
- 1Mac 安装 JDK21 流程_open jdk21 for mac
- 2使用Flask部署YoloV3-PyTorch_flask yolov3
- 3git补充(fetch和rebase)_fetch rebase
- 4如何使用docker pull命令从腾讯云镜像加速源拉取镜像,以提高下载速度?_docker pull mysql 8.0.36 命令加速 指定镜像
- 5Unity 读取调用资源 Resources.Load(详细+示例)_unity resources.load
- 6C++11:模板(可变模板参数)_c++ 模板参数包 使用
- 7Arduino驱动MLX90614红外测温传感器(温湿度传感器)_arduino uno mlx90614
- 8Dockerfile及Docker-compose Yaml_dockerfile与docker-compose.yaml
- 9注意力机制 YOLOv8添加注意力机制_yolov8引入注意力机制
- 10HarmonyOS应用开发培训笔记2_自定义组件可以声明props属性,父组件
SparkSQL系列-6、外部数据源 DataSource?_datasource.enabled spark
赞
踩
版权声明:本文为博主原创文章,遵循 CC 4.0 BY-SA 版权协议,转载请附上原文出处链接和本声明。
传送门:大数据系列文章目录
官方网址:http://spark.apache.org/、 http://spark.apache.org/sql/

SparkSQL支持哪些外部数据源?
在SparkSQL模块,提供一套完成API接口,用于方便读写外部数据源的的数据(从Spark 1.4版本提供),框架本身内置外部数据源:
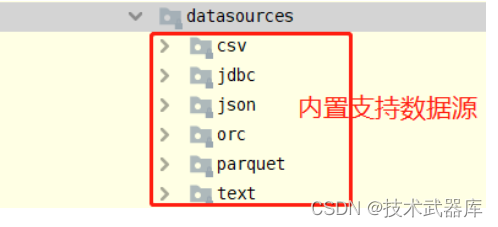
在Spark 2.4版本中添加支持Image Source(图像数据源)和Avro Source。
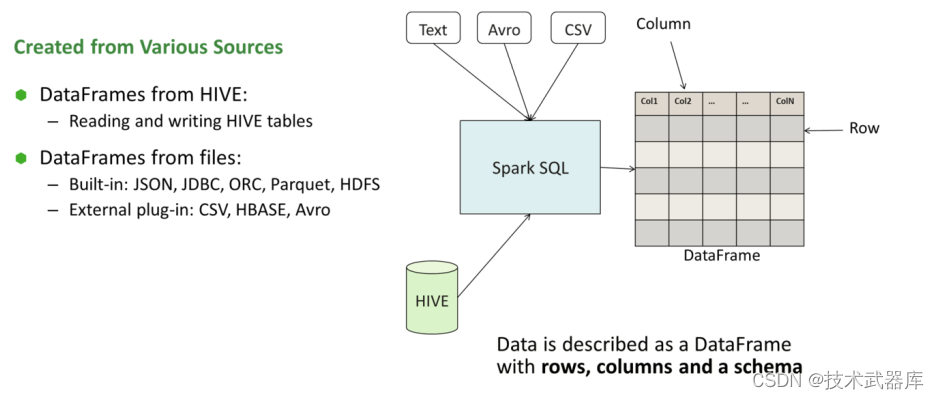
数据源与格式
数据分析处理中,数据可以分为结构化数据、非结构化数据及半结构化数据。

1)、结构化数据(Structured)
- 结构化数据源可提供有效的存储和性能。例如, Parquet和ORC等柱状格式使从列的子集中提取值变得更加容易。
- 基于行的存储格式(如Avro)可有效地序列化和存储提供存储优势的数据。然而,这些优点通常以灵活性为代价。如因结构的固定性,格式转变可能相对困难。
2)、非结构化数据(UnStructured)
- 相比之下,非结构化数据源通常是自由格式文本或二进制对象,其不包含标记或元数据以定义数据的结构。
- 报纸文章,医疗记录,图像,应用程序日志通常被视为非结构化数据。这些类型的源通常要求数据周围的上下文是可解析的。
3)、半结构化数据(Semi-Structured)
- 半结构化数据源是按记录构建的,但不一定具有跨越所有记录的明确定义的全局模式。每个数据记录都使用其结构信息进行扩充。
- 半结构化数据格式的好处是,它们在表达数据时提供了最大的灵活性,因为每条记录都是自我描述的。但这些格式的主要缺点是它们会产生额外的解析开销,并且不是特别为ad-hoc(特定)查询而构建的。
加载/保存数据
SparkSQL提供一套通用外部数据源接口,方便用户从数据源加载和保存数据,例如从MySQL表中既可以加载读取数据: load/read,又可以保存写入数据: save/write。
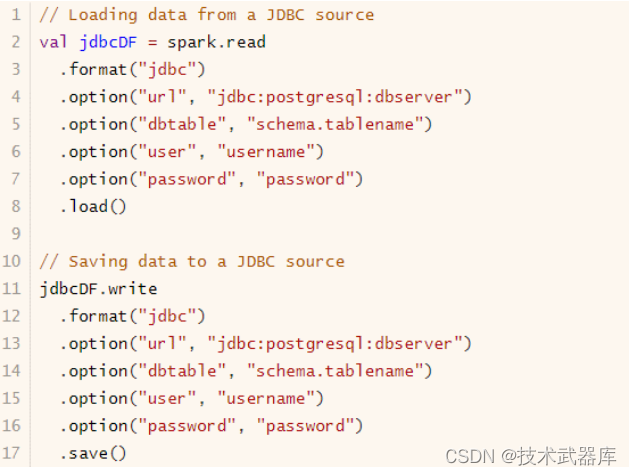
由于SparkSQL没有内置支持从HBase表中加载和保存数据,但是只要实现外部数据源接口,也能像上面方式一样读取加载数据
Load 加载数据
在SparkSQL中读取数据使用SparkSession读取,并且封装到数据结构Dataset/DataFrame中。

DataFrameReader专门用于加载load读取外部数据源的数据,基本格式如下:

SparkSQL模块本身自带支持读取外部数据源的数据:

总结起来三种类型数据,也是实际开发中常用的:
第一类:文件格式数据
- 文本文件text、 csv文件和json文件
第二类:列式存储数据
- Parquet格式、 ORC格式
第三类:数据库表
- 关系型数据库RDBMS: MySQL、 DB2、 Oracle和MSSQL
- Hive仓库表
官方文档: http://spark.apache.org/docs/2.4.5/sql-data-sources-load-save-functions.html
此外加载文件数据时, 可以直接使用SQL语句,指定文件存储格式和路径:

Save 保存数据
SparkSQL模块中可以从某个外部数据源读取数据,就能向某个外部数据源保存数据,提供相应接口,通过DataFrameWrite类将数据进行保存。

与DataFrameReader类似,提供一套规则,将数据Dataset保存,基本格式如下:

SparkSQL模块内部支持保存数据源如下:

所以使用SpakrSQL分析数据时,从数据读取,到数据分析及数据保存,链式操作,更多就是ETL操作。 当将结果数据DataFrame/Dataset保存至Hive表中时,可以设置分区partition和分桶bucket,形式如下:

案例演示
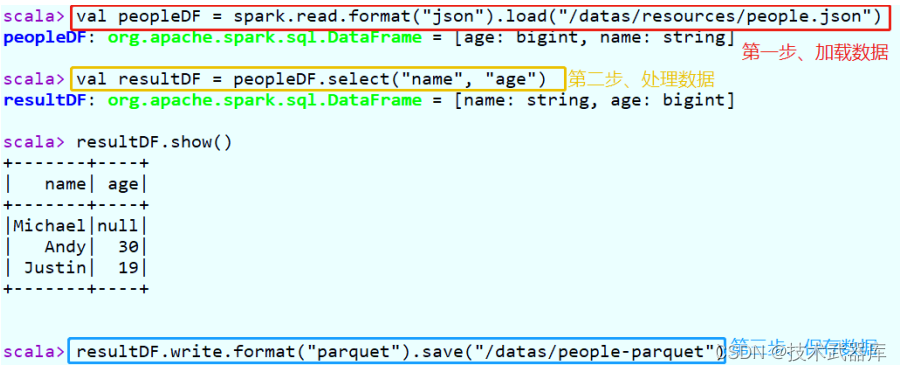
加载json格式数据,提取name和age字段值,保存至Parquet列式存储文件。
// 加载json数据
val peopleDF = spark.read.format("json").load("/datas/resources/people.json")
val resultDF = peopleDF.select("name", "age")
// 保存数据至parquet
resultDF.write.format("parquet").save("/datas/people-parquet")
- 1
- 2
- 3
- 4
- 5
在spark-shell上执行上述语句,截图结果如下:
查看HDFS文件系统目录,数据已保存值parquet文件,并且使用snappy压缩。
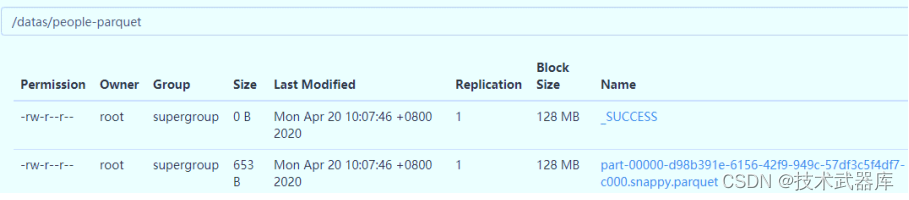
保存模式(SaveMode)
将Dataset/DataFrame数据保存到外部存储系统中,考虑是否存在,存在的情况下的下如何进行保存, DataFrameWriter中有一个mode方法指定模式:

通过源码发现SaveMode时枚举类,使用Java语言编写,如下四种保存模式:
- Append 追加模式,当数据存在时,继续追加;
- Overwrite 覆写模式,当数据存在时,覆写以前数据,存储当前最新数据;
- ErrorIfExists 存在及报错;
- Ignore 忽略,数据存在时不做任何操作;
实际项目依据具体业务情况选择保存模式,通常选择Append和Overwrite模式。
parquet 数据
SparkSQL模块中默认读取数据文件格式就是parquet列式存储数据, 通过参数
【spark.sql.sources.default】设置,默认值为【parquet】。
范例演示代码: 直接load加载parquet数据和指定parquet格式加载数据。
import org.apache.spark.sql.{DataFrame, SparkSession}
/**
* SparkSQL读取Parquet列式存储数据
*/
object SparkSQLParquet {
def main(args: Array[String]): Unit = {
// 构建SparkSession实例对象,通过建造者模式创建
val spark: SparkSession = SparkSession
.builder()
.appName(this.getClass.getSimpleName.stripSuffix("$"))
.master("local[3]")
.getOrCreate()
import spark.implicits._
// TODO: 从LocalFS上读取parquet格式数据
val usersDF: DataFrame = spark.read.parquet("datas/resources/users.parquet")
usersDF.printSchema()
usersDF.show(10, truncate = false)
// SparkSQL默认读取文件格式为parquet
val df = spark.read.load("datas/resources/users.parquet")
df.printSchema()
df.show(10, truncate = false)
// 应用结束,关闭资源
spark.stop()
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
运行程序结果:
root
|-- name: string (nullable = true)
|-- favorite_color: string (nullable = true)
|-- favorite_numbers: array (nullable = true)
| |-- element: integer (containsNull = true)
+------+--------------+----------------+
|name |favorite_color|favorite_numbers|
+------+--------------+----------------+
|Alyssa|null |[3, 9, 15, 20] |
|Ben |red |[] |
+------+--------------+----------------+
root
|-- name: string (nullable = true)
|-- favorite_color: string (nullable = true)
|-- favorite_numbers: array (nullable = true)
| |-- element: integer (containsNull = true)
+------+--------------+----------------+
|name |favorite_color|favorite_numbers|
+------+--------------+----------------+
|Alyssa|null |[3, 9, 15, 20] |
|Ben |red |[] |
+------+--------------+----------------+
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
text 数据
SparkSession加载文本文件数据,提供两种方法,返回值分别为DataFrame和Dataset,前面【入门案例:词频统计WordCount】中已经使用,下面看一下方法声明:

可以看出textFile方法底层还是调用text方法,先加载数据封装到DataFrame中,再使用as[String]方法将DataFrame转换为Dataset,实际项目中推荐使用textFile方法,从Spark 2.0开始提供。
无论是text方法还是textFile方法读取文本数据时, 一行一行的加载数据,每行数据使用UTF-8编码的字符串,列名称为【value】 。
范例演示: 分别使用text和textFile方法加载数据。
import org.apache.log4j.{Level, Logger}
import org.apache.spark.sql.{DataFrame, Dataset, SparkSession}
/**
* SparkSQL加载文本文件数据,方法text和textFile
*/
object SparkSQLText {
def main(args: Array[String]): Unit = {
// 构建SparkSession实例对象,通过建造者模式创建
val spark: SparkSession = SparkSession
.builder()
.appName(this.getClass.getSimpleName.stripSuffix("$"))
.master("local[3]")
.getOrCreate() // 底层实现:单例模式,创建SparkContext对象
Logger.getRootLogger.setLevel(Level.WARN)
// TODO: text方法加载数据,封装至DataFrame中
val dataframe: DataFrame = spark.read.text("datas/resources/people.txt")
dataframe.printSchema()
dataframe.show(10, truncate = false)
println("=================================================")
val dataset: Dataset[String] = spark.read.textFile("datas/resources/people.txt")
dataset.printSchema()
dataset.show(10, truncate = false)
spark.stop()// 应用结束,关闭资源
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
执行结果:
root
|-- value: string (nullable = true)
+-----------+
|value |
+-----------+
|Michael, 29|
|Andy, 30 |
|Justin, 19 |
+-----------+
=================================================
root
|-- value: string (nullable = true)
+-----------+
|value |
+-----------+
|Michael, 29|
|Andy, 30 |
|Justin, 19 |
+-----------+
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
json 数据
实际项目中,有时处理数据以JSON格式存储的,尤其后续结构化流式模块:
StructuredStreaming,从Kafka Topic消费数据很多时候是JSON个数据,封装到DataFrame中,需要解析提取字段的值。以读取github操作日志JSON数据为例,数据结构如下:
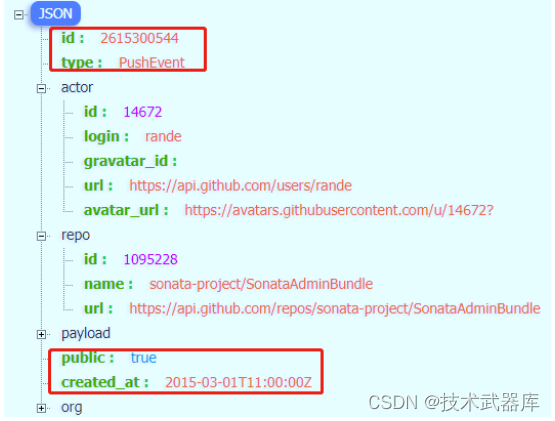
1)、操作日志数据使用GZ压缩: 2015-03-01-11.json.gz,先使用json方法读取。
// 构建SparkSession实例对象,通过建造者模式创建
val spark: SparkSession = SparkSession
.builder()
.appName(this.getClass.getSimpleName.stripSuffix("$"))
.master("local[3]")
// 底层实现:单例模式,创建SparkContext对象
.getOrCreate()
import spark.implicits._
// TODO: 从LocalFS上读取json格式数据(压缩)
val jsonDF: DataFrame = spark.read.json("datas/json/2015-03-01-11.json.gz")
jsonDF.printSchema()
jsonDF.show(10, truncate = true)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
2)、使用textFile加载数据,对每条JSON格式字符串数据,使用SparkSQL函数库functions中自带get_json_obejct函数提取字段: id、 type、 public和created_at的值。
函数: get_json_obejct使用说明

范例演示完整代码:
import org.apache.log4j.{Level, Logger}
import org.apache.spark.sql.{DataFrame, Dataset, SparkSession}
/**
* SparkSQL读取JSON格式文本数据
*/
object SparkSQLJson {
def main(args: Array[String]): Unit = {
// 构建SparkSession实例对象,通过建造者模式创建
val spark: SparkSession = SparkSession
.builder()
.appName(this.getClass.getSimpleName.stripSuffix("$"))
.master("local[3]")
// 底层实现:单例模式,创建SparkContext对象
.getOrCreate()
Logger.getRootLogger.setLevel(Level.WARN)
import spark.implicits._
// TODO: 从LocalFS上读取json格式数据(压缩)
val jsonDF: DataFrame = spark.read.json("datas/json/2015-03-01-11.json.gz")
jsonDF.printSchema()
jsonDF.show(10, truncate = true)
println("===================================================")
val githubDS: Dataset[String] = spark.read.textFile("datas/json/2015-03-01-11.json.gz")
githubDS.printSchema() // value 字段名称,类型就是String
githubDS.show(1)
// TODO:使用SparkSQL自带函数,针对JSON格式数据解析的函数
import org.apache.spark.sql.functions._
// 获取如下四个字段的值: id、 type、 public和created_at
val gitDF: DataFrame = githubDS.select(
get_json_object($"value", "$.id").as("id"),
get_json_object($"value", "$.type").as("type"),
get_json_object($"value", "$.public").as("public"),
get_json_object($"value", "$.created_at").as("created_at")
)
gitDF.printSchema()
gitDF.show(10, truncate = false)
// 应用结束,关闭资源
spark.stop()
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
csv 数据
在机器学习中,常常使用的数据存储在csv/tsv文件格式中,所以SparkSQL中也支持直接读取格式数据,从2.0版本开始内置数据源。关于CSV/TSV格式数据说明:

SparkSQL中读取CSV格式数据,可以设置一些选项,重点选项:
1)、分隔符: sep
- 默认值为逗号,必须单个字符
2)、数据文件首行是否是列名称: header
- 默认值为false,如果数据文件首行是列名称,设置为true
3)、是否自动推断每个列的数据类型: inferSchema
- 默认值为false,可以设置为true
官方提供案例:

当读取CSV/TSV格式数据文件首行是否是列名称,读取数据方式(参数设置)不一样的 。
第一点:首行是列的名称,如下方式读取数据文件
// TODO: 读取TSV格式数据
val ratingsDF: DataFrame = spark.read
// 设置每行数据各个字段之间的分隔符, 默认值为 逗号
.option("sep", "\t")
// 设置数据文件首行为列名称,默认值为 false
.option("header", "true")
// 自动推荐数据类型,默认值为false
.option("inferSchema", "true")
// 指定文件的路径
.csv("datas/ml-100k/u.dat")
ratingsDF.printSchema()
ratingsDF.show(10, truncate = false)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
第二点:首行不是列的名称,如下方式读取数据(设置Schema信息)
// 定义Schema信息
val schema = StructType(
StructField("user_id", IntegerType, nullable = true) ::
StructField("movie_id", IntegerType, nullable = true) ::
StructField("rating", DoubleType, nullable = true) ::
StructField("timestamp", StringType, nullable = true) :: Nil
)
// TODO: 读取TSV格式数据
val mlRatingsDF: DataFrame = spark.read
// 设置每行数据各个字段之间的分隔符, 默认值为 逗号
.option("sep", "\t")
// 指定Schema信息
.schema(schema)
// 指定文件的路径
.csv("datas/ml-100k/u.data")
mlRatingsDF.printSchema()
mlRatingsDF.show(5, truncate = false)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
将DataFrame数据保存至CSV格式文件,演示代码如下:
/**
* 将电影评分数据保存为CSV格式数据
*/
mlRatingsDF
// 降低分区数,此处设置为1,将所有数据保存到一个文件中
.coalesce(1)
.write
// 设置保存模式,依据实际业务场景选择,此处为覆写
.mode(SaveMode.Overwrite)
.option("sep", ",")
// TODO: 建议设置首行为列名
.option("header", "true")
.csv("datas/ml-csv-" + System.nanoTime())
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
范例演示完整代码SparkSQLCsv.scala如下:
import org.apache.log4j.{Level, Logger}
import org.apache.spark.SparkContext
import org.apache.spark.sql.types._
import org.apache.spark.sql.{DataFrame, SaveMode, SparkSession}
/**
* SparkSQL 读取CSV/TSV格式数据:
* i). 指定Schema信息
* ii). 是否有header设置
*/
object SparkSQLCsv {
def main(args: Array[String]): Unit = {
// 构建SparkSession实例对象
val spark: SparkSession = SparkSession.builder()
.appName(SparkSQLCsv.getClass.getSimpleName)
.master("local[2]")
.getOrCreate()
Logger.getRootLogger.setLevel(Level.WARN)
import spark.implicits._
// 获取SparkContext实例对象
val sc: SparkContext = spark.sparkContext
/**
* 实际企业数据分析中
* csv\tsv格式数据,每个文件的第一行(head, 首行),字段的名称(列名)
*/
// TODO: 读取TSV格式数据
val ratingsDF: DataFrame = spark.read
// 设置每行数据各个字段之间的分隔符, 默认值为 逗号
.option("sep", "\t")
// 设置数据文件首行为列名称,默认值为 false
.option("header", "true")
// 自动推荐数据类型,默认值为false
.option("inferSchema", "true")
// 指定文件的路径
.csv("datas/ml-100k/u.dat")
ratingsDF.printSchema()
ratingsDF.show(10, truncate = false)
// 定义Schema信息
val schema = StructType(
StructField("user_id", IntegerType, nullable = true) ::
StructField("movie_id", IntegerType, nullable = true) ::
StructField("rating", DoubleType, nullable = true) ::
StructField("timestamp", StringType, nullable = true) :: Nil
)
// TODO: 读取TSV格式数据
val mlRatingsDF: DataFrame = spark.read
// 设置每行数据各个字段之间的分隔符, 默认值为 逗号
.option("sep", "\t")
// 指定Schema信息
.schema(schema)
// 指定文件的路径
.csv("datas/ml-100k/u.data")
mlRatingsDF.printSchema()
mlRatingsDF.show(5, truncate = false)
// 将电影评分数据保存为CSV格式数据
mlRatingsDF
// 降低分区数,此处设置为1,将所有数据保存到一个文件中
.coalesce(1)
.write
// 设置保存模式,依据实际业务场景选择,此处为覆写
.mode(SaveMode.Overwrite)
.option("sep", ",")
// TODO: 建议设置首行为列名
.option("header", "true")
.csv("datas/ml-csv-" + System.nanoTime())
// 关闭资源
spark.stop()
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
执行结果:
root
|-- userId: integer (nullable = true)
|-- movieId: integer (nullable = true)
|-- rating: integer (nullable = true)
|-- timestamp: integer (nullable = true)
+------+-------+------+---------+
|userId|movieId|rating|timestamp|
+------+-------+------+---------+
|196 |242 |3 |881250949|
|186 |302 |3 |891717742|
|22 |377 |1 |878887116|
|244 |51 |2 |880606923|
|166 |346 |1 |886397596|
|298 |474 |4 |884182806|
|115 |265 |2 |881171488|
|253 |465 |5 |891628467|
|305 |451 |3 |886324817|
|6 |86 |3 |883603013|
+------+-------+------+---------+
only showing top 10 rows
root
|-- user_id: integer (nullable = true)
|-- movie_id: integer (nullable = true)
|-- rating: double (nullable = true)
|-- timestamp: string (nullable = true)
+-------+--------+------+---------+
|user_id|movie_id|rating|timestamp|
+-------+--------+------+---------+
|196 |242 |3.0 |881250949|
|186 |302 |3.0 |891717742|
|22 |377 |1.0 |878887116|
|244 |51 |2.0 |880606923|
|196 |242 |3.0 |881250949|
+-------+--------+------+---------+
only showing top 5 rows
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
rdbms 数据
回顾在SparkCore中读取MySQL表的数据通过JdbcRDD来读取的,在SparkSQL模块中提供对应接口,提供三种方式读取数据:
方式一: 单分区模式

方式二: 多分区模式,可以设置列的名称,作为分区字段及列的值范围和分区数目

方式三: 高度自由分区模式,通过设置条件语句设置分区数据及各个分区数据范围

当加载读取RDBMS表的数据量不大时,可以直接使用单分区模式加载;当数据量很多时,考虑使用多分区及自由分区方式加载。
从RDBMS表中读取数据,需要设置连接数据库相关信息,基本属性选项如下:
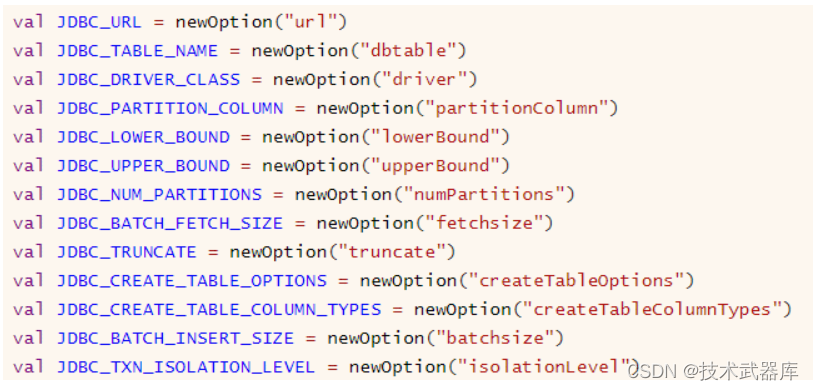
范例演示: 以MySQL数据库为例,加载订单表so数据,首先添加数据库驱动依赖包:
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>8.0.19</version>
</dependency>
- 1
- 2
- 3
- 4
- 5
完整演示代码如下:
import java.util.Properties
import org.apache.log4j.{Level, Logger}
import org.apache.spark.sql.{DataFrame, SparkSession}
/**
* 使用SparkSession从RDBMS 表中读取数据,此处以MySQL数据库为例
*/
object SparkSQLMySQL {
def main(args: Array[String]): Unit = {
// 在SparkSQL中,程序的同一入口为SparkSession实例对象,构建采用是建造者模式
val spark: SparkSession = SparkSession.builder()
.master("local[4]")
.appName("SparkSQLMySQL")
.config("spark.sql.shuffle.partitions", "4")
.getOrCreate()
Logger.getRootLogger.setLevel(Level.WARN)
// 导入隐式转换
import spark.implicits._
// 连接数据库三要素信息
val url: String = "jdbc:mysql://localhost:3306/test?serverTimezone=UTC&characterEncoding=utf8&useUnicode = true"
val table: String = "t_pay_log"
// 存储用户和密码等属性
val props: Properties = new Properties ()
props.put ("driver", "com.mysql.cj.jdbc.Driver")
props.put ("user", "root")
props.put ("password", "123456")
// TODO: 从MySQL数据库表:支付记录表
// def jdbc(url: String, table: String, properties: Properties): DataFrame
val sosDF: DataFrame = spark.read.jdbc (url, table, props)
println (s"Count = ${sosDF.count()}"
)
sosDF.printSchema()
sosDF.show(10, truncate = false)
// 关闭资源
spark.stop()
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
执行结果:
Count = 622
root
|-- id: long (nullable = true)
|-- create_date: timestamp (nullable = true)
|-- modify_date: timestamp (nullable = true)
|-- store_id: long (nullable = true)
|-- distributor_id: long (nullable = true)
|-- pay_order_type: integer (nullable = true)
|-- payer_user_id: string (nullable = true)
|-- payee_user_id: string (nullable = true)
|-- payee_account_number: string (nullable = true)
|-- order_id: long (nullable = true)
|-- order_no: string (nullable = true)
|-- amount: decimal(20,2) (nullable = true)
|-- deduction_amount: decimal(20,2) (nullable = true)
|-- credit_amount: decimal(20,2) (nullable = true)
|-- net_receipts_amount: decimal(20,2) (nullable = true)
|-- net_receipts_amount_cent: string (nullable = true)
|-- pay_time: timestamp (nullable = true)
|-- pay_sn: string (nullable = true)
|-- binding_tx_sn: string (nullable = true)
|-- binding_card_id: long (nullable = true)
|-- pay_status_name: string (nullable = true)
|-- pay_status: string (nullable = true)
|-- pay_type: string (nullable = true)
|-- pay_name: string (nullable = true)
|-- is_send_cpcn_pay: boolean (nullable = true)
|-- pay_business_type: integer (nullable = true)
|-- ext_type: integer (nullable = true)
|-- is_deduction_amount_return: boolean (nullable = true)
|-- callback_time: timestamp (nullable = true)
|-- service_charge: decimal(20,2) (nullable = true)
|-- is_duplicate_pay: boolean (nullable = true)
|-- accept_time: timestamp (nullable = true)
|-- is_delete: boolean (nullable = true)
|-- remark: string (nullable = true)
+---+-------------------+-------------------+--------+--------------+--------------+----------------------+----------------------+--------------------+--------+---------------------+------+----------------+-------------+-------------------+------------------------+-------------------+---------------------------+---------------------------+---------------+---------------+----------+--------+--------+----------------+-----------------+--------+--------------------------+-------------+--------------+----------------+-----------+---------+------+
|id |create_date |modify_date |store_id|distributor_id|pay_order_type|payer_user_id |payee_user_id |payee_account_number|order_id|order_no |amount|deduction_amount|credit_amount|net_receipts_amount|net_receipts_amount_cent|pay_time |pay_sn |binding_tx_sn |binding_card_id|pay_status_name|pay_status|pay_type|pay_name|is_send_cpcn_pay|pay_business_type|ext_type|is_deduction_amount_return|callback_time|service_charge|is_duplicate_pay|accept_time|is_delete|remark|
+---+-------------------+-------------------+--------+--------------+--------------+----------------------+----------------------+--------------------+--------+---------------------+------+----------------+-------------+-------------------+------------------------+-------------------+---------------------------+---------------------------+---------------+---------------+----------+--------+--------+----------------+-----------------+--------+--------------------------+-------------+--------------+----------------+-----------+---------+------+
|3 |2021-10-23 21:49:52|2021-11-28 18:44:15|24098 |1 |1 |PE20211021153512861672|PE20211013104025354326|null |7328 |STO816349545592226499|0.02 |0.00 |null |0.02 |2 |null |202110231349288471914024279|202110211551567835530441719|218 |支付失败 |40 |0 |快捷支付|true |0 |null |false |null |0.00 |false |null |true |null |
|4 |2021-10-25 17:36:56|2021-11-15 23:57:25|24098 |1 |1 |PE20211021153512861672|PE20211013104025354326|null |7328 |STO816349545592226499|0.02 |0.00 |null |0.02 |2 |null |202110250936497741984473432|202110211551567835530441719|218 |支付失败 |40 |0 |快捷支付|true |0 |null |false |null |0.00 |false |null |true |null |
|5 |2021-10-25 17:49:48|2021-11-28 18:44:23|24098 |1 |1 |PE20211021153512861672|PE20211013104025354326|null |7328 |STO816349545592226499|0.02 |0.00 |null |0.02 |2 |null |202110250949434516009115077|202110211551567835530441719|218 |支付失败1 |40 |0 |快捷支付|true |0 |null |false |null |0.00 |false |null |true |null |
|6 |2021-10-25 19:16:05|2021-11-15 23:57:25|24098 |1 |1 |PE20211021153512861672|PE20211013104025354326|null |7328 |STO816349545592226499|0.02 |0.00 |null |0.02 |2 |null |202110251116020875276500203|202110211551567835530441719|218 |支付失败 |40 |0 |快捷支付|true |0 |null |false |null |0.00 |false |null |true |null |
|7 |2021-10-25 19:32:28|2021-11-15 23:57:25|24098 |1 |1 |PE20211021153512861672|PE20211013104025354326|null |7328 |STO816349545592226499|0.02 |0.00 |null |0.02 |2 |null |202110251132225246101010159|202110211551567835530441719|218 |支付失败 |40 |0 |快捷支付|true |0 |null |false |null |0.00 |false |null |false |null |
|8 |2021-10-25 20:13:11|2021-11-15 23:57:25|24098 |1 |1 |PE20211021153512861672|PE20211013104025354326|null |7329 |STO816351349582806323|0.02 |0.00 |null |0.02 |2 |null |202110251213063509169295561|202110211551567835530441719|218 |支付处理中 |20 |0 |快捷支付|true |0 |null |false |null |0.00 |false |null |true |null |
|9 |2021-10-25 20:25:16|2021-11-15 23:57:25|24098 |1 |1 |PE20211021153512861672|PE20211013104025354326|null |7329 |STO816351349582806323|0.02 |0.00 |null |0.02 |2 |2021-10-25 20:26:54|202110251225113602792072707|202110211551567835530441719|218 |支付成功 |30 |0 |快捷支付|true |0 |null |false |null |0.00 |false |null |true |null |
|10 |2021-10-25 20:35:29|2021-11-15 23:57:25|24098 |1 |1 |PE20211021153512861672|PE20211013104025354326|null |7329 |STO816351349582806323|0.02 |0.00 |null |0.02 |2 |null |202110251235236495282362928|202110211551567835530441719|218 |支付失败 |40 |0 |快捷支付|true |0 |null |false |null |0.00 |false |null |true |null |
|11 |2021-10-25 20:41:24|2021-11-15 23:57:25|24098 |1 |1 |PE20211021153512861672|PE20211013104025354326|null |7329 |STO816351349582806323|0.02 |0.00 |null |0.02 |2 |null |202110251241198087141763857|202110211551567835530441719|218 |支付处理中 |20 |0 |快捷支付|true |0 |null |false |null |0.00 |false |null |true |null |
|12 |2021-10-25 20:47:25|2021-11-15 23:57:25|24098 |1 |1 |PE20211021153512861672|PE20211013104025354326|null |7330 |STO816351371385476431|0.02 |0.00 |null |0.02 |2 |null |202110251247195197853981367|202110211551567835530441719|218 |支付失败 |40 |0 |快捷支付|true |0 |null |false |null |0.00 |false |null |false |null |
+---+-------------------+-------------------+--------+--------------+--------------+----------------------+----------------------+--------------------+--------+---------------------+------+----------------+-------------+-------------------+------------------------+-------------------+---------------------------+---------------------------+---------------+---------------+----------+--------+--------+----------------+-----------------+--------+--------------------------+-------------+--------------+----------------+-----------+---------+------+
only showing top 10 rows
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
可以使用option方法设置连接数据库信息,而不使用Properties传递,代码如下:
// TODO: 使用option设置参数
val dataframe: DataFrame = spark.read
.format("jdbc")
.option("driver", "com.mysql.cj.jdbc.Driver")
.option("url", "jdbc:mysql://localhost:3306/test?serverTimezone=UTC&characterEncoding=utf8&useUnicode=tru
.option("user", "root")
.option("password", "123456")
.option("dbtable", "t_pay_log")
.load()
dataframe.show(5, truncate = false)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
hive 数据
Spark SQL模块从发展来说,从Apache Hive框架而来,发展历程: Hive(MapReduce) -> Shark(Hive on Spark) -> Spark SQL(SchemaRDD -> DataFrame -> Dataset),所以SparkSQL天然无缝集成Hive,可以加载Hive表数据进行分析。
官方文档: http://spark.apache.org/docs/2.4.5/sql-data-sources-hive-tables.html
spark-shell 集成 Hive
第一步、当编译Spark源码时,需要指定集成Hive,命令如下:

官方文档: http://spark.apache.org/docs/2.4.5/building-spark.html#building-with-hive-and-jdbc-support
第二步、 SparkSQL集成Hive本质就是: 读取Hive框架元数据MetaStore,此处启动Hive MetaStore服务即可。
- Hive 元数据MetaStore读取方式: JDBC连接四要素和HiveMetaStore服务

- 启动Hive MetaStore 服务,脚本【metastore-start.sh】内容如下:
#!/bin/sh
HIVE_HOME=/export/server/hive
## 启动服务的时间
DATE_STR=`/bin/date '+%Y%m%d%H%M%S'`
# 日志文件名称(包含存储路径)
HIVE_SERVER2_LOG=${HIVE_HOME}/hivemetastore-${DATE_STR}.log
## 启动服务
/usr/bin/nohup ${HIVE_HOME}/bin/hive --service metastore > ${HIVE_SERVER2_LOG} 2>&1 &
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
第三步、连接HiveMetaStore服务配置文件hive-site.xml,放于【$SPARK_HOME/conf】目录
<?xml version="1.0"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<property>
<name>hive.metastore.uris</name>
<value>thrift://node1.cn:9083</value>
</property>
</configuration>
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
将hive-site.xml配置发送到集群中所有Spark按照配置目录,此时任意机器启动应用都可以访问Hive表数据
第四步、案例演示,读取Hive中db_hive.emp表数据,分析数据
- 其一、读取表的数据,使用DSL分析
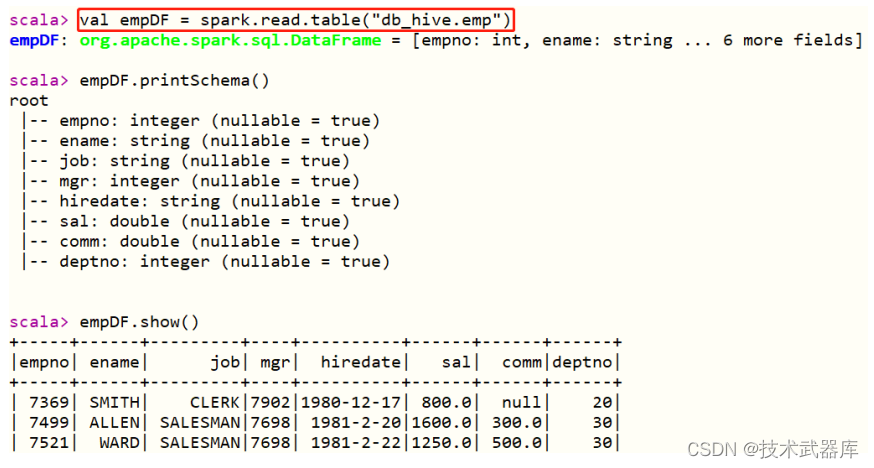
- 其二、直接编写SQL语句
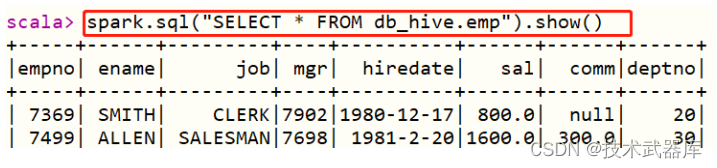
复杂SQL分析语句执行:
spark.sql("select e.ename, e.sal, d.dname from db_hive.emp e join db_hive.dept d on e.deptno = d.deptno").show()
- 1
IDEA 集成 Hive
在IDEA中开发应用,集成Hive,读取表的数据进行分析,构建SparkSession时需要设置HiveMetaStore服务器地址及集成Hive选项,首先添加MAVEN依赖包:
<!-- Spark SQL 与 Hive 集成 依赖 -->
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-hive_${scala.binary.version}</artifactId>
<version>${spark.version}</version>
</dependency>
- 1
- 2
- 3
- 4
- 5
- 6
范例演示代码如下:
import org.apache.spark.sql.SparkSession
/**
* SparkSQL集成Hive,读取Hive表的数据进行分析
*/
object SparkSQLHive {
def main(args: Array[String]): Unit = {
// TODO: 构建SparkSession实例对象
val spark: SparkSession = SparkSession.builder()
.appName(this.getClass.getSimpleName.stripSuffix("$"))
.master("local[4]")
.config("spark.sql.shuffle.partitions", "4")
// 指定Hive MetaStore服务地址
.config("hive.metastore.uris", "thrift://node1.cn:9083")
// TODO: 表示集成Hive,读取Hive表的数据
.enableHiveSupport()
.getOrCreate()
// 导入隐式转换
import spark.implicits._
// 导入函数库
import org.apache.spark.sql.functions._
// TODO: 读取Hive表的数据
spark.sql(
"""
|SELECT deptno, ROUND(AVG(sal), 2) AS avg_sal FROM db_hive.emp GROUP BY deptno
""".stripMargin)
.show(10, truncate = false)
println("===========================================================")
import org.apache.spark.sql.functions._
spark.read
.table("db_hive.emp")
.groupBy($"deptno")
.agg(round(avg($"sal"), 2).alias("avg_sal"))
.show(10, truncate = false)
// 应用结束,关闭资源
spark.stop()
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
运行程序结果如下:


