
- 1手机运营商二要素验证接口:确保业务操作安全可靠_手机运营商二要素验证接口:确保业务操作安全可靠
- 2树莓派4的串口启用设置_atmel 4串口
- 3Vue前端自动化测试-Vue Test Utils
- 4HBase 配置文件
- 5多模态大模型:技术原理与实战 大模型在软件研发领域的实战案例与前沿探索
- 6全球人工智能产业链&产业图谱
- 7ShardingSphere分库分表核心原理精讲第六节 分布式主键和解析引擎
- 8unity 2d个人学习手册_unity 2d教程
- 9python基础知识_如何在cmd写python代码
- 10记录:Unity 2019.2.1f1版本打包报错UnityException: SDK Tools version 25.2.5 < 26.1.1.解决方法
TreeSet解析
赞
踩
目录
(2)实现Comparable接口,覆写compareTo()方法
2、 HashSet、LinkedHashSet 以及 TreeSet。
一、TreeSet介绍
TreeSet是一个有序的集合,基于TreeMap实现,支持两种排序方式:自然排序和定制排序。
TreeSet是非同步的,线程不安全的。
二、源码分析
1、TreeSet实现的接口
如下图:
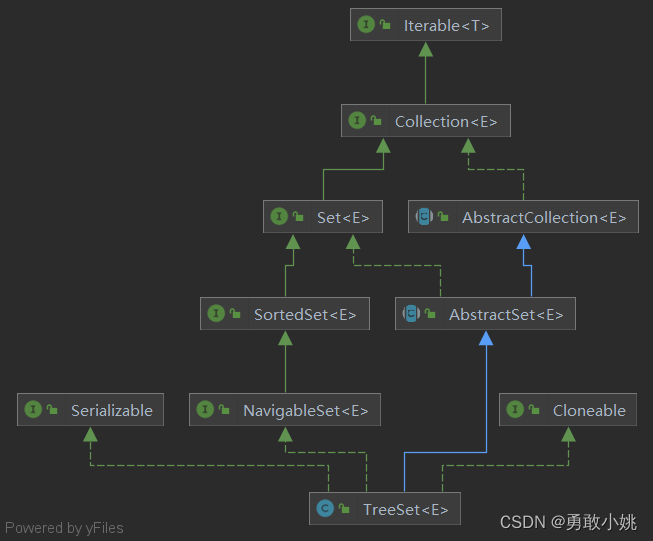
观察上图:
- AbstractSet类:该类提供了Set接口的骨架实现,通过扩展此类来实现集合的过程与通过扩展AbstractCollection实现集合的过程相同,除了此类的子类中的所有方法和构造函数都必须遵守由Set接口施加的附加约束(例如,添加方法不能允许将一个对象的多个实例添加到集合中)。
- Navigable接口:支持一系列的导航方法。比如查找与指定目标最匹配项。
- Serializable接口:主要用于序列化,即:能够将对象写入磁盘。与之对应的还有反序列化操作,就是将对象从磁盘中读取出来。因此如果要进行序列化和反序列化,ArrayList的实例对象就必须实现这个接口,否则在实例化的时候程序会报错(java.io.NotSerializableException)。
- Cloneable接口:实现Cloneable接口的类能够调用clone方法,如果没有实现Cloneable接口就调用方法,就会抛出异常(java.lang.CloneNotSupportedException)。
2、TreeSet中的变量
- private transient NavigableMap<E,Object> m:存放元素的集合
- private static final Object PRESENT = new Object():常量,构造一个虚拟的对象PRESENT,默认为map的value值(HashSet中只需要用到键,而HashMap是key-value键值对,使用PRESENT作为value的默认填充值,解决差异问题)
3、TreeSet的构造方法
(1)同包下的构造方法
- TreeSet(NavigableMap<E,Object> m) {
- this.m = m;
- }
(2)无参构造方法
- public TreeSet() {
- this(new TreeMap<E,Object>());
- }
(3)带比较器的构造方法
- public TreeSet(Comparator<? super E> comparator) {
- this(new TreeMap<>(comparator));
- }
(4)带集合参数的构造方法
- public TreeSet(Collection<? extends E> c) {
- this();
- addAll(c);
- }
(5)带SortMap的构造方法
- public TreeSet(SortedSet<E> s) {
- this(s.comparator());
- addAll(s);
- }
通过上面的构造方法,可以看出TreeSet的底层是用TreeMap实现的。在构造方法中会创建一个TreeMap实例,用于存放元素,另外TreeSet是有序的,也提供了制定比较器的构造函数,如果没有提供比较器,则采用key的自然顺序进行比较大小,如果指定的比较器,则采用指定的比较器,进行key值大小的比较。
4、常用方法
- //遍历方法,返回m.keyset集合
- public Iterator<E> iterator() {
- return m.navigableKeySet().iterator();
- }
-
- //逆序排序的迭代器
- public Iterator<E> descendingIterator() {
- return m.descendingKeySet().iterator();
- }
-
- /**
- * @since 1.6
- */
- public NavigableSet<E> descendingSet() {
- return new TreeSet<>(m.descendingMap());
- }
-
- //返回 m 包含的键值对的数量
- public int size() {
- return m.size();
- }
-
- //是否为空
- public boolean isEmpty() {
- return m.isEmpty();
- }
-
- //是否包含指定的key
- public boolean contains(Object o) {
- return m.containsKey(o);
- }
-
- //添加元素,调用m.put方法实现
- public boolean add(E e) {
- return m.put(e, PRESENT)==null;
- }
-
- //删除方法,调用m.remove()方法实现
- public boolean remove(Object o) {
- return m.remove(o)==PRESENT;
- }
-
- //清除集合
- public void clear() {
- m.clear();
- }
-
- //将一个集合中的所有元素添加到TreeSet中
- public boolean addAll(Collection<? extends E> c) {
- // Use linear-time version if applicable
- if (m.size()==0 && c.size() > 0 &&
- c instanceof SortedSet &&
- m instanceof TreeMap) {
- SortedSet<? extends E> set = (SortedSet<? extends E>) c;
- TreeMap<E,Object> map = (TreeMap<E, Object>) m;
- Comparator<? super E> cc = (Comparator<? super E>) set.comparator();
- Comparator<? super E> mc = map.comparator();
- if (cc==mc || (cc != null && cc.equals(mc))) {
- map.addAllForTreeSet(set, PRESENT);
- return true;
- }
- }
- return super.addAll(c);
- }
-
- //返回子集合,通过 m.subMap()方法实现
- public NavigableSet<E> subSet(E fromElement, boolean fromInclusive,
- E toElement, boolean toInclusive) {
- return new TreeSet<>(m.subMap(fromElement, fromInclusive,
- toElement, toInclusive));
- }
-
- //返回set的头部
- public NavigableSet<E> headSet(E toElement, boolean inclusive) {
- return new TreeSet<>(m.headMap(toElement, inclusive));
- }
-
- //返回尾部
- public NavigableSet<E> tailSet(E fromElement, boolean inclusive) {
- return new TreeSet<>(m.tailMap(fromElement, inclusive));
- }
-
- //返回子Set
- public SortedSet<E> subSet(E fromElement, E toElement) {
- return subSet(fromElement, true, toElement, false);
- }
-
- //返回set的头部
- public SortedSet<E> headSet(E toElement) {
- return headSet(toElement, false);
- }
-
- //返回set的尾部
- public SortedSet<E> tailSet(E fromElement) {
- return tailSet(fromElement, true);
- }
- //返回m使用的比较器
- public Comparator<? super E> comparator() {
- return m.comparator();
- }
-
- //返回第一个元素
- public E first() {
- return m.firstKey();
- }
- //返回最后一个元素
- public E last() {
- return m.lastKey();
- }
-
- //返回set中小于e的最大的元素
- public E lower(E e) {
- return m.lowerKey(e);
- }
-
- //返回set中小于/等于e的最大元素
- public E floor(E e) {
- return m.floorKey(e);
- }
-
- //返回set中大于/等于e的最大元素
- public E ceiling(E e) {
- return m.ceilingKey(e);
- }
-
- //返回set中大于e的最小元素
- public E higher(E e) {
- return m.higherKey(e);
- }
-
- //获取TreeSet中第一个元素,并从Set中删除该元素
- public E pollFirst() {
- Map.Entry<E,?> e = m.pollFirstEntry();
- return (e == null) ? null : e.getKey();
- }
-
- //获取TreeSet中最后一个元素,并从Set中删除该元素
- public E pollLast() {
- Map.Entry<E,?> e = m.pollLastEntry();
- return (e == null) ? null : e.getKey();
- }
-
- //克隆方法
- public Object clone() {
- TreeSet<E> clone = null;
- try {
- clone = (TreeSet<E>) super.clone();
- } catch (CloneNotSupportedException e) {
- throw new InternalError();
- }
-
- clone.m = new TreeMap<>(m);
- return clone;
- }
-
- //将对象写入到输出流中。
- private void writeObject(java.io.ObjectOutputStream s)
- throws java.io.IOException {
- // Write out any hidden stuff
- s.defaultWriteObject();
-
- // Write out Comparator
- s.writeObject(m.comparator());
-
- // Write out size
- s.writeInt(m.size());
-
- // Write out all elements in the proper order.
- for (E e : m.keySet())
- s.writeObject(e);
- }
-
- //从输入流中读取对象的信息
- private void readObject(java.io.ObjectInputStream s)
- throws java.io.IOException, ClassNotFoundException {
- // Read in any hidden stuff
- s.defaultReadObject();
-
- // Read in Comparator
- Comparator<? super E> c = (Comparator<? super E>) s.readObject();
-
- // Create backing TreeMap
- TreeMap<E,Object> tm;
- if (c==null)
- tm = new TreeMap<>();
- else
- tm = new TreeMap<>(c);
- m = tm;
-
- // Read in size
- int size = s.readInt();
-
- tm.readTreeSet(size, s, PRESENT);
- }

5、TreeSet的两种排序方式
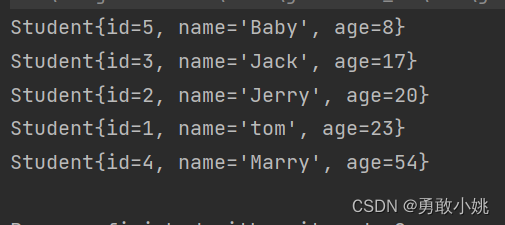
(1)实现Comparator接口,重写compare方法
-
- import java.util.*;
-
- class Student{
- private int id;
- private String name;
- private int age;
-
- public Student(int id, String name, int age) {
- this.id = id;
- this.name = name;
- this.age = age;
- }
-
- public int getId() {
- return id;
- }
-
- public void setId(int id) {
- this.id = id;
- }
-
- public String getName() {
- return name;
- }
-
- public void setName(String name) {
- this.name = name;
- }
-
- public int getAge() {
- return age;
- }
-
- public void setAge(int age) {
- this.age = age;
- }
-
- @Override
- public String toString() {
- return "Student{" +
- "id=" + id +
- ", name='" + name + '\'' +
- ", age=" + age +
- '}';
- }
- }
- class MyComparator implements Comparator{
-
- @Override
- public int compare(Object o1, Object o2) {
- Student s1 = (Student) o1;
- Student s2 = (Student) o2;
- return s1.getAge() - s2.getAge();
- }
- }
- public class Main {
- public static void main(String[] args) {
- TreeSet treeSet = new TreeSet(new MyComparator());
- treeSet.add(new Student(1, "tom", 23));
- treeSet.add(new Student(2, "Jerry", 20));
- treeSet.add(new Student(3, "Jack", 17));
- treeSet.add(new Student(4, "Marry", 54));
- treeSet.add(new Student(5, "Baby", 8));
- Iterator iterator = treeSet.iterator();
- while(iterator.hasNext()){
- System.out.println(iterator.next());
- }
-
- }
- }
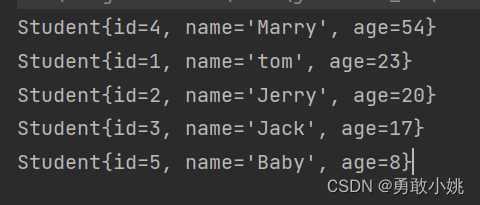
(2)实现Comparable接口,覆写compareTo()方法
- import java.util.*;
-
- class Student implements Comparable{
- private int id;
- private String name;
- private int age;
-
- public Student(int id, String name, int age) {
- this.id = id;
- this.name = name;
- this.age = age;
- }
-
- public int getId() {
- return id;
- }
-
- public void setId(int id) {
- this.id = id;
- }
-
- public String getName() {
- return name;
- }
-
- public void setName(String name) {
- this.name = name;
- }
-
- public int getAge() {
- return age;
- }
-
- public void setAge(int age) {
- this.age = age;
- }
-
- @Override
- public String toString() {
- return "Student{" +
- "id=" + id +
- ", name='" + name + '\'' +
- ", age=" + age +
- '}';
- }
-
- @Override
- public int compareTo(Object o) {
- if(!(o instanceof Student)){
- throw new RuntimeException("对象有问题");
- }
- Student s = (Student) o;
- if(this.age > s.age){
- return -1;
- }else{
- return 1;
- }
- }
- }
-
- public class Main {
- public static void main(String[] args) {
- TreeSet treeSet = new TreeSet();
- treeSet.add(new Student(1, "tom", 23));
- treeSet.add(new Student(2, "Jerry", 20));
- treeSet.add(new Student(3, "Jack", 17));
- treeSet.add(new Student(4, "Marry", 54));
- treeSet.add(new Student(5, "Baby", 8));
- Iterator iterator = treeSet.iterator();
- while(iterator.hasNext()){
- System.out.println(iterator.next());
- }
-
- }
- }
三、总结
1、TreeSet总结
- TreeSet实际上是TreeMap实现的,所以底层结构也是红黑树。TreeSet不需要重写hashCode()和euqals()方法,因为它去重是依靠比较器来去重,因为结构是红黑树,所以每次插入都会遍历比较来寻找节点插入位置,如果发现某个节点的值是一样的那就会直接覆盖。
- 当我们构造TreeSet时;若使用不带参数的构造函数,则TreeSet的使用自然比较器;若用户需要使用自定义的比较器,则需要使用带比较器的参数。
- TreeSet是非线程安全的。
- TreeSet实现java.io.Serializable的方式。当写入到输出流时,依次写入“比较器、容量、全部元素”;当读出输入流时,再依次读取。
2、 HashSet、LinkedHashSet 以及 TreeSet。
(1)HashSet
- 不能保证元素的排列顺序,顺序有可能发生变化
- 不是同步的,非线程安全
- 集合元素可以是null,但只能放入一个null
- 当向HashSet结合中存入一个元素时,HashSet会调用该对象的hashCode()方法来得到该对象的hashCode值,然后根据 hashCode值来决定该对象在HashSet中存储位置。
- 简单的说,HashSet集合判断两个元素相等的标准是两个对象通过equals方法比较相等,并且两个对象的hashCode()方法返回值相等
- 注意,如果要把一个对象放入HashSet中,重写该对象对应类的equals方法,也应该重写其hashCode()方法。其规则是如果两个对象通过equals方法比较返回true时,其hashCode也应该相同。另外,对象中用作equals比较标准的属性,都应该用来计算hashCode的值。
(2)LinkedHashSet
LinkedHashSet集合同样是根据元素的hashCode值来决定元素的存储位置,但是它同时使用链表维护元素的次序。这样使得元素看起 来像是以插入顺序保存的,也就是说,当遍历该集合时候,LinkedHashSet将会以元素的添加顺序访问集合的元素。
- LinkedHashSet中不能有相同元素,可以有一个Null元素,元素严格按照放入的顺序排列。
- LinkedHashSet底层数据结构由哈希表和链表组成,链表保证了元素的有序即存储和取出一致,哈希表保证了元素的唯一性。
- LinkedHashSet添加、删除操作时间复杂度都是O(1)。
(3)TreeSet
- TreeSet支持两种排序方式,自然排序 和定制排序,其中自然排序为默认的排序方式。向TreeSet中加入的应该是同一个类的对象。
- TreeSet判断两个对象不相等的方式是两个对象通过equals方法返回false,或者通过CompareTo方法比较没有返回0
- TreeSet是中不能有相同元素,不可以有Null元素,根据元素的自然顺序进行排序。
- TreeSet底层的数据结构是红黑树(一种自平衡二叉查找树)
- 添加、删除操作时间复杂度都是O(log(n))
(4)使用场景
HashSet是基于Hash算法实现的,其性能通常都优于TreeSet。我们通常都应该使用HashSet,在我们需要排序的功能时,我们才使用TreeSet。
(5)对象的加入过程
TreeSet集合对象的加入过程:
TreeSet的底层是通过二叉树来完成存储的,无序的集合
当我们将一个对象加入treeset中,treeset会将第一个对象作为根对象,然后调用对象的compareTo方法拿第二个对象和第一个比较,当返回值等于0时,说明2个对象内容相等,treeset就不把第二个对象加入集合。返回>1时,说明第二个对象大于第一个对象,将第二个对象放在右边,返回-1时,则将第二个对象放在左边,依次类推 。
HashSet集合对象的加入过程:
hashset底层是hash值的地址,它里面存的对象是无序的。
第一个对象进入集合时,hashset会调用object类的hashcode根据对象在堆内存里的地址调用对象重写的hashcode计算出一个hash值,然后第一个对象就进入hashset集合中的任意一个位置。
第二个对象开始进入集合,hashset先根据第二个对象在堆内存的地址调用对象的计算出一个hash值,如果第二个对象和第一个对象在堆内存里的地址是相同的,那么得到的hash值也是相同的,直接返回true,hash得到true后就不把第二个元素加入集合(这段是hash源码程序中的操作)。如果第二个对象和第一个对象在堆内存里地址是不同的,这时hashset类会先调用自己的方法遍历集合中的元素,当遍历到某个元素时,调用对象的equals方法,如果相等,返回true,则说明这两个对象的内容是相同的,hashset得到true后不会把第二个对象加入集合。

