
- 1Java开发专家阿里P6-P7面试题大全及答案汇总(持续更新)_java专家面试题
- 2elasticsearch之嵌套对象、父子文档_es嵌套对象
- 3人工智能机器人电销,AI语音机器人系统_ai电销机器人系统
- 4自学Java怎么找工作?好程序员学员大厂面试经验分享!_2023java怎么找工作
- 5解决:Property ‘sqlSessionFactory‘ or ‘sqlSessionTemplate‘ are required_property 'sqlsessionfactory' or 'sqlsessiontemplat
- 6使用Springboot + Tesseract OCR引擎实现图片文字自动识别_springboot整合tesseract
- 7操作系统书籍推荐_osek操作系统学习有哪些推荐书籍
- 8链表中环的入口节点_环形链表入口
- 9uni-app - 在uniapp中使用echarts展示图表_uniapp echarts
- 10golang框架
AI模型:开源大语言模型bloom学习
赞
踩
前言
chatgpt已经成为了当下热门,github首页的trending排行榜上天天都有它的相关项目,但背后隐藏的却是openai公司提供的api收费服务。作为一名开源爱好者,我非常不喜欢知识付费或者服务收费的理念,所以便有决心写下此系列,让一般大众们可以不付费的玩转当下比较新的开源大语言模型bloom及其问答系列模型bloomz。
一、模型介绍

bloom是一个开源的支持最多59种语言和176B参数的大语言模型。它是在Megatron-LM GPT2的基础上修改训练出来的,主要使用了解码器唯一结构,对词嵌入层的归一化,使用GeLU激活函数的线性偏差注意力位置编码等技术。它的训练集包含了45种自然语言和12种编程语言,1.5TB的预处理文本转化为了350B的唯一token。bigscience在hugging face上发布的bloom模型包含多个参数多个版本,本文中出于让大家都能动手实践的考虑,选择最小号的bloom-1b1版本,其他模型请自行尝试。
二、环境准备
python版本最好是3.8及以上,因为项目都会逐渐对老版本python停止支持,可能找不到现成的wheel包从而需要自己编译,而windows下需要使用VS,那是个相当痛苦的过程。
推荐pip原生虚拟环境安装,不推荐conda虚拟环境。本文的安装方法都是基于pip,如果你不懂pip虚拟环境请运行以下命令(linux如果有python2,请运行pip3):
pip install virtualenv -i https://mirror.baidu.com/pypi/simple #安装虚拟环境包
python -m venv bloom #在当前目录创建名叫bloom的虚拟环境
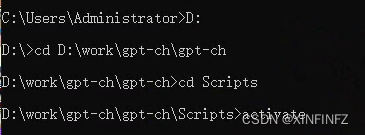
创建完后如何启动:先一路cd到根目录,即脚本文件夹所在目录,然后cd进去activate。
cd Scripts
activate
比如我这里是名叫gpt-ch的环境:
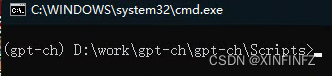
输完后这样就表示启动成功了,所有的命令都会在隔离环境里运行,安装的包也都会在gpt-ch/Lib/site-packages里:
三、安装pip包
如果只用cpu进行推理,只需要安装以下包:
pip install torch torchvision torchaudio --extra-index-url https://download.pytorch.org/whl/cpu
pip install transformers -i https://mirror.baidu.com/pypi/simple
如果你想用英伟达gpu进行推理,请自行安装gpu版的torch。这里提供wheel下载链接:
记得torch和torchvision的版本是需要对应的,然后这里默认你已经安装配置好了cuda路径,如果没有请看我之前的文章或者去网上查。
以我这里的cu117版本为例。

运行以下命令:
pip install torch-1.13.0+cu117-cp39-cp39-win_amd64.whl #自行更改文件名
pip install torchvision-0.14.0+cu117-cp39-cp39-win_amd64.whl #自行更改文件名
pip install transformers -i https://mirror.baidu.com/pypi/simple
pip install accelerate -i https://mirror.baidu.com/pypi/simple
四、模型下载
首先请编写以下代码保存运行:
from transformers import AutoModelForCausalLM, AutoTokenizer
checkpoint = "bigscience/bloom-1b1" #1b1,可改名成你想要的更大的模型
tokenizer = AutoTokenizer.from_pretrained(checkpoint) #下载模型的tokenizer
model = AutoModelForCausalLM.from_pretrained(checkpoint) #下载模型
网速足够快的情况下等一会就下载好了,但通常情况下我们得ctrl+c打断代码运行,手动下载模型存放到对应位置,即.cache\huggingface\hub\models–bigscience–bloom-1b1下。
如果你是windows,那么这个cache文件夹默认会创建在C:\Users\Administrator\下。如果你是linux,你使用了root权限,会在root文件夹下创建,如果是普通用户权限,则会在对应名称的普通用户目录下,此外该文件夹在linux中默认为隐藏文件夹,需打开权限查看。
下载模型地址: https://huggingface.co/bigscience/bloom-1b1/tree/main
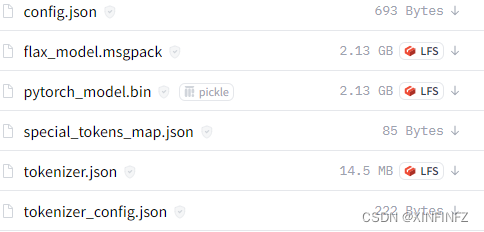
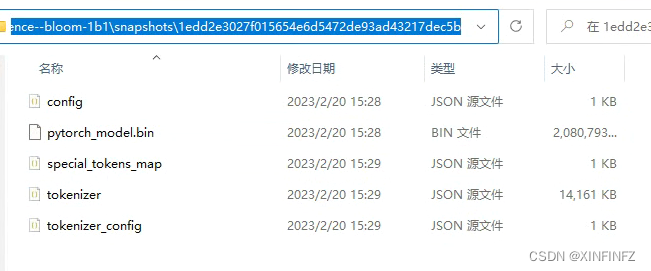
把如上图所示链接中的五个文件(不包含这个flax_model.msgpack)下载下来放进自己的本地目录下的snapshots\一串数字(如下图所示)即可,其他文件夹都不用管。
五、生成文本
万事准备就绪后,就可以开始愉快的游玩了,运行以下代码:
from transformers import AutoModelForCausalLM, AutoTokenizer
import time
a1 = time.time()
checkpoint = "bigscience/bloom-1b1"
tokenizer = AutoTokenizer.from_pretrained(checkpoint)
model = AutoModelForCausalLM.from_pretrained(checkpoint)
inputs = tokenizer.encode("奋进在不可逆转的复兴进程上", return_tensors="pt") #prompt
outputs = model.generate(inputs,min_length=150,max_new_tokens=200,do_sample=True)
print(tokenizer.decode(outputs[0])) #使用tokenizer对生成结果进行解码
a2 = time.time()
print(f'time cost is {a2 - a1} s')
time模块用来计时,我的是十二代i7,花了40s生成。
这里有一些生成时的参数需要讲解一下:
min_length是指最小生成长度,等于你输入的提示词+最小生成的token数,也就是input_length+min_new_tokens。
max_new_tokens规定了最大生成的token数目,这里的token你可以理解为一个词,不好翻译所以一律token,忽略你输入的prompt。与之相关的是max_length参数,其实max_length就是max_new_tokens+你输入的prompt长度。
do_sample=True表示进行抽样,否则会使用贪心解码策略。
生成以下结果:

其他
参考:https://blog.csdn.net/weixin_43945848/article/details/129375410

