
- 1mid360+point-lio_all processes on machine have died, roslaunch will
- 2Swin Transformer代码详解(必懂)
- 3使用微软Phi-3-mini模型快速创建生成式AI应用_phi3 本地 部署 安装 csdn
- 4你是一名即将加入职场的程序员吗?试用期让你倍感压力?别担心,帮你苟过试用期!本指南为职场新人提供了必备的法则,让你顺利度过试用期,快速融入团队。赶紧来看看吧_刚入职的程序员怎么给压力
- 5PHP获取图片和视频类型_php 获取图片格式
- 6【已解决】RuntimeError: CUDA out of memory. Tried to allocate 50.00 MiB (GPU 0; 4.00 GiB total capacity;_torch.cuda.outofmemoryerror: cuda out of memory. t
- 7Vivado_除法器 IP核 使用详解_vivado除法器ip核
- 8RDD的创建-Scala_rdd的创建sanla
- 9群晖 root_群晖安装下载工具Transmission以及配置Transmission Web UI教程
- 10【八股】2024春招八股复习笔记3(测试、运维、安全、游戏、客户端)_渲染管线 八股
【spark sql】spark(八)sparkSQL概述:dataFrame、DataSet、UDF、SparkSQL数据源_sparksql 执行load data的时候需要多少资源
赞
踩
通过本文介绍sparksql的dataFrame、DataSet、UDF、SparkSQL数据源,来对sparksql有一个完整的了解
一. spark sql概述
Spark SQL是Spark用来处理结构化数据的一个模块,它提供了2个编程抽象:DataFrame和DataSet。 Spark
SQL是将Spark SQL转换成RDD,然后提交到集群中运行。
1. spark sql的由来
spark sql 前生是shark,但shark在兼容hive方面依赖hive过多,比如hive的语法解析器、查询优化器等。
spark sql在hive兼容方面仅依赖HQL parser、Hive Metastore、Hive SerDe。简单的说,从HQL被解析成抽象语法树后,就全部有Spark SQL接管了。其中执行计划生成和执行计划的优化都由Catalyst负责。
2. spark sql的运行流程
通用的sql执行计划
- 词法和语法解析,并生成逻辑计划
- 绑定:sql和实际的数据表绑定
- 优化Optimze:生成最优执行计划
- 执行并返回查询数据。
描述SparkSQL的执行过程之前先看下SparkSQL的构成:
core:处理数据的输入和输出,并将数据源转换为DataFrame
Catalyst:处理查询语句的整个过程:包括Sql的解析、绑定、优化、物理计划等。
Hive:对hive数据的处理
Hive-thrift server:提供client、JDBC等入口。
spark sql对sql语句的处理类似于上述关系型数据库的方法,其中:
spark sql先将sql语句进行解析形成一个Tree,然后使用Rule对Tree进行绑定、优化等处理。
sparkSQL查询优化器是catalyst,它负责对查询语句的解析、绑定、优化和生成物理计划等。
过程如下:
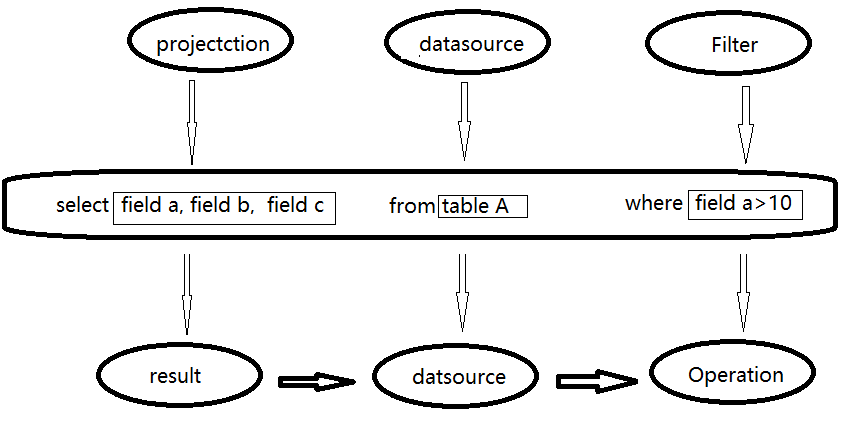
1. 语法和词法解析:比如解析上图sql中哪些是关键词、表达式、projection(select选择的列的集合)、datasource等,并判断sql语法是否规范,并形成逻辑计划。
2. 绑定: Analyzer使用Analysis Rules + 元数据,将sql和数据库中的数据字典(列、表、视图等)进行绑定,如果projection和datasource都在,则表示这个sql是可以执行的。
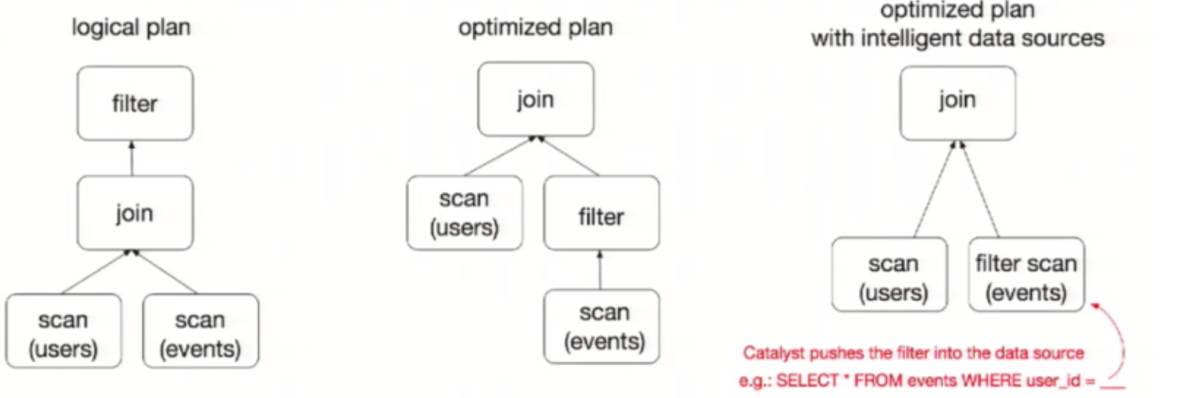
3. 优化: Optimizer使用Optimization Rules,将绑定的逻辑计划进行例如:合并、列裁剪、过滤器下推的优化工作后生成优化的逻辑计划。
4. 形成物理计划: 对优化后的逻辑计划进行转换形成可执行的物理计划。根据性能统计数据,选择最佳的物理执行计划(costModel),生成物理执行计划树,得到SparkPlan。
5. 执行: 进行preparation规则进行处理,最后调用spark plan的execute执行计算RDD。
3. spark sql的原理ing
spark sql的过程大致分为这几个过程:
1.通过Sqlparse 转成unresolvedLogicplan
2.通过Analyzer转成 resolvedLogicplan
3.通过optimizer转成 optimzedLogicplan
4.通过sparkplanner转成physicalLogicplan
5.通过prepareForExecution 转成executable logicplan
6.通过toRDD等方法执行executedplan去调用tree的doExecute
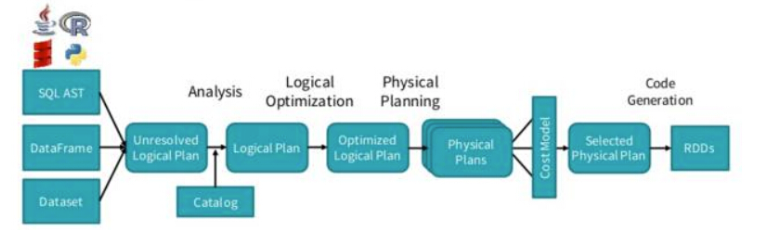
总体执行流程如下图:从(SQL,Dataset, dataframe)开始,依次经过未解析的逻辑计划—>解析的逻辑计划—>优化的逻辑计划—>物理计划—>根据cost based优化,选取一条物理计划进行执行。
二. sparkSQL的编程抽象:DataFrame和Dataset
1. DataFrame
1.1. 概述
DataFrame: 类似于数据库中的一张数据表,但只描述了字段名不知道每个字段的数据类型。
DataFrame和RDD的区别:
- RDD不了解数据结构,DataFrame是为数据提供了Schema的视图
- 性能上比RDD要高:例如对于join操作有谓词下推的效果
编程入口: 在Spark SQL中SparkSession是创建DataFrame和执行SQL的入口
dataframe的解析:
每一行的数据类型都是Row,导致每一列的值,只有通过解析才能获取。也可以通过字段的索引来访问数据(从0开始)

其他场景
如果要写一些适配性很强的函数时,如果使用Dataset,行的类型又不确定,可能是各种case class,无法实现适配,这时候用DataFrame即Dataset[Row]就能比较好的解决问题。
1.2 创建DataFrame的三种方式
通过Spark的数据源进行创建;
从一个存在的RDD进行转换;
还可以从HiveTable进行查询返回。
如下从json数据源中创建
json格式的源文件可以直接转为DataFrame格式的数据
scala> spark.read.json("file:/home/hadoop/tmpdata/test.json")
scala> res0.show
+---+----------+
|age| name|
+---+----------+
| 20| gaogao|
| 21|liangliang|
| 16| xiaoxiao|
| 18| lanlan|
+---+----------+
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
1.3 RDD与DataFrame相互转换
注意:如果需要RDD与DF或DS之间操作,那么都需要引入 import spark.implicits._ 【spark不是包名,而是sparkSession对象的名称】
1.3.1 单列和多列
单列:

多列:
scala> sc.makeRDD(Array((1,"xiaoxiao",23),(2,"lanlan",21),(3,"liaoliao",15)))
scala> res23.toDF("id","name","age")
scala> res24.show
- 1
- 2
- 3
1.3.2 RDD到dataframe
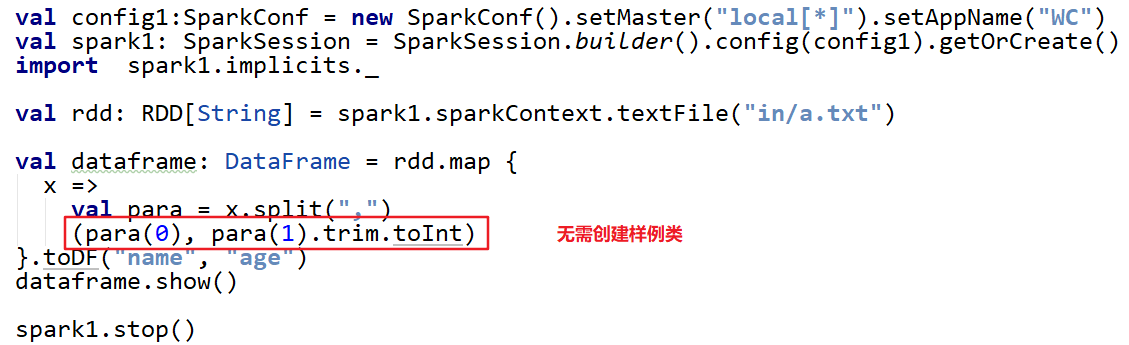
sparkSQL能够自动将包含case类的RDD通过toDF/toDS转换为DataFrame或DataSet
1.3.3 case class
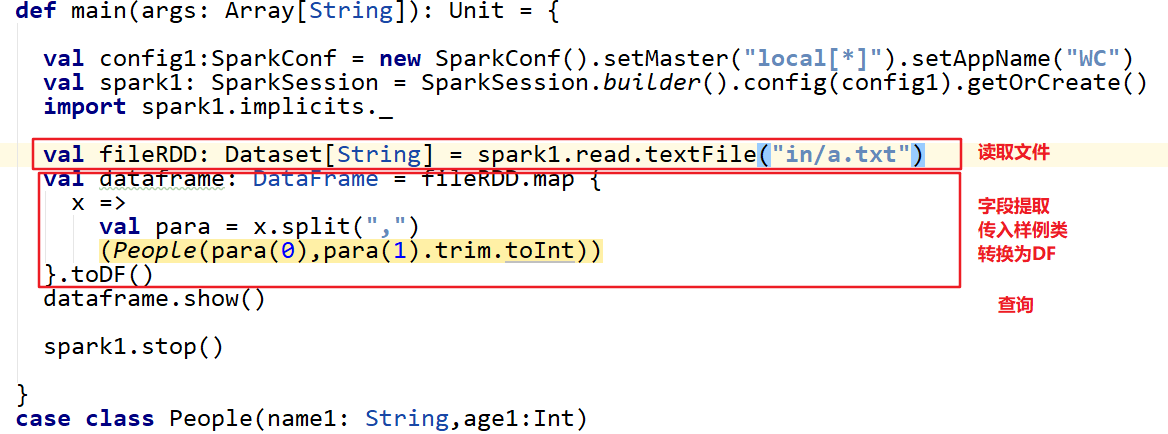
2. DataSet
2.1 概述
DataSet是分布式的数据集合,DataSet和java对象类似:关心数据的结构和属性。相比DataFrame,Dataset提供了编译时类型检查。
Spark2.0合并DataSet和DataFrame数据集合API,DataFrame变成DataSet的子集。
使用API尽量使用DataSet ,不行再选用DataFrame,其次选择RDD。
2.2 DataSet的转换
2.2.1 RDD转DataSet
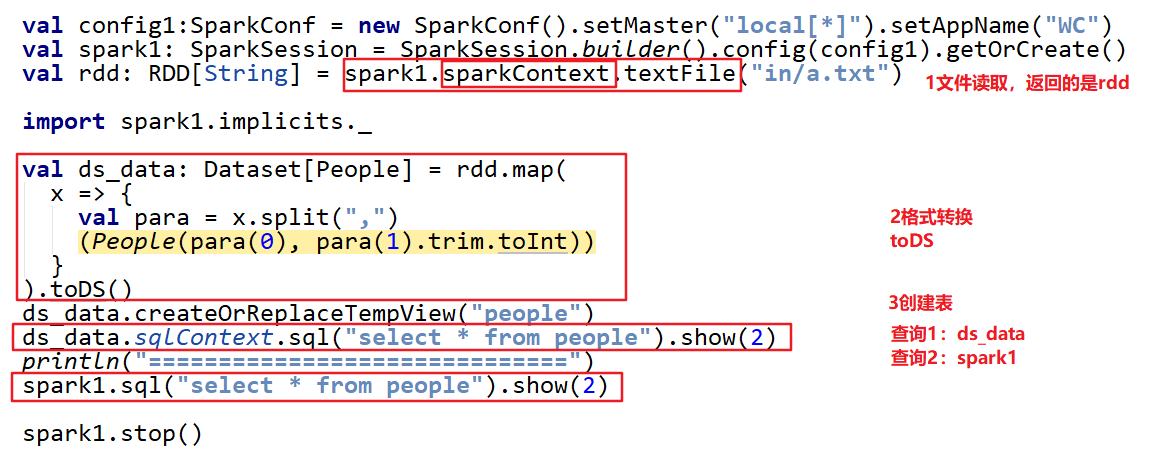
sparkSQL能够自动将包含case类的RDD通过toDF/toDS转换为DataFrame或DataSet
2.2.2 Seq序列到DataSet

2.2.3. DataFrame到DataSet

2.2.4. DataSet到RDD
scala> val toRDD=ds.rdd
scala> toRDD.foreach(println)
P1(11,11)
P1(22,22)
P1(33,13)
- 1
- 2
- 3
- 4
- 5
3. RDD、DataFrame和DataSet小结
3.1. 三者相互转换
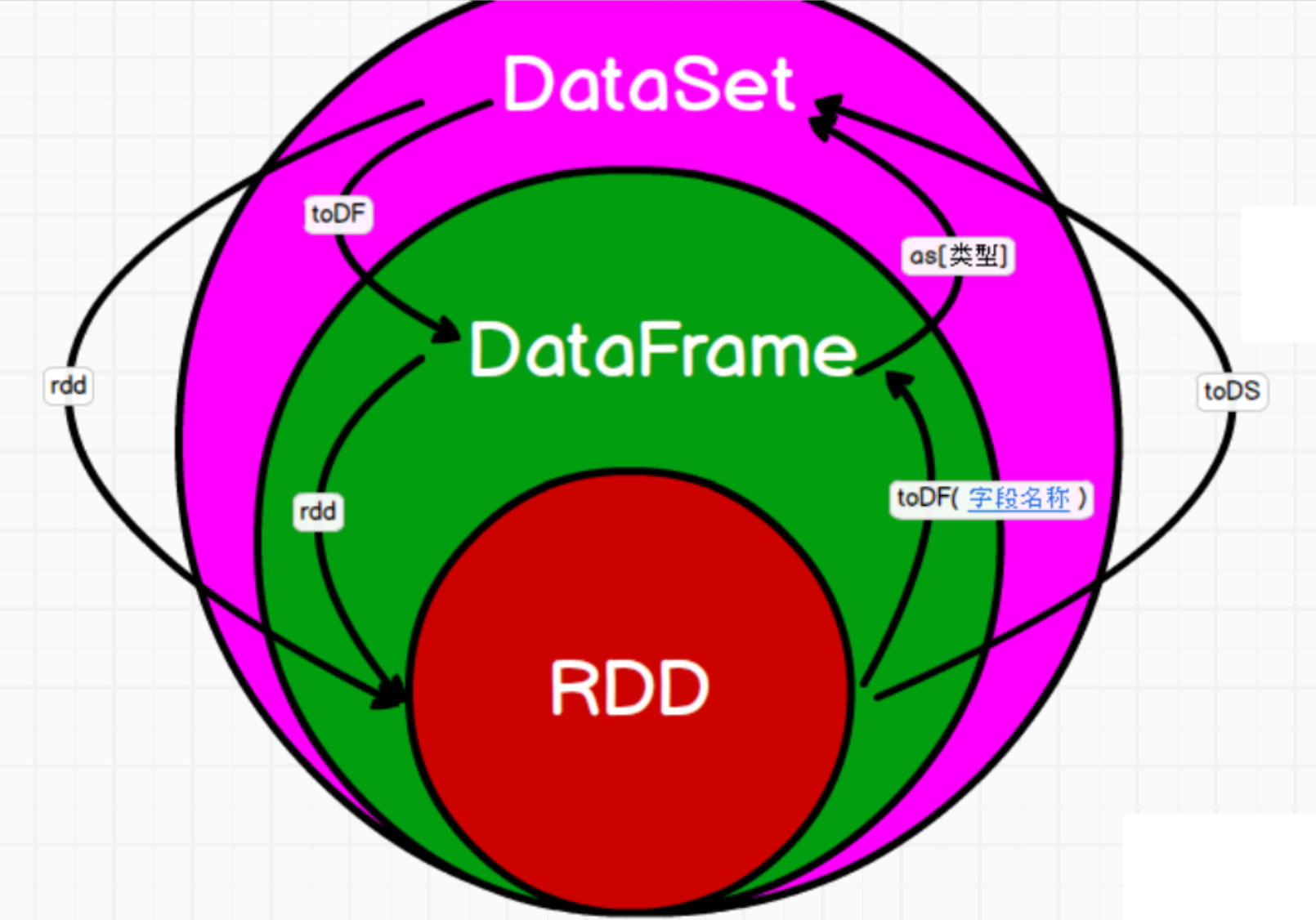
如果同样的数据都给到这三个数据结构,计算之后都会给出相同的结果。但执行效率和执行方式是不同的。
3.2. 三者的相同点
- 三者都有惰性机制
- 三者都会根据spark的内存情况自动缓存运算,这样即使数据量很大,也不用担心会内存溢出。
- 三者都有partition的概念
- 在对DataFrame和Dataset进行操作许多操作都需要这个包(import spark.implicits._)进行支持
- DataFrame和Dataset均可使用模式匹配获取各个字段的值和类型
三. spark sql 的UDF函数
1. 实现UDF

2. (对于强数据类型)实现UDAF函数

UDAF函数


四. spark sql 数据源
1. Parquet
Spark SQL的默认数据源为Parquet格式,Parquet是一种列式存储格式。

数据保存模式
"error"(default) : 如果文件存在,则报错
"append" : 追加
"overwrite" : 覆写
"ignore" : 数据存在,则忽略
- 1
- 2
- 3
- 4
2. json文件
自动推断:sparkSql能够自动推断JSON数据集的结构,并将它加载成DataFrame
加载:通过SparkSession.read.json()加载一个JSON文件
Spark中JSON文件的格式:不是一个传统的JSON文件,每一行都得是一个JSON串
{“name”:“Michael”}
{“name”:“Andy”, “age”:30}
读取和保存方式:

3. JDBC数据源
//从Mysql数据库加载数据
val connectionProperties = new Properties()
connectionProperties.put("user", "root")
connectionProperties.put("password", "000000")
val jdbcDF2 = spark.read.jdbc("jdbc:mysql://hadoop102:3306/rdd", "rddtable", connectionProperties)
//trans
//将数据写入Mysql
jdbcDF2.write.jdbc("jdbc:mysql://hadoop102:3306/rdd", "db", connectionProperties)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
4. Hive数据库
spark使用内置hive
展示表
scala> spark.sql("show tables").show
+--------+---------+-----------+
|database|tableName|isTemporary|
+--------+---------+-----------+
创建临时表
scala> jdbcDF.createTempView("stu1")
scala> spark.sql("show tables").show
+--------+---------+-----------+
|database|tableName|isTemporary|
+--------+---------+-----------+
| | stu1| true|
+--------+---------+-----------+
创建表并导入数据
scala> spark.sql("create table hhh(id int)")
scala> spark.sql("load data local inpath '/home/hadoop/tmpdata/h1' into table hhh")
scala> spark.sql("select * from hhh").show
+----+
| id|
+----+
| 1|
| 2|
| 3|
|null|
+----+
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
代码中集成Hive
(1)添加依赖:
<!-- https://mvnrepository.com/artifact/org.apache.spark/spark-hive -->
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-hive_2.11</artifactId>
<version>2.1.1</version>
</dependency>
<!-- https://mvnrepository.com/artifact/org.apache.hive/hive-exec -->
<dependency>
<groupId>org.apache.hive</groupId>
<artifactId>hive-exec</artifactId>
<version>1.2.1</version>
</dependency>
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
(2)使用hive源
//为使用内置Hive需要指定一个Hive仓库地址。若使用的是外部Hive,则需要将hive-site.xml添加到ClassPath下。
val warehouseLocation: String = new File("spark-warehouse").getAbsolutePath
val spark = SparkSession.builder().appName("Spark Hive Example")
.config("spark.sql.warehouse.dir", warehouseLocation)
.enableHiveSupport()
.getOrCreate()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
参考:
SparkSql运行原理详细解析

