
热门标签
热门文章
- 1动态代理没有捕捉到自定义的异常(抛出UndeclaredThrowableException异常)_动态代理抛出自定义异常
- 2(南京观海微电子)——EDP简介_edp接口抗rf干扰
- 3使用Topaz Video Enhance AI进行视频超分辨率_video enhance速度
- 4一根不均匀的绳子,全部烧完需要1个小时,问怎样烧能计时1个小时15分钟(微软的笔试题)_烧一根不均匀的绳子需要一个小时
- 520个主流的代码生成LLM大模型及9种常见应用场景_llm模型
- 6FPGA原理与结构(16)——时钟IP核的使用与测试_clock wizard ip核
- 7一个简单的HTML网页——传统节日春节网页(HTML+CSS)_春节html素材
- 82023 ATT&CK v13版本更新指南_attck
- 9PAT (Basic Level) Practice (中文)-1012-数字分类 (20分)_入包含一个测试用例。每个测试用例先给出一个不超过 1000 的正整数 n 表示月
- 10详解拉东(Radon)变换原理、直线检测、代码实现_radon变换
当前位置: article > 正文
如何爬取小红书文章_爬取小红书标签
作者:Gausst松鼠会 | 2024-02-16 03:58:29
赞
踩
爬取小红书标签
纯技术研究分享
先说思路,正常小红书的文章,如果想通过网页爬取,需要知道文章的id,
例如:‘https://www.xiaohongshu.com/explore/64bbad45000000001700d709’
网页端爬取:
1.思路是通过无头浏览器,利用python就可以模拟账号验证码登录,这个有点麻烦,也可以把二维码截图,拍了发到企业微信(助手)群里,收到的时候扫码(容易封号)登录
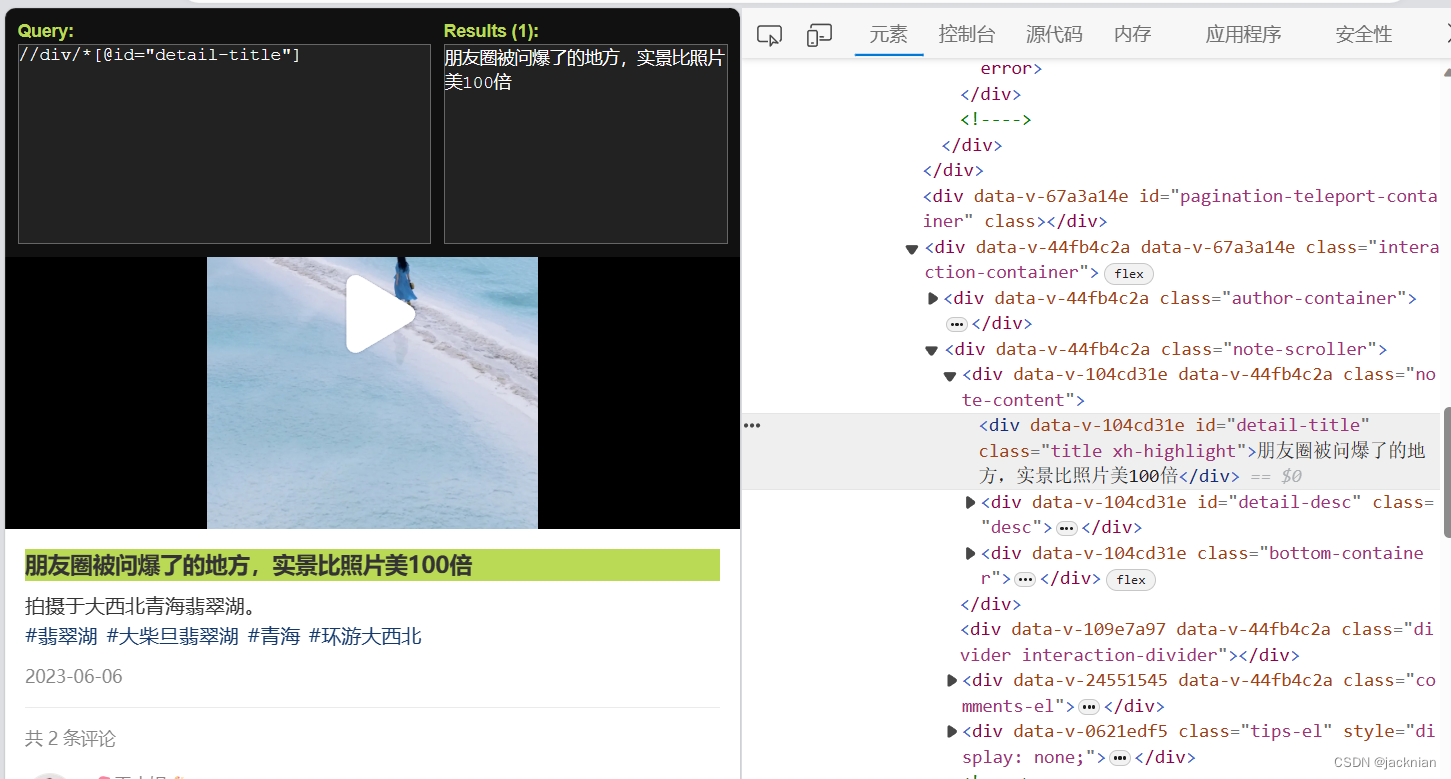
可以用搜索的方式找到你要的文章或者视频资源。
这个是找标题,图片和视频也是类似的方法//div/*[@id="detail-title"]
爬到后就可以自己存入mysql或者mongodb,这里不得不提一下,小红书的图片尽然没加水印,这就造成了很多的原文章被数据公司窃取的风险,最近看到小红书的图片改成webp格式了,估计也快了。
方法2:
用安卓app写一个模拟操作的程序,可以模拟用户登录,然后搜索你要的信息,爬取文章的接口
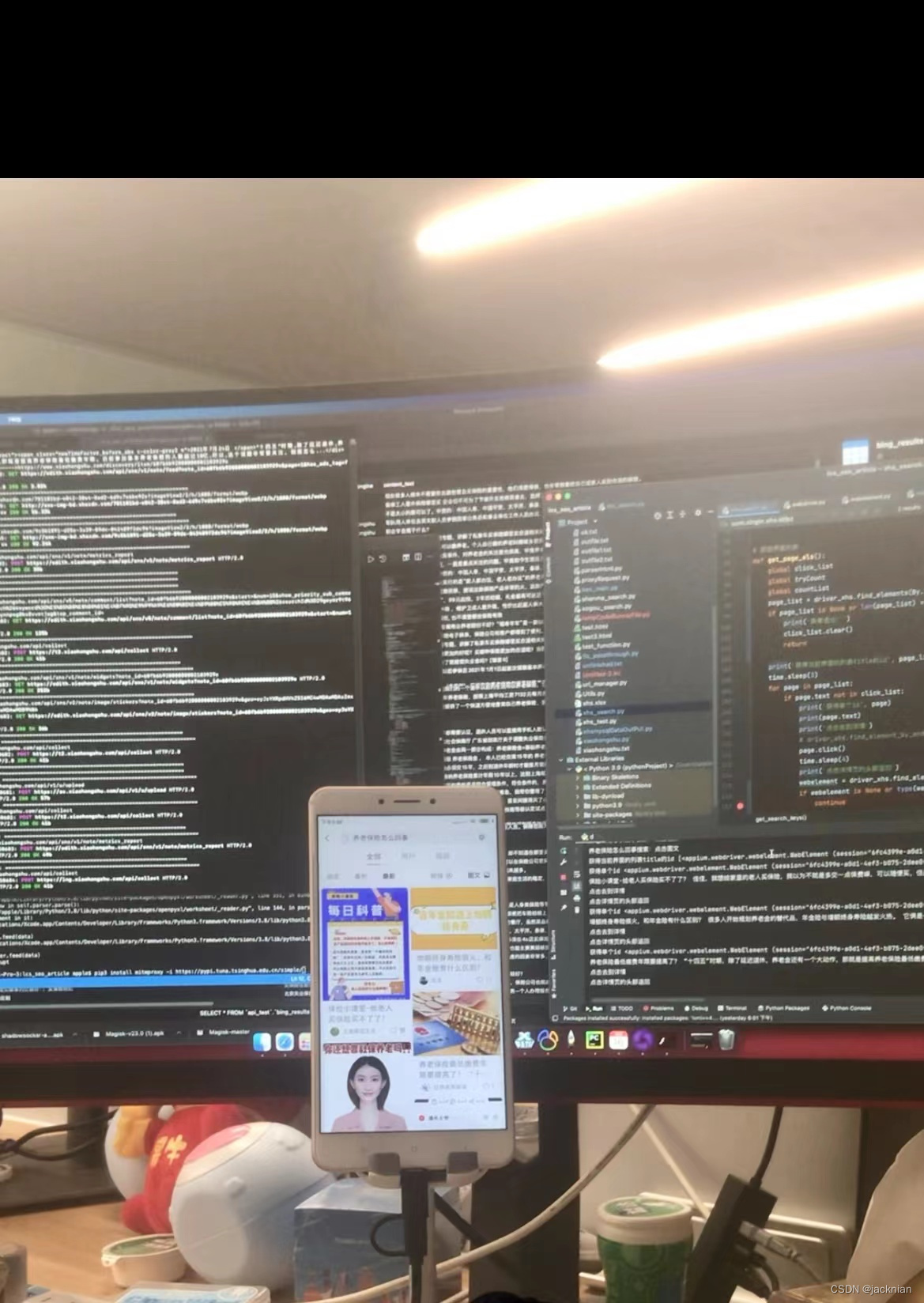
抓安卓的网络包,方法还是python的selenium,webdriver安卓辅助模式,存mysql。都有封号的风险,最好使用代理,切换一下账号。
3.思路三,是用微信小程序的文章列表爬取,这个比较容易点。
以上是目前能用的方式,都有封号的风险,作为技术研究可以交流,商业应用涉及小红书公司信息安全,以上均为学习经验,不要用于商业,不要用于商业,不要用于商业。
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/Gausst松鼠会/article/detail/90530
推荐阅读
相关标签

