
- 1Hadoop较全面的概述_hadoop2.0改进与提升hadoop1.0版本与hadoop2.0版本的区别组件hadoop1.
- 2python语言程序设计 答案,python程序设计教程题库_根据圆半径计算圆面积,此题目是自动批阅类型,请注意:获得输入使用input
- 3毕业设计:python汽车销售数据爬取分析可视系统 Flask框架 requests爬虫 Echarts可视化(源码)✅_销售数据分析系统
- 4苹果电脑能玩赛博朋克2077吗 如何在mac上运行赛博朋克2077 crossover能玩什么游戏
- 5大数据与人工智能_人工智能及大数据应用人力架构
- 6文献学习-36-自主缝合的现状:系统综述_伯克利大学 自主手术
- 7[学习][笔记]设计模式(基于C/C++实现)<七>桥接模式_c 实现网口桥接
- 8《我的阿勒泰》观后感(一、什么叫做有用)_我的阿勒泰观后感800字作文
- 9关于对正则表达式中\b单词边界的理解_单词边界是什么意思
- 10RAG进阶(一): 多重查询(Multi Query)_multi-query
微软推出的ReCall历史记录AI搜索你会用吗?开源开箱即用RAG-Verba;从零开始实现Llama3_微软recall实现方案
赞
踩
✨ 1: Copilot+ PCs
Copilot+ PCs 是微软推出的智能Windows电脑,拥有强大AI性能和全天电池续航。

Copilot+ PCs是微软推出的新一代Windows PC,专为人工智能(AI)设计。这些PC采用先进的处理器和AI模型,提供卓越的性能和电池寿命,并引入了多种新功能,如Recall(可以快速查找曾经在PC上见过的内容)、Cocreator(几乎实时生成和编辑AI图像)以及Live Captions(实时翻译并生成英语字幕)。Copilot+ PCs还支持多种流行的软件,如Adobe Photoshop和DaVinci Resolve Studio,并配备微软的Pluton安全处理器,增强设备的安全性。
Cocreator 功能结合墨迹笔触和文本提示,实时生成和优化图像,提升了图像编辑的效率和质量。通过与 Adobe、DaVinci Resolve Studio、CapCut 等创意应用的合作,Copilot+ PCs 为用户带来了新颖的 AI 驱动创意体验。
此外,实时字幕功能可以实时翻译音频,将其转换为英语字幕,使更多内容变得易于访问。新的和增强的 Windows Studio 效果,帮助用户在各种环境中展现最佳形象和声音。每台 Copilot+ PC 都配备了强大的 AI 智能体 Copilot,提供简洁、强大且个性化的应用体验。
这些设备由微软Surface和多家OEM合作伙伴(包括Acer、ASUS、Dell、HP、Lenovo和Samsung)生产,将于6月18日开始发售,起价999美元。这些PC不仅在性能上有显著提升,还强调了AI在设备本地化运行的优势,标志着Windows平台的重大转变。
地址:https://blogs.microsoft.com/blog/2024/05/20/introducing-copilot-pcs/
✨ 2: Verba
开源的数据检索增强生成应用,支持多种数据类型和语言模型
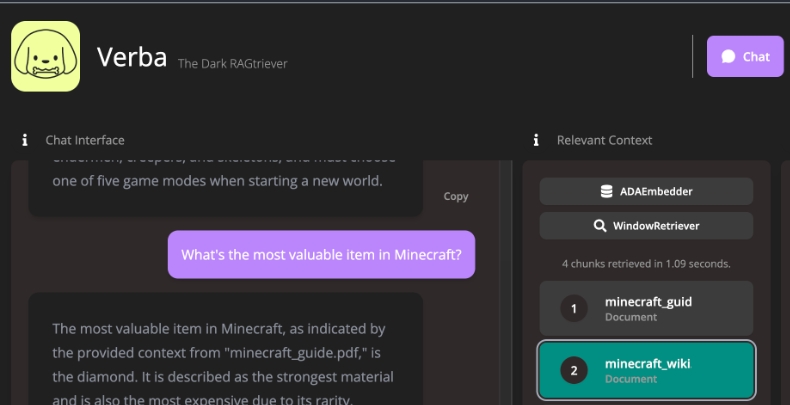
Verba,是一个开源应用程序,旨在提供开箱即用的检索增强生成(Retrieval-Augmented Generation, RAG)解决方案。通过简单易行的步骤,可以本地或通过云端探索数据集并提取洞见,支持如HuggingFace、Ollama以及OpenAI、Cohere、Google等多种大语言模型(LLM)提供商。
地址:https://github.com/weaviate/Verba
✨ 3: SQL Chat
基于对话的SQL客户端,自然语言与数据库交互实现查询、修改和删除操作。

SQL Chat是一个基于聊天界面的SQL客户端,通过自然语言与数据库进行交互,来实现查询、修改、添加和删除等操作。以下是SQL Chat的详细总结和使用场景。用户无需记忆复杂的SQL语法,只需使用自然语言输入命令,SQL Chat就会将其转换为SQL查询语句并执行。支持包括MySQL、PostgreSQL、MSSQL和TiDB Cloud,未来会支持更多类型的数据库。
地址:https://github.com/sqlchat/sqlchat
✨ 4: llama3 implemented from scratch
从头开始实现Llama3,通过加载元数据提供的模型文件中的权重一步步构建张量和矩阵乘法

个从零开始实现Llama3自然语言处理模型的项目。这个项目分为以下几个主要功能:
-
加载模型权重:
- 需要从Meta下载官方的模型权重文件。
- 将权重文件加载到Python环境中。
-
分词器(Tokenizer):
- 使用了一个现成的分词器库
tiktoken(可能是OpenAI的开源库)。 - 将输入文本转化为tokens(编码后的文本片段)。
- 使用了一个现成的分词器库
-
读取模型文件:
- 从权重文件中读取每个张量的数据。
-
嵌入层(Embeddings):
- 将tokens转化为其对应的嵌入向量。
- 使用rms normalization对嵌入向量进行归一化处理。
-
Transformer层的实现:
- 包含注意力机制和前馈神经网络部分。
- 注意力机制包括计算查询向量(query)、键向量(key)、值向量(value)、以及通过旋转位置嵌入(RoPE)添加位置信息。
- 计算查询和键的点积来获得注意力得分,并通过softmax进行归一化处理。
- 最终计算得到的注意力向量与值向量相乘,得到更新后的嵌入向量。
-
多头注意力(Multi-head Attention):
- 对每个注意力头进行上述计算。
- 合并所有注意力头的结果。
-
前馈神经网络(Feed Forward Network):
- 在得到的注意力向量后,通过SwiGLU激活函数的前馈神经网络进一步处理。
- 更新最终的嵌入向量。
-
最终层和解码:
- 在所有Transformer层计算完成后,进行最后的归一化处理。
- 使用输出权重矩阵将最终的嵌入向量转为输出token。
- 通过解码器解码出下一个预测的token。
最终通过以上过程,从一个给定的提示语中预测下一个token,并验证模型的正确性(在例子中,模型预测了"42"作为下一个token)。
地址:https://github.com/naklecha/llama3-from-scratch

更多AI工具,参考国内AiBard123,Github-AiBard123

