
热门标签
热门文章
- 1Spring源码分析-BeanDefinition_spring源码系列之beandefinition
- 2Mac 解决配置 zsh 后,nvm不见的问题
- 3苹果微信分身双开怎么弄?2024最新苹果微信分身下载教程!
- 4AI代码生成助手Cursor、TabNine 、Cosy使用体验_cursor是基于chargbt的吗
- 5四、Hybrid_astar.py文件中Hybrid A * 算法程序的详细介绍
- 6微信小程序电子签名及图片生成_电子签名小程序
- 7腾讯云认证FAQ | 热门考试方向、考试报名流程、模拟试题等_腾讯云运维工程师认证
- 8Sublime text3 Version 3.22下载安装及注册_sublime 322 注册
- 9详解Python对Excel处理_python能处理xls文件吗
- 10《Flink原理、实战与性能优化》(Flink知识梳理一)
当前位置: article > 正文
计算机毕业设计hadoop+spark+hive物流大数据分析平台 物流预测系统 物流信息爬虫 物流大数据 机器学习 深度学习 知识图谱 大数据
作者:花生_TL007 | 2024-05-28 15:41:36
赞
踩
计算机毕业设计hadoop+spark+hive物流大数据分析平台 物流预测系统 物流信息爬虫 物流大数据 机器学习 深度学习 知识图谱 大数据
流程:
1.Python爬虫采集物流数据等存入mysql和.csv文件;
2.使用pandas+numpy或者MapReduce对上面的数据集进行数据清洗生成最终上传到hdfs;
3.使用hive数据仓库完成建库建表导入.csv数据集;
4.使用hive之hive_sql进行离线计算,使用spark之scala进行实时计算;
5.将计算指标使用sqoop工具导入mysql;
6.使用Flask+echarts进行可视化大屏实现、数据查询表格实现、含预测算法;
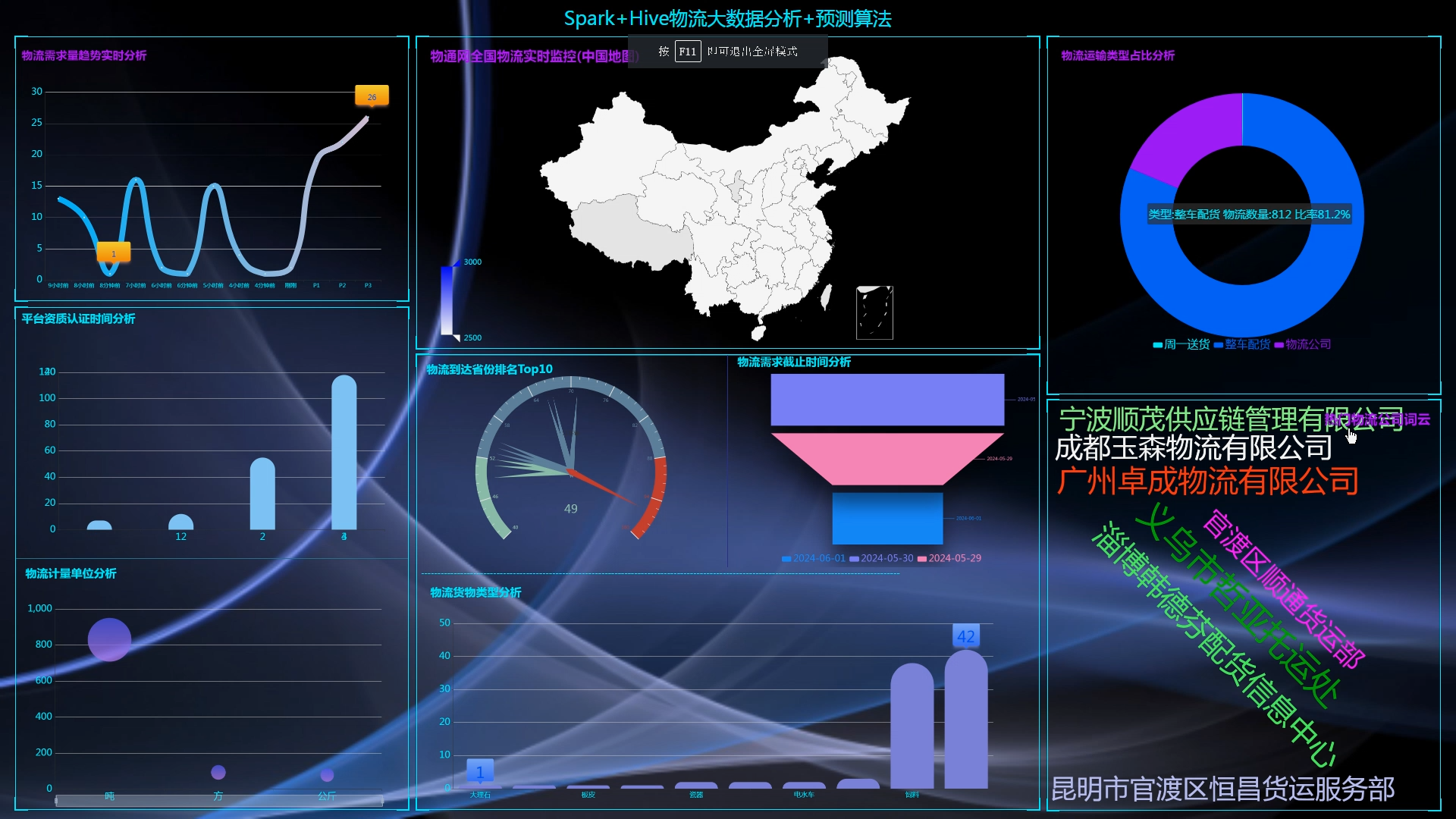

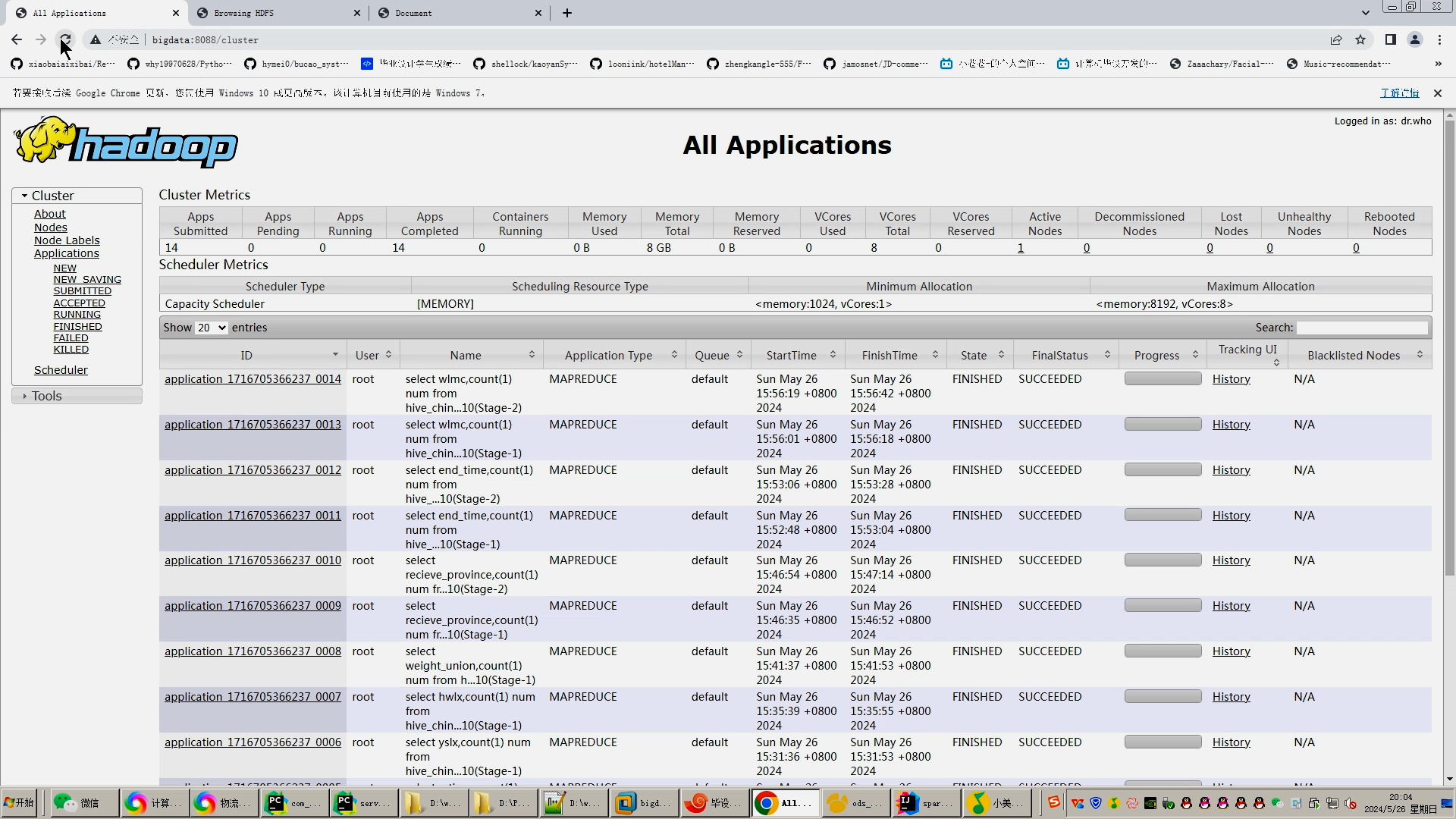


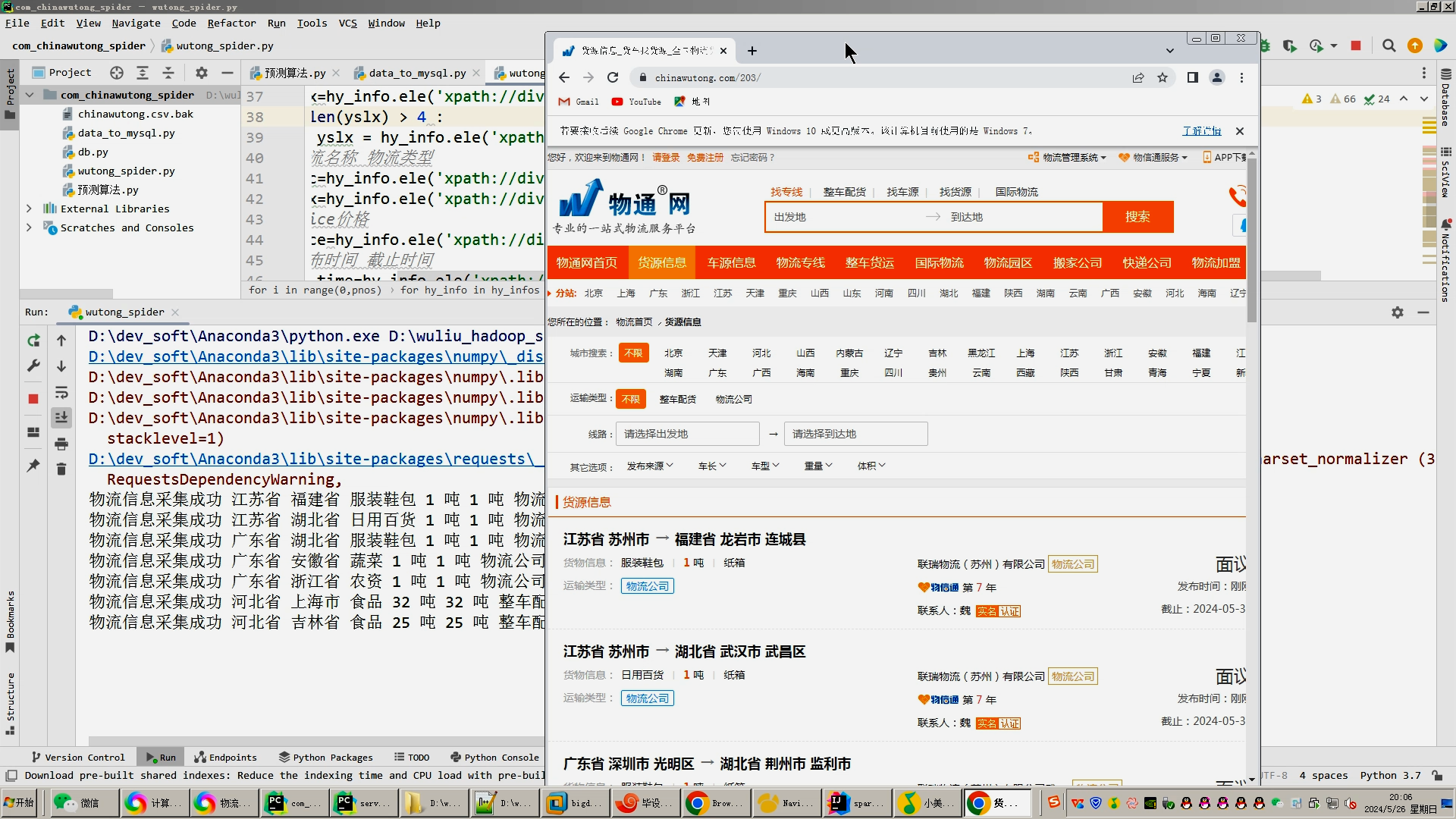
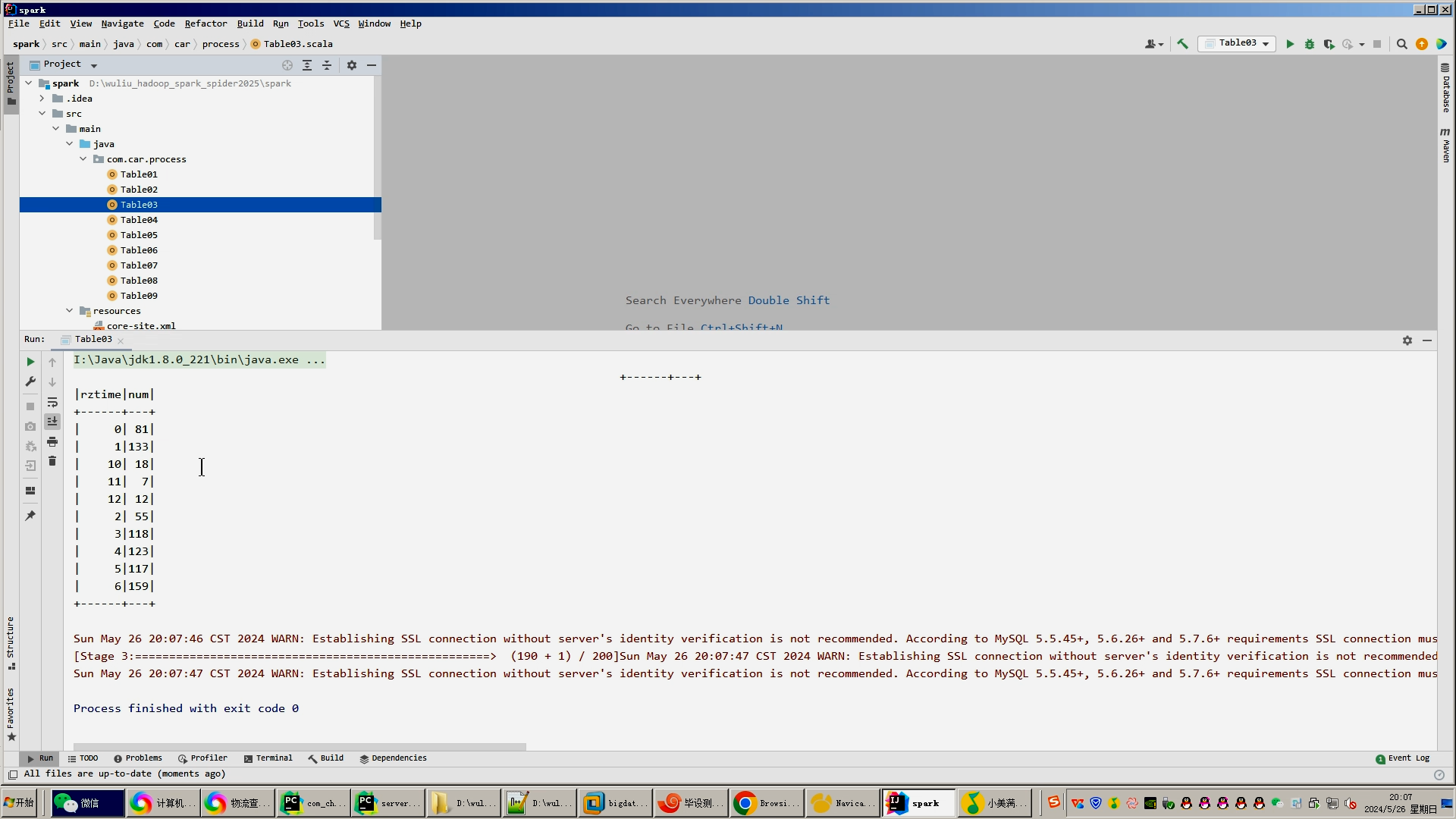

核心算法代码分享如下:
- from flask import Flask, render_template, request, redirect, url_for
- import json
- from flask_mysqldb import MySQL
- from flask import Flask, send_from_directory,render_template, request, redirect, url_for, jsonify
- import csv
- import os
- import pymysql
- # 创建应用对象
- app = Flask(__name__)
- app.config['MYSQL_HOST'] = 'bigdata'
- app.config['MYSQL_USER'] = 'root'
- app.config['MYSQL_PASSWORD'] = '123456'
- app.config['MYSQL_DB'] = 'hive_chinawutong'
- mysql = MySQL(app) # this is the instantiation
-
-
- @app.route('/tables01')
- def tables01():
- cur = mysql.connection.cursor()
- cur.execute('''SELECT replace(REPLACE(REPLACE(from_province, '区', ''), '省', ''),'市','') from_province,num FROM table01''')
- #row_headers = [x[0] for x in cur.description] # this will extract row headers
- row_headers = ['from_province','num'] # this will extract row headers
- rv = cur.fetchall()
- json_data = []
- #print(json_data)
- for result in rv:
- json_data.append(dict(zip(row_headers, result)))
- return json.dumps(json_data, ensure_ascii=False)
-
- @app.route('/tables02')
- def tables02():
- cur = mysql.connection.cursor()
- cur.execute('''SELECT pub_time,num,LENGTH(pub_time) len_time FROM table02 ORDER BY len_time desc ''')
- #row_headers = [x[0] for x in cur.description] # this will extract row headers
- row_headers = ['pub_time','num'] # this will extract row headers
- rv = cur.fetchall()
- json_data = []
- #print(json_data)
- for result in rv:
- json_data.append(dict(zip(row_headers, result)))
- return json.dumps(json_data, ensure_ascii=False)
-
- @app.route('/tables03')
- def tables03():
- cur = mysql.connection.cursor()
- cur.execute('''SELECT * FROM table03 order by rztime asc''')
- #row_headers = [x[0] for x in cur.description] # this will extract row headers
- row_headers = ['rztime','num'] # this will extract row headers
- rv = cur.fetchall()
- json_data = []
- #print(json_data)
- for result in rv:
- json_data.append(dict(zip(row_headers, result)))
- return json.dumps(json_data, ensure_ascii=False)
-
- @app.route('/tables04')
- def tables04():
- cur = mysql.connection.cursor()
- cur.execute('''SELECT * FROM table04''')
- #row_headers = [x[0] for x in cur.description] # this will extract row headers
- row_headers = ['yslx','num'] # this will extract row headers
- rv = cur.fetchall()
- json_data = []
- #print(json_data)
- for result in rv:
- json_data.append(dict(zip(row_headers, result)))
- return json.dumps(json_data, ensure_ascii=False)
-
- @app.route("/getmapcountryshowdata")
- def getmapcountryshowdata():
- filepath = r"D:\\wuliu_hadoop_spark_spider2025\\echarts\\data\\maps\\china.json"
- with open(filepath, "r", encoding='utf-8') as f:
- data = json.load(f)
- return json.dumps(data, ensure_ascii=False)
-
-
- @app.route('/tables05')
- def tables05():
- cur = mysql.connection.cursor()
- cur.execute('''SELECT * FROM table05 order by num asc''')
- #row_headers = [x[0] for x in cur.description] # this will extract row headers
- row_headers = ['hwlx','num'] # this will extract row headers
- rv = cur.fetchall()
- json_data = []
- #print(json_data)
- for result in rv:
- json_data.append(dict(zip(row_headers, result)))
- return json.dumps(json_data, ensure_ascii=False)
-
- @app.route('/tables06')
- def tables06():
- cur = mysql.connection.cursor()
- cur.execute('''SELECT * FROM table06''')
- #row_headers = [x[0] for x in cur.description] # this will extract row headers
- row_headers = ['weight_union','num'] # this will extract row headers
- rv = cur.fetchall()
- json_data = []
- #print(json_data)
- for result in rv:
- json_data.append(dict(zip(row_headers, result)))
- return json.dumps(json_data, ensure_ascii=False)
-
- @app.route('/tables07')
- def tables07():
- cur = mysql.connection.cursor()
- cur.execute('''SELECT * FROM table07 order by num asc''')
- #row_headers = [x[0] for x in cur.description] # this will extract row headers
- row_headers = ['recieve_province','num'] # this will extract row headers
- rv = cur.fetchall()
- json_data = []
- #print(json_data)
- for result in rv:
- json_data.append(dict(zip(row_headers, result)))
- return json.dumps(json_data, ensure_ascii=False)
-
- @app.route('/tables08')
- def tables08():
- cur = mysql.connection.cursor()
- cur.execute('''SELECT * FROM table08''')
- #row_headers = [x[0] for x in cur.description] # this will extract row headers
- row_headers = ['end_time','num'] # this will extract row headers
- rv = cur.fetchall()
- json_data = []
- #print(json_data)
- for result in rv:
- json_data.append(dict(zip(row_headers, result)))
- return json.dumps(json_data, ensure_ascii=False)
-
- @app.route('/tables09')
- def tables09():
- cur = mysql.connection.cursor()
- cur.execute('''SELECT * FROM table09''')
- #row_headers = [x[0] for x in cur.description] # this will extract row headers
- row_headers = ['wlmc','num'] # this will extract row headers
- rv = cur.fetchall()
- json_data = []
- #print(json_data)
- for result in rv:
- json_data.append(dict(zip(row_headers, result)))
- return json.dumps(json_data, ensure_ascii=False)
-
-
- @app.route('/data',methods=['GET'])
- def data():
- limit = int(request.args['limit'])
- page = int(request.args['page'])
- page = (page-1)*limit
- conn = pymysql.connect(host='bigdata', user='root', password='123456', port=3306, db='hive_chinawutong',
- charset='utf8mb4')
-
- cursor = conn.cursor()
- if (len(request.args) == 2):
- cursor.execute("select count(*) from ods_chinawutong");
- count = cursor.fetchall()
- cursor = conn.cursor(cursor=pymysql.cursors.DictCursor)
- cursor.execute("select * from ods_chinawutong limit "+str(page)+","+str(limit));
- data_dict = []
- result = cursor.fetchall()
- for field in result:
- data_dict.append(field)
- else:
- weight_union = str(request.args['weight_union'])
- wlmc = str(request.args['wlmc']).lower()
- if(weight_union=='不限'):
- cursor.execute("select count(*) from ods_chinawutong where wlmc like '%"+wlmc+"%'");
- count = cursor.fetchall()
- cursor = conn.cursor(cursor=pymysql.cursors.DictCursor)
- cursor.execute("select * from ods_chinawutong where wlmc like '%"+wlmc+"%' limit " + str(page) + "," + str(limit));
- data_dict = []
- result = cursor.fetchall()
- for field in result:
- data_dict.append(field)
- else:
- cursor.execute("select count(*) from ods_chinawutong where wlmc like '%"+wlmc+"%' and weight_union like '%"+weight_union+"%'");
- count = cursor.fetchall()
- cursor = conn.cursor(cursor=pymysql.cursors.DictCursor)
- cursor.execute("select * from ods_chinawutong where wlmc like '%"+wlmc+"%' and weight_union like '%"+weight_union+"%' limit " + str(page) + "," + str(limit));
- data_dict = []
- result = cursor.fetchall()
- for field in result:
- data_dict.append(field)
- table_result = {"code": 0, "msg": None, "count": count[0], "data": data_dict}
- cursor.close()
- conn.close()
- return jsonify(table_result)
-
-
- if __name__ == "__main__":
- app.run(debug=False)

声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/花生_TL007/article/detail/638194
推荐阅读
相关标签

