
- 1Python实现雅可比(Jacobi)迭代计算_1.利用numpy的矩阵运算实现雅可比迭代法解线性方程组 2.完成jacobi矩阵迭代并行计
- 2华为认证H12-811题库_如下图所示的网络,主机 a 没有配置网关,主机 b 存在网关的 arp 缓存,下列说法 正
- 3python 百天面试题(1-10)_给列表set1=[1,2,3,5,6,3,2],删除元素8
- 4解决win7下安装Mysql卡在Start service的问题_mysql7安装start service
- 5图像处理学习笔记(1)——图像滤波_bitmap 图片添加滤波
- 6熵值TOPSIS_熵值topsis法
- 7matlab 熵权法代码
- 8【论文阅读】Time-Series Anomaly Detection Service at Microsoft_sr谱残差
- 9Java Excel 导出为 PDF_hssfworkbook转pdf
- 10蓝桥杯2022 第一次官方模拟赛 1-9 个人代码
Elasticsearch 基本使用(四)聚合查询_es聚合查询
赞
踩
概述
说到聚合查询,马上会想到 SQL 中的 group by,ES中也有类似的功能,名叫 Aggregation。
单字段聚合查询
统计分组后的数量
按年龄分组,然后统计每个年龄人数 count(*) ,age xxx group by age
非文档字段分组
GET bank/_search
{
"aggs": {
"by_age": {
"terms": {
# age 为数值,可以直接分组
"field": "age"
}
}
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
文档字段分组
GET bank/_search
{
"aggs": {
"by_age": {
"terms": {
"field": "city"
}
}
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
直接使用文档字段分组会报错。

ES没有对文本字段聚合,排序等操作优化;如果对文本字段进行分组,推荐使用 关键字字段
改为关键字分组
GET bank/_search
{
"aggs": {
"by_age": {
"terms": {
"field": "city.keyword"
}
}
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
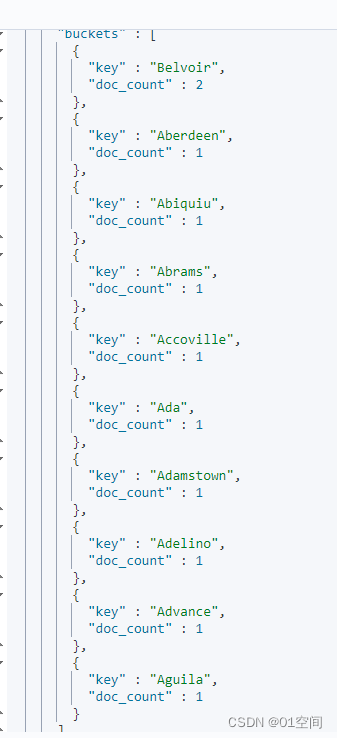
但是,ES默认只返回10条分组数据;如果要返回更多分组数据,需要在聚合里面使用 size 字段
GET bank/_search
{
"aggs": {
"by_age": {
"terms": {
"field": "city.keyword",
"size": 1000
}
}
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
可以看到,返回了更多的分组数据
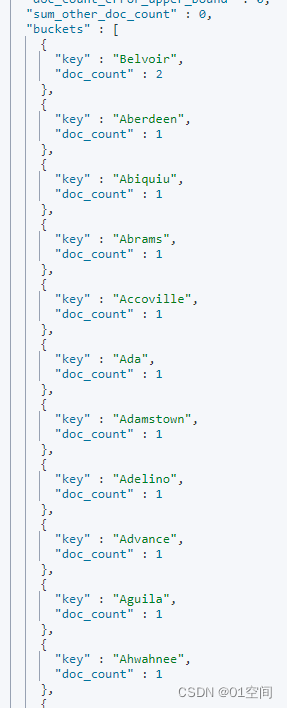
其他聚合运算
在使用 terms时,ES会根据指定字段进行分组;此时得到的结果集是
"buckets" : [
{
"key" : 分组字段的值,
"doc_count" : 当前分组数量
}
]
- 1
- 2
- 3
- 4
- 5
- 6
统计平均值
如果,我们要基于当前分组,进行其他聚合运算呢。
比如,我先按照年龄分组,统计数量;
然后我要统计每个分组内,账户余额的平均值呢。
# 基于年龄分组的基础上,统计账户余额平均值 GET bank/_search { "size": 0, "aggs": { "by_age": { "terms": { "field": "age", "size": 1000 }, "aggs": { "avg_balance": { "avg": { "field": "balance" } } } } } }

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
统计总金额
如果还要基于账户余额平均值的基础上,还要进行其他聚合运算,可以直接在 内部的 aggs 内添加其他聚合函数。比如,我不仅要统计平均值,还要统计每个分组内的账户总金额。
# 基于统计账户余额平均值的基础上,再统计每个分组下,账户总金额 GET bank/_search { "size": 0, "aggs": { "by_age": { "terms": { "field": "age", "size": 1000 }, "aggs": { "avg_balance": { "avg": { "field": "balance" } }, "sum_balance":{ "sum": { "field": "balance" } } } } } }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
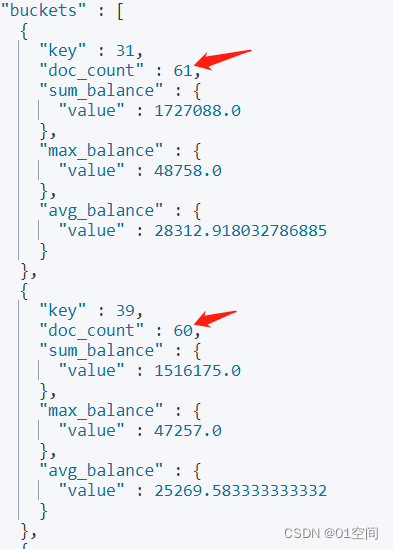
统计最大值
再统计一个,基于年龄的分组下,账户余额的最大值
# 基于统计账户余额平均值和总金额的基础上,再统计每个分组下,账户最大余额 GET bank/_search { "size": 0, "aggs": { "by_age": { "terms": { "field": "age", "size": 1000 }, "aggs": { "avg_balance": { "avg": { "field": "balance" } }, "sum_balance":{ "sum": { "field": "balance" } }, "max_balance":{ "max": { "field": "balance" } } } } } }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
自定义聚合结果排序
默认,ES的聚合以分组内数量倒序排序。
我们基于上面最后的统计结果,自定义聚合结果排序
- 默认排序方式
- 按数量升序
之前说过,默认分组,提供了两个字段的返回;
key 和 doc_count,如果要自定义这两个基本字段排序方式,需要在前面加上 下划线 _,当然还可以按照其他聚合函数的结果排序
GET bank/_search { "size": 0, "aggs": { "by_age": { "terms": { "field": "age", "size": 1000, "order": { # 数量升序/降序 "_count": "asc/desc" # key 升序/降序 "_key": "asc/desc", # 按平均值升序/降序 "avg_balance":"asc/desc", # 按总金额值升序/降序 "sum_balance":"asc/desc", # 按最大值升序/降序 "max_balance":"asc/desc", } }, "aggs": { "avg_balance": { "avg": { "field": "balance" } }, "sum_balance":{ "sum": { "field": "balance" } }, "max_balance":{ "max": { "field": "balance" } } } } } }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
简单聚合小结
总之,一句话。
分组逻辑在外面的 aggs,使用的是 terms 指定分组字段;默认,附带每个分组内数量统计。
基于此分组的其他聚合运算,aggs 内再定义一个 aggs,用于定义其他聚合运算。
自定义聚合结果排序,在aggs -> terms 下使用 order 指定排序字段及其排序方式,但是,经过测试,直接写多个字段排序时,只有最后一个生效
多字段聚合查询
上面的聚合查询,我们都是基于一个字段进行查询。
那么如何实现按多个字段进行分组呢?
我们先看看,在上面额外聚合运算上使用 terms 的效果
- 先对 age分组,再对gender(文档字段,需使用关键字形式)分组,看看效果
GET bank/_search { "size": 0, "aggs": { "by_age": { "terms": { "field": "age", "size": 1000, "order": { "_count": "desc" } }, "aggs": { "by_gender":{ "terms": { "field": "gender.keyword", "size": 1000 } } } } } }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
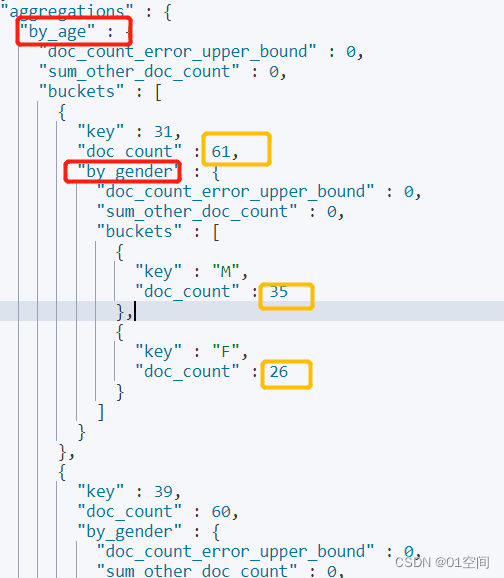
可以看到,得到的结果是一个带有层级结构的数据,这在某些场景下可能有用;但常规的多字段分组可不是这样的,我们通常需要一个扁平化的排序结果
- 使用 script 替代 field ,定义分组字段
script :使用脚本,运算一个结果来作为分组字段。
使用以下 脚本替代 field"script": { "inline": "doc['age'].value +'-'+ doc['gender.keyword'].value " }- 1
- 2
- 3
以上脚本的意思是,使用 age-gender 作为分组依据,注意,这里依然要注意文档字段 .keyword 的问题,以下是完整脚本
# 按多个字段分组,这里按照 年龄-性别 分组,不能直接使用 field 分组,要使用 script 构建分组内容;按默认的数量倒序 GET bank/_search { "size": 0, "aggs": { "by_state": { "terms": { "script": { "inline": "doc['age'].value +'-'+ doc['gender.keyword'].value " }, "size": 1000, "order": { "_count": "desc" } }, "aggs": { "avg_balance": { "avg": { "field": "balance" } }, "sum_balance":{ "sum": { "field": "balance" } }, "max_balance":{ "max": { "field": "balance" } } } } } }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
可以看到,按照预期进行了分组
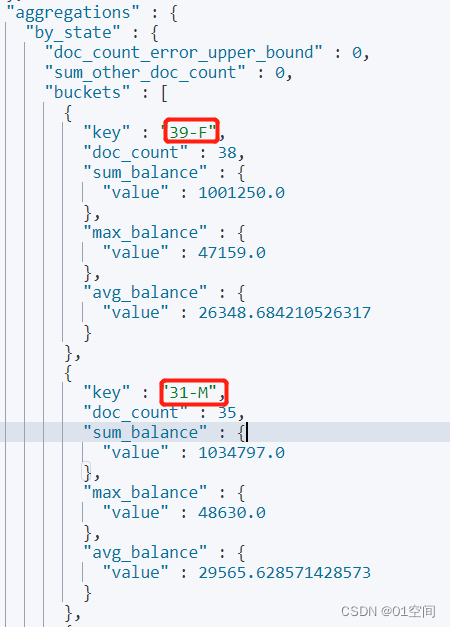
至于基于分组的其他聚合运算,排序等操作,和单字段分组一样。


