
- 1刷一道leetcode花了一天,这正常吗?_力扣写一道题花一天时间
- 213(PHP连接Mysql)_php连接mysql数据库代码
- 3定时从linux获取文件,CentOS 6.4下定时通过ftp获取数据库服务器上的文件
- 4Docker 的安装使用_docker apt-get
- 5Flask Web开发:使用render_template渲染动态HTML模板
- 6c# 实习面试题_c#实习面试
- 7AI绘画:实例-利用Stable Diffusion ComfyUI实现多图连接:区域化提示词与条件设置_comfyui区域条件
- 8Python: 如何绘制核密度散点图和箱线图?_python 箱线图
- 9GitHub主页设计_给github主页装修
- 10GPU快速排序笔记_gpu quick sort
Flink保姆级面试大全(更新中)_flink系列常见面试题汇总
赞
踩
文章目录
一、Flink 简介
1.什么是Flink?
1.1概念
Apache Flink 是一个框架和分布式处理引擎,用于对无界和有界数据流进行有状态计算。Flink 被设计在所有常见的集群环境中运行,以内存执行速度和任意规模来执行计算。
1.2处理有界和无界数据
无界流有起点但没有定义的终点。无界流必须持续处理,即事件在被摄取后必须立即处理。处理无界数据通常需要以特定顺序(例如事件发生的顺序)摄取事件,以便能够推断结果的完整性。
有界流有定义的开始和结束。可以在执行任何计算之前摄取所有数据来处理有界流。处理有界流不需要有序摄取,因为有界数据集始终可以排序。有界流的处理也称作批处理。
2.什么是Flink Kubernetes Operator?
Flink Kubernetes Operator 充当控制平面来管理 Apache Flink 应用程序的完整部署生命周期。尽管 Flink 的原生 Kubernetes 集成已经允许您在运行的 Kubernetes(k8s) 集群上直接部署 Flink 应用程序,但自定义资源和操作员模式也已成为 Kubernetes 原生部署体验的核心。
Flink Kubernetes Operator 旨在承担管理 Flink 部署的人类操作员的职责。人类操作员对 Flink 部署应该如何运行、如何启动集群、如何部署作业、如何升级作业以及出现问题时如何反应有着深入的了解。操作者的主要目标是这些活动的自动化,这无法仅通过 Flink 原生集成來实现。
3.什么是Flink表存储?
Flink Table Store 是 Flink 中为流处理和批处理构建动态表的统一存储,支持高速数据摄取和及时的数据查询。表格存储提供以下核心能力:
支持大数据集的存储,并允许以批处理和流模式读取/写入。
支持流式查询,延迟最短可达毫秒。
支持批量/OLAP 查询,延迟最小至秒級。
默认支持增量快照进行流消费。因此用户无需自行组合不同的管道。
二、Flink 运行架构
1.Flink 运行时的组件
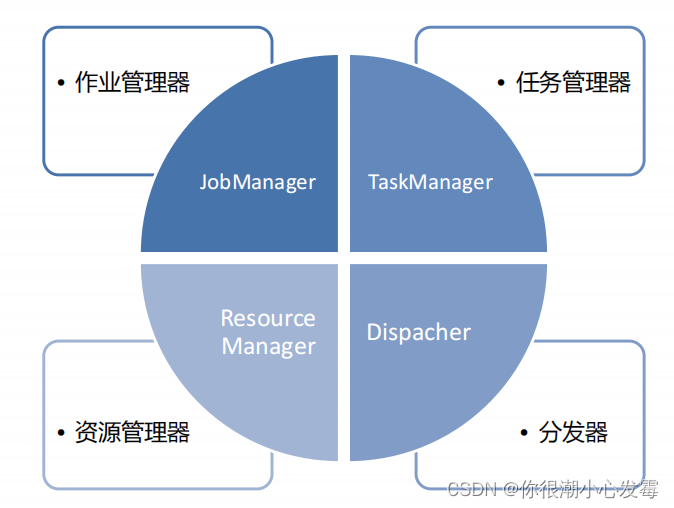
作业管理器(JobManager)
• 控制一个应用程序执行的主进程,也就是说,每个应用程序都会被一个不同的JobManager 所控制执行。
• JobManager 会先接收到要执行的应用程序,这个应用程序会包括:作业图(JobGraph)、逻辑数据流图(logical dataflow graph)和打包了所有的类、库和其它资源的JAR包。
• JobManager 会把JobGraph转换成一个物理层面的数据流图,这个图被叫做“执行图”(ExecutionGraph),包含了所有可以并发执行的任务。
• JobManager 会向资源管理器(ResourceManager)请求执行任务必要的资源,也就是任务管理器(TaskManager)上的插槽(slot)。一旦它获取到了足够的资源,就会将执行图分发到真正运行它们的TaskManager上。而在运行过程中,JobManager会负责所有需要中央协调的操作,比如说检查点(checkpoints)的协调。
任务管理器(TaskManager)
• Flink中的工作进程。通常在Flink中会有多个TaskManager运行,每一
个TaskManager都包含了一定数量的插槽(slots)。插槽的数量限制了TaskManager能够执行的任务数量。
• 启动之后,TaskManager会向资源管理器注册它的插槽;收到资源管理器的指令后,TaskManager就会将一个或者多个插槽提供给JobManager调用。JobManager就可以向插槽分配任务(tasks)来执行了。
• 在执行过程中,一个TaskManager可以跟其它运行同一应用程序的TaskManager交换数据。
资源管理器(ResourceManager)
• 主要负责管理任务管理器(TaskManager)的插槽(slot),TaskManger 插槽是Flink中定义的处理资源单元。
• Flink为不同的环境和资源管理工具提供了不同资源管理器,比如YARN、Mesos、K8s,以及standalone部署。
• 当JobManager申请插槽资源时,ResourceManager会将有空闲插槽的TaskManager分配给JobManager。如果ResourceManager没有足够的插槽来满足JobManager的请求,它还可以向资源提供平台发起会
话,以提供启动TaskManager进程的容器。
分发器(Dispatcher)
• 可以跨作业运行,它为应用提交提供了REST接口。
• 当一个应用被提交执行时,分发器就会启动并将应用移交给一个JobManager。
• Dispatcher也会启动一个Web UI,用来方便地展示和监控作业执行的信息。
• Dispatcher在架构中可能并不是必需的,这取决于应用提交运行的方式。
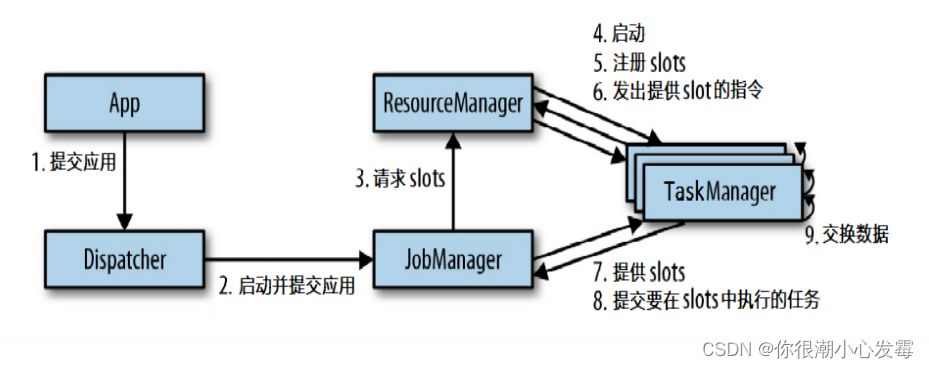
2.任务提交流程
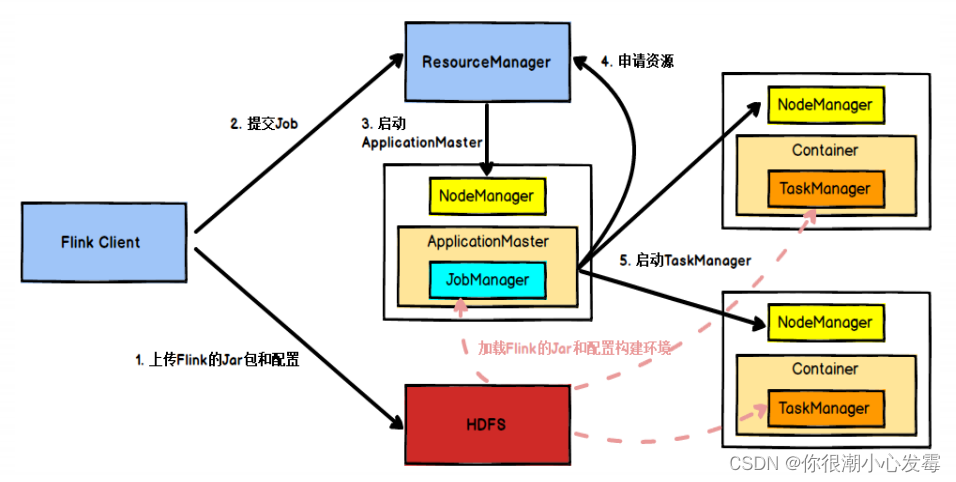
3.任务提交流程(YARN)
4.任务调度原理
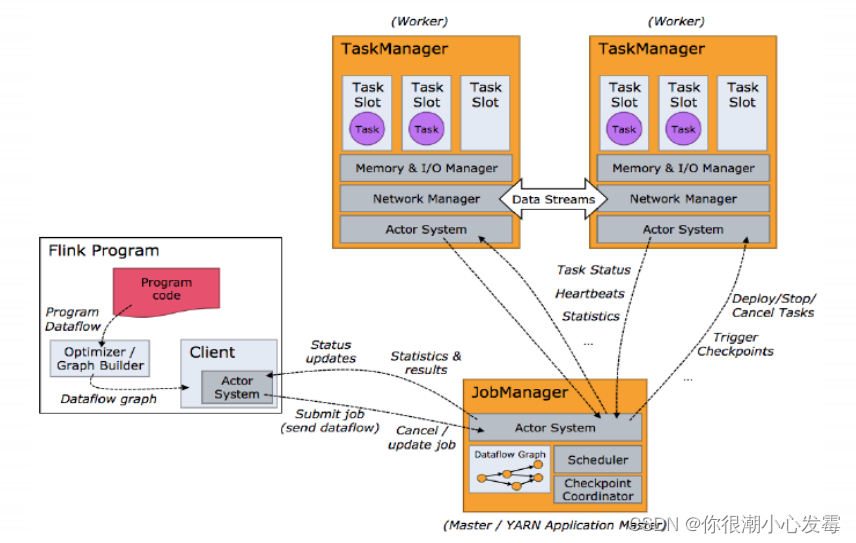
• 当Flink执行executor会自动根据程序代码生成DAG数据流图;
• ActorSystem创建Actor将数据流图发送给JobManager中的Actor;
• JobManager会不断接收TaskManager的心跳消息,从而可以获取到有效的TaskManager;
• JobManager通过调度器在TaskManager中调度执行Task(在Flink中,最小的调度单元就是task,对应就是一个线程);
• 在程序运行过程中,task与task之间是可以进行数据传输的。
5.并行度(Parallelism)
• 一个特定算子的 子任务(subtask)的个数被称之为其并行度(parallelism)。
一般情况下,一个 stream 的并行度,可以认为就是其所有算子中最大的并行度。
6.TaskManager 和 Slots
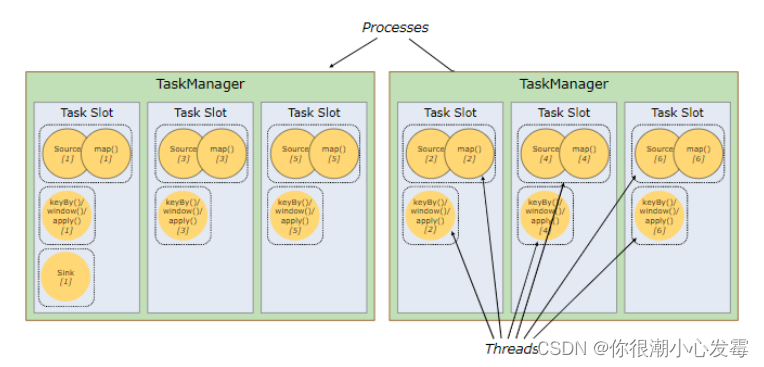
• Flink 中每一个 TaskManager 都是一个JVM进程,它可能会在独立的线程上执行一个或多个子任务
• 为了控制一个 TaskManager 能接收多少个 task, TaskManager 通过 task slot 来进行控制(一个 TaskManager 至少有一个 slot)
• 默认情况下,Flink 允许子任务共享 slot,即使它们是不同任务的子任务。 这样的结果是,一个 slot 可以保存作业的整个管道。
• Task Slot 是静态的概念,是指 TaskManager 具有的并发执行能力
7.程序与数据流(DataFlow)
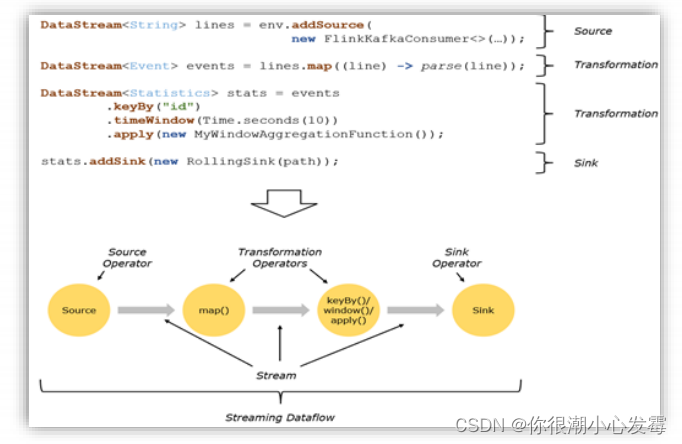
• 所有的Flink程序都是由三部分组成的:Source 、Transformation和Sink。
• Source 负责读取数据源,Transformation 利用各种算子进行处理加工,Sink负责输出
• 在运行时,Flink上运行的程序会被映射成“逻辑数据流”(dataflows),它包含了这三部分
• 每一个dataflow以一个或多个sources开始以一个或多个sinks结束。dataflow类似于任意的有向无环图(DAG)
• 在大部分情况下,程序中的转换运算(transformations)跟dataflow中的算子(operator)是一一对应的关系
8.执行图(ExecutionGraph)
• Flink 中的执行图可以分成四层:StreamGraph -> JobGraph -> ExecutionGraph -> 物理执行图
➢ StreamGraph:是根据用户通过 Stream API 编写的代码生成的最初的图。用来表示程序的拓扑结构。
➢ JobGraph:StreamGraph经过优化后生成了 JobGraph,提交给 JobManager 的数据结构。主要的优化为,将多个符合条件的节点 chain 在一起作为一个节点
➢ ExecutionGraph:JobManager 根据 JobGraph 生成ExecutionGraph。
ExecutionGraph是JobGraph的并行化版本,是调度层最核心的数据结构。
➢ 物理执行图:JobManager 根据 ExecutionGraph 对 Job 进行调度后,在各个TaskManager 上部署 Task 后形成的“图”,并不是一个具体的数据结构。
9.数据传输形式
• 一个程序中,不同的算子可能具有不同的并行度
• 算子之间传输数据的形式可以是 one-to-one (forwarding) 的模式也可以是redistributing 的模式,具体是哪一种形式,取决于算子的种类
➢ One-to-one:stream维护着分区以及元素的顺序(比如source和map之间)。这意味着map 算子的子任务看到的元素的个数以及顺序跟 source 算子的子任务生产的元素的个数、顺序相同。map、fliter、flatMap等算子都是one-to-one的对应关系。
➢ Redistributing:stream的分区会发生改变。每一个算子的子任务依据所选择的transformation发送数据到不同的目标任务。例如,keyBy 基于 hashCode 重分区、而 broadcast 和 rebalance 会随机重新分区,这些算子都会引起redistribute过程,而 redistribute 过程就类似于 Spark 中的 shuffle 过程。
10.任务链(Operator Chains)
• Flink 采用了一种称为任务链的优化技术,可以在特定条件下减少本地
通信的开销。为了满足任务链的要求,必须将两个或多个算子设为相同
的并行度,并通过本地转发(local forward)的方式进行连接
• 相同并行度的 one-to-one 操作,Flink 这样相连的算子链接在一起形
成一个 task,原来的算子成为里面的 subtask
• 并行度相同、并且是 one-to-one 操作,两个条件缺一不可
三、Flink window API
1.window 概念

• 一般真实的流都是无界的,怎样处理无界的数据?
• 可以把无限的数据流进行切分,得到有限的数据集进行处理 —— 也
就是得到有界流
• 窗口(window)就是将无限流切割为有限流的一种方式,它会将流
数据分发到有限大小的桶(bucket)中进行分析
2.window 类型
• 时间窗口(Time Window)
➢ 滚动时间窗口
➢ 滑动时间窗口
➢ 会话窗口
• 计数窗口(Count Window)
➢ 滚动计数窗口
➢ 滑动计数窗口
2.1滚动窗口(Tumbling Windows)
• 将数据依据固定的窗口长度对数据进行切分
• 时间对齐,窗口长度固定,没有重叠
2.2滑动窗口(Sliding Windows)
• 滑动窗口是固定窗口的更广义的一种形式,滑动窗口由固定的窗口
长度和滑动间隔组成
• 窗口长度固定,可以有重叠
2.3会话窗口(Session Windows)
• 由一系列事件组合一个指定时间长度的 timeout 间隙组成,也就是一段时间没有接收到新数据就会生成新的窗口
• 特点:时间无对齐
3.window API
• 窗口分配器 —— window() 方法
➢ 我们可以用 .window() 来定义一个窗口,然后基于这个 window 去做一些聚合或者其它处理操作。注意 window () 方法必须在 keyBy 之后才能用。
➢ Flink 提供了更加简单的 .timeWindow 和 .countWindow 方法,用于定义时间窗口和计数窗口。

3.1窗口分配器(window assigner)
• window() 方法接收的输入参数是一个 WindowAssigner
• WindowAssigner 负责将每条输入的数据分发到正确的 window 中
• Flink 提供了通用的 WindowAssigner
➢ 滚动窗口(tumbling window)
➢ 滑动窗口(sliding window)
➢ 会话窗口(session window)
➢ 全局窗口(global window)
3.2创建不同类型的窗口


3.3窗口函数(window function)
• window function 定义了要对窗口中收集的数据做的计算操作
• 可以分为两类
➢ 增量聚合函数(incremental aggregation functions)
• 每条数据到来就进行计算,保持一个简单的状态
• ReduceFunction, AggregateFunction
➢ 全窗口函数(full window functions)
• 先把窗口所有数据收集起来,等到计算的时候会遍历所有数据
• ProcessWindowFunction,WindowFunction
3.4其它可选 API
• .trigger() —— 触发器
➢ 定义 window 什么时候关闭,触发计算并输出结果
• .evictor() —— 移除器
➢ 定义移除某些数据的逻辑
• .allowedLateness() —— 允许处理迟到的数据
• .sideOutputLateData() —— 将迟到的数据放入侧输出流
• .getSideOutput() —— 获取侧输出流
4.Window 总结
4.1flink支持两种划分窗口的方式(time和count)
• 如果根据时间划分窗口,那么它就是一个time-window
• 如果根据数据划分窗口,那么它就是一个count-window
4.2flink支持窗口的两个重要属性(size和interval)
• 如果size=interval,那么就会形成tumbling-window(无重叠数据)
• 如果size>interval,那么就会形成sliding-window(有重叠数据)
• 如果size<interval,那么这种窗口将会丢失数据。比如每5秒钟,统计过去3秒的通过路口汽车的数据,将会漏掉2秒钟的数据。
4.3通过组合可以得出四种基本窗口
• time-tumbling-window 无重叠数据的时间窗口,设置方式举例:timeWindow(Time.seconds(5))
• time-sliding-window 有重叠数据的时间窗口,设置方式举例:timeWindow(Time.seconds(5), Time.seconds(3))
• count-tumbling-window无重叠数据的数量窗口,设置方式举例:countWindow(5)
四、Flink中的时间语义和watermark
1.Flink 中的时间语义
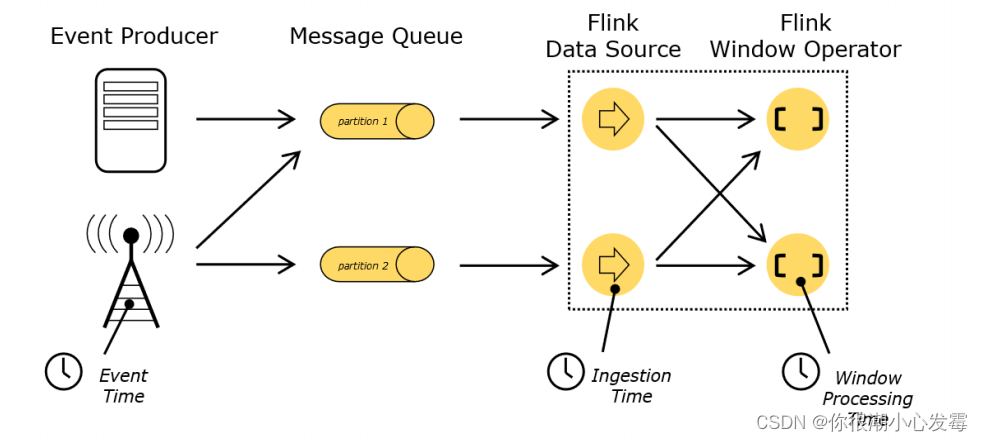
• Event Time:事件创建的时间
• Ingestion Time:数据进入Flink的时间
• Processing Time:执行操作算子的本地系统时间,与机器相关
哪种时间语义更重要:
不同的时间语义有不同的应用场合,我们往往更关心事件时间(Event Time)。某些应用场合,不应该使用 Processing Time,Event Time 可以从日志数据的时间戳(timestamp)中提取
2.设置 Event Time
• 我们可以直接在代码中,对执行环境调用 setStreamTimeCharacteristic
方法,设置流的时间特性
• 具体的时间,还需要从数据中提取时间戳(timestamp)

乱序数据的影响:
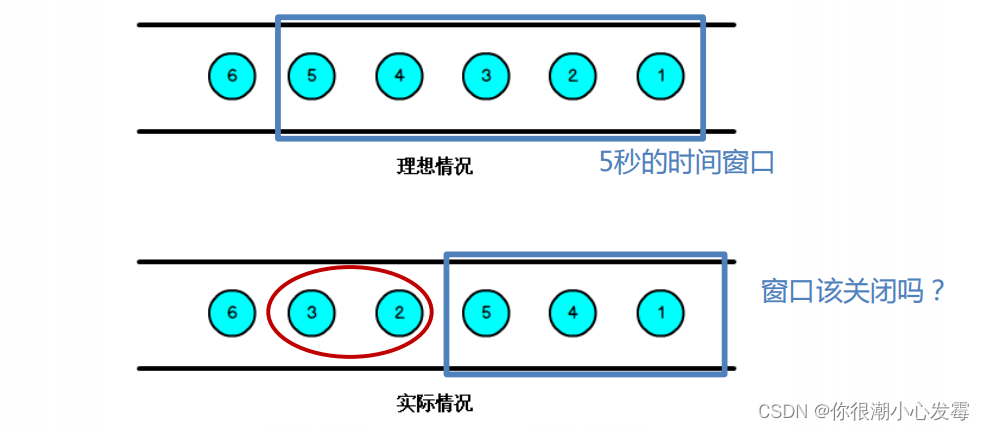
• 当 Flink 以 Event Time 模式处理数据流时,它会根据数据里的时间戳来
处理基于时间的算子
• 由于网络、分布式等原因,会导致乱序数据的产生
• 乱序数据会让窗口计算不准确
3.水位线(Watermark)
➢ 怎样避免乱序数据带来计算不正确?
➢ 遇到一个时间戳达到了窗口关闭时间,不应该立刻触发窗口计算,而是等
待一段时间,等迟到的数据来了再关闭窗口
• Watermark 是一种衡量 Event Time 进展的机制,可以设定延迟触发
• Watermark 是用于处理乱序事件的,而正确的处理乱序事件,通常用
Watermark 机制结合 window 来实现;
• 数据流中的 Watermark 用于表示 timestamp 小于 Watermark 的数据,
都已经到达了,因此,window 的执行也是由 Watermark 触发的。
• watermark 用来让程序自己平衡延迟和结果正确性
4.watermark 的特点
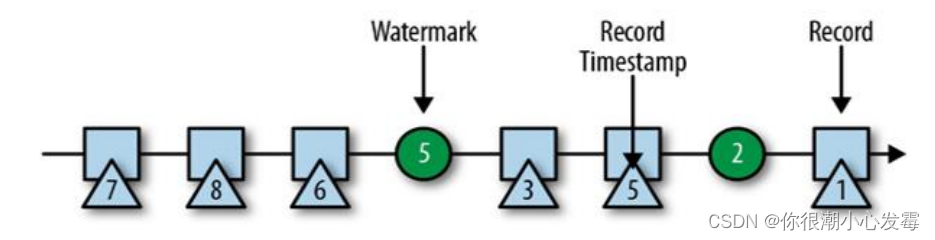
• watermark 是一条特殊的数据记录
• watermark 必须单调递增,以确保任务的事件时间时钟在向前推进,而
不是在后退
• watermark 与数据的时间戳相关
5.如何生成水位线
5.1 生成水位线的总体原则
由于网络传输的延迟不确定,为了获取所有迟到数据,只能设置延迟时间。但等待的时间越长,处理的实时性越低。因此可以单独创建一个 Flink 作业来监控事件流,建立概率分布或者机器学习模型,学习事件的迟到规律。得到分布规律之后,就可以选择置信区间来确定延迟,作为水位线的生成策略了。如,数据的迟到时间服从μ=1,σ=1 的正态分布,那么设置水位线延迟为 3 秒,就可以保证至少 97.7%的数据可以正确处理
5.2 水位线生成策略(Watermark Strategies)
在 Flink 的 DataStream API 中 , 有 一 个 单 独 用 于 生 成 水 位 线 的 方法:.assignTimestampsAndWatermarks(),它主要用来为流中的数据分配时间戳,并生成水位线来指示事件时间:
.assignTimestampsAndWatermarks()方法需要传入一个WatermarkStrategy 作为参数,这就是 所 谓 的 水 位 线 生 成 策 略 WatermarkStrategy 中 包 含 了 一 个 时 间 戳 分 配器TimestampAssigner 和一个水位线生成器WatermarkGenerator。
TimestampAssigner:主要负责从流中数据元素的某个字段中提取时间戳,并分配给元素。时间戳的分配是生成水位线的基础
WatermarkGenerator:主要负责按照既定的方式,基于时间戳生成水位线。在WatermarkGenerator 接口中,主要又有两个方法:onEvent()和 onPeriodicEmit()
5.3 Flink 内置水位线生成器
有序流:
调用WatermarkStrategy.forMonotonousTimestamps()方法就可以实现,直接拿当前最大的时间戳作为水位线

乱序流:
由于乱序流中需要等待迟到数据到齐,所以必须设置一个固定量的延迟时间(Fixed Amount of Lateness)。这时生成水位线的时间戳,就是当前数据流中最大的时间戳减去延迟的结果,相当于把表调慢,当前时钟会滞后于数据的最大时间戳。调用 WatermarkStrategy. forBoundedOutOfOrderness()方法就可以实现。这个方法需要传入一个 maxOutOfOrderness 参数,表示最大乱序程度,它表示数据流中乱序数据时间戳的最大差值

5.4自定义水位线策略
1)周期性水位线生成器(Periodic Generator)
周期性生成器一般是通过 onEvent()观察判断输入的事件,而在 onPeriodicEmit()里发出水位线
// 自定义水位线的产生
public class CustomWatermarkTest {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env =
StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
env
.addSource(new ClickSource())
.assignTimestampsAndWatermarks(new CustomWatermarkStrategy())
.print();
env.execute();
}
public static class CustomWatermarkStrategy implements WatermarkStrategy<Event> {
@Override
public TimestampAssigner<Event> createTimestampAssigner(TimestampAssignerSupplier.Context context) {
return new SerializableTimestampAssigner<Event>() {
@Override
public long extractTimestamp(Event element, long recordTimestamp) {
return element.timestamp; // 告诉程序数据源里的时间戳是哪一个字段
}
};
}
@Override
public WatermarkGenerator<Event> createWatermarkGenerator(WatermarkGeneratorSupplier.Context context) {
return new CustomPeriodicGenerator();
}
}
public static class CustomPeriodicGenerator implements WatermarkGenerator<Event> {
private Long delayTime = 5000L; // 延迟时间
private Long maxTs = Long.MIN_VALUE + delayTime + 1L; // 观察到的最大时间戳
@Override
public void onEvent(Event event, long eventTimestamp, WatermarkOutput output) {
// 每来一条数据就调用一次
maxTs = Math.max(event.timestamp, maxTs); // 更新最大时间戳
}
@Override
public void onPeriodicEmit(WatermarkOutput output) {
// 发射水位线,默认 200ms 调用一次
output.emitWatermark(new Watermark(maxTs - delayTime - 1L));
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
}
2)断点式水位线生成器(Punctuated Generator)
断点式生成器会不停地检测 onEvent()中的事件,当发现带有水位线信息的特殊事件时,就立即发出水位线。一般来说,断点式生成器不会通过 onPeriodicEmit()发出水位线
public class CustomPunctuatedGenerator implements WatermarkGenerator {
@Override
public void onEvent(Event r, long eventTimestamp, WatermarkOutput output) {
// 只有在遇到特定的 itemId 时,才发出水位线
if (r.user.equals(“Mary”)) {
output.emitWatermark(new Watermark(r.timestamp - 1));
}
}
@Override
public void onPeriodicEmit(WatermarkOutput output) {
// 不需要做任何事情,因为我们在 onEvent 方法中发射了水位线
}
}
- 1
- 2
- 3
- 4
- 5
6.watermark 的传递
上游任务处理完水位线、时钟改变之后,要把当前的水位线再次发出,广播给所有的下游子任务。这样,后续任务就不需要依赖原始数据中的时间戳(经过转化处理后,数据可能已经改变了),也可以知道当前事件时间。
在重分区(redistributing)的传输模式下:
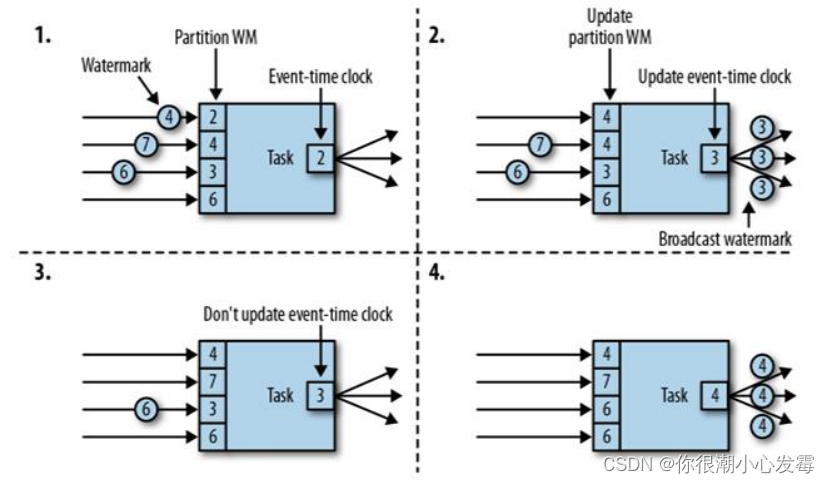
当前任务的上游,有四个并行子任务,所以会接收到来自四个分区的水位线;而下游有三个并行子任务,所以会向三个分区发出水位线。
具体过程如下:
(1)上游并行子任务发来不同的水位线,当前任务会为每一个分区设置一个分区水位线(Partition Watermark),这是一个分区时钟;而当前任务的时钟,就是所有分区时钟里最小的那个
(2)当有一个新的水位线(第一分区的 4)从上游传来时,当前任务会首先更新对应的分区时钟;然后再判断所有分区时钟中的最小值,如果比之前大,说明事件时间有了进展,当前任务的时钟也就可以更新了。这里要注意,更新后的任务时钟,并不一定是新来的那个分区水位线,比如这里改变的是第一分区的时钟,但最小的分区时钟是第三分区的 3,于是当前任务时钟就推进到了 3。当时钟有进展时,当前任务就会将自己的时钟以水位线的形式,广播给下游所有子任务
(3)再次收到新的水位线(第二分区的 7)后,执行同样的处理流程。首先将第二个分区时钟更新为 7,然后比较所有分区时钟;发现最小值没有变化,那么当前任务的时钟也不变,也不会向下游任务发出水位线。
(4)同样道理,当又一次收到新的水位线(第三分区的 6)之后,第三个分区时钟更新为6,同时所有分区时钟最小值变成了第一分区的 4,所以当前任务的时钟推进到 4,并发出时间戳为 4 的水位线,广播到下游各个分区任务。
五、Flink 状态管理
1.Flink 中的状态
• 由一个任务维护,并且用来计算某个结果的所有数据,都属于这个任务的状
态
• 可以认为状态就是一个本地变量,可以被任务的业务逻辑访问
• Flink 会进行状态管理,包括状态一致性、故障处理以及高效存储和访问,以
便开发人员可以专注于应用程序的逻辑
• 在 Flink 中,状态始终与特定算子相关联
• 为了使运行时的 Flink 了解算子的状态,算子需要预先注册其状态
➢ 总的说来,有两种类型的状态:
• 算子状态(Operator State):算子状态的作用范围限定为算子任务
• 键控状态(Keyed State):根据输入数据流中定义的键(key)来维护和访问
2.算子状态(Operatior State)
2.1 算子状态(Operator State)
• 算子状态的作用范围限定为算子任务,由同一并行任务所处理的所有数据都
可以访问到相同的状态
• 状态对于同一子任务而言是共享的
• 算子状态不能由相同或不同算子的另一个子任务访问
2.2 算子状态数据结构
➢ 列表状态(List state)
• 将状态表示为一组数据的列表
➢ 联合列表状态(Union list state)
• 也将状态表示为数据的列表。它与常规列表状态的区别在于,在发生故
障时,或者从保存点(savepoint)启动应用程序时如何恢复
➢ 广播状态(Broadcast state)
• 如果一个算子有多项任务,而它的每项任务状态又都相同,那么这种特
殊情况最适合应用广播状态。
3.键控状态(Keyed State)
3.1键控状态
• 键控状态是根据输入数据流中定义的键(key)来维护和访问的
• Flink 为每个 key 维护一个状态实例,并将具有相同键的所有数据,都分区到
同一个算子任务中,这个任务会维护和处理这个 key 对应的状态
• 当任务处理一条数据时,它会自动将状态的访问范围限定为当前数据的 key
3.2键控状态数据结构
➢ 值状态(Value state)
• 将状态表示为单个的值
➢ 列表状态(List state)
• 将状态表示为一组数据的列表
➢ 映射状态(Map state)
• 将状态表示为一组 Key-Value 对
➢ 聚合状态(Reducing state & Aggregating State)
• 将状态表示为一个用于聚合操作的列表
3.3键控状态的使用

4.状态后端(State Backends)
4.1状态后端
• 每传入一条数据,有状态的算子任务都会读取和更新状态
• 由于有效的状态访问对于处理数据的低延迟至关重要,因此每个并行任务都会在本地维护其状态,以确保快速的状态访问
• 状态的存储、访问以及维护,由一个可插入的组件决定,这个组件就叫做状态后端(state backend)
• 状态后端主要负责两件事:本地的状态管理,以及将检查点(checkpoint)状态写入远程存储
4.2选择一个状态后端
➢ MemoryStateBackend
• 内存级的状态后端,会将键控状态作为内存中的对象进行管理,将它们存储在
TaskManager 的 JVM 堆上,而将 checkpoint 存储在 JobManager 的内存中
• 特点:快速、低延迟,但不稳定
➢ FsStateBackend
• 将 checkpoint 存到远程的持久化文件系统(FileSystem)上,而对于本地状态,跟 MemoryStateBackend 一样,也会存在 TaskManager 的 JVM 堆上
• 同时拥有内存级的本地访问速度,和更好的容错保证
➢ RocksDBStateBackend
• 将所有状态序列化后,存入本地的 RocksDB 中存储。
六、Flink 的容错机制
1.一致性检查点(checkpoint)
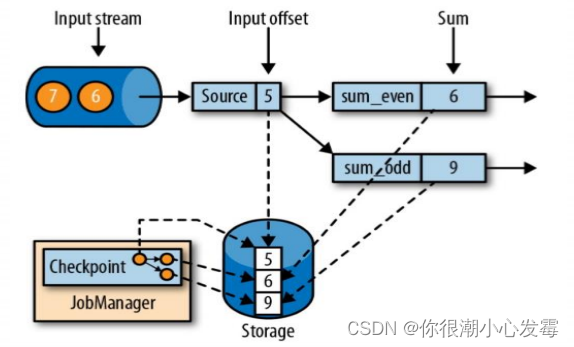
• Flink 故障恢复机制的核心,就是应用状态的一致性检查点
• 有状态流应用的一致检查点,其实就是所有任务的状态,在某个时间点的一份拷贝(一份快照);这个时间点,应该是所有任务都恰好处理完一个相同的输入数据的时候
2.从检查点恢复状态
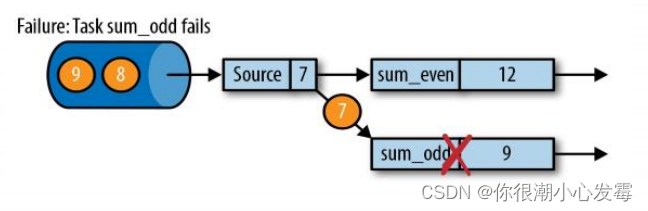
• 在执行流应用程序期间,Flink 会定期保存状态的一致检查点
• 如果发生故障, Flink 将会使用最近的检查点来一致恢复应用程序的状态,并重新启动处理流程
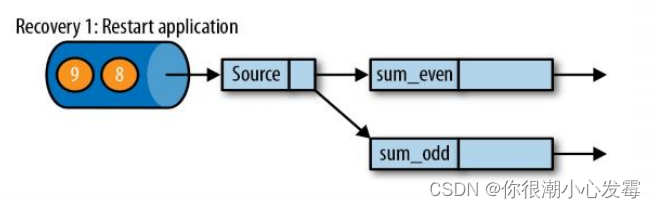
• 遇到故障之后,第一步就是重启应用
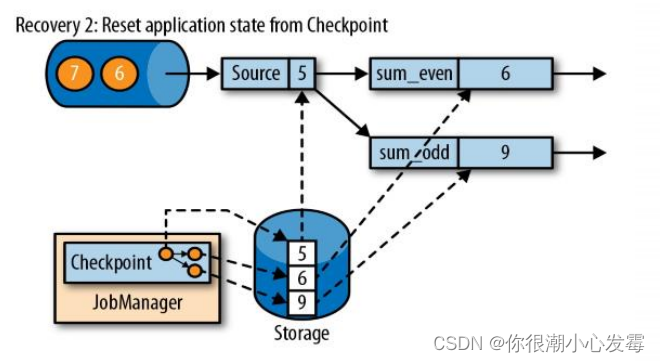
• 第二步是从 checkpoint 中读取状态,将状态重置
• 从检查点重新启动应用程序后,其内部状态与检查点完成时的状态完全相同
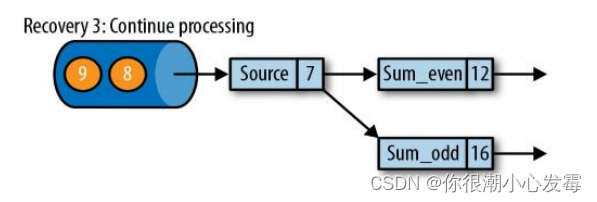
• 第三步:开始消费并处理检查点到发生故障之间的所有数据
• 这种检查点的保存和恢复机制可以为应用程序状态提供“精确一次”
(exactly-once)的一致性,因为所有算子都会保存检查点并恢复其所有状态,这样一来所有的输入流就都会被重置到检查点完成时的位置
3.Flink 检查点算法
检查点的实现算法:
• 一种简单的想法
—— 暂停应用,保存状态到检查点,再重新恢复应用
• Flink 的改进实现
—— 基于 Chandy-Lamport 算法的分布式快照
—— 将检查点的保存和数据处理分离开,不暂停整个应用
Flink 检查点算法:
➢ 检查点分界线(Checkpoint Barrier)
• Flink 的检查点算法用到了一种称为分界线(barrier)的特殊数据形式,
用来把一条流上数据按照不同的检查点分开
• 分界线之前到来的数据导致的状态更改,都会被包含在当前分界线所属
的检查点中;而基于分界线之后的数据导致的所有更改,就会被包含在
之后的检查点中
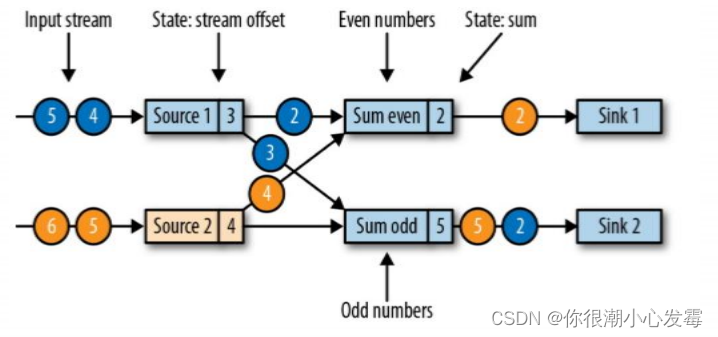
• 现在是一个有两个输入流的应用程序,用并行的两个 Source 任务来读取
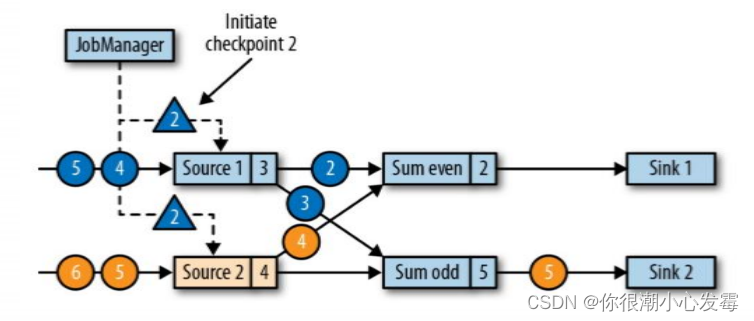
• JobManager 会向每个 source 任务发送一条带有新检查点 ID 的消息,通过这种方式来启动检查点
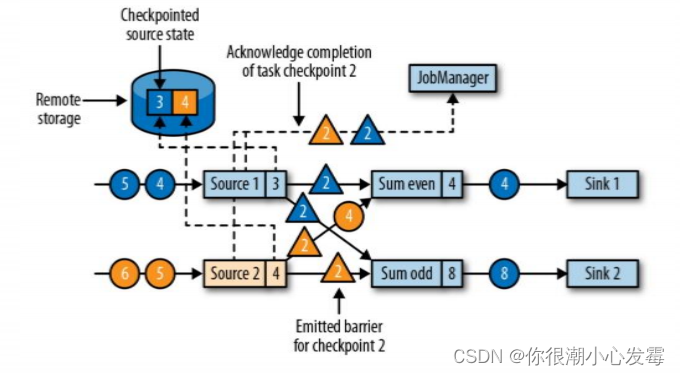
• 数据源将它们的状态写入检查点,并发出一个检查点 barrier
• 状态后端在状态存入检查点之后,会返回通知给 source 任务,source 任务就会向 JobManager 确认检查点完成
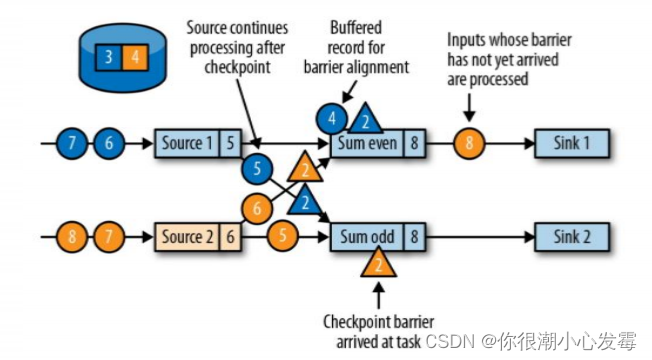
• 分界线对齐:barrier 向下游传递,sum 任务会等待所有输入分区的 barrier 到达
• 对于barrier已经到达的分区,继续到达的数据会被缓存
• 而barrier尚未到达的分区,数据会被正常处理
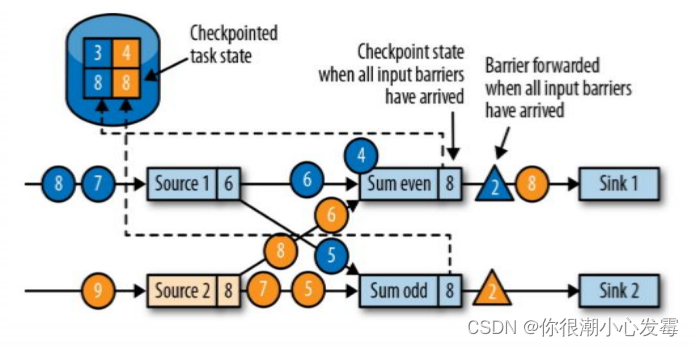
• 当收到所有输入分区的 barrier 时,任务就将其状态保存到状态后端的检查点中,然后将 barrier 继续向下游转发
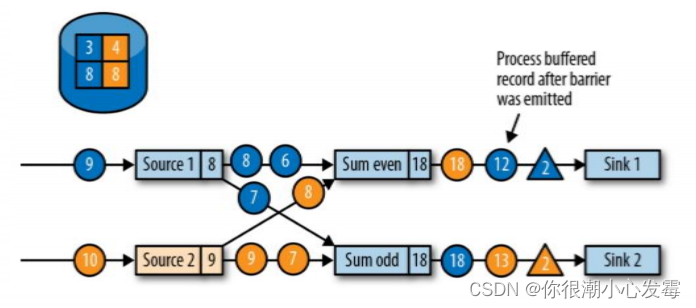
• 向下游转发检查点 barrier 后,任务继续正常的数据处理
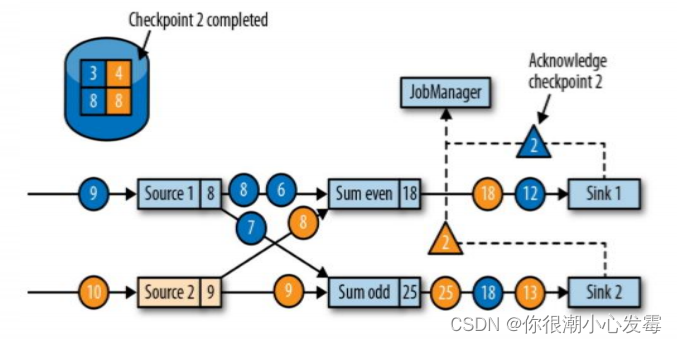
• Sink 任务向 JobManager 确认状态保存到 checkpoint 完毕
• 当所有任务都确认已成功将状态保存到检查点时,检查点就真正完成了
4.保存点(save points)
• Flink 还提供了可以自定义的镜像保存功能,就是保存点(savepoints)
• 原则上,创建保存点使用的算法与检查点完全相同,因此保存点可以认
为就是具有一些额外元数据的检查点
• Flink不会自动创建保存点,因此用户(或者外部调度程序)必须明确地
触发创建操作
• 保存点是一个强大的功能。除了故障恢复外,保存点可以用于:有计划
的手动备份,更新应用程序,版本迁移,暂停和重启应用,等等。
七、Flink 的状态一致性
1.状态一致性
1.1什么是状态一致性
• 有状态的流处理,内部每个算子任务都可以有自己的状态
• 对于流处理器内部来说,所谓的状态一致性,其实就是我们所说的计
算结果要保证准确。
• 一条数据不应该丢失,也不应该重复计算
• 在遇到故障时可以恢复状态,恢复以后的重新计算,结果应该也是完
全正确的。
1.2状态一致性分类
• AT-MOST-ONCE(最多一次)
➢ 当任务故障时,最简单的做法是什么都不干,既不恢复丢失的状态,也不重播丢失的数据。At-most-once 语义的含义是最多处理一次事件。
• AT-LEAST-ONCE(至少一次)
➢ 在大多数的真实应用场景,我们希望不丢失事件。这种类型的保障称为 atleast-once,意思是所有的事件都得到了处理,而一些事件还可能被处理多次。
• EXACTLY-ONCE(精确一次)
➢ 恰好处理一次是最严格的保证,也是最难实现的。恰好处理一次语义不仅仅意味着没有事件丢失,还意味着针对每一个数据,内部状态仅仅更新一次。
2.一致性检查点(checkpoint)
• Flink 使用了一种轻量级快照机制 —— 检查点(checkpoint)来保
证 exactly-once 语义
• 有状态流应用的一致检查点,其实就是:所有任务的状态,在某个时
间点的一份拷贝(一份快照)。而这个时间点,应该是所有任务都恰
好处理完一个相同的输入数据的时候。
• 应用状态的一致检查点,是 Flink 故障恢复机制的核心
3.端到端(end-to-end)状态一致性
• 目前我们看到的一致性保证都是由流处理器实现的,也就是说都是在Flink 流处理器内部保证的;而在真实应用中,流处理应用除了流处理器以外还包含了数据源(例如 Kafka)和输出到持久化系统
• 端到端的一致性保证,意味着结果的正确性贯穿了整个流处理应用的始终;每一个组件都保证了它自己的一致性
• 整个端到端的一致性级别取决于所有组件中一致性最弱的组件
4.端到端的精确一次(exactly-once)保证
• 内部保证 —— checkpoint
• source 端 —— 可重设数据的读取位置
• sink 端 —— 从故障恢复时,数据不会重复写入外部系统
➢ 幂等写入
➢ 事务写入
4.1幂等写入
• 所谓幂等操作,是说一个操作,可以重复执行很多次,但只导致一次
结果更改,也就是说,后面再重复执行就不起作用了
4.2事务写入
• 事务(Transaction)
➢ 应用程序中一系列严密的操作,所有操作必须成功完成,否则在每个操作中所作的所有更改都会被撤消
➢ 具有原子性:一个事务中的一系列的操作要么全部成功,要么一个都做
• 实现思想:构建的事务对应着 checkpoint,等到 checkpoint 真正完成的时候,才把所有对应的结果写入 sink 系统中
• 实现方式
➢ 预写日志
➢ 两阶段提交
预写日志(Write-Ahead-Log,WAL):
• 把结果数据先当成状态保存,然后在收到 checkpoint 完成的通知时,一次性写入 sink 系统
• 简单易于实现,由于数据提前在状态后端中做了缓存,所以无论什么sink 系统,都能用这种方式一批搞定
• DataStream API 提供了一个模板类:GenericWriteAheadSink,来实现这种事务性 sink
5.Flink+Kafka 端到端状态一致性的保证
八、Kafka
8.1、kafka介绍
kafka是最初由linkedin公司开发的,使用scala语言编写,kafka是一个分布式,分区的,多副本的,多订阅者的消息队列系统。
8.2、kafka相比其他消息队列的优势
常见的消息队列:RabbitMQ,Redis ,zeroMQ ,ActiveMQ
kafka的优势:
- 可靠性:分布式的,分区,复制和容错的。
- 可扩展性:kafka消息传递系统轻松缩放,无需停机。
- 耐用性:kafka使用分布式提交日志,这意味着消息会尽可能快速的保存在磁盘上,因此它是持久的。
- 性能:kafka对于发布和定于消息都具有高吞吐量。即使存储了许多TB的消息,他也爆出稳定的性能。
- kafka非常快:保证零停机和零数据丢失。
8.3、kafka的术语
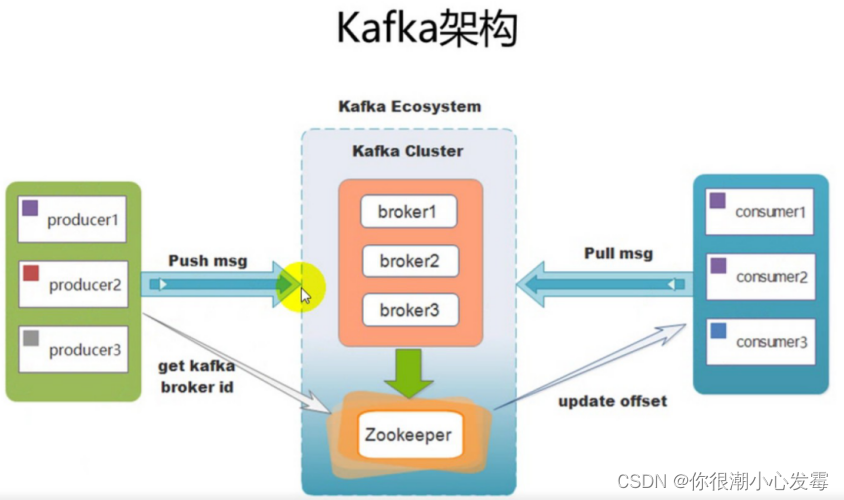
8.3.1、kafka中的术语名词
Broker:kafka集群中包含一个或者多个服务实例,这种服务实例被称为Broker
Topic:每条发布到kafka集群的消息都有一个类别,这个类别就叫做Topic
Partition:Partition是一个物理上的概念,每个Topic包含一个或者多个Partition
Producer:负责发布消息到kafka的Broker中。
Consumer:消息消费者,向kafka的broker中读取消息的客户端
Consumer Group:每一个Consumer属于一个特定的Consumer Group(可以为每个Consumer指定 groupName)
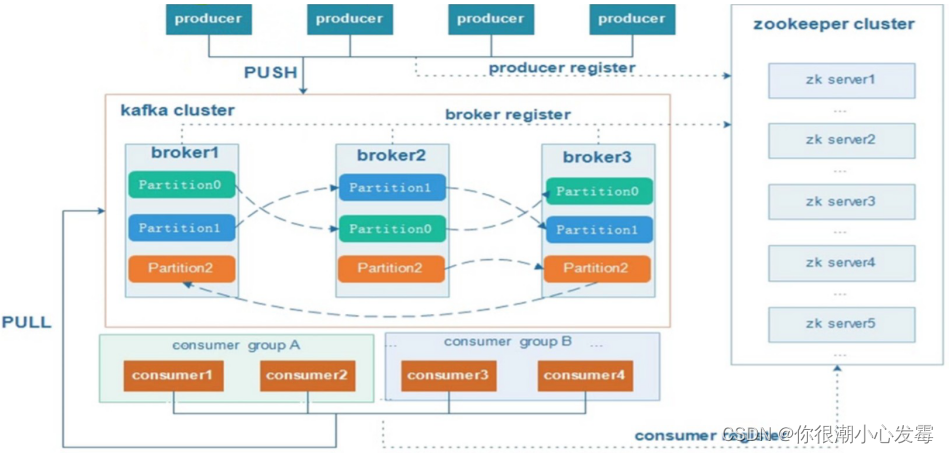
8.4、kafka的架构
8.5、kafka能做到消费的有序性吗
- 一个主题(topic)下面有一个分区(partition)即可
8.5.1、为什么topic下多个分区不能保证有序
- 生产者生产数据到borker的多个分区,每个分区的数据是相对有序的,但整体的数据就无序了。因为消费者在消费的时候是一个个的分区进行消费的,所以不能保证全局有序。
8.6、分区与消费者组间的关系
- 消费组: 由一个或者多个消费者组成,同一个组中的消费者对于同一条消息只消费一次。
- 某一个主题下的分区数,对于消费组来说,应该小于等于该主题下的分区数。
8.7、生产者分区策略
- 没有指定分区号、没指定key根据轮询的方式发送到不同的分区
- 没有指定分区号、指定了key,根据key.hashcode%numPartition
- 指定了分区号,则直接将数据写到指定的分区里面去
- 自定义分区策略
//可根据主题和内容发送
public ProducerRecord(String topic, V value)
//根据主题,key、内容发送
public ProducerRecord(String topic, K key, V value)
//根据主题、分区、key、内容发送
public ProducerRecord(String topic, Integer partition, K key, V value)
//根据主题、分区、时间戳、key,内容发送
public ProducerRecord(String topic, Integer partition, Long timestamp, K key, V value)
如果没有指定分区号,也没有指定具体的key(轮询)
如果没有指定分区号,指定了具体的key(hash)
前缀+date.getTime() fixlog_1564388581914
如果指定了具体的分区号,(按照分区号)
自定义分区
### 8.8、数据丢失
#### 8.8.1、生产者保证数据不丢失
1. **同步模式**:配置=1 (只有Leader收到,-1 所有副本成功,0 不等待)Leader Partition挂了,数据就会丢失
解决:设置 -1 保证produce 写入所有副本算成功 producer.type = sync request.required.acks=-1
2. **异步模式**,当缓冲区满了,如果配置为0(没有收到确认,一满就丢弃),数据立刻丢弃
解决:不限制阻塞超时时间。就是一满生产者就阻
#### **8.8.2、broker保证数据不丢失**
broker采用分片副本机制,保证数据高可用。
#### 8.8.3、customer保证数据不丢失
- 拿到数据后,存储到hbase中或者mysql中,如果hbase或者mysql在这个时候连接不上,就会抛出异常,如果在处理数据的时候已经进行了提交,那么kafka上的offset值已经进行了修改了,但是hbase或者mysql中没有数据,这个时候就会出现**数据丢失**。 主要是因为offset提交使用了异步提交。
- 解决方案
- Consumer将数据处理完成之后,再来进行offset的修改提交。默认情况下offset是 自动提交,需要修改为手动提交offset值。
- 流式计算。高级数据源以kafka为例,由2种方式:receiver (开启WAL,失败可恢复) director (checkpoint保证)
### 8.9、数据重复
* 落表(主键或者唯一索引的方式,避免重复数据)
业务逻辑处理(选择唯一主键存储到Redis或者mongdb中,先查询是否存在,若存在则不处理;若不存在,先插入Redis或Mongdb,再进行业务逻辑处理)
### 8.10、kafka当中数据的查找过程
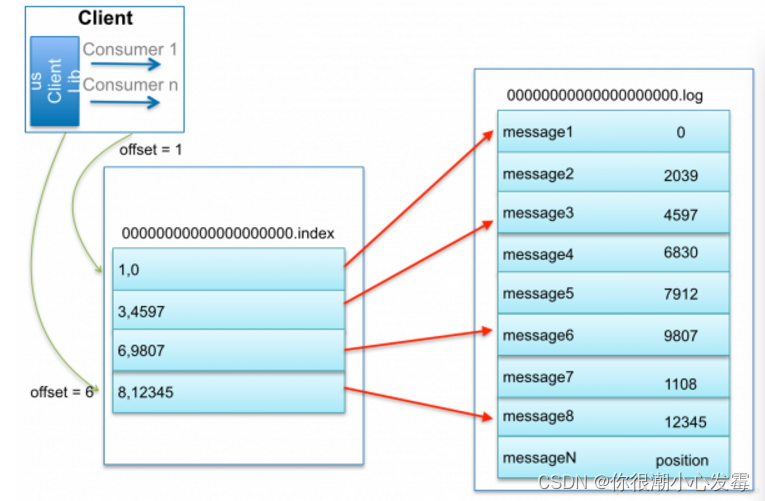
**第一步**:通过offset确定数据保存在哪一个segment里面了,
**第二步**:查找对应的segment里面的index文件 。index文件都是key/value对的。key表示数据在log文件里面的顺序是第几条。value记录了这一条数据在全局的标号。如果能够直接找到对应的offset直接去获取对应的数据即可
如果index文件里面没有存储offset,就会查找offset最近的那一个offset,例如查找offset为7的数据找不到,那么就会去查找offset为6对应的数据,找到之后,再取下一条数据就是offset为7的数据
### 8.11、Kafka auto.offset.reset值详解
**earliest**
* 当各分区下有已提交的offset时,从提交的offset开始消费;无提交的offset时,从头开始消费
**latest**
* 当各分区下有已提交的offset时,从提交的offset开始消费;无提交的offset时,消费新产生的该分区下的数据
**none**
* topic各分区都存在已提交的offset时,从offset后开始消费;只要有一个分区不存在已提交的offset,则抛出异常
**latest 这个设置容易丢失消息**,假如kafka出现问题,还有数据往topic中写,这个时候重启kafka,这个设置会从最新的offset开始消费,中间出问题的哪些就不管了。
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64

