
- 12023互联网公司加班时长_计算机行业平均加班时间
- 2OSPF技术连载15:OSPF 数据包的类型、格式和邻居发现的过程_ospf数据包
- 3如何使用Python和大模型进行数据分析和文本生成?_大模型python编译
- 4计算机等级考试-Java考试大纲
- 5git学习笔记 | 版本管理 - 分支管理_git多分支开发版本管理
- 6Mac上使用phpstudy+vscode配置PHP开发环境_phpstudy mac
- 7从车辆工程转行做程序员,我的经历可以给纠结的你一些建议_车辆工程能跳槽软件公司吗
- 8FPGA千兆网口数据传输MDIO接口——FPGA学习笔记3_yt8531sh原理图
- 9视频一键动漫化AI工具DomoAI火了,武打戏各种招式丝滑转换,免费在线可玩_domoai中国版下载
- 10从程序员到项目经理(19):想改变任何人都是徒劳的
五行俱下 – 如何在短时间里遍历 Amazon S3 亿级对象桶(原理篇)
赞
踩

自从 2006 年 Amazon Simple Storage Service (Amazon S3) 发布以来,对象存储已经成为了云计算和互联网的基石,通过 Amazon Pi Day 2023 上披露的数据我们知道 Amazon S3 已经拥有超过 280 万亿个对象,平均每秒超过 1 亿个请求。

为了保护数据完整性,Amazon S3 每秒执行超过 40 亿次校验和计算。多年来,我们添加了许多功能,例如,不断引入新的存储层级,以在满足应用性能要求的前提下,更经济高效的保存各种数据温度的数据。平均每天从 S3 Glacier 灵活检索和 S3 Glacier 深度归档存储层恢复超过 1 PB 的数据。自推出以来,通过使用 Amazon S3 智能分层,我们为客户节省了 10 亿美元。2015 年,我们增加了跨区域复制数据的特性,Amazon S3 复制功能每周都会为客户移动超过 100 PB 的数据。
Amazon S3 也是数十万个数据湖的核心。它也已成为不断发展的无服务器应用程序生态系统的重要组成部分。每天,Amazon S3 都会向无服务器应用程序发送超过 1250 亿条事件通知。总而言之,Amazon S3 正在帮助世界各地的人们安全地存储数据并从数据中提取价值。
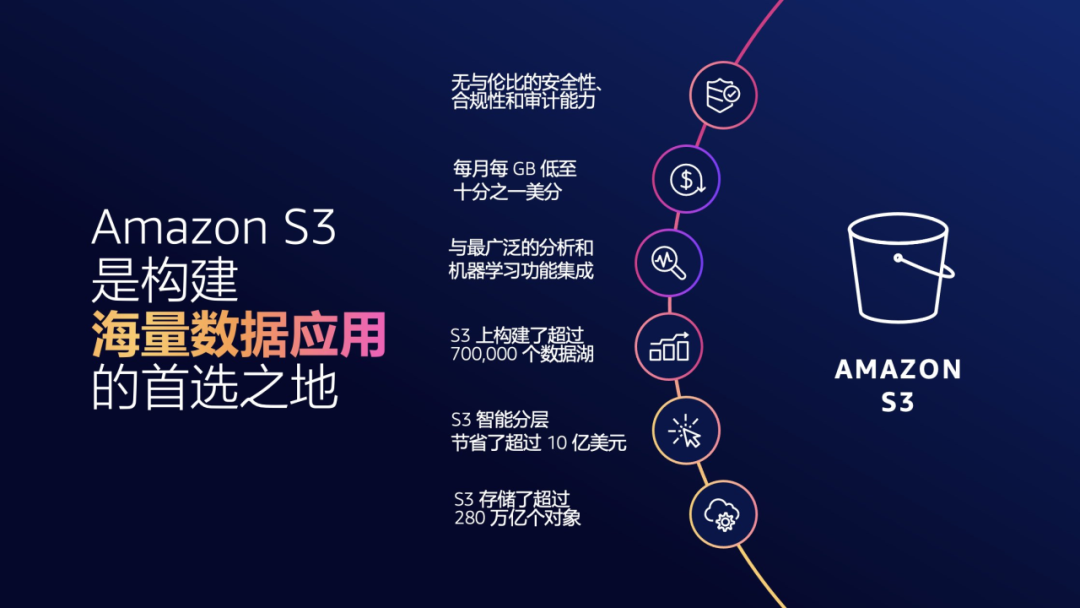
随着我们的客户在 Amazon S3 上存储了越来越多的数据,很多客户在 Amazon S3 存储桶里的数据量已经达到了几十甚至是百 PB 的规模,对象数量也达到了亿级甚至更多。
亿级对象是什么概念?
1 亿个人手拉手站在一起,可以绕地球 4 圈多!

每一份数据都是客户宝贵的资产,如何管理好这么大规模的数据是我们和客户共同的责任。
Amazon S3 提供了很多分析及洞察特性来帮助客户更好的管理数据资产,包括:S3 Storage Lens 存储使用和洞察工具,S3 Inventory 资产清单,S3 Storage Class Analysis 存储层级使用分析工具,S3 CloudWatch 监控指标等。其中,S3 Inventory 是我们用来获取 S3 存储桶里对象清单列表最便捷的方式,S3 Inventory 可以每天或每周提供 S3 存储桶或特定前缀的对象及其相应元数据的报告,为客户进行数据资产盘点提供对象级别的数据支撑。
而在一些特定的场景中,我们希望可以在短时间内获取完整的对象列表:
1、数据迁移上云
数据迁移的场景里, 在迁移过程中、迁移完成后,我们通常希望尽快掌握已经完成数据迁移的对象列表,以准确评估数据迁移的进展,为后续操作提供决策依据。
2、跨桶或跨区域数据复制
Amazon S3 提供了原生的数据复制特性 S3 Replication,可以实现数据在同区域或跨区域之间进行复制。那些被 S3 Replication 规则覆盖的对象可以很放心的交由 S3 的 Replication 来进行纳管实现复制,但同时,我们也需要一些方法来及时发现那些复制规则没有覆盖到的对象,并形成列表,进行后续是否需要进行复制的判断。
3、基础架构管理
许多团队中,基础设施运维与业务应用在工作界面上相互分开。作为使用方,业务应用部门负责构建应用,但在资源使用,销毁等流程上依赖基础设施运维部门来具体执行。而运维部门很难准确把握业务应用在 Amazon S3 上的具体使用细节,在大体量数据的管理中,难免出现一些对象最终变成了管理上的“孤儿”。及时获取对象的详细列表有助于运维和应用部门在资源的管理上达成统一的对话平面。
准实时性:
首先,我们要明确一个概念,在 S3 桶处于“可写入”状态的前提下,我们是很难获取一份时间点一致的完整对象列表的:
1、作为一套超大规模的分布式存储服务,任何获取适当权限的应用和个人都可以从世界任何一个角落,在任何一个时间点在 S3 桶里写入或删除数据。
2、获取对象列表的操作需要一定的时间,在这个时间窗口中的写入或删除操作可能发生在列表操作之后,那么,在列表操作结束以后,相关的对象变更便不会反应在输出的列表中。
3、Amazon S3 已经实现了对象级的强一致性,但在对象桶的对象列表层面,并没有一致性的控制机制,因为那样做可能会大大限制 Amazon S3 的高并发特性。
以上的信息对管理过超大规模文件系统的朋友可谓感同身受,文件数据量达到亿级以后,同样的挑战也出现在文件系统中。
那么,我们能做的事情是使用正确的方式,尽量缩小上面所说的获取对象列表的时间窗口,用最短的时间来获取相对时间点一致的对象列表,既所谓“准实时”的对象列表。
接下去,我们就来探讨一下在短时间里遍历 Amazon S3 亿级对象桶的思路和方法。
对象键和对象元数据:
我们所说的对象列表,不仅仅包括对象名本身,还包括了:
1、Key 对象键
2、ETag 对象实体标签
3、Size 对象大小
4、LastModified 对象创建时间
5、StorageClass 对象存储层
6、Owner 对象拥有者
7、RestoreStatus 对象恢复状态
以上信息描述了存储在 S3 的对象的基本属性,有了这些信息,针对上面提到的使用场景,可以做一些非常有用的事情,比如可以通过对象创建时间确定对象的生成时间,通过对比两个对象的大小及对象实体标签来确定对象的内容是否一致,等等。
Amazon S3 上没有传统文件系统目录的概念,对象键由如下组成:
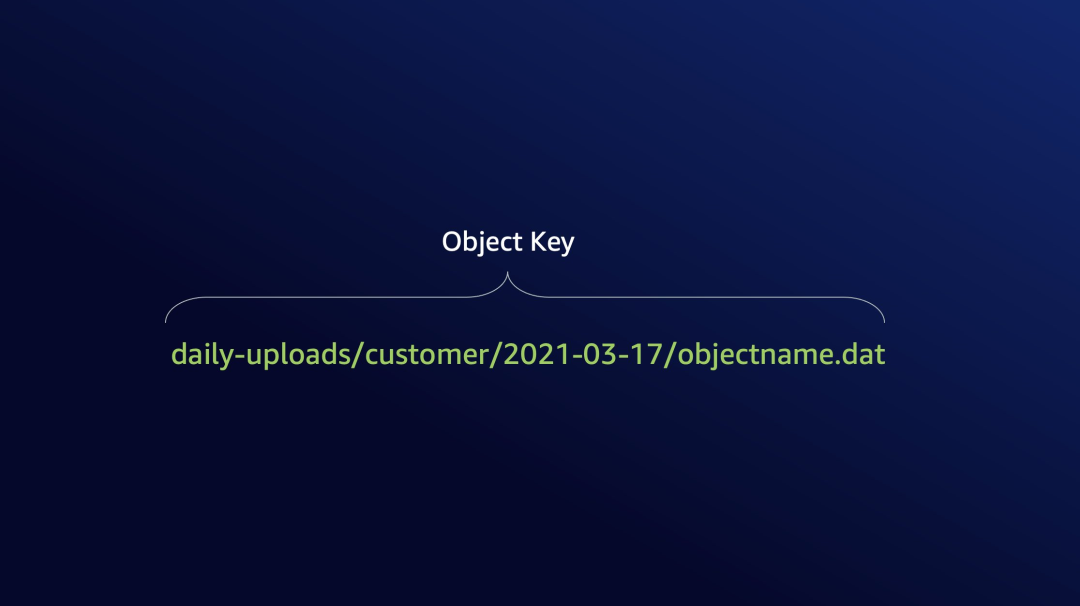
Object Key 即对象键(以下用 Object Key 指代对象键)是 Unicode 字符序列,采用 UTF-8 编码,长度最大为 1,024 字节,对象键名称区分大小写。
Amazon S3 对象存储本质上是一套基于键值的存储系统,任何一个对象都可以通过对象键来进行唯一的定位。
ListObjectsV2 API
Amazon S3 提供了 ListObjectsV2 API 来获取对象的列表,ListObjectsV2 的主要使用逻辑如下:
1、每次调用最多返回 1000 个对象
2、通过 start-after 指定返回对象列表的起始 Object Key(但不包括这个 Object Key 本身)
3、实现分页的机制,通过 ContinuationToken 获取下一页的对象列表
初步测算一下,如果我们有一个包含 1 亿个对象的 S3 存储桶,通过互联网调用 ListObjectsV2 API 来获取对象列表,假设每次 API 请求的响应时间为 100 毫秒,每次返回 1000 个对象,那么通过 ListObjectsV2 的分页机制依次按页获取完整1亿个对象列表所需的时间预估如下:
(对象总数 / 每次最大返回)x 每次 API 时间 = (100,000,000 / 1000)x 0.1 = 10,000 秒
大约需要 2.7 小时的时间窗口,所以,我们可以更快吗?
并发访问
显然 2.7 小时在某些场景下还是不能接受的,那么,我们尝试进化一下我们的对象列表获取策略。
在以前的博客里我们曾经介绍过,Amazon S3 作为一个超大规模的分布式存储服务,可以提供很高的并发访问能力,只要您遵循了 Amazon S3 的使用最佳实践,对任何单体客户来说, Amazon S3 都可以提供无限的访问性能和存储容量。
以顺序方式调用:
ListObjectsV2 API 的时间为 10,000 秒
如果我们实现 10 个并发操作:
ListObjectsV2 API 时间就能缩短到 1,000 秒
以此类推,100 个并发:
ListObjectsV2 API 的完成时间 100 秒
燃!100 秒钟获得 1 亿个对象列表能够解决很多问题,符合绝大部分场景的要求。
当然你可能可以使用更大的并发:
1000 个并发 ListObjectsV2 API,完成时间 10 秒
几乎可以达到近实时的效果了。
那么如何实现 ListObjectsV2 的并发操作呢?
名字空间
我们回到 Amazon S3 的基本性质上来,官方文档明确指出 ListObjectsV2 操作的结果是按 UTF-8 的二进制来排序的: “List results are always returned in UTF-8 binary order“ ,即我们通常所说的字典顺序 lexicographical order。
用一个简单的例子来表示,如果我们的桶里如果有以下 5 个对象:
- sample.jpg
- photos/2006/January/sample.jpg
- photos/2006/February/sample2.jpg
- photos/2006/February/sample3.jpg
- photos/2006/February/sample4.jpg
猜一猜 API 返回的对象列表是怎样的?我们使用 Amazon CLI 来进行操作:
- $ aws s3api list-objects-v2 --bucket <BUCKET>
-
-
- {
- "Contents": [
- {
- "Key": "photos/2006/February/sample2.jpg",
- "LastModified": "2023-11-11T06:13:13+00:00",
- "ETag": "\"d41d8cd98f00b204e9800998ecf8427e\"",
- "Size": 0,
- "StorageClass": "STANDARD"
- },
- {
- "Key": "photos/2006/February/sample3.jpg",
- "LastModified": "2023-11-11T06:13:13+00:00",
- "ETag": "\"d41d8cd98f00b204e9800998ecf8427e\"",
- "Size": 0,
- "StorageClass": "STANDARD"
- },
- {
- "Key": "photos/2006/February/sample4.jpg",
- "LastModified": "2023-11-11T06:13:13+00:00",
- "ETag": "\"d41d8cd98f00b204e9800998ecf8427e\"",
- "Size": 0,
- "StorageClass": "STANDARD"
- },
- {
- "Key": "photos/2006/January/sample.jpg",
- "LastModified": "2023-11-11T06:13:13+00:00",
- "ETag": "\"d41d8cd98f00b204e9800998ecf8427e\"",
- "Size": 0,
- "StorageClass": "STANDARD"
- },
- {
- "Key": "sample.jpg",
- "LastModified": "2023-11-11T06:13:13+00:00",
- "ETag": "\"d41d8cd98f00b204e9800998ecf8427e\"",
- "Size": 0,
- "StorageClass": "STANDARD"
- }
- ]
- }

返回对象的顺序为:
- photos/2006/February/sample2.jpg
- photos/2006/February/sample3.jpg
- photos/2006/February/sample4.jpg
- photos/2006/January/sample.jpg
- sample.jpg
结果超出想象,但符合预期,每次返回的列表都会按字母字典顺序排序:
p* 打头的 Object Key 永远优先于 s* 打头的 Object Key 返回
photos/2006/F* 打头的 Object Key 优先于 photos/2006/J* 打头的 Object Key 返回
但不管怎样,在这个简单的场景中,一次 API 完整地取回了 5 个对象的列表,您可以在获取对象列表后按照自己的逻辑顺序再进行排序。
接下去,我们扩展到更复杂的场景,如果我们的桶里有 1004 个对象:
- sample.jpg
- photos/2006/January/1/sample.jpg
- photos/2006/January/2/sample.jpg
- ...
- photos/2006/January/999/sample.jpg
- photos/2006/January/1000/sample.jpg
- photos/2006/February/sample2.jpg
- photos/2006/February/sample3.jpg
- photos/2006/February/sample4.jpg
那么猜一猜这一次 List API 会怎么返回?
$ aws s3api list-objects-v2 --bucket <BUCKET> --no-paginate第一次 List API 会按字母顺序返回如下列表, 并返回一个 NextContinuationToken
- photos/2006/February/sample2.jpg
- photos/2006/February/sample3.jpg
- photos/2006/February/sample4.jpg
- photos/2006/January/1/sample.jpg
- photos/2006/January/10/sample.jpg
- photos/2006/January/100/sample.jpg
- photos/2006/January/1000/sample.jpg
- photos/2006/January/101/sample.jpg
- photos/2006/January/102/sample.jpg
- ...
- photos/2006/January/994/sample.jpg
- photos/2006/January/995/sample.jpg
- photos/2006/January/996/sample.jpg
-
-
- $ aws s3api list-objects-v2 --bucket <BUCKET> --starting-token <NextContinuationToken>
第二次 List API 使用第一次调用返回的 NextContinuationToken,作为 ContinuationToken 参数(Amazon CLI 的参数为–starting-token)的输入值,会返回剩余的 4 个对象:
- photos/2006/January/997/sample.jpg
- photos/2006/January/998/sample.jpg
- photos/2006/January/999/sample.jpg
- sample.jpg
以此类推,任何对象数量的存储桶都可以使用 ListObjectsV2 API 的分页机制来依次顺序获取完整的对象列表,
但分页机制的局限性在于:下一个请求的输入参数 ContinuationToken 依赖于上一个请求的输出 NextContinuationToken。
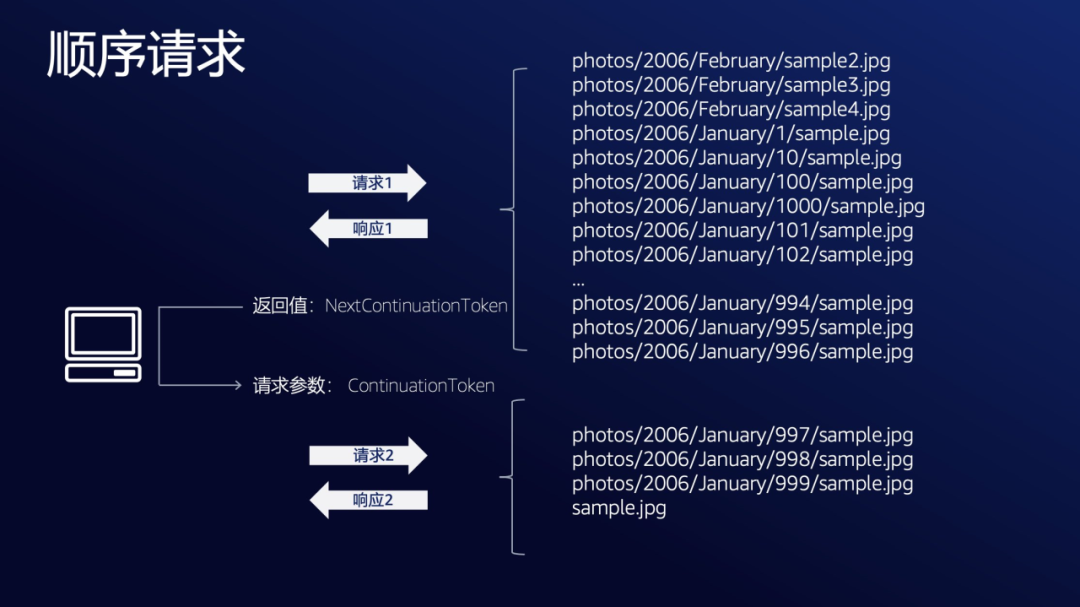
那么,以上顺序执行的 API 能否实现并行化改造呢?
为了实现并发,让两个 ListObjectsV2 API 可以同时发起请求, 我们把第二个 API 的执行参数做一下改造。
请求 1:
$ aws s3api list-objects-v2 --bucket <BUCKET> --no-paginate请求 2:
- $ aws s3api list-objects-v2 --bucket <BUCKET> --start-after "photos/2006/January/996/sample.jpg"
- {
- "Contents": [
- {
- "Key": "photos/2006/January/997/sample.jpg",
- "LastModified": "2023-11-11T06:02:13+00:00",
- "ETag": "\"d41d8cd98f00b204e9800998ecf8427e\"",
- "Size": 0,
- "StorageClass": "STANDARD"
- },
- {
- "Key": "photos/2006/January/998/sample.jpg",
- "LastModified": "2023-11-11T06:02:13+00:00",
- "ETag": "\"d41d8cd98f00b204e9800998ecf8427e\"",
- "Size": 0,
- "StorageClass": "STANDARD"
- },
- {
- "Key": "photos/2006/January/999/sample.jpg",
- "LastModified": "2023-11-11T06:02:13+00:00",
- "ETag": "\"d41d8cd98f00b204e9800998ecf8427e\"",
- "Size": 0,
- "StorageClass": "STANDARD"
- },
- {
- "Key": "sample.jpg",
- "LastModified": "2023-11-11T06:03:48+00:00",
- "ETag": "\"d41d8cd98f00b204e9800998ecf8427e\"",
- "Size": 0,
- "StorageClass": "STANDARD"
- }
- ]
- }
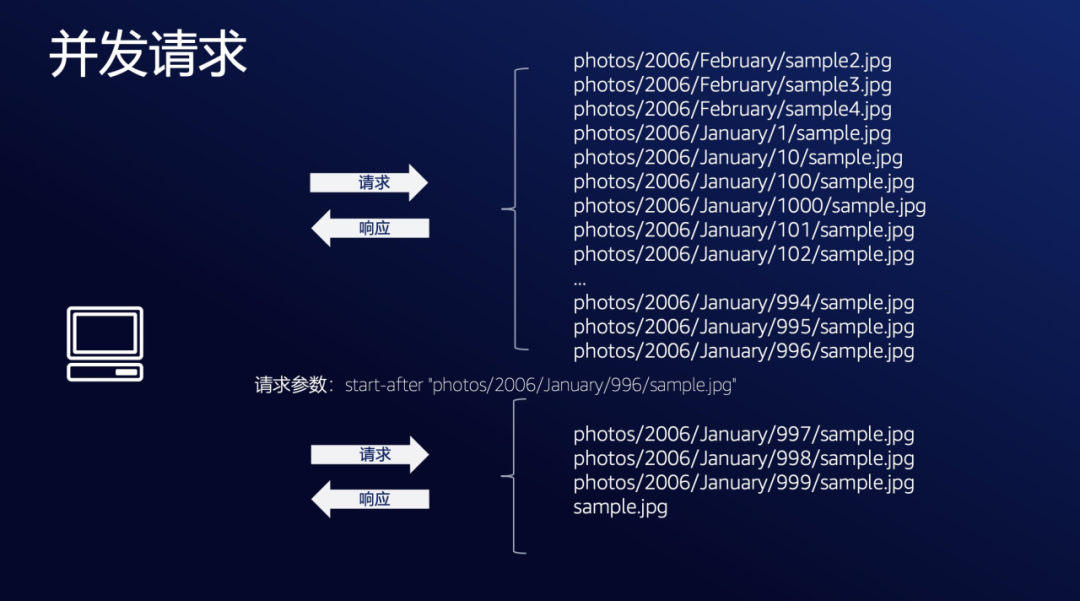
返回符合预期,使用 start-after 参数,我们把两个顺序执行的 API 变成了无相互依赖,可并执行的版本,但你可能会问,我怎么能正好知道请求 2 的起始 Object Key 应该是" photos/2006/January/996/sample.jpg "呢?
好吧,对于一个无时不刻不在新增和删除的 S3 对象桶来说,这个的确很难。
那么我们继续改造请求 2:
- $ aws s3api list-objects-v2 --bucket <BUCKET> --start-after "photos/2006/January/997"
- {
- "Contents": [
- {
- "Key": "photos/2006/January/997/sample.jpg",
- "LastModified": "2023-11-11T06:02:13+00:00",
- "ETag": "\"d41d8cd98f00b204e9800998ecf8427e\"",
- "Size": 0,
- "StorageClass": "STANDARD"
- },
- {
- "Key": "photos/2006/January/998/sample.jpg",
- "LastModified": "2023-11-11T06:02:13+00:00",
- "ETag": "\"d41d8cd98f00b204e9800998ecf8427e\"",
- "Size": 0,
- "StorageClass": "STANDARD"
- },
- {
- "Key": "photos/2006/January/999/sample.jpg",
- "LastModified": "2023-11-11T06:02:13+00:00",
- "ETag": "\"d41d8cd98f00b204e9800998ecf8427e\"",
- "Size": 0,
- "StorageClass": "STANDARD"
- },
- {
- "Key": "sample.jpg",
- "LastModified": "2023-11-11T06:03:48+00:00",
- "ETag": "\"d41d8cd98f00b204e9800998ecf8427e\"",
- "Size": 0,
- "StorageClass": "STANDARD"
- }
- ]
- }
这次依然返回了最后 4 个对象,但这一次难度降低了很多,我们不需要知道具体的确切的对象名,只需要提供可能的切分点就能达到并发执行的效果。
结论:
以上便是利用 ListObjectsV2 API 实现对 S3 桶并发访问来获取对象列表的核心思路:使用 Amazon S3 ListObjectsV2 API 的 start-after 参数来解偶顺序执行的调用,达到并发执行的目的。
如上所述,理论上,只要我们能够把 S3 存储桶的 Object Key 空间切分得足够细,就可以实现更大的并发,进而可以用更短的时间获取 S3 桶里所有对象的列表。
但是实际的情况远比我们上面的这个例子要复杂得多,现实中我们必须要面对:
1、S3 桶里的对象在不断地新建和删除,因此整个桶的 Object Key 空间在不断的变化中,如何来对亿级对象桶的 Object Key 空间来进行切分 ?
2、实际生产的 S3 存储桶的 Object Key 空间并不会按字母顺序分布,存在热点的前缀;在诸如数据湖的场景中,一个统一的前缀下可能存在巨大的分支,这样的实际场景该如何来处理?
3、当我们讨论亿级对象的列表就必须要考虑到数据量,按一个对象的元数据保守估算需要 100 个字节来计算,1 亿个对象需要 9.3GiB 的空间,如何解决最终结果在短时间里持久化的问题?
4、理论上我们可以通过横向扩展来提高并发度,但更高的并发度意味着更复杂的控制流程和更多的资源投入,而获取对象列表的场景更多时候希望快速且灵活,我们应该如何在高并发和灵活性上实现权衡取舍?
带着以上这些问题,我们会在下一篇博客中介绍快速遍历亿级对象工具的具体实现,敬请关注。
本篇作者

戴逸洋
亚马逊云科技数据存储资深架构师,致力于推广存储技术在云上的各种最佳实践。

方浩
亚马逊云科技 Startup 团队解决方案架构师,致力于云计算、大数据技术在初创企业中的推广。拥有近二十年的 IT 从业经验。加入亚马逊云科技之前,在驻云科技担任高级解决方案架构师和大数据架构师。更早以前,在多家创业公司担任分公司经理一职。

陈超
亚马逊云科技资深解决方案架构师,主要负责迁移相关的技术支持工作,同时致力于亚马逊云服务在国内的应用及推广。加入亚马逊云科技之前,曾在阿里巴巴工作 8 年,历任研发工程师、云计算解决方案架构师等,熟悉传统企业 IT、互联网架构,在企业应用架构方面有多年实践经验。

李佳
亚马逊云科技快速原型解决方案研发架构师,主要负责微服务与容器原型设计与研发。

星标不迷路,开发更极速!
关注后记得星标「亚马逊云开发者」

听说,点完下面4个按钮
就不会碰到bug了!


