
热门标签
当前位置: article > 正文
为什么选择spark
作者:Gausst松鼠会 | 2024-05-30 21:27:55
赞
踩
为什么选择spark
原因
随着互联网规模的爆发式增长,不断增加的数据量要求应用程序能够延伸到更大的集群中去计算。
与单台机器计算不同,集群计算引发了几个关键问题,如
集群计算资源的共享
单点宕机(单点死机的意思)
节点执行缓慢
程序的并行化。针对这几个集群环境的问题,许多大数据处理框架应运而生。
比如Google的MapReduce,它提出了简单、通用并具有自动容错功能的批处理计算模型。但是MapReduce对于某些类型的计算并不适合,比如
交互式(对话的方式一问一答,相互的那种)
流式计算(对数据流进行实时计算)
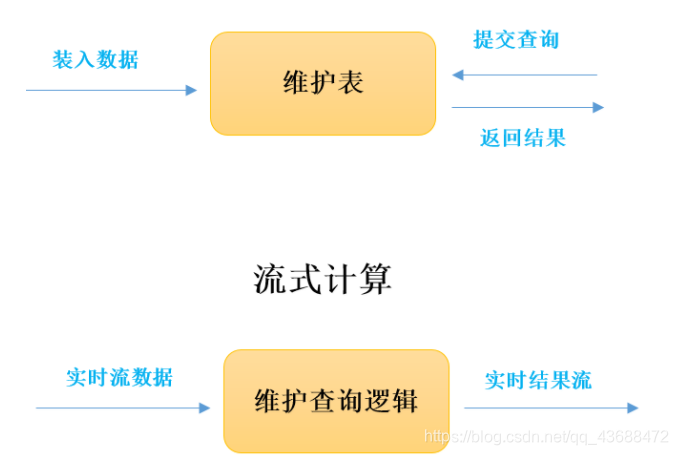
基于这种类型需求的不一致性,大量不同于MapReduce的专门数据处理模型诞生了,如GraphLab、Impala、Storm等。大量数据模型的产生,引发的后果是对于大数据处理而言,针对不同类型的计算,通常需要一系列不同的处理框架才能完成。这些不同的处理框架由于天生的差异又带来了一系列问题:
重复计算、
使用范围的局限性、
资源分配、
统一管理
又出现了这些问题,spark诞生了
要注意这些问题,不同的时间段出现不同的问题,有不同的解决方法
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/Gausst松鼠会/article/detail/648676
推荐阅读
相关标签

