- 1IO_总结
- 2mysql开启ssl_mysql ssl
- 3Elasticsearch7.6.x学习笔记(超详细)_es 7.6源码解析
- 4YOLOv7 | 注意力机制 | 添加ECA注意力机制_eca模块
- 5Python 机器学习 基础 之 监督学习 [ 神经网络(深度学习)] 算法 的简单说明_深度学习算法
- 6Flutter-Android签名打包,给小伙伴分享APP吧_flutter android签名打包
- 7C语言实现运动会分数统计_运动会分数统计系统c语言
- 8copy 修改时间_SCI论文审稿时间需要多久?
- 9n皇后问题(DFS)_比赛 题库 提交记录 hack! 博客 帮助 好评差评[-5] #58. n皇后问题百度翻译实时翻
- 10云原生存储:使用MinIO与Spring整合
YOLO8实战:行人跌倒检测系统_基于yolo的老人摔倒检测系统开发目的或意义
赞
踩
yolo8行人跌倒检测系统
前言
随着科技的不断进步,人工智能和深度学习技术已广泛应用于各行各业,尤其是在人身安全检测方面。传统的跌倒检测方法依赖于人工观察,但这种方法不仅耗时耗力,而且容易因人为因素导致误判或漏判。因此,开发一种能够自动、准确、快速地检测行人跌倒行为系统显得尤为重要。
YOLOv8作为先进的(SOTA)模型,具备在大型数据集上进行训练的能力,并能在各种硬件平台上运行,从CPU到GPU。它建立在先前YOLO系列模型的成功基础上,并引入了新功能和改进,以进一步提升性能和灵活性。这使得YOLOv8成为开发行人跌倒检测系统的理想选择。
基于YOLOv8的跌倒检测系统具有重要的背景和意义。首先,基于YOLOv8的行人跌倒检测系统利用深度学习算法,可以实现对行人跌倒行为的自动化识别和检测。这种系统不仅提高了跌倒检测的准确性,还减少了对人力资源的依赖,使得跌倒事件能够被及时发现并采取相应的救助措施。其次,行人跌倒检测在老年人护理和安防监控中具有特别重要的意义。老年人由于身体机能下降,跌倒的风险较高,而跌倒往往可能导致严重的后果。通过安装基于YOLOv8的跌倒检测系统,可以实时监测老年人的活动情况,一旦发现跌倒事件,就能迅速采取救援措施,避免不必要的伤害。此外,在安防监控方面,行人跌倒检测系统也发挥了重要作用。在公共场所如商场、地铁站等,安装跌倒检测系统可以帮助监控人员及时发现异常情况,从而防止潜在的安全隐患。最后,YOLOv8模型具有实时性能高、检测准确度高、多尺度预测以及自适应锚框等优点,使得基于该模型的行人跌倒检测系统能够在各种硬件平台上运行,并且能够在各种复杂环境中保持较高的检测性能。
综上所述,基于YOLOv8的行人跌倒检测系统具有重要的研究意义和应用价值,不仅可以提高跌倒检测的准确性和效率,还可以保护人们的生命财产安全,推动人工智能技术在安全领域的应用。
数据集
使用的跌倒行为图片数据集为自制数据集。数据集制作的具体步骤是,在网上爬取了7630张行人跌倒图片。然后使用labeling标注图片,将图片分为了三类:分为两类:stand person;fall down。数据集格式保存为YOLO格式,并按80%、20%的比例划分为训练集和验证集。数据集样张如图3.1所示。转化为txt格式如图3.2所示。
图3.1 数据集样张
图3.2 txt格式样张
YOLO8网络
YOLOv8 是 ultralytics 公司在 2023 年开源的 YOLOv5 的下一个重大更新版本,按照官方描述,YOLOv8 是一个 SOTA 模型,它建立在以前 YOLO 版本的成功基础上,并引入了新的功能和改进,以进一步提升性能和灵活性。不过 ultralytics 并没有直接将开源库命名为 YOLOv8,而是直接使用 ultralytics 这个词,原因是 ultralytics 将这个库定位为算法框架,而非某一个特定算法,一个主要特点是可扩展性。其希望这个库不仅仅能够用于 YOLO 系列模型,而是能够支持非 YOLO 模型以及分类分割姿态估计等各类任务。因此,YOLO发展到如今的版本,已经不单单是目标检测的代名词,就像官方所解释的那样,YOLOv8 更应该更名为Ultralytics 。目前YOLO8算法框架(ultralytics库)全面支持图像分类、目标检测和实例分割、人体关键点检测等任务。在目标跟踪方面,YOLO8算法库内置了多目标跟踪领域的SOTA算法(Byte-tracker和Bot-tracker)。在实例分割方面,支持与SAM、Fast-SAM无缝集成.....未来,我们也期待着ultralytics库能够扩充更多的CV领域的SOTA算法。
与之前的YOLO版本相比,YOLOv8在以下几个方面有所不同:
骨干网络:YOLOv8采用了全新的骨干网络,以提高模型的性能和准确性。YOLOv8的骨干网络是Darknet-53。Darknet-53是一个深度卷积神经网络模型,它由53个卷积层和池化层组成,用于提取图像特征。其实Darknet-53在YOLOv3网络中就已经被广泛使用,并在YOLOv4和YOLOv5中也得到了应用。它具有较强的特征提取能力,能够在目标检测任务中提供较好的性能。
检测头:YOLOv8采用了Anchor-Free的检测头,这意味着它不再需要预先定义一组固定的先验框来检测目标,而是可以直接从原始图像中预测目标的边界框,这有助于提高模型的灵活性和准确性。
损失函数:YOLOv8采用了新的损失函数,以更好地优化模型的训练过程,进一步提高模型的性能。YOLOv8的损失函数由多个部分组成,包括分类损失(VFL Loss)、回归损失为CIOU Loss+DFL的形式。
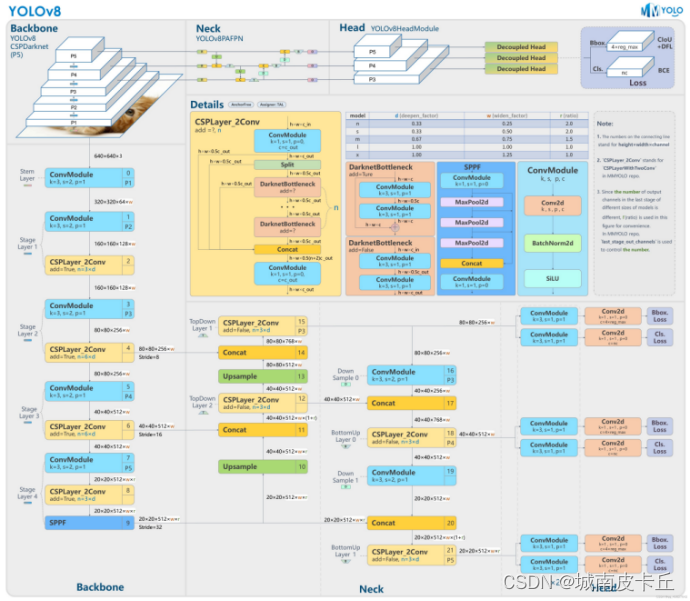
图4-14 yolov8网络结构
模型训练
将标注好的数据集划分为训练集和验证集后,开始对我们搭建的网络进行训练。一般为了缩短网络的训练时间,并达到更好的精度,我们一般加载预训练权重进行网络的训练。而yolov8给我们提供了几个预训练权重,我们可以对应我们不同的需求选择不同的版本的预训练权重。预训练权重越大,训练出来的精度就会相对来说越高,但是其检测的速度就会越慢。本次训练自己的数据集用的预训练权重为yolov8n.pt。其中主要的代码如下:
- from ultralytics import YOLO
- if __name__=='__main__':
- model=YOLO('yolov8n.pt')
- model.train(data='./data.yaml',imgsz=(640,640),workers=1,batch=16,epochs=250)
训练设置的超参数如下:
| 键 | 值 | 描述 |
| model | None | 模型文件路径,例如yolov8n.pt,yolov8n.yaml |
| data | None | 数据文件路径,例如 coco128.yaml |
| epochs | 100 | 训练的轮次数量 |
| patience | 50 | 早停训练的等待轮次 |
| batch | 16 | 每批图像数量(-1为自动批大小) |
| imgsz | 640 | 输入图像的大小,以整数表示 |
| save | True | 保存训练检查点和预测结果 |
| save_period | -1 | 每x轮次保存检查点(如果<1则禁用) |
| cache | False | True/ram, disk 或 False。使用缓存加载数据 |
| device | None | 运行设备,例如 cuda device=0 或 device=0,1,2,3 或 device=cpu |
| workers | 8 | 数据加载的工作线程数(如果DDP则为每个RANK) |
| project | None | 项目名称 |
| name | None | 实验名称 |
| exist_ok | False | 是否覆盖现有实验 |
| pretrained | True | (bool 或 str) 是否使用预训练模型(bool)或从中加载权重的模型(str) |
| optimizer | 'auto' | 使用的优化器,选择范围=[SGD, Adam, Adamax, AdamW, NAdam, RAdam, RMSProp, auto] |
| verbose | False | 是否打印详细输出 |
| seed | 0 | 随机种子,用于可重复性 |
| deterministic | True | 是否启用确定性模式 |
| single_cls | False | 将多类数据作为单类训练 |
| rect | False | 矩形训练,每批为最小填充整合 |
| cos_lr | False | 使用余弦学习率调度器 |
| close_mosaic | 10 | (int) 最后轮次禁用马赛克增强(0为禁用) |
| resume | False | 从最后检查点恢复训练 |
| amp | True | 自动混合精度(AMP)训练,选择范围=[True, False] |
| fraction | 1.0 | 训练的数据集比例(默认为1.0,即训练集中的所有图像) |
| profile | False | 在训练期间为记录器分析ONNX和TensorRT速度 |
| freeze | None | (int 或 list, 可选) 在训练期间冻结前n层,或冻结层索引列表 |
| lr0 | 0.01 | 初始学习率(例如 SGD=1E-2, Adam=1E-3) |
| lrf | 0.01 | 最终学习率 (lr0 * lrf) |
| momentum | 0.937 | SGD动量/Adam beta1 |
| weight_decay | 0.0005 | 优化器权重衰减5e-4 |
| warmup_epochs | 3.0 | 热身轮次(小数ok) |
| warmup_momentum | 0.8 | 热身初始动量 |
| warmup_bias_lr | 0.1 | 热身初始偏差lr |
| box | 7.5 | 框损失增益 |
| cls | 0.5 | cls损失增益(根据像素缩放) |
| dfl | 1.5 | dfl损失增益 |
| pose | 12.0 | 姿态损失增益(仅限姿态) |
| kobj | 2.0 | 关键点obj损失增益(仅限姿态) |
| label_smoothing | 0.0 | 标签平滑(小数) |
| nbs | 64 | 标称批大小 |
| overlap_mask | True | 训练期间掩码应重叠(仅限分割训练) |
| mask_ratio | 4 | 掩码降采样比率(仅限分割训练) |
| dropout | 0.0 | 使用dropout正则化(仅限分类训练) |
| val | True | 训练期间验证/测试 |
Streamlit UI界面介绍
Streamlit是一个专门为机器学习和数据科学团队设计的应用开发框架,它的主要目标是帮助数据科学家和开发人员更快速地创建和部署交互式数据应用程序,以便将研究成果转化为实际应用。
这个框架的主要优势在于其易用性和高效性。使用Streamlit,开发者只需要几行代码就可以创建出交互式应用,无需编写HTML、CSS或JavaScript。同时,Streamlit支持大量表格、图表、数据表等对象的渲染,并封装了大量互动组件,如滑动条、单选框、复选框等,使得应用界面丰富且用户友好。
Streamlit也支持实时预览,即在编辑代码时,应用会自动重新加载,开发者可以实时查看更改的效果。此外,Streamlit还可以自动调整布局和大小,以适应不同的屏幕和设备,实现栅格化响应式布局。
Streamlit的另一个显著特点是对Python数据科学库的广泛支持,如Pandas、Numpy、Matplotlib、Scikit-Learn等,这使得开发者可以利用这些库的功能,直接在Streamlit应用中实现数据分析和可视化。
Streamlit的应用场景非常广泛,比如可以用于搭建预测模型的Web应用,或者用于自动化处理Excel文件的Web应用等。它可以帮助用户将复杂的机器学习或者深度学习模型或数据处理流程转化为易于理解和使用的Web界面,从而方便非专业人员的使用。
总的来说,Streamlit是一个功能强大且易于使用的应用开发框架,特别适合于机器学习和数据科学领域的快速应用开发。
模型评价标准
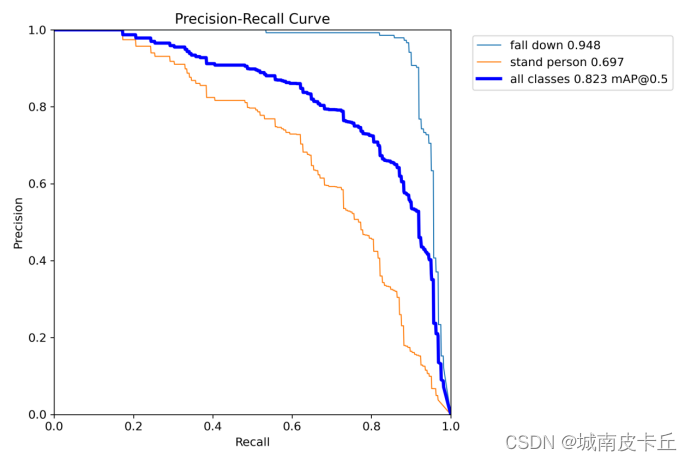
1.PR曲线
P-R曲线是根据模型的预测结果对样本进行排序,把最有可能是正样本的个体排在前面,而后面的则是模型认为最不可能为正例的样本,再按此顺序逐个把样本作为“正例”进行预测并计算出当前的准确率和召回率得到的曲线。PR曲线中的P代表的是Precision(精准率),R代表的是Recall(召回率),其代表的是精准率与召回率的关系,一般情况下,将recall设置为横坐标,precision设置为纵坐标。PR曲线下围成的面积即AP,所有类别AP平均值即map。如下图所示:
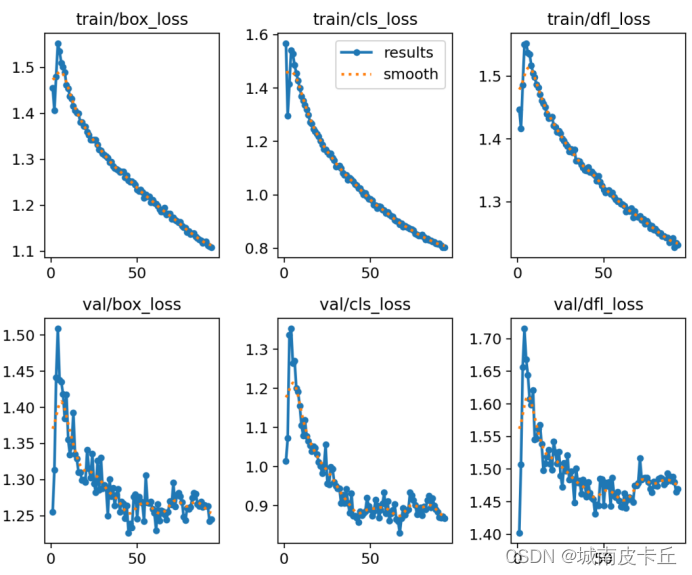
2. loss曲线与map
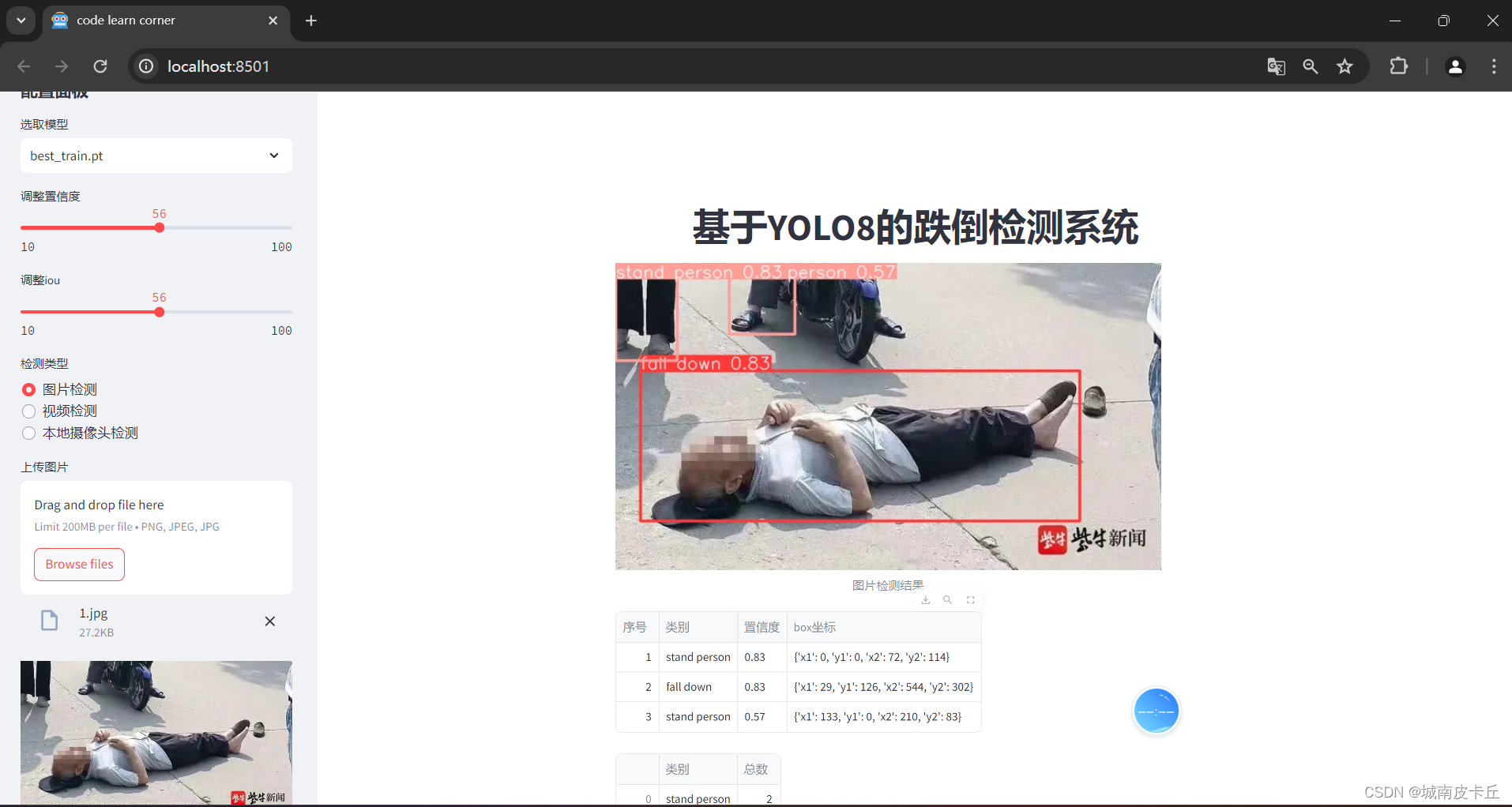
系统界面展示
另外,限于本篇文章的篇幅,更细致的逻辑讲解、代码实现将在项目源码注释、项目说明文档中体现,需要项目源码的小伙伴在微信公众号搜索 ‘编程学习园地’ ,回复关键字‘yolo8实战’即可获得下载链接。