的对象。这提供了有关对象的有用先验信息,包括它们的位置、宽度和高度。
3.来自 2D 对象检测的信息随后用于生成 3D 平截头体。平截头体是一个金字塔形状的体积,它基于 2D 边界框表示对象在 3D 空间中的可能位置。
4.生成的视锥体被输入到 PointNets 算法中,该算法执行实例分割并预测视锥体内每个对象的 3D 边界框。
通过结合 2D 和 3D 物体检测算法的结果,该系统实现了室内和室外的实时物体检测性能。对于方法评估,作者表示使用英特尔实感 D435i RGB-D 相机实现实时 3D 物体检测,算法在基于 NVIDIA GTX 1080 ti GPU 的系统上运行。然而,这种提出的方法有局限性,并且通常由于深度和物体反射率的估计不佳而受到噪声的影响。
3. FusionVision Pipeline
除了第一步数据采集之外,所实施的 FusionVision 流程可概括为六个步骤(图 3):

1.数据采集和注释:这个初始阶段涉及获取适合训练对象检测模型的图像。该图像集合可以包括单类或多类场景。作为准备所获取数据的一部分,需要分成指定用于训练和测试目的的单独子集。如果感兴趣的对象位于 Microsoft COCO(上下文中的通用对象)数据集 [50] 的 80 个类别内,则此步骤可能是可选的,从而允许利用现有的预训练模型。否则,如果要检测特殊物体,或者物体形状不常见或与数据集中的物体形状不同,则需要执行此步骤。
2.YOLO模型训练:数据采集后,YOLO模型接受训练以增强其检测特定物体的能力。此过程涉及根据获取的数据集优化模型的参数。
3.应用模型推理:训练成功后,YOLO 模型将部署在 RGB-D 相机的 RGB 传感器的实时流上,以实时检测物体。此步骤涉及应用经过训练的模型来识别相机视野内的物体。
4.FastSAM应用:如果在RGB流中检测到任何对象,则估计的边界框将作为FastSAM算法的输入,以便于提取对象掩模。此步骤利用 FastSAM 的功能完善对象分割过程。
5.RGB 和深度匹配:RGB 传感器生成的估计掩模与 RGB-D 相机的深度图对齐。这种对齐是通过利用已知的内在和外在矩阵来实现的,从而提高了后续 3D 对象定位的准确性。
6.深度图 3D 重建的应用:利用对齐的掩模和深度信息,生成 3D 点云,以便于在三个维度上实时定位和重建检测到的对象。最后一步会产生 3D 空间中对象的孤立表示。
3.1. Data Acquisition
对于需要检测特定物体的应用,数据采集包括使用特定物体的相机在不同角度、位置和变化的照明条件下收集大量图像。随后需要使用与图像中对象的位置相对应的边界框对图像进行注释。此步骤可以使用多个注释器,例如 Roboflow [51]、LabelImg [52] 或 VGG Image Annotator [53]。
3.2. YOLO Training
训练 YOLO 模型进行稳健的目标检测构成了 FusionVision 管道的强大支柱。获取的数据分为 80% 用于训练,20% 用于验证。为了进一步增强模型的泛化能力,通过水平和垂直翻转图像以及应用轻微的角度倾斜来采用数据增强技术[54]。


在整个训练过程中,图像及其相应的注释被输入 YOLO 网络 [22]。网络依次生成边界框、类概率和置信度分数的预测。然后使用上述损失函数将这些预测与真实数据进行比较。这个迭代过程逐渐提高模型的目标检测精度,直到达到总损失的最小值。
3.3. FastSAM Deployment
训练 YOLO 模型后,其边界框将作为涉及 FastSAM 模型的后续步骤的输入。处理完整图像时,FastSAM 会估计所有查看对象的实例分割掩码。因此,不需要处理整个图像,而是使用 YOLO 估计的边界框作为输入信息,将注意力集中在对象所在的相关区域,从而显着减少计算开销。然后,其基于 Transformer 的架构深入研究这个裁剪后的图像补丁,以生成像素级掩模。训练 YOLO 模型后,其边界框将作为涉及 FastSAM 模型的后续步骤的输入。处理完整图像时,FastSAM 会估计所有查看对象的实例分割掩码。因此,不需要处理整个图像,而是使用 YOLO 估计的边界框作为输入信息,将注意力集中在对象所在的相关区域,从而显着减少计算开销。然后,其基于 Transformer 的架构深入研究这个裁剪后的图像补丁,以生成像素级掩模。
3.4. RGB and Depth Matching
RGB-D 成像设备通常包含一个负责捕获传统 2D 彩色图像的 RGB 传感器,以及一个集成左右摄像头以及位于中间的红外 (IR) 投影仪的深度传感器。投射到物理对象上的红外图案会因其形状而扭曲,然后被左右摄像机捕获。然后,利用两幅图像中对应点之间的视差信息来估计场景中每个像素的深度。作为 FastSAM 输出的提取片段通过相机 RGB 通道中的二进制掩码表示。 DS 中物理对象的识别是通过对齐二进制掩模和深度帧来实现的(图 4)。
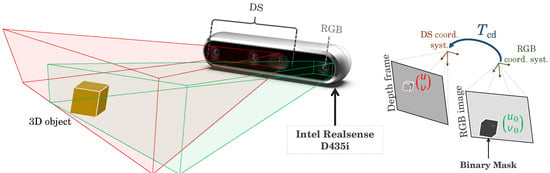
在此对准过程中,需要使用校准过程或基于默认工厂值来估计 RGB 相机和深度传感器的坐标系之间的转换。很少有校准技术可以用于改进矩阵估计,例如[55, 56]。该变换在数学上用等式(5)表示:


3.5. 3D Reconstruction of the Physical Object
一旦 FastSAM 掩模与深度图对齐,识别出的物理对象就可以在 3D 坐标中重建,仅考虑感兴趣区域 (ROI)。该过程涉及几个关键步骤,包括:(1) 下采样,(2) 去噪,以及 (3) 为点云中每个识别的对象生成 3D 边界框。
下采样过程应用于原始点云数据,可以降低计算复杂性,同时保留基本的对象信息。所选择的下采样技术涉及体素化,其中点云被分为规则的体素网格,并且每个体素仅保留一个点[57]。下采样之后,实施基于统计异常值去除的去噪程序[58]以提高生成的点云的质量。识别可能由传感器噪声引起的异常值并将其从点云中删除。最后,对于在对齐的 FastSAM 掩模中检测到的每个物理对象,在去噪点云内生成一个 3D 边界框。边界框生成涉及创建一组沿每个轴连接最小和最大坐标的线。这组线与去噪点云中对象的位置对齐。生成的边界框提供了检测到的对象的 3D 空间表示。
4. Results and Discussion
4.1. Setup Configuration
在实验研究中,所提出的框架在三种常用物理对象的检测上进行了测试:杯子、计算机和瓶子。表 1 总结了已使用的设置配置。
表 1. 实时 FusionVision 管道的设置配置。

4.2. Data Acquisition and Annotation
在数据采集步骤中,使用 RealSense 相机的 RGB 流捕获了总共 100 张具有常见物体(即杯子、电脑和瓶子)的图像。记录的图像包括所选 3D 物理对象的多个姿势和照明条件,以确保模型训练的稳健和全面的数据集。使用 YOLO 对象检测模型的 Roboflow 注释器对图像进行注释。此外,还应用数据增强技术来丰富数据集,包括水平和垂直翻转以及角度倾斜(图 5)。

图 5. YOLO 训练获取的图像示例:顶部两张图像是原始图像,底部两张图像是增强图像。
4.3. YOLO Training and FastSAM Deployment
4.3.1. Model Training and Deployment
对象检测的训练是在获取的图像和增强的图像的情况下进行的。图 6 总结了训练结果和验证曲线,包括损失函数
Copyright © 2003-2013 www.wpsshop.cn 版权所有,并保留所有权利。

