
- 1ChatGPT之后,值得关注的垂直领域大模型
- 2BERT文本分类实战_bert进行英文分类
- 3【iVX】iVX的低代码未来发展趋势:加速应用开发的创新之路_ivx发展规划
- 4最常问的MySQL面试题集合
- 5单片机开发教程3——串口发送MPU6050姿态角_mpu6050数据 串口收发
- 6基于Java的XxlCrawler网络信息爬取基础篇
- 7Android studio页面跳转时闪退_安卓跳转多次activity闪退
- 8【蚂蚁笔试题汇总】[全网首发] 2024-03-30-蚂蚁春招笔试题-三语言题解(CPP Python Java)_蚂蚁笔试解析
- 9「6.1K Star 项目推荐」github主页”快速装修“神器
- 10【微信小程序】基础篇 -- 案例 - 本地生活(列表页面)(三十)_微信小程序设计实例
小白入门机器学习笔记之Transformer_零基础学习transformer
赞
踩
Transformer
1.1 基础架构
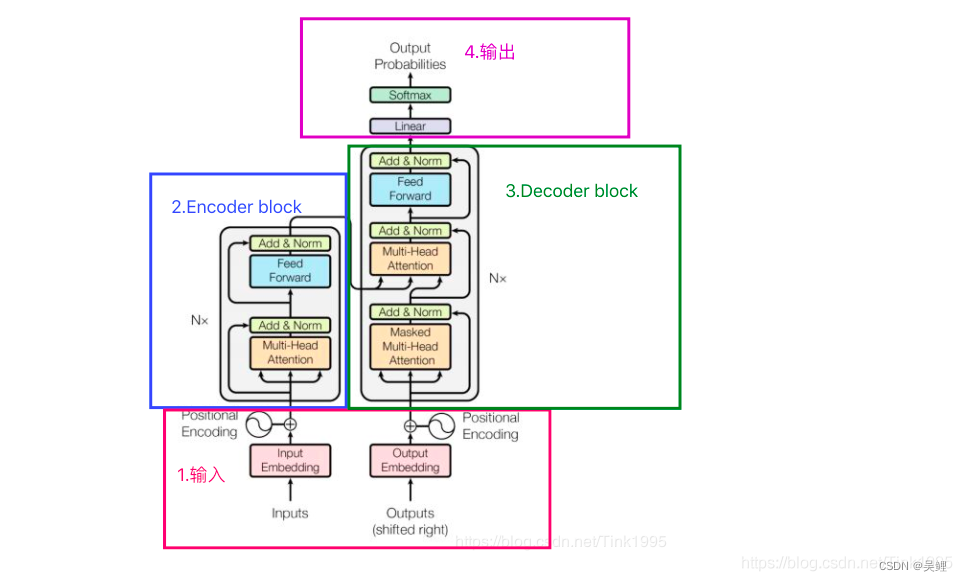
1.1.1Input输入层
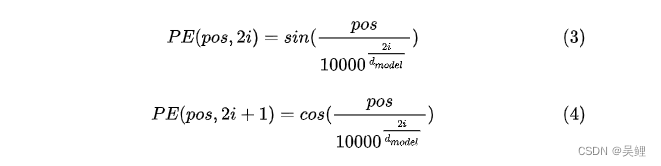
将词转化为词向量后进行位置编码。进行 位置编码是因为:一句话中的每个单词的摆放是有顺序的,但是self-attention机制是无顺序的。
1.1.2编码器 Encoder
一个Multi-Head Attention层,一个Feed Forward层,两个ADD&norm层
1.1.2.1Multi-Head Attention:

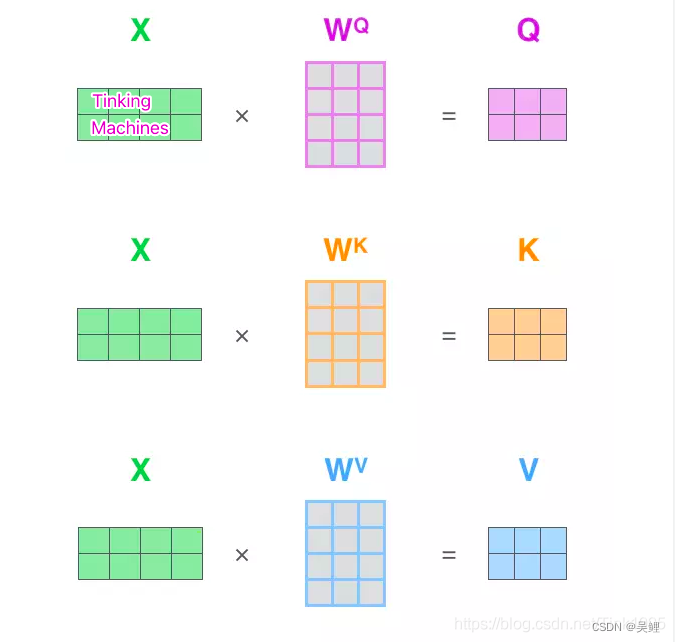
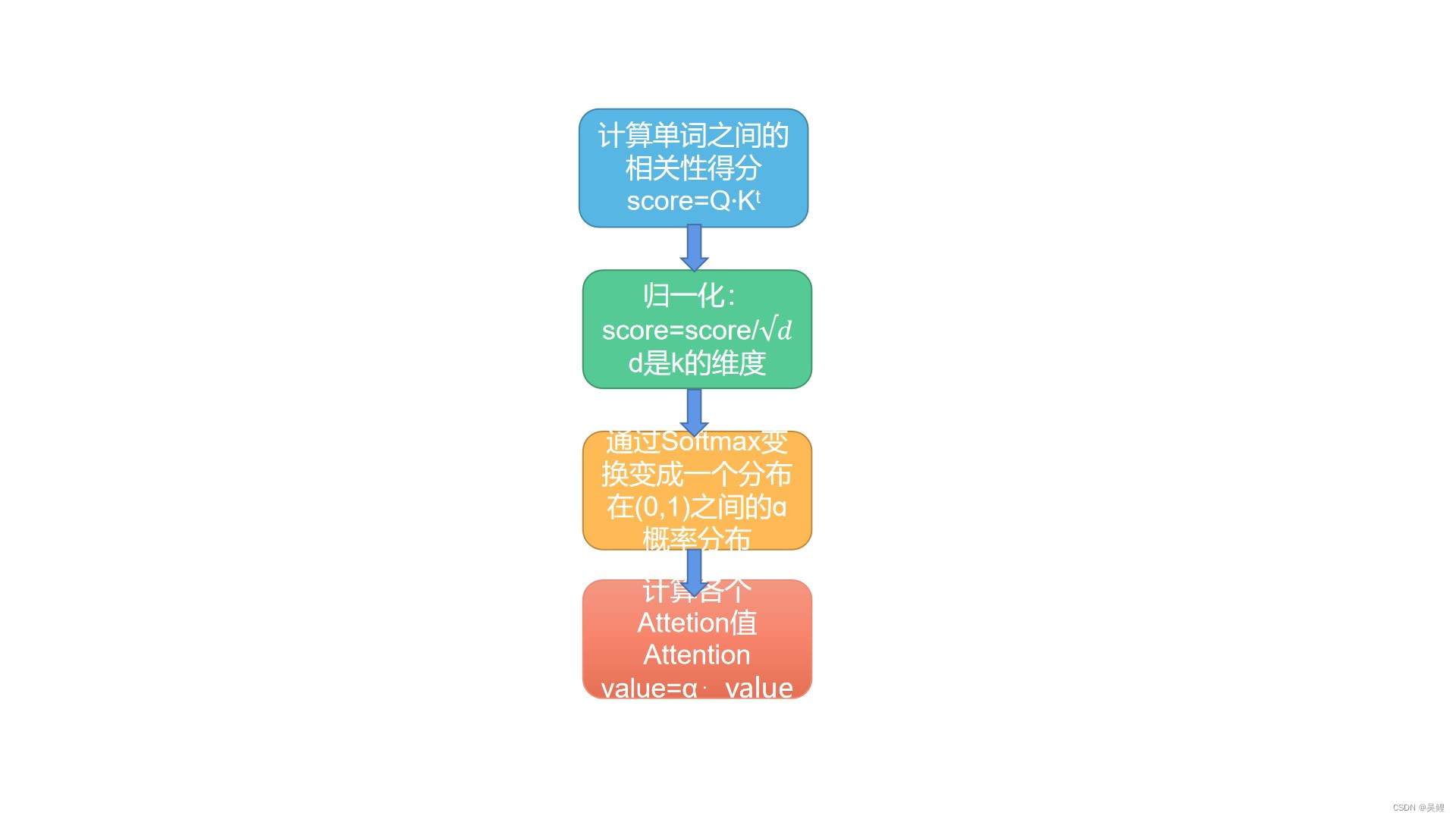
1.1.2.2 Multi Attention值计算流程图
Multi-Head Attention使用多组Wq、Wk、Wv得到多组Query,Keys,Values,然后每组分别计算得到一个Z矩阵,最后将得到的多个Z矩阵进行拼接。
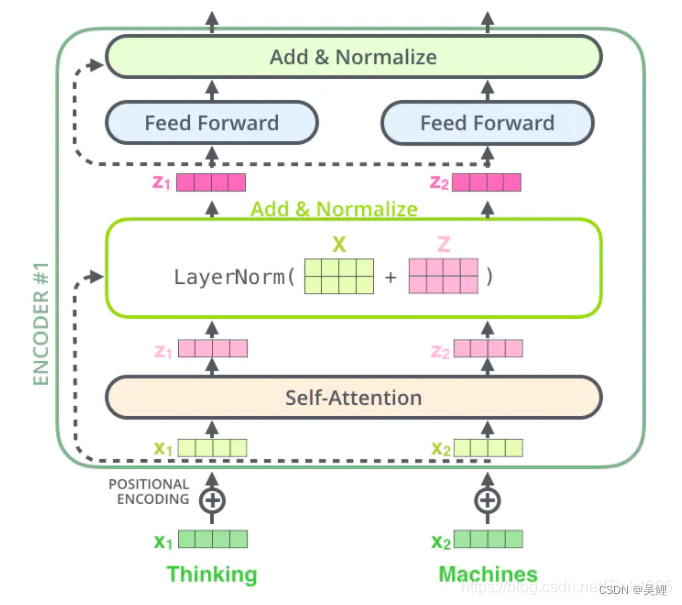
1.1.2.3Add&Normalize
ADD:
ResNet 残差神经网络是用来解决设计神经网络时,设计的网络层数大于使模型达到最优效果的层数时,将多余的层数进行恒等映射的一种方法。下面来介绍残差块。
一般来说,我们想到恒等映射会想到:h(x)=x.但是在模型进行学习的时候,者并不实用,因为在Relu函数将负数激活成了0,并且神经网络的初始参数一般接近于0,且经过变换后也更容易变换为0,而不是x.所以这里恒等映射函数用h(x)=F(x)+x,让F(x)=0会更加实用。

Layer Normalization(LN):
LN是在同一个样本中不同神经元之间进行归一化,而BN是在同一个batch中不同样本之间的同一位置的神经元之间进行归一化。当输入词后,对每一个batch的同一位置进行归一化是没有意义的。
1.1.2.4Feed-Forward Networks
全连接网络层:
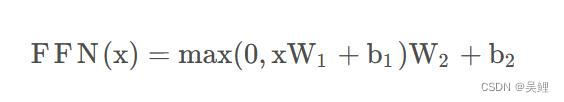
这里的全连接层是一个两层的神经网络,先线性变换,然后ReLU非线性,再线性变换。这里的x就是我们Multi-Head Attention的输出Z,还是引用上面的例子,那么Z是(2,64)维的矩阵,假设W1是(64,1024),其中W2与W1维度相反(1024,64),那么按照上面的公式:FFN(Z)=(2,64)x(64,1024)x(1024,64)=(2,64),我们发现维度没有发生变化,这两层网络就是为了将输入的Z映射到更加高维的空间中(2,64)x(64,1024)=(2,1024),然后通过非线性函数ReLU进行筛选,筛选完后再变回原来的维度。
1.1.3 Decoder
一个Masked Multi-Head Attention层,S一个Multi-Head Attention层,一个Feed Forward层,三个ADD&norm层
1.1.3.1Decoder输入
训练时输入,预测时输入
1.1.3.1.1 Masked Multi-Head Attention
mask分为两种,一种叫padding mask,一种叫sequence mask
padding mask:
因为输入的序列长度不一,所以要对过长和过短的序列进行处理,对于多余位置可以采用填充为一个无穷大的负数的方法来填充,这样经过softmax后,这些多余位置的编码会变成0.
sequence mask:
使在t时刻输出的单词只依赖t时刻之前的输出从,而不依赖t时刻之后的输出,所以要对t时刻之后单词及逆行遮掩。具体方法为:产生一个上三角矩阵,上三角的值全为0。把这个矩阵作用在每一个序列上,就可以达到我们的目的。
1.1.3.1.2 Multi-Head Attention**
第一个Masked Multi-Head Attention是为了得到之前已经预测输出的信息,相当于记录当前时刻的输入之间的信息的意思。第二个Multi-Head Attention是为了通过当前输入的信息得到下一时刻的信息,也就是输出的信息,是为了表示当前的输入与经过encoder提取过的特征向量之间的关系来预测输出。
1.1.4 输出
首先经过一次线性变换,然后Softmax得到输出的概率分布,然后通过词典,输出概率最大的对应的单词作为我们的预测输出。
2.简易结构总结
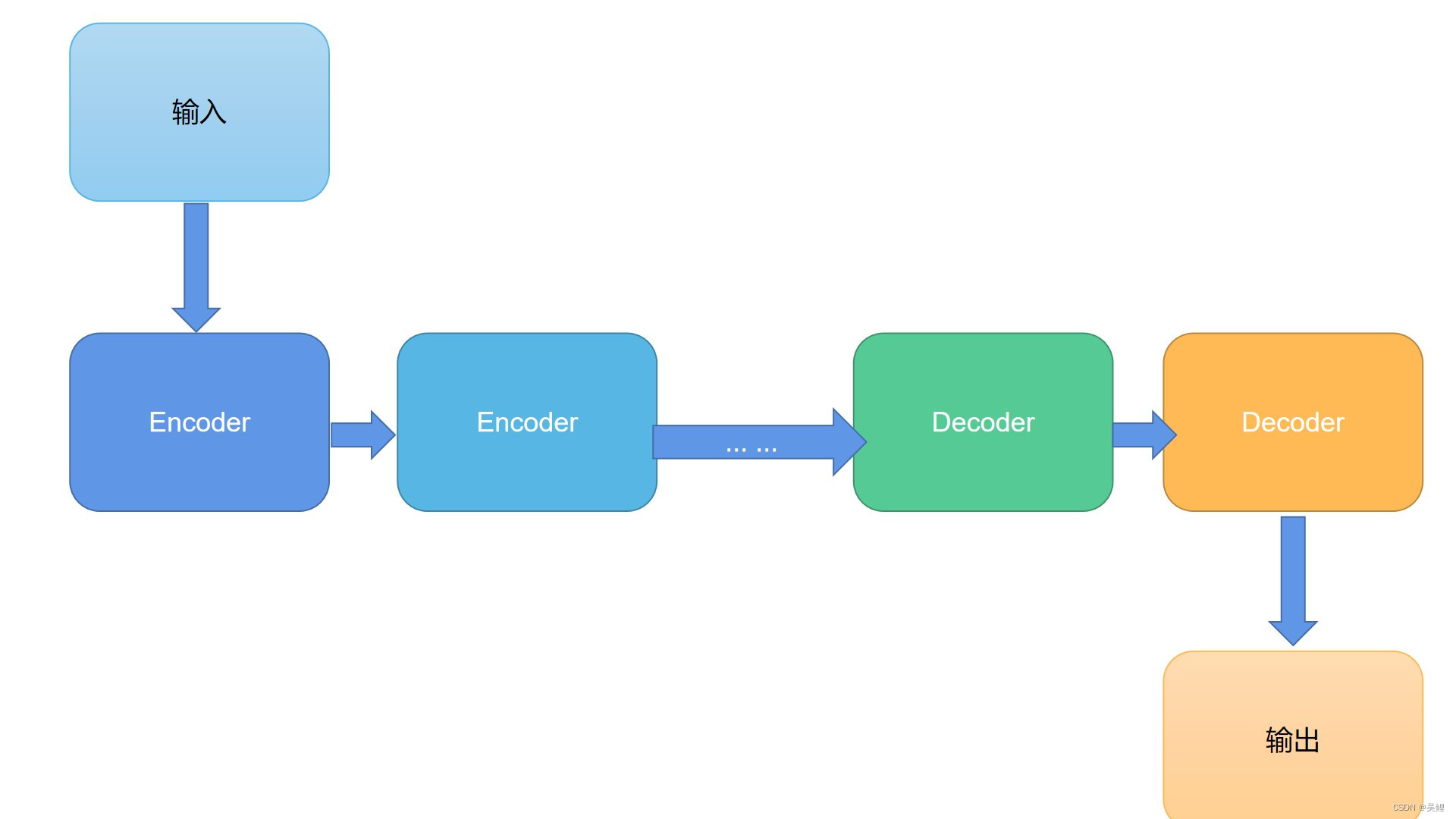
优点:可以进行并行运算,解决了长距离依赖的问题
缺点:在解决词语位置之间的信息方面的能力有所欠缺。

