
- 1YOLOv7改进之二十四:引入量子启发的新型视觉主干模型WaveMLP(可尝试发SCI)_yolosci
- 2ChatGPT的诞生和发展_chatgpt的产生与发展
- 3Hive使用beeline(KERBEROS)_beeline kerberos
- 4Spring框架中访问MongoDB的深入解析*
- 5RocketMQ与Kafka深度对比:特性与适用场景解析_kafka和rocketmq对比
- 6全新桥隧坡安全监测解决方案,24h监测效率提升30%
- 7SercureCRT软件通过SSH连接ubuntb报错:password authentication failed解决方案_passwd authentication failed
- 8基于FPGA的四则运算_fpga除法的小数
- 9高效办公,从几行批处理命令开始,你知道吗?_几个非常高效的办公室批处理命令
- 10TortoiseGit不安全目录解决办法_to add an exception for this directory, call: git
Spark编程实验二:RDD编程初级实践_(a) 该系共开设了多少门课程? (b) tom同学的总成绩平均分是多少? (c) 求每名同学
赞
踩
目录
一、目的与要求
1、熟悉Spark的RDD基本操作及键值对操作;
2、熟悉使用RDD编程解决实际具体问题的方法。
二、实验内容
1、pyspark交互式编程
给定数据集 data1.txt,包含了某大学计算机系的成绩,数据格式如下所示:
Tom,DataBase,80
Tom,Algorithm,50
Tom,DataStructure,60
Jim,DataBase,90
Jim,Algorithm,60
Jim,DataStructure,80
……
数据集data1.txt下载地址:https://pan.quark.cn/s/c20aee60e9c0 (提取码:fhcM)
请根据给定的实验数据,在pyspark中通过编程来计算以下内容:
(1)该系总共有多少学生;
(2)该系共开设了多少门课程;
(3)Tom同学的总成绩平均分是多少;
(4)求每名同学的选修的课程门数;
(5)该系DataBase课程共有多少人选修;
(6)各门课程的平均分是多少;
(7)使用累加器计算共有多少人选了DataBase这门课。
2、编写独立应用程序实现数据去重
对于两个输入文件A和B,编写Spark独立应用程序,对两个文件进行合并,并剔除其中重复的内容,得到一个新文件C。下面是输入文件和输出文件的一个样例,供参考。
输入文件A的样例如下:
20170101 x
20170102 y
20170103 x
20170104 y
20170105 z
20170106 z
输入文件B的样例如下:
20170101 y
20170102 y
20170103 x
20170104 z
20170105 y
根据输入的文件A和B合并得到的输出文件C的样例如下:
20170101 x
20170101 y
20170102 y
20170103 x
20170104 y
20170104 z
20170105 y
20170105 z
20170106 z
3、编写独立应用程序实现求平均值问题
每个输入文件表示班级学生某个学科的成绩,每行内容由两个字段组成,第一个是学生名字,第二个是学生的成绩;编写Spark独立应用程序求出所有学生的平均成绩,并输出到一个新文件中。下面是输入文件和输出文件的一个样例,供参考。
Algorithm成绩:
小明 92
小红 87
小新 82
小丽 90
Database成绩:
小明 95
小红 81
小新 89
小丽 85
Python成绩:
小明 82
小红 83
小新 94
小丽 91
平均成绩如下:
(小红,83.67)
(小新,88.33)
(小明,89.67)
(小丽,88.67)
4、三个综合实例
题目详情可查看实验步骤。
三、实验步骤
1、pyspark交互式编程
先在终端启动pyspark:
[root@bigdata zhc]# pyspark(1)该系总共有多少学生;
- >>> lines = sc.textFile("file:///home/zhc/datasets/data1.txt")
- >>> res = lines.map(lambda x:x.split(",")).map(lambda x: x[0]) # 获取每行数据的第1列
- >>> distinct_res = res.distinct() # 去重操作
- >>> distinct_res.count() # 取元素总个数
执行结果:

(2)该系共开设了多少门课程;
- >>> lines = sc.textFile("file:///home/zhc/datasets/data1.txt")
- >>> res = lines.map(lambda x:x.split(",")).map(lambda x:x[1]) # 获取每行数据的第2列
- >>> distinct_res = res.distinct() # 去重操作
- >>> distinct_res.count() # 取元素总个数
执行结果:

(3)Tom同学的总成绩平均分是多少;
- >>> lines = sc.textFile("file:///home/zhc/datasets/data1.txt")
- >>> res = lines.map(lambda x:x.split(",")).filter(lambda x:x[0]=="Tom") # 筛选Tom同学的成绩信息
- >>> res.foreach(print)
- >>> score = res.map(lambda x:int(x[2])) # 提取Tom同学的每门成绩,并转换为int类型
- >>> num = res.count() # Tom同学选课门数
- >>> sum_score = score.reduce(lambda x,y:x+y) # Tom同学的总成绩
- >>> avg = sum_score/num # 总成绩/门数=平均分
- >>> print(avg)
执行结果:

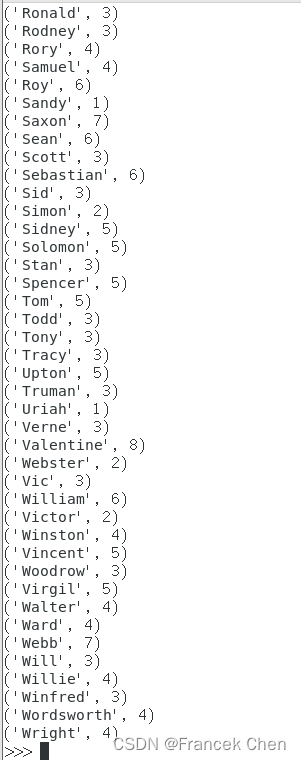
(4)求每名同学的选修的课程门数;
- >>> lines = sc.textFile("file:///home/zhc/datasets/data1.txt")
- >>> res = lines.map(lambda x:x.split(",")).map(lambda x:(x[0],1)) # 学生每门课程都对应(学生姓名,1),学生有n门课程则有n个(学生姓名,1)
- >>> each_res = res.reduceByKey(lambda x,y: x+y) # 按学生姓名获取每个学生的选课总数
- >>> each_res.foreach(print)
执行结果:
 ......
......
(5)该系DataBase课程共有多少人选修;
- >>> lines = sc.textFile("file:///home/zhc/datasets/data1.txt")
- >>> res = lines.map(lambda x:x.split(",")).filter(lambda x:x[1]=="DataBase")
- >>> res.count()
执行结果:

(6)各门课程的平均分是多少;
- >>> lines = sc.textFile("file:///home/zhc/datasets/data1.txt")
- >>> res = lines.map(lambda x:x.split(",")).map(lambda x:(x[1],(int(x[2]),1))) # 为每门课程的分数后面新增一列1,表示1个学生选择了该课程。格式如('ComputerNetwork', (44, 1))
- >>> temp = res.reduceByKey(lambda x,y:(x[0]+y[0],x[1]+y[1])) # 按课程名聚合课程总分和选课人数。格式如('ComputerNetwork', (7370, 142))
- >>> avg = temp.map(lambda x:(x[0], round(x[1][0]/x[1][1],2))) # 课程总分/选课人数 = 平均分,并利用round(x,2)保留两位小数
- >>> avg.foreach(print)
执行结果:

(7)使用累加器计算共有多少人选了DataBase这门课。
- >>> lines = sc.textFile("file:///home/zhc/datasets/data1.txt")
- >>> res = lines.map(lambda x:x.split(",")).filter(lambda x:x[1]=="DataBase") # 筛选出选了DataBase课程的数据
- >>> accum = sc.accumulator(0) # 定义一个从0开始的累加器accum
- >>> res.foreach(lambda x:accum.add(1)) # 遍历res,每扫描一条数据,累加器加1
- >>> accum.value # 输出累加器的最终值
执行结果:

2、编写独立应用程序实现数据去重
对于两个输入文件A和B,编写Spark独立应用程序,对两个文件进行合并,并剔除其中重复的内容,得到一个新文件C。下面是输入文件和输出文件的一个样例,供参考。
输入文件A的样例如下:
20170101 x
20170102 y
20170103 x
20170104 y
20170105 z
20170106 z
输入文件B的样例如下:
20170101 y
20170102 y
20170103 x
20170104 z
20170105 y
根据输入的文件A和B合并得到的输出文件C的样例如下:
20170101 x
20170101 y
20170102 y
20170103 x
20170104 y
20170104 z
20170105 y
20170105 z
20170106 z
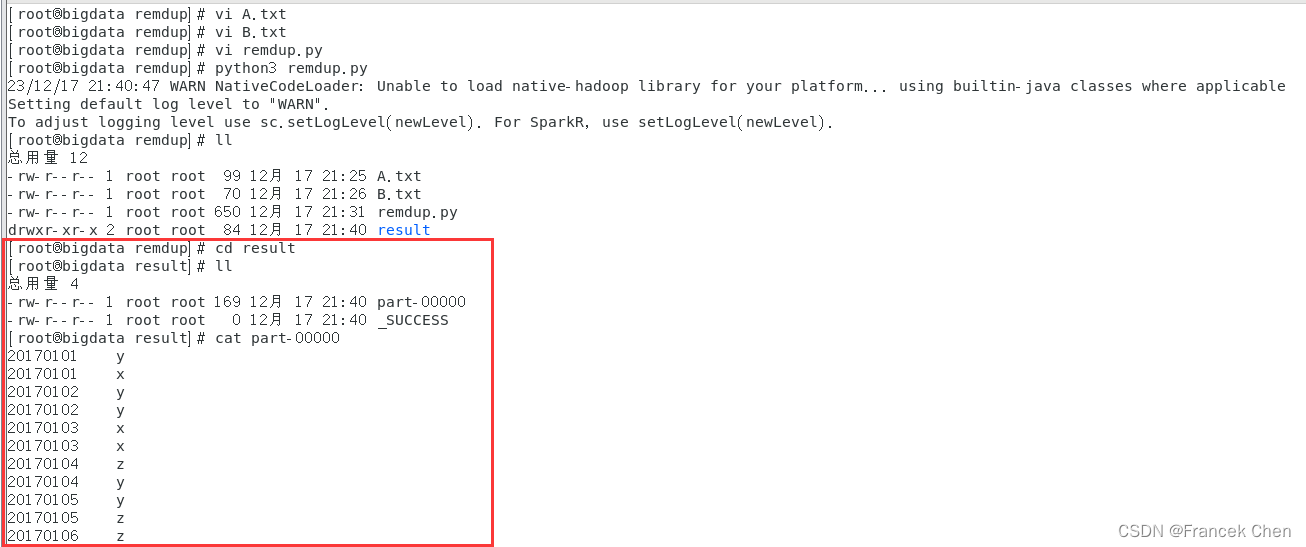
在“/home/zhc/mycode/remdup”目录下新建代码文件remdup.py:
- # /home/zhc/mycode/remdup/remdup.py
- from pyspark import SparkContext
- #初始化SparkContext
- sc = SparkContext('local','remdup')
- #加载两个文件A和B
- lines1 = sc.textFile("file:///home/zhc/mycode/remdup/A.txt")
- lines2 = sc.textFile("file:///home/zhc/mycode/remdup/B.txt")
- #合并两个文件的内容
- lines = lines1.union(lines2)
- #去重操作
- distinct_lines = lines.distinct()
- #排序操作
- res = distinct_lines.sortBy(lambda x:x)
- #将结果写入result文件中,repartition(1)的作用是让结果合并到一个文件中,不加的话会结果写入到两个文件
- res.repartition(1).saveAsTextFile("file:///home/zhc/mycode/remdup/result")
在目录“/home/zhc/mycode/remdup”下执行下面命令执行程序(注意执行程序时请先退出pyspark shell,否则会出现“地址已在使用”的警告)。
[root@bigdata remdup]# python3 remdup.py在目录“/home/zhc/mycode/remdup/result”下即可得到结果文件part-00000。
- [root@bigdata remdup]# cd result
- [root@bigdata result]# cat part-00000
3、编写独立应用程序实现求平均值问题
每个输入文件表示班级学生某个学科的成绩,每行内容由两个字段组成,第一个是学生名字,第二个是学生的成绩;编写Spark独立应用程序求出所有学生的平均成绩,并输出到一个新文件中。下面是输入文件和输出文件的一个样例,供参考。
Algorithm成绩:
小明 92
小红 87
小新 82
小丽 90
Database成绩:
小明 95
小红 81
小新 89
小丽 85
Python成绩:
小明 82
小红 83
小新 94
小丽 91
平均成绩如下:
(小红,83.67)
(小新,88.33)
(小明,89.67)
(小丽,88.67)
在“/home/zhc/mycode/avgscore”目录下新建代码文件avgscore.txt:
- # /home/zhc/mycode/avgscore/avgscore.txt
- from pyspark import SparkContext
- #初始化SparkContext
- sc = SparkContext('local',' avgscore')
- #加载三个文件Algorithm.txt、Database.txt和Python.txt
- lines1 = sc.textFile("file:///home/zhc/mycode/avgscore/Algorithm.txt")
- lines2 = sc.textFile("file:///home/zhc/mycode/avgscore/Database.txt")
- lines3 = sc.textFile("file:///home/zhc/mycode/avgscore/Python.txt")
- #合并三个文件的内容
- lines = lines1.union(lines2).union(lines3)
- #为每行数据新增一列1,方便后续统计每个学生选修的课程数目。data的数据格式为('小明', (92, 1))
- data = lines.map(lambda x:x.split(" ")).map(lambda x:(x[0],(int(x[1]),1)))
- #根据key也就是学生姓名合计每门课程的成绩,以及选修的课程数目。res的数据格式为('小明', (269, 3))
- res = data.reduceByKey(lambda x,y:(x[0]+y[0],x[1]+y[1]))
- #利用总成绩除以选修的课程数来计算每个学生的每门课程的平均分,并利用round(x,2)保留两位小数
- result = res.map(lambda x:(x[0],round(x[1][0]/x[1][1],2)))
- #将结果写入result文件中,repartition(1)的作用是让结果合并到一个文件中,不加的话会结果写入到三个文件
- result.repartition(1).saveAsTextFile("file:///home/zhc/mycode/avgscore/result")

在目录“/home/zhc/mycode/avgscore”下执行下面命令执行程序(注意执行程序时请先退出pyspark shell,否则会出现“地址已在使用”的警告)。
[root@bigdata avgscore]# python3 avgscore.py 在目录“/home/zhc/mycode/avgscore/result”下即可得到结果文件part-00000。
- [root@bigdata avgscore]# cd result
- [root@bigdata result]# cat part-00000

4、三个综合实例
案例一:求Top值
任务描述:某个目录下有若干个文本文件,每个文件里包含了很多数据,每行数据由4个字段的值构成,不同字段之间用逗号隔开,4个字段分别为orderid,userid,payment和productid,要求求出Top N个payment值。
file01.txt:
1,1768,50,155
2,1218, 600,211
3,2239,788,242
4,3101,28,599
5,4899,290,129
6,3110,54,1201
7,4436,259,877
8,2369,7890,27
file02.txt:
100,4287,226,233
101,6562,489,124
102,1124,33,17
103,3267,159,179
104,4569,57,125
105,1438,37,116
- [root@bigdata zhc]# cd /mycode/RDD
- [root@bigdata RDD]# vi file0.txt
- [root@bigdata RDD]# vi TopN.py
- [root@bigdata RDD]# vi file0.txt
- [root@bigdata RDD]# spark-submit TopN.py
使用vim编辑器编辑“/home/zhc/mycode/RDD/file0.txt”文件:
我这里将file01.txt和file02.txt合并为一个文件了——>file0.txt
1,1768,50,155
2,1218,600,211
3,2239,788,242
4,3101,28,599
5,4899,290,129
6,3110,54,1201
7,4436,259,877
8,2369,7890,27
100,4287,226,233
101,6562,489,124
102,1124,33,17
103,3267,159,179
104,4569,57,125
105,1438,37,116
使用vim编辑器编辑“/home/zhc/mycode/RDD/TopN.py”代码文件:
- #/home/zhc/mycode/RDD/TopN.py
- from pyspark import SparkConf, SparkContext
- # 创建SparkConf对象,设置应用程序名称和部署模式
- conf = SparkConf().setMaster("local").setAppName("ReadHBase")
- # 创建SparkContext对象
- sc = SparkContext(conf = conf)
- # 从本地文件系统读取数据
- lines= sc.textFile("file:///home/zhc/mycode/RDD/file0.txt")
- # 过滤出长度不为0且包含4个逗号的行
- result1 = lines.filter(lambda line:(len(line.strip()) > 0) and (len(line.split(","))== 4))
- # 提取第三列数据
- result2=result1.map(lambda x:x.split(",")[2])
- # 将第三列数据转换成键值对(key为数字,value为空串)
- result3=result2.map(lambda x:(int(x),""))
- # 对数据进行重新分区,分区数为1
- result4=result3.repartition(1)
- # 按照键降序排序
- result5=result4.sortByKey(False)
- # 取出前5个键
- result6=result5.map(lambda x:x[0])
- result7=result6.take(5)
- # 打印前5个键
- for a in result7:
- print(a)
使用spark-submit提交TopN.py文件,得到结果如下。

案例二:文件排序
任务描述:有多个输入文件,每个文件中的每一行内容均为一个整数。要求读取所有文件中的整数,进行排序后,输出到一个新的文件中,输出的内容个数为每行两个整数,第一个整数为第二个整数的排序位次,第二个整数为原待排序的整数。
输入文件:
file1.txt:
33
37
12
40
file2.txt:
4
16
39
5
file3.txt:
1
45
25
- [root@bigdata RDD]# mkdir filesort
- [root@bigdata RDD]# cd filesort
- [root@bigdata filesort]# vi file1.txt
- [root@bigdata filesort]# vi file2.txt
- [root@bigdata filesort]# vi file3.txt
- [root@bigdata filesort]# cd ..
- [root@bigdata RDD]# vi FileSort.py
- [root@bigdata RDD]# spark-submit FileSort.py
在“/home/zhc/mycode/RDD/filesort”路径下,使用vim编辑器将上面三个文件内容输入。
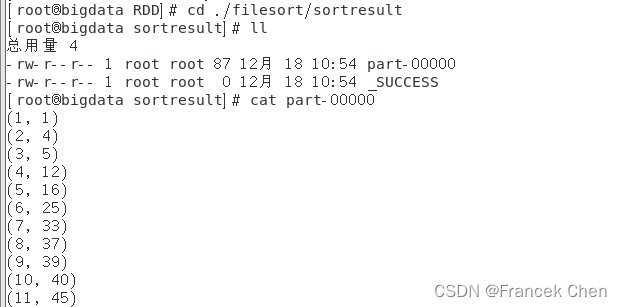
使用vim编辑器编辑“/home/zhc/mycode/RDD/FileSort.py”文件:
- #/home/zhc/mycode/RDD/FileSort.py
- from pyspark import SparkConf, SparkContext
- # 定义一个全局变量index,用于记录索引值
- index=0
- # 自定义函数getindex,每调用一次将index加1,并返回新的index值
- def getindex():
- global index
- index+=1
- return index
- def main():
- # 创建SparkConf对象,设置应用程序名称和部署模式(本地1核运行)
- conf = SparkConf().setMaster("local[1]").setAppName("FileSort")
- sc = SparkContext(conf = conf)
- lines= sc.textFile("file:///home/zhc/mycode/RDD/filesort/file*.txt")
- index = 0
- # 过滤出长度不为0的行
- result1 = lines.filter(lambda line:(len(line.strip()) > 0))
- # 将每行数据转换成整型键值对
- result2=result1.map(lambda x:(int(x.strip()),""))
- # 对数据进行重新分区,分区数为1
- result3=result2.repartition(1)
- # 按照键升序排序
- result4=result3.sortByKey(True)
- # 只保留键
- result5=result4.map(lambda x:x[0])
- # 将数据映射为(index, value)的形式
- result6=result5.map(lambda x:(getindex(),x))
- result6.foreach(print)
- # 将结果保存到本地文件系统
- result6.saveAsTextFile("file:///home/zhc/mycode/RDD/filesort/sortresult")
- if __name__ == '__main__':
- main()
使用spark-submit提交FileSort.py文件,得到结果如下。

可以到“/home/zhc/mycode/RDD/filesort/sortresult”目录下查看结果文件part-00000。
- [root@bigdata RDD]# cd ./filesort/sortresult
- [root@bigdata sortresult]# cat part-00000
案例三:二次排序
任务描述: 对于一个给定的文件(数据如file4.txt所示),请对数据进行排序,首先根据第1列数据降序排序,如果第1列数据相等,则根据第2列数据降序排序。
输入文件 file4.txt:
5 3
1 6
4 9
8 3
4 7
5 6
3 2
- [root@bigdata RDD]# vi file4.txt
- [root@bigdata RDD]# vi SecondarySortApp.py
- [root@bigdata RDD]# spark-submit SecondarySortApp.py
在“/home/zhc/mycode/RDD”路径下,使用vim编辑器将上面file4.txt文件内容输入。
使用vim编辑器编辑“/home/zhc/mycode/RDD/SecondarySortApp.py”文件:
- #/home/zhc/mycode/RDD/SecondarySortApp.py
- # 导入gt函数,用于比较大小
- from operator import gt
- from pyspark import SparkContext, SparkConf
- # 定义SecondarySortKey类
- class SecondarySortKey():
- def __init__(self, k):
- self.column1 = k[0]
- self.column2 = k[1]
- # 定义__gt__方法,用于比较大小
- def __gt__(self, other):
- if other.column1 == self.column1:
- return gt(self.column2,other.column2)
- else:
- return gt(self.column1, other.column1)
-
- def main():
- # 创建SparkConf对象,设置应用程序名称和部署模式(本地1核运行)
- conf = SparkConf().setAppName('spark_sort').setMaster('local[1]')
- sc = SparkContext(conf=conf)
- file="file:///home/zhc/mycode/RDD/file4.txt"
- rdd1 = sc.textFile(file)
- # 过滤出长度不为0的行
- rdd2=rdd1.filter(lambda x:(len(x.strip()) > 0))
- # 将每行数据转换成带有键值对的元组,键为元组类型
- rdd3=rdd2.map(lambda x:((int(x.split(" ")[0]),int(x.split(" ")[1])),x))
- # 将数据中的键转换成SecondarySortKey类型
- rdd4=rdd3.map(lambda x: (SecondarySortKey(x[0]),x[1]))
- # 对数据进行按键排序
- rdd5=rdd4.sortByKey(False)
- # 只保留值
- rdd6=rdd5.map(lambda x:x[1])
- rdd6.foreach(print)
-
- if __name__ == '__main__':
- main()


使用spark-submit提交SecondarySortApp.py文件,得到结果如下。

四、结果分析与实验体会
在进行RDD编程实验之前,需要掌握Spark的基本概念和RDD的特性,例如惰性计算、分区、依赖关系等。同时需要了解Python等语言的基础知识。在实验过程中,可以通过以下步骤来完成:
(1)创建SparkContext对象,用于连接Spark集群和创建RDD;(2)通过textFile函数读取文件数据,并利用filter等函数进行数据清洗和处理;(3)将数据转换成键值对的形式,再利用map、reduceByKey等函数进行计算和处理;(4)利用sortByKey等函数进行排序操作;(5)最后通过foreach等函数将结果输出。
在实验过程中,需要注意以下几点:(1)选择合适的算子,例如filter、map、reduceByKey、sortByKey等,以及合适的lambda表达式来进行数据处理和计算。(2)对于大规模数据的处理,需要考虑分区和并行计算,以提高计算效率。(3)需要注意数据类型和格式,确保数据的正确性和一致性。(4)在进行排序操作时,需要利用自定义类来实现二次排序等功能。
总之,通过实验可以更加深入地理解Spark的原理和机制,提高数据处理和计算的效率和准确性。同时也能够培养代码编写和调试的能力,提高编程水平。

