
- 1服务器被攻击怎么防DDOS_有效防止服务器被ddos
- 2C++ 11 左值,右值,左值引用,右值引用(emplace用法关键),std::move, std::foward_emplace(std::move
- 3NLTK语料库下载
- 4Python系列:NLP系列三:pyltp的介绍与使用_pyltp官网
- 5达梦 DM管理工具_达梦管理工具
- 6numpy中的argsort()_np.argsort(fitness)
- 7Stanford CS 144 Note 24 - Principle rate guarantees_cs144note
- 8【FPGA】基于FPGA的极简CPU设计_fpga大作业
- 9conda命令-安装opencv_conda 安装opencv清华源
- 10CHIP-2020 中文医学文本实体关系抽取_chip2020
Megatron-LM训练GPT2模型_megatron llama
赞
踩
基于Megatron-LM从0到1完成GPT2模型预训练、模型评估及推理 - 知乎 (zhihu.com)
1、配置环境(太遭罪了)
先讲结论,踩坑太漫长了:
GPU:tesla P100
cuda11.8(可换其他,低点好)
pytorch2.1.0(可换其他2.1还是有点小坑)
Megatron-LM(tag2.5),最新的transformer_engine用不了,对GPU框架有要求
pytorch镜像选好版本(别用太高,gpu不行,多踩了很多坑),有apex的就行
首先进入到Megatron-LM目录,安装一下依赖,pip install -r requirements.txt
不需要tensorflow
pytorch和cuda要匹配
安装apex遇到的各种问题:
1、cuda和torch版本不匹配
原来时cuda11.4,torch版本1.12+cu113(torch没有114就离谱)
修改setup.py文件,删除验证匹配的地方即可
或者重下cuda和torch
我都做了但我卡住的地方不是这个原因

2、编译不了c++文件!为什么!(放弃了,没解决)
from /root/yjy/Megatron-LM/apex/csrc/flatten_unflatten.cpp:1:
/usr/include/c++/9/cwchar:44:10: fatal error: wchar.h: No such file or directory
gpt让我下载
- sudo apt-get update
- sudo apt-get install libc6-dev
但是又报错,这个linux-headers-5.4.0-165我不敢乱删

放弃了,转而使用镜像!
使用镜像配置环境:(又是曲折的换版本)
PyTorch Release 21.05 - NVIDIA Docs
下载镜像 ,选好版本(别用太高,不适配,多踩了很多坑),有apex的就行

- docker run -dt --name pytorch_yjy --restart=always --gpus all \
- --network=host \
- --shm-size 8G \
- -v /mnt/VMSTORE/yjy/Megatron-LM-GPT:/Megatron-LM-GPT \
- -w /Megatron-LM-GPT \
- nvcr.io/nvidia/pytorch:23.04-py3 \
- /bin/bash
docker exec -it pytorch_yjy bash缺少amp_C
在这里安装apex成功了,但是模型训练使用的时候又报错了!!!缺少amp_C!!!
解决办法一:(别用,后面还会报错)
用这个版本的apex成功了
NVIDIA/apex at 3303b3e7174383312a3468ef390060c26e640cb1 (github.com)
Megatron-LLaMA/megatron/model/fused_layer_norm.pyNVIDIA/apex at 3303b3e7174383312a3468ef390060c26e640cb1 (github.com)
但是会报没有_six等错误 ,没有inf的错误,这些修改一下就好

解决办法二:

用 python setup.py install,别用pip

其他报错:
- RuntimeError: ColumnParallelLinear was called with gradient_accumulation_fusion set to True but the custom CUDA extension fused_weight_gradient_mlp_cuda module is not found. To use gradient_accumulation_fusion you must install APEX with --cpp_ext and --cuda_ext. For example: pip install --global-option="--cpp_ext" --global-option="--cuda_ext ." Note that the extension requires CUDA>=11. Otherwise, you must turn off gradient accumulation fusion.RuntimeError
- : ColumnParallelLinear was called with gradient_accumulation_fusion set to True but the custom CUDA extension fused_weight_gradient_mlp_cuda module is not found. To use gradient_accumulation_fusion you must install APEX with --cpp_ext and --cuda_ext. For example: pip install --global-option="--cpp_ext" --global-option="--cuda_ext ." Note that the extension requires CUDA>=11. Otherwise, you must turn off gradient accumulation fusion.
【精选】安装apex报错_install the apex with cuda support (https://github-CSDN博客ModuleNotFoundError: No module named ‘fused_layer_norm_cuda‘_我用k-bert的时候报错no module named 'layer_norm,但我是有这个组件的-CSDN博客
增加cuda环境变量:
- export CUDA_HOME=/usr/local/cuda-11.3
- export LD_LIBRARY_PATH=/usr/local/cuda-11.3/lib64:$LD_LIBRARY_PATH
报错:21.05没有transformer_engine
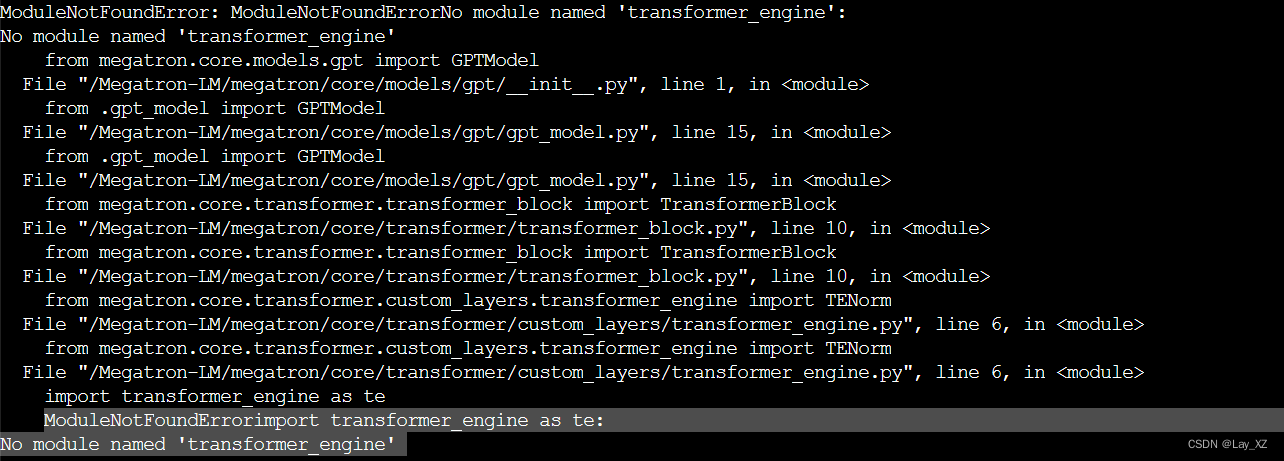
然后完全不知道为什么会报段错误
又换了22.10,没有段错误但是,缺少te.pytorch.DotProductAttention!!!!安装transformer_engine又是各种报错,是我没看文档,transformer_engine0.6以上才有这个API

23.04环境运行报错:原因就是cuda和gpu和torch版本不匹配

- #cuda是否可用;
- torch.cuda.is_available()
- # 返回gpu数量;
- torch.cuda.device_count()
- # 返回gpu名字,设备索引默认从0开始;
- torch.cuda.get_device_name(0)
- # 返回当前设备索引;
- torch.cuda.current_device()
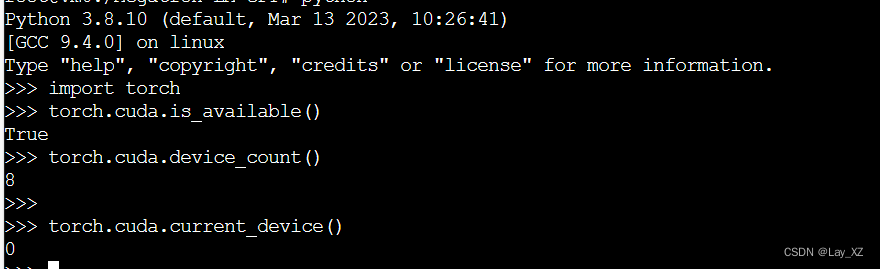
尝试1:卸载torch然后重新下载,但是transformer_engine损坏了,链接不到了
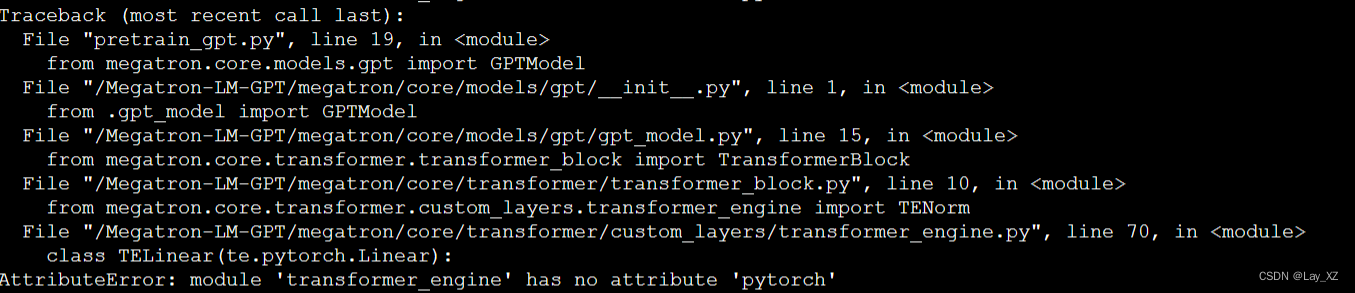
尝试2:不要 transformer_engine
vim megatron/core/transformer/custom_layers/transformer_engine.py不行还是需要用到的,删掉容器重来吧,回到原点的错误
WARNING: Setting args.overlap_p2p_comm to False since non-interleaved schedule does not support overlapping p2p communication
查看算力: 查看NVIDIA显卡计算能力-CSDN博客

就是GPU的算力和cuda不匹配
怎么在cuda的镜像上堆pytorch镜像?

我最后还是在23.04环境里重新安装了cuda11.8
因为只有cuda环境的镜像太干净了,要自己重装好多东西!!
然后重装torch
但是重装不了transformer_engine,然后我终于在找为什么的时候发现了tesla根本用不了!!!!



最后选择MegatronLM的2.5版本就不会用到它!
2、准备数据集
数据集下载地址:
安装依赖库
pip install ftfy langdetect numpy torch pandas nltk sentencepiece boto3 tqdm regex bs4 newspaper3k htmlmin tldextract -i https://pypi.tuna.tsinghua.edu.cn/simple --trusted-host pypi.tuna.tsinghua.edu.cn进入openwebtext文件夹下,将下载的数据集放在urls文件夹下,然后去重,执行
python3 blacklist_urls.py urls clean_urls.txt从url下载数据,使用工具:
yet-another-account/openwebtext at dependabot/pip/certifi-2022.12.7 (github.com)
python3 download.py clean_urls.txt --n_procs=15 --timeout=15 ----output_dir然后报错
TypeError: 'ExtractResult' object is not iterable
- Traceback (most recent call last):
- File "download.py", line 307, in <module>
- cdata = list(pool.imap(download, chunk, chunksize=1))
- File "/opt/conda/lib/python3.8/multiprocessing/pool.py", line 868, in next
- raise value
- TypeError: 'ExtractResult' object is not iterable
解决1: tldextract版本不对,换个版本就可以跑了
这个问题出现在尝试使用 tldextract 库从 URL 中提取域名时。错误消息表明 tldextract.extract(url) 的结果类型不可迭代,这可能是因为库的版本更新或者在使用上有一些变化

下载完成后,之后就会生成一个scraped文件夹,每个url下载的文本就保存在data子文件夹下
使用(merge_jsons.py)来把文件夹中的所有txt合并成一个json文件
python3 tools/openwebtext/merge_jsons.py --data_path=scraped/data --output_file=data/merged_output.json
数据清洗:
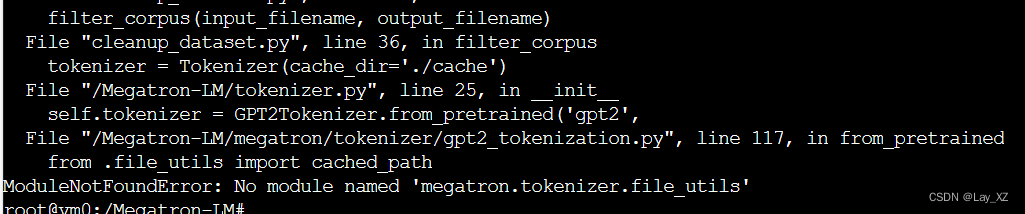
python3 cleanup_dataset.py tools/openwebtext/merged_output.json data/merged_cleand.json报错:找不到tokenizer
之前一直以为是识别不到megatron里的tokenizer,或者是pip tokenizer的包,弄了好久,结果是根本就是缺少了一个tokenizer.py

这是tokenizer.py
- # coding=utf-8
- # Copyright (c) 2019, NVIDIA CORPORATION. All rights reserved.
- #
- # Licensed under the Apache License, Version 2.0 (the "License");
- # you may not use this file except in compliance with the License.
- # You may obtain a copy of the License at
- #
- # http://www.apache.org/licenses/LICENSE-2.0
- #
- # Unless required by applicable law or agreed to in writing, software
- # distributed under the License is distributed on an "AS IS" BASIS,
- # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
- # See the License for the specific language governing permissions and
- # limitations under the License.
-
- import sys
- sys.path.append('..')
-
- from megatron.tokenizer.gpt2_tokenization import GPT2Tokenizer
-
-
- class Tokenizer:
-
- def __init__(self, cache_dir=None):
- self.tokenizer = GPT2Tokenizer.from_pretrained('gpt2',
- cache_dir=cache_dir)
- self.tokenizer.max_len = int(1e12)
- self.eod_token = self.tokenizer.encoder['<|endoftext|>']
- assert self.eod_token < 65535, 'vocab size will not fit in uint16'
- print('> GPT2 tokenizer with {} vocab size and eod token {} ...'.format(
- len(self.tokenizer.encoder), self.eod_token))
-
- def tokenize_document(self, document):
- tokens = self.tokenizer.encode(document)
- tokens.append(self.eod_token)
- return tokens

fix issue #33 missing modules by hyoo · Pull Request #89 · NVIDIA/Megatron-LM (github.com)
cannot import name 'cached_path' from 'transformers'


shuffle清洗后的数据集。
shuf data/merged_cleand.json -o data/train_data.json
数据预处理:
- python tools/preprocess_data.py \
- --input data/train_data_half.json \
- --output-prefix data/my-gpt2_half \
- --vocab-file model/gpt2-vocab.json\
- --tokenizer-type GPT2BPETokenizer \
- --merge-file model/gpt2-merges.txt \
- --append-eod \
- --workers 20

输出文件名为 my-gpt2_text_document.bin 和 my-gpt2_text_document.idx。在 GPT2 训练时,使用不带扩展名的名称作为 --data-path。
至此数据处理结束!
- #!/bin/bash
-
- # Runs the "345M" parameter model
-
- export CUDA_DEVICE_MAX_CONNECTIONS=1
-
- CHECKPOINT_PATH=model/model_optim_rng.pt
- VOCAB_FILE=model/gpt2-vocab.json
- MERGE_FILE=model/gpt2-merges.txt
- DATA_PATH=data/my-gpt2_text_document
- MODEL_PATH=model/output
-
- # 模型超参数
- GPT_ARGS="
- --num-layers 24 \
- --hidden-size 1024 \
- --num-attention-heads 16 \
- --seq-length 1024 \
- --max-position-embeddings 1024 \
- --micro-batch-size 1 \
- --global-batch-size 2 \
- --lr 0.00015 \
- --train-iters 5000 \
- --lr-decay-iters 320000 \
- --lr-decay-style cosine \
- --min-lr 1.0e-5 \
- --weight-decay 1e-2 \
- --lr-warmup-fraction .01 \
- --clip-grad 1.0 \
- --fp16
- "
-
- # 数据集和词表路径参数
- DATA_ARGS="
- --data-path $DATA_PATH \
- --vocab-file $VOCAB_FILE \
- --merge-file $MERGE_FILE \
- --data-impl mmap \
- --split 700,200,100
- "
-
- # 模型权重输出、评估、日志相关的参数
- OUTPUT_ARGS="
- --log-interval 100 \
- --save-interval 10000 \
- --eval-interval 1000 \
- --eval-iters 10
- "
-
- # 启动训练任务
- torchrun pretrain_gpt.py \
- $GPT_ARGS \
- $DATA_ARGS \
- $OUTPUT_ARGS \
- --save $MODEL_PATH \
- --load $CHECKPOINT_PATH
3、模型训练:
查看显卡占用情况:
watch -n 5 nvidia-smi- python -m gpt2 train --train_corpus data/wikitext-103-raw/wiki.train.raw \
- --eval_corpus data/wikitext-103-raw/wiki.test.raw \
- --vocab_path build/vocab.txt \
- --save_checkpoint_path ckpt-gpt2.pth \
- --save_model_path gpt2-pretrained.pth \
- --batch_train 128 \
- --batch_eval 128 \
- --seq_len 64 \
- --total_steps 1000000 \
- --eval_steps 500 \
- --save_steps 5000 \
- --use_amp \
- --use_grad_ckpt \
- --gpus GPUS 4
单机单卡:
-
- CHECKPOINT_PATH=model/model_optim_rng.pt
- VOCAB_FILE=model/gpt2-vocab.json
- MERGE_FILE=model/gpt2-merges.txt
- DATA_PATH=data/my-gpt2_text_document
- MODEL_PATH=model/output
-
- GPT_ARGS="--num-layers 24 \
- --hidden-size 1024 \
- --num-attention-heads 16 \
- --seq-length 1024 \
- --max-position-embeddings 1024 \
- --micro-batch-size 4 \
- --global-batch-size 8 \
- --lr 0.00015 \
- --train-iters 500000 \
- --lr-decay-iters 320000 \
- --lr-decay-style cosine \
- --vocab-file $VOCAB_FILE \
- --merge-file $MERGE_FILE \
- --lr-warmup-fraction .01 \
- --fp16"
-
- OUTPUT_ARGS="--log-interval 10 \
- --save-interval 500 \
- --eval-interval 100 \
- --eval-iters 10 \
- --checkpoint-activations"
-
- python pretrain_gpt.py \
- $GPT_ARGS \
- $OUTPUT_ARGS \
- --save $MODEL_PATH \
- --load $CHECKPOINT_PATH \
- --data-path $DATA_PATH \




Distributed training:
DP:
- WORLD_SIZE=4
- TENSOR_MP_SIZE=1
- PIPELINE_MP_SIZE=1
-
- DISTRIBUTED_ARGS="--nproc_per_node $WORLD_SIZE \
- --nnodes 1 \
- --node_rank 0 \
- --master_addr localhost \
- --master_port 6000"
-
- CHECKPOINT_PATH=model/model_optim_rng.pt
- VOCAB_FILE=model/gpt2-vocab.json
- MERGE_FILE=model/gpt2-merges.txt
- DATA_PATH=data/my-gpt2_text_document
- MODEL_PATH=model/output/mp
-
- GPT_ARGS="--num-layers 24 \
- --hidden-size 1024 \
- --num-attention-heads 16 \
- --seq-length 1024 \
- --max-position-embeddings 1024 \
- --micro-batch-size 2 \
- --global-batch-size 8 \
- --lr 0.00015 \
- --train-iters 500000 \
- --lr-decay-iters 320000 \
- --lr-decay-style cosine \
- --vocab-file $VOCAB_FILE \
- --merge-file $MERGE_FILE \
- --lr-warmup-fraction .01 \
- --fp16"
-
- OUTPUT_ARGS="--log-interval 10 \
- --save-interval 500 \
- --eval-interval 100 \
- --eval-iters 10 \
- --checkpoint-activations"
-
- python -m torch.distributed.launch $DISTRIBUTED_ARGS ./pretrain_gpt.py \
- $GPT_ARGS \
- $OUTPUT_ARGS \
- --save $MODEL_PATH \
- --load $CHECKPOINT_PATH \
- --data-path $DATA_PATH \
- --tensor-model-parallel-size $TENSOR_MP_SIZE \
- --pipeline-model-parallel-size $PIPELINE_MP_SIZE \
- --DDP-impl torch




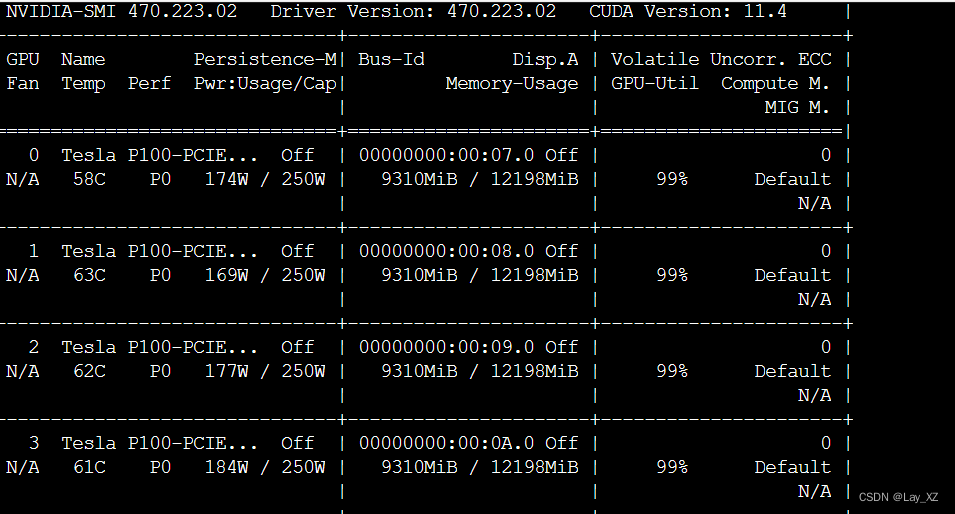
PP:
- WORLD_SIZE=4
- TENSOR_MP_SIZE=1
- PIPELINE_MP_SIZE=4
-
- DISTRIBUTED_ARGS="--nproc_per_node $WORLD_SIZE \
- --nnodes 1 \
- --node_rank 0 \
- --master_addr localhost \
- --master_port 6000"
-
- CHECKPOINT_PATH=model/model_optim_rng.pt
- VOCAB_FILE=model/gpt2-vocab.json
- MERGE_FILE=model/gpt2-merges.txt
- DATA_PATH=data/my-gpt2_text_document
- MODEL_PATH=model/output/mp
-
- GPT_ARGS="--num-layers 24 \
- --hidden-size 1024 \
- --num-attention-heads 16 \
- --seq-length 1024 \
- --max-position-embeddings 1024 \
- --micro-batch-size 2 \
- --global-batch-size 8 \
- --lr 0.00015 \
- --train-iters 500000 \
- --lr-decay-iters 320000 \
- --lr-decay-style cosine \
- --vocab-file $VOCAB_FILE \
- --merge-file $MERGE_FILE \
- --lr-warmup-fraction .01 \
- --fp16"
-
- OUTPUT_ARGS="--log-interval 10 \
- --save-interval 500 \
- --eval-interval 100 \
- --eval-iters 10 \
- --checkpoint-activations"
-
- python -m torch.distributed.launch $DISTRIBUTED_ARGS ./pretrain_gpt.py \
- $GPT_ARGS \
- $OUTPUT_ARGS \
- --save $MODEL_PATH \
- --load $CHECKPOINT_PATH \
- --data-path $DATA_PATH \
- --tensor-model-parallel-size $TENSOR_MP_SIZE \
- --pipeline-model-parallel-size $PIPELINE_MP_SIZE \
- --DDP-impl local


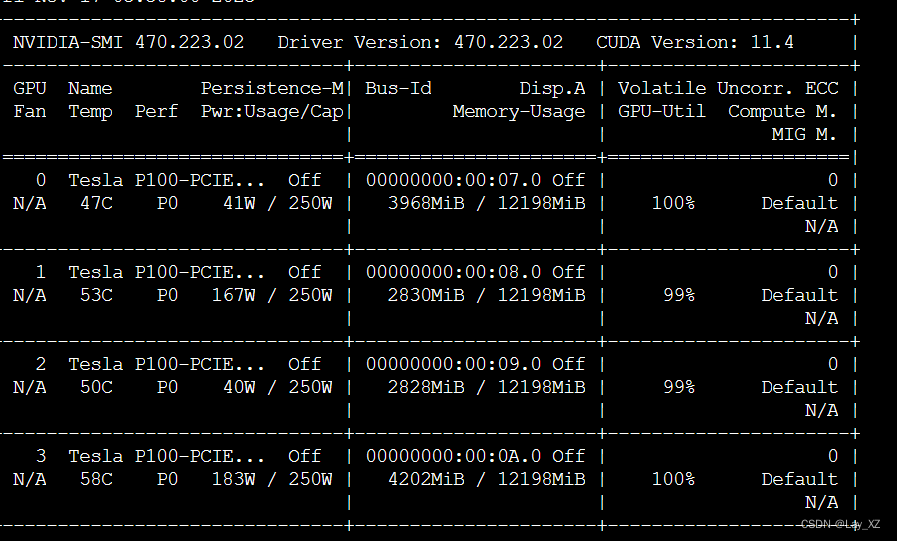

TP:
- WORLD_SIZE=4
- TENSOR_MP_SIZE=4
- PIPELINE_MP_SIZE=1
-
- DISTRIBUTED_ARGS="--nproc_per_node $WORLD_SIZE \
- --nnodes 1 \
- --node_rank 0 \
- --master_addr localhost \
- --master_port 6000"
-
- CHECKPOINT_PATH=model/model_optim_rng.pt
- VOCAB_FILE=model/gpt2-vocab.json
- MERGE_FILE=model/gpt2-merges.txt
- DATA_PATH=data/my-gpt2_text_document
- MODEL_PATH=model/output/tp
-
- GPT_ARGS="--num-layers 24 \
- --hidden-size 1024 \
- --num-attention-heads 16 \
- --seq-length 1024 \
- --max-position-embeddings 1024 \
- --micro-batch-size 2 \
- --global-batch-size 8 \
- --lr 0.00015 \
- --train-iters 500000 \
- --lr-decay-iters 320000 \
- --lr-decay-style cosine \
- --vocab-file $VOCAB_FILE \
- --merge-file $MERGE_FILE \
- --lr-warmup-fraction .01 \
- --fp16"
-
- OUTPUT_ARGS="--log-interval 10 \
- --save-interval 500 \
- --eval-interval 100 \
- --eval-iters 10 \
- --checkpoint-activations"
-
- python -m torch.distributed.launch $DISTRIBUTED_ARGS ./pretrain_gpt.py \
- $GPT_ARGS \
- $OUTPUT_ARGS \
- --save $MODEL_PATH \
- --load $CHECKPOINT_PATH \
- --data-path $DATA_PATH \
- --tensor-model-parallel-size $TENSOR_MP_SIZE \
- --pipeline-model-parallel-size $PIPELINE_MP_SIZE \
- --DDP-impl local
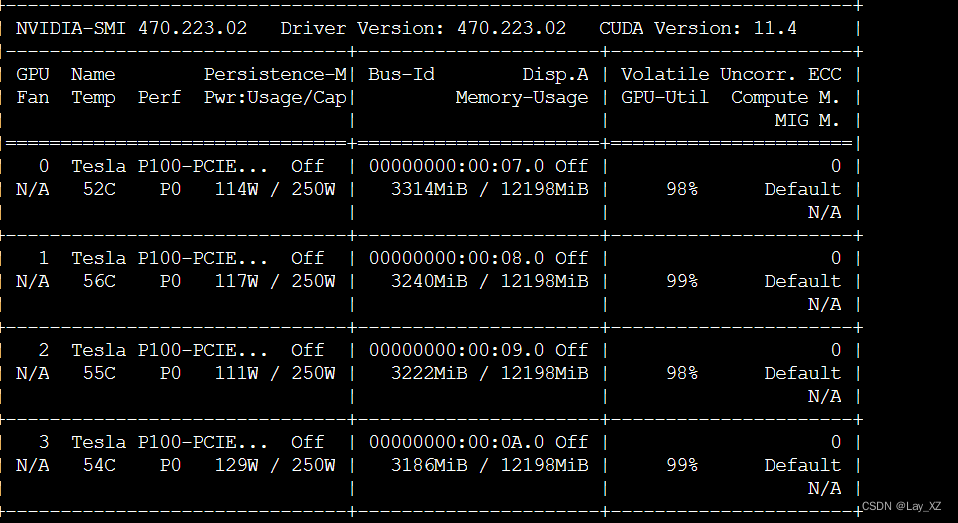


MP:380M
- WORLD_SIZE=4
- TENSOR_MP_SIZE=2
- PIPELINE_MP_SIZE=2
-
- DISTRIBUTED_ARGS="--nproc_per_node $WORLD_SIZE \
- --nnodes 1 \
- --node_rank 0 \
- --master_addr localhost \
- --master_port 6000"
-
- CHECKPOINT_PATH=model/model_optim_rng.pt
- VOCAB_FILE=model/gpt2-vocab.json
- MERGE_FILE=model/gpt2-merges.txt
- DATA_PATH=data/my-gpt2_text_document
- MODEL_PATH=model/output/mp
-
- GPT_ARGS="--num-layers 24 \
- --hidden-size 1024 \
- --num-attention-heads 16 \
- --seq-length 1024 \
- --max-position-embeddings 1024 \
- --micro-batch-size 2 \
- --global-batch-size 8 \
- --lr 0.00015 \
- --train-iters 500000 \
- --lr-decay-iters 320000 \
- --lr-decay-style cosine \
- --vocab-file $VOCAB_FILE \
- --merge-file $MERGE_FILE \
- --lr-warmup-fraction .01 \
- --fp16"
-
- OUTPUT_ARGS="--log-interval 10 \
- --save-interval 500 \
- --eval-interval 100 \
- --eval-iters 10 \
- --checkpoint-activations"
-
- python -m torch.distributed.launch $DISTRIBUTED_ARGS ./pretrain_gpt.py \
- $GPT_ARGS \
- $OUTPUT_ARGS \
- --save $MODEL_PATH \
- --load $CHECKPOINT_PATH \
- --data-path $DATA_PATH \
- --tensor-model-parallel-size $TENSOR_MP_SIZE \
- --pipeline-model-parallel-size $PIPELINE_MP_SIZE \
- --DDP-impl local

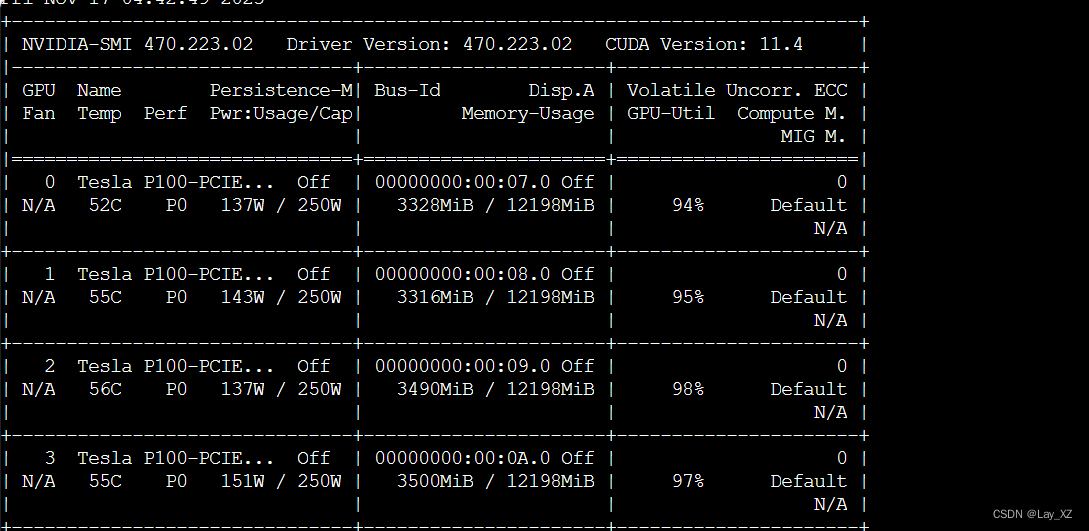

MP:1.6B(参数不太对)
- WORLD_SIZE=4
- TENSOR_MP_SIZE=2
- PIPELINE_MP_SIZE=2
-
- DISTRIBUTED_ARGS="--nproc_per_node $WORLD_SIZE \
- --nnodes 1 \
- --node_rank 0 \
- --master_addr localhost \
- --master_port 6000"
-
- CHECKPOINT_PATH=model/model_optim_rng.pt
- VOCAB_FILE=model/gpt2-vocab.json
- MERGE_FILE=model/gpt2-merges.txt
- DATA_PATH=data/my-gpt2_text_document
- MODEL_PATH=model/output/mp
-
- GPT_ARGS="--num-layers 48 \
- --hidden-size 1024 \
- --num-attention-heads 16 \
- --seq-length 1024 \
- --max-position-embeddings 1600 \
- --micro-batch-size 16 \
- --global-batch-size 64 \
- --lr 0.00015 \
- --train-iters 5000 \
- --lr-decay-iters 320000 \
- --lr-decay-style cosine \
- --vocab-file $VOCAB_FILE \
- --merge-file $MERGE_FILE \
- --lr-warmup-fraction .01 \
- --fp16"
-
- OUTPUT_ARGS="--log-interval 10 \
- --save-interval 500 \
- --eval-interval 100 \
- --eval-iters 10 \
- --checkpoint-activations"
-
- python -m torch.distributed.launch $DISTRIBUTED_ARGS ./pretrain_gpt.py \
- $GPT_ARGS \
- $OUTPUT_ARGS \
- --save $MODEL_PATH \
- --load $CHECKPOINT_PATH \
- --data-path $DATA_PATH \
- --tensor-model-parallel-size $TENSOR_MP_SIZE \
- --pipeline-model-parallel-size $PIPELINE_MP_SIZE \
- --DDP-impl local




训练llama7B:
wiki数据集的xml转成json格式了,怎么从url获取text呢??
Wikidata 数据包下载+格式转换+入库MySQL_wiki数据库-CSDN博客
快速使用wikiextractor提取维基百科语料的简单用法-CSDN博客
wiki中文文本语料下载并处理 ubuntu + python2.7_wikismallen.txt-CSDN博客

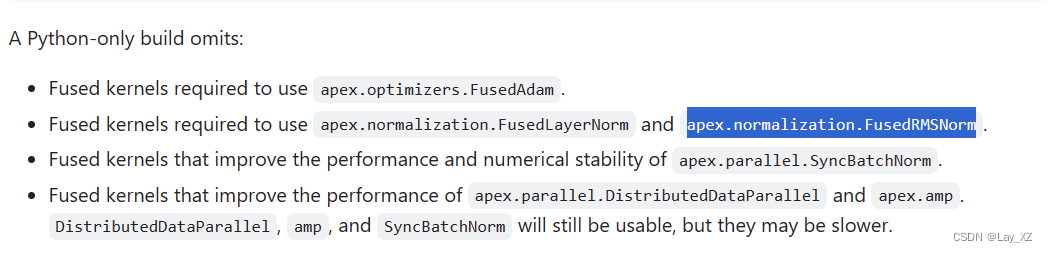
还是用了openwebtext数据集
- python Megatron-LLaMA/tools/preprocess_data.py \
- --input data/train_halfdata.json \
- --output-prefix data/openwebtexthalf \
- --dataset-impl mmap \
- --tokenizer-type PretrainedFromHF \
- --tokenizer-name-or-path llama7B_hf \
- --append-eod \
- --workers 20 \
- --chunk-size 25
将huggingface转换为megatron可用,但是这个卡跑不下7B的,砍了参数,就不适配这个转换好的 了
- python Megatron-LLaMA/tools/checkpoint_conversion/llama_checkpoint_conversion.py \
- --load_path "llama7B_hf" \
- --save_path "llama7B_hf_ab" \
- --target_tensor_model_parallel_size 2 \
- --target_pipeline_model_parallel_size 4 \
- --target_data_parallel_size 1 \
- --target_params_dtype "fp16" \
- --make_vocab_size_divisible_by 1 \
- --print-checkpoint-structure \
- --megatron-path "Megatron-LLaMA"
这个是将llama官网下的tokenizer.model转换为huggingface的
- python convert_llama_weights_to_hf.py \
- --input_dir llama7B \
- --model_size 7B \
- --output_dir llama7B_hf
转换成功后
- #!/bin/bash
-
-
- DATASET="data/openwebtexthalf"
-
- TP_SIZE=2
- PP_SIZE=4
- WORLD_SIZE=8
- MICRO_BATCH_SIZE=1
- # The int is the number of micro steps of gradient accumulation
- GLOBAL_BATCH_SIZE=$((($WORLD_SIZE * $MICRO_BATCH_SIZE) / ($TP_SIZE * $PP_SIZE) * 8))
- # GLOBAL_BATCH_SIZE=128
-
- JOB_NAME="LLaMA_tp${TP_SIZE}_pp${PP_SIZE}_mbs${MICRO_BATCH_SIZE}_gpus${WORLD_SIZE}"
-
- LOAD_CHECKPOINT_PATH="llama7B_hf_ab/"
- SAVE_CHECKPOINT_PATH="model/llama-7/"
- TOKENIZER_PATH="llama7B_hf_ab/"
- TENSORBOARD_DIR="model/tensorboard/"
-
- TRAIN_ITERS=1000
- EVAL_ITERS=10
- EVAL_INTERVAL=1000
- SAVE_INTERVAL=100
- LOG_INTERVAL=1
-
- # Setting --tensorboard-queue-size to 1 significantly slows down the training
- options=" \
- --finetune \
- --sequence-parallel \
- --tensor-model-parallel-size ${TP_SIZE} \
- --pipeline-model-parallel-size ${PP_SIZE} \
- --num-layers 32 \
- --hidden-size 4096 \
- --num-attention-heads 32 \
- --seq-length 4096 \
- --max-position-embeddings 4096 \
- --no-position-embedding \
- --use-rotary-position-embeddings \
- --swiglu \
- --ffn-hidden-size 11008\
- --disable-bias-linear \
- --RMSNorm \
- --layernorm-epsilon 1e-6 \
- --causal-lm \
- --tokenizer-type PretrainedFromHF \
- --tokenizer-name-or-path $TOKENIZER_PATH \
- --make-vocab-size-divisible-by 1 \
- --init-method-std 0.01 \
- --micro-batch-size ${MICRO_BATCH_SIZE} \
- --global-batch-size ${GLOBAL_BATCH_SIZE} \
- --train-iters ${TRAIN_ITERS} \
- --lr 6.0e-5 \
- --lr-decay-iters 10 \
- --lr-warmup-iters 5 \
- --min-lr 6.0e-6 \
- --override-opt_param-scheduler \
- --lr-decay-style cosine \
- --adam-beta1 0.9 \
- --adam-beta2 0.95 \
- --clip-grad 1.0 \
- --weight-decay 0.1 \
- --overlapped-distributed-optimizer \
- --reduce-bucket-size=2e8 \
- --no-gradient-accumulation-fusion \
- --dataloader-type cyclic \
- --data-impl mmap \
- --data-path ${DATASET} \
- --split 98,2,0 \
- --eval-interval ${EVAL_INTERVAL} \
- --eval-iters ${EVAL_ITERS} \
- --save-interval ${SAVE_INTERVAL} \
- --save ${SAVE_CHECKPOINT_PATH} \
- --load ${LOAD_CHECKPOINT_PATH} \
- --no-load-optim \
- --log-interval ${LOG_INTERVAL} \
- --tensorboard-dir ${TENSORBOARD_DIR} \
- --tensorboard-queue-size 1000 \
- --log-timers-to-tensorboard \
- --log-batch-size-to-tensorboard \
- --log-validation-ppl-to-tensorboard \
- --job-name ${JOB_NAME} \
- --bf16 \
- --recompute-activations \
- --recompute-granularity selective \
- "
-
- torchrun --nproc_per_node=8 --master_port=6000 Megatron-LLaMA/pretrain_llama.py ${options}



终于跑起来了,就是因为 megatron-llama的fused_kernels里用了

导致编译通不过但不知道为什么


词向量维度*((4*词向量维度 + 3*FFN隐藏层维度) *层数+词表大小+窗口长度)



