
- 1Hadoop3:HDFS副本节点选择逻辑讲解
- 2漏洞扫描器 - cmd命令行执行
- 3发榜啦!Baidu Comate 智能编码助手获奖名单公布
- 4Unity 旧版本下载地址_unity老版本下载
- 5Unity跨平台UI解决方案:可能是最全的FairyGUI系列教程_fairygui教程
- 6python post cookies_Python3 Post登录并且保存cookie登录其他页面的方法
- 7解决VS Code的高cpu占用率问题_vscode太吃内存解决办法
- 8新版Unity编译效率提高,关闭脚本自动重新编译。_unity怎么取消每次代码自动编译
- 9OpenAI新一轮股权大瓜,Sam Altman长文回应
- 10springboot实现邮箱验证码功能_springboot邮箱验证码
经典排序算法之快速排序详解_快速排序 45,10,21,60
赞
踩
写在前面:大家好!我是
ACfun,我的昵称来自两个单词Accepted和fun。我是一个热爱ACM的蒟蒻。这篇博客来记录一下快速排序算法以及快速排序的模板。如果博客中有不足或者的错误的地方欢迎在评论区或者私信我指正,感谢大家的不吝赐教。我的唯一博客更新地址是:https://ac-fun.blog.csdn.net/。非常感谢大家的支持。一起加油,冲鸭!
用知识改变命运,用知识成就未来!加油 (ง •̀o•́)ง (ง •̀o•́)ง
快速排序简介
快速排序是对冒泡排序的一种改进。冒泡排序的时间复杂度为O(N²),这是一个非常高的时间复杂度。冒泡排序早在 1956 年就有人开始研究,之后有很多人都尝试过对冒泡排序进行改进,但结果却令人失望。如 Donald E. Knuth(中文名为高德纳,1974 年图灵奖获得者)所说:“冒泡排序除了它迷人的名字和导致了某些有趣的理论问题这一事实之外,似乎没有什么值得推荐的。”
快速排序动画演示:
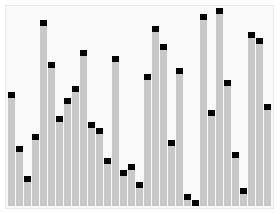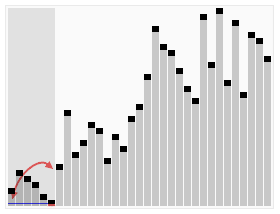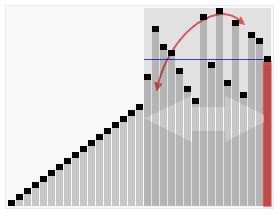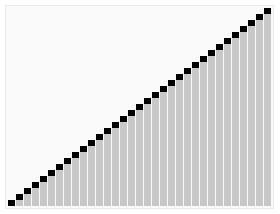
快速排序的思想
快速排序的基本思想是:通过一趟排序将待排记录分割成独立的两部分,其中一部分关键字都比另一部分记录的关键字小,然后再分别对这两部分关键字进行相同步骤的排序,直到整个序列有序。
快速排序的具体实现
一趟快速排序的具体做法是:附设两个变量low和high,分别指向第一个数据和最后一个数据。首先从low所指的位置向后找到第一个关键字大于监视哨的值,然后high开始向前移动直到找到第一个小于监视哨的值,然后将两个数据位置交换。现在我们将下面这一串数据进行快速排序:
6 1 2 7 5 3 4 9 10 8
1.将数字 5 设置为监视哨[ (low + high) / 2 ],然后开始第一轮的快速排序。
2.首先从low就是数据的最左端寻找到第一个比 5 大的值 6 ,然后从high就是最右端寻找到第一个比 5 小的数字4。然后将这两个数字交换位置:
41 2 7 5 3 6 9 10 8。
3.然后low继续向后移动直到找到第二个比 5 大的数据 7 ,high继续向前移动找到第二个比 5 小的数字 3,然后将两者位置交换:
4 1 2 3 5 7 6 9 10 8。
此时我们发现 5 左边的数据全部比 5 小,右边的数据全部比 5 大。即将数据以 5 为界将数据分为了两个部分。然后我们分别对这两部分分别执行相同的操作。此时左边的数据为“4 1 2 3 5”,右边的数据为“7 6 9 10 8”。然后分别使用递归处理这两个部分。依次进行上述操作直到整个序列变得有序。
在写快速排序的时候需要注意几个地方,首先建议基准点每次都选中间的值,因为数据量大而且数据严格递增时,如果取端点的值作为基准点,递归深度会由
l
o
g
n
log{n}
logn 变成
n
n
n ,时间复杂度变成了
n
2
n^2
n2。会TLE。还有就是 边界问题,快速排序非常容易出现边界问题,为了避免因边界问题而导致各种出错,建议背一个自己觉得容易理解的模板,在理解快排思路的基础上每次写快排的时候只要写上自己记的模板即可。
快排边界问题处理不好很容易出现 TLE、数组越界 等问题。如果在写快排代码时出现错误,建议手动模拟一下自己出错的测试样例,这样就可以快速找到问题所在。
时间复杂度
快速排序之所以比较快,是因为相比冒泡排序,每次交换是跳跃式的。每次排序的时候设置一个 基准点,将小于等于基准点的数全部放到基准点的左边,将大于等于基准点的数全部放到基准点的右边。这样在每次交换的时候就不会像冒泡排序一样只能在相邻的数之间进行交换,交换的距离就大得多了。因此总的比较和交换次数就少了,速度自然就提高了。
当然在最坏的情况下,仍可能是相邻的两个数进行了交换,因此在最坏情况下快速排序的时间复杂度和冒泡排序是一样的,都是 O(n2)。快排的平均时间复杂度为 O( n l o g n nlog{n} nlogn)。一般情况下快速排序已经是时间复杂度最优的基于比较的排序算法。
快速排序模板
void quick_sort(int q[],int l,int r){
if(l >= r) return;
int x = q[(l + r) >> 1], i = l - 1, j = r + 1;
while (i < j){
do i++; while (q[i] < x);
do j--; while (q[j] > x);
if (i < j) swap(q[i], q[j]);
}
quick_sort(q, l, j);
quick_sort(q, j + 1, r);
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
例题
题目信息
原题链接:快速排序
题目描述
给定你一个长度为n的整数数列。请你使用快速排序对这个数列按照从小到大进行排序。并将排好序的数列按顺序输出。
输入格式
输入共两行,第一行包含整数 n。
第二行包含 n 个整数(所有整数均在1~109范围内),表示整个数列。
输出格式
输出共一行,包含 n 个整数,表示排好序的数列。
数据范围
1≤n≤100000
输入样例
5
3 1 2 4 5
输出样例
1 2 3 4 5
解题代码
#include<iostream>
#include<algorithm>
#include<cstdio>
using namespace std;
const int N = 1e6 + 10;
int q[N], n;
void quick_sort(int l, int r) {
if (l >= r) return;
int x = q[(l + r) >> 1], i = l - 1, j = r + 1;
/* x 最好是取中间位置值,因为数据量大而且数据严格递增时,如果取左端点
递归深度由logn 变成 n 了,时间复杂度变成了 n^2。会TLE
*/
while (i < j) {
do i++; while (q[i] < x);
do j--; while (q[j] > x);
if (i < j) swap(q[i], q[j]);
}
// 为了解决边界问题,递归函数写 j, x 取中间值。写其他很容易出现边界问题
quick_sort(l, j);
quick_sort(j + 1, r);
}
int main() {
scanf("%d", &n);
for (int i = 0; i < n; i++) scanf("%d", &q[i]);
quick_sort(0, n - 1);
for (int i = 0; i < n; i++) printf("%d ", q[i]);
return 0;
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
注意:这里没有使用 cin>> 和 cout<< 的原因是其输入输出速度不如 scanf() 和 printf() 快,所以在这里使用的是 scanf() 和 prinf() 。
我是ACfun,感谢大家的支持!


