
热门标签
热门文章
- 1Git管理详解
- 2px4学习笔记——实时操作系统以及NUTTX_px4 nuttx
- 3微信小程序 事件_微信小程序 按钮事件
- 4绿联科技通过注册:年营收48亿拟募资15亿 高瓴是股东
- 5OpenAI 组件 | 加速 OpenAI API 在项目中的集成_open ai 商店插件 集成到接口
- 6mybatis&Mysql分页查询,以及SQL_CALC_FOUND_ROWS与count(*) 性能对比_mybatisconfig分页设置
- 7只需 30 分钟,微调 Qwen2-7B,搭建专属 AI 客服解决方案
- 8将网页内容转换为markdown的工具_网页转换工具
- 9插件化基础(一)——加载插件的类
- 10UE4--行为树的使用(AI移动)_ue 行为树
当前位置: article > 正文
YOLO v4 实现目标检测详细教程_yolov4
作者:运维做开发 | 2024-07-13 13:07:35
赞
踩
yolov4
目录
前言
YOLOv4,作为物体检测领域的杰出代表,以其卓越的性能和广泛的应用受到了广泛关注。本文将详细解析YOLOv4的原理,带您深入了解其背后的技术原理和设计思路。
一、YOLO V4算法介绍
YOLOv4的算法原理主要基于深度学习,特别是卷积神经网络(CNN),以实现高精度和高效率的物体检测。其核心原理可以概括为构建一个端到端的物体检测模型,该模型充分利用多尺度特征和多层次特征融合的方式进行物体检测。
1.1 YOLOv4结构图
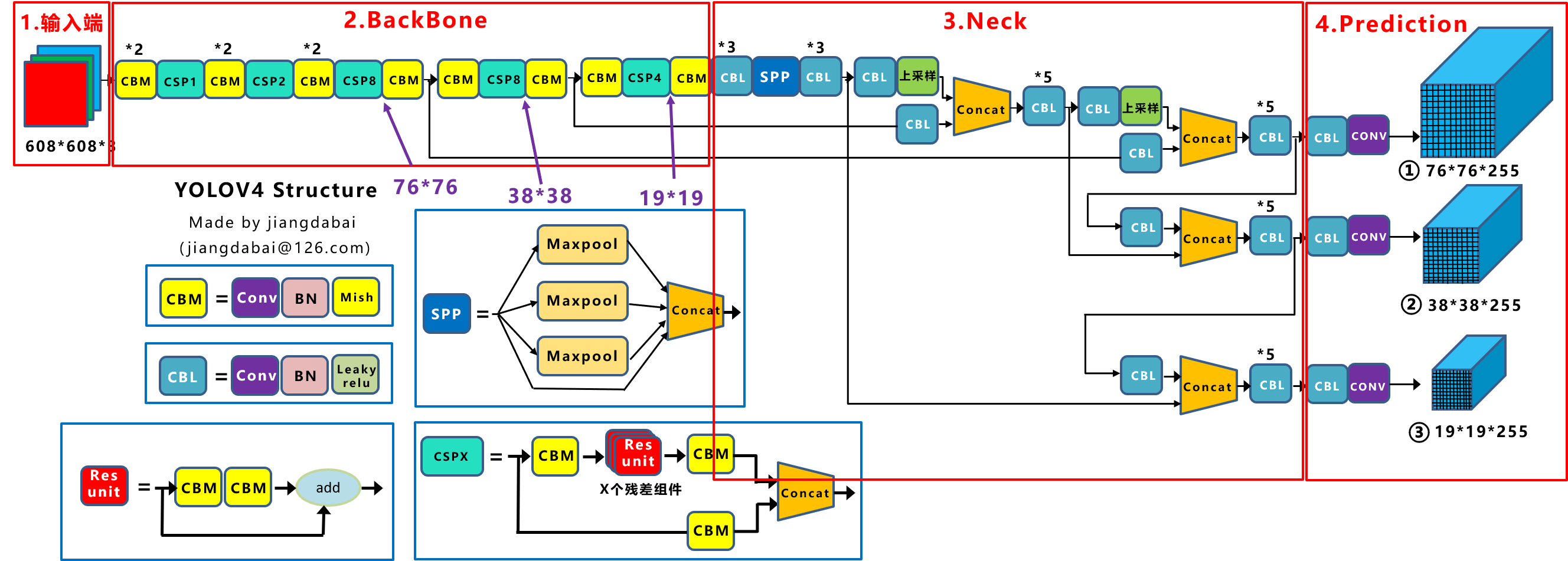
具体来说,YOLOv4的算法流程可以分为以下几个关键部分:
- 输入端:通常包含图片预处理阶段,例如将输入图像缩放到网络所需的输入大小,并进行归一化等操作,以便模型能够更有效地处理图像数据。
- Backbone网络:主要是分类网络,用于提取通用的特征表示。在YOLOv4中,采用了CSPDarkNet53作为基准网络。这个网络结构通过使用Mish激活函数代替原始的ReLU激活函数,以及增加Dropblock模块,来进一步提升模型的泛化能力。
- Neck网络:进一步提升特征的多样性和鲁棒性。YOLOv4利用SPP(空间金字塔池化)模块来融合不同尺度大小的特征图,同时使用自顶向下的FPN(特征金字塔网络)特征金字塔与自底向上的PAN(路径聚合网络)特征金字塔,以增强网络的特征提取能力。
- Head网络:用于完成目标检测结果的输出。在YOLOv4中,使用了CIOU_Loss来代替Smooth L1 Loss函数,以及DIOU_nms来代替传统的NMS(非极大值抑制)操作,这些改进有助于进一步提高算法的检测精度。
除了上述的核心结构,YOLOv4还采用了一系列称为“bag of freebies”(BoF)和“bag of specials”(BoS)的方法和技巧。BoF是指那些只改变训练策略或增加训练成本,但不增加推理成本的方法。而BoS是指那些只会少量增加推理成本,但能显著提高目标检测精度的模块和后处理方法。这些方法和技巧的引入,使得YOLOv4在保持高效率的同时,实现了更高的检测精度。
总的来说,YOLOv4通过结合深度学习和计算机视觉的最新技术,构建了一个强大而高效的物体检测模型,适用于各种复杂场景下的物体检测任务。
二、YOLO V4项目实现
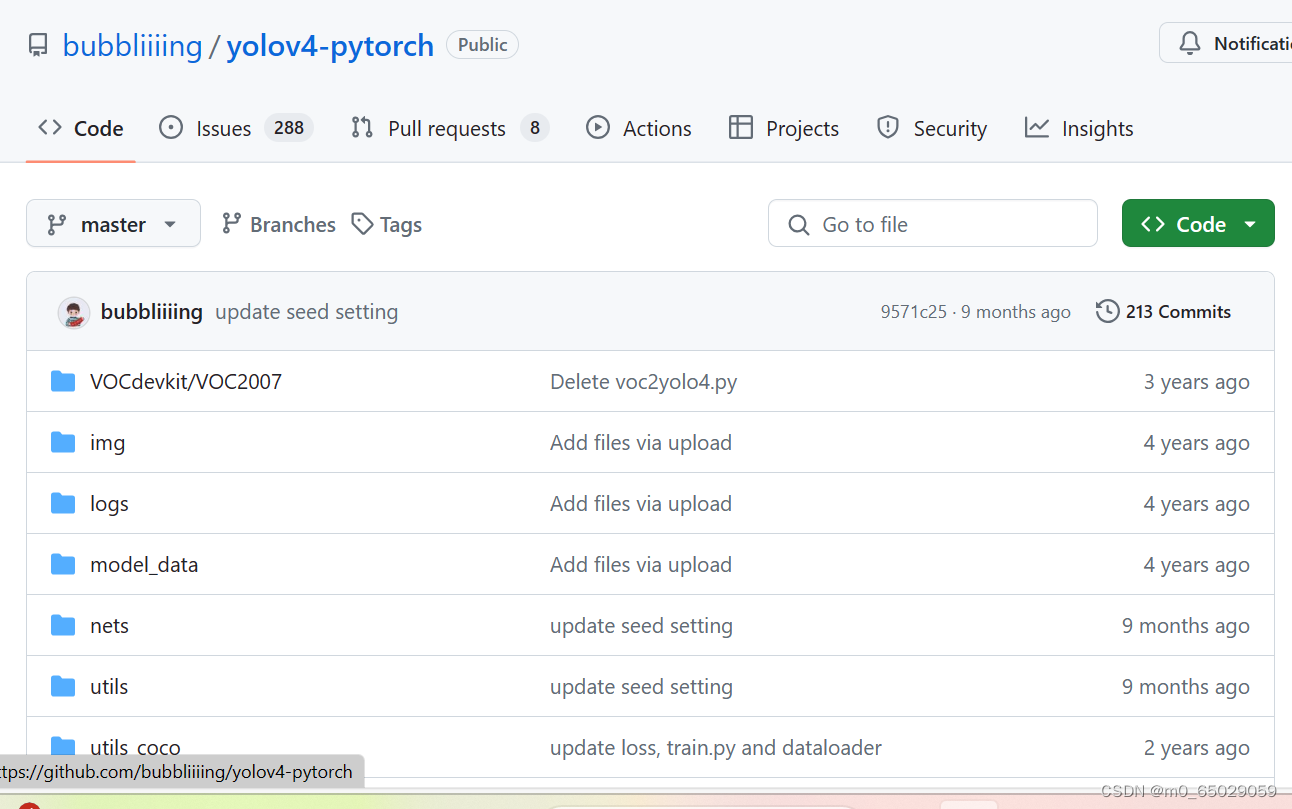
2.1下载源代码,保存并解压
- 我是课堂老师发送的源代码压缩包,直接保存至U盘。
- yolov4代码地址:GitHub - bubbliiiing/yolov4-pytorch: 这是一个YoloV4-pytorch的源码,可以用于训练自己的模型。

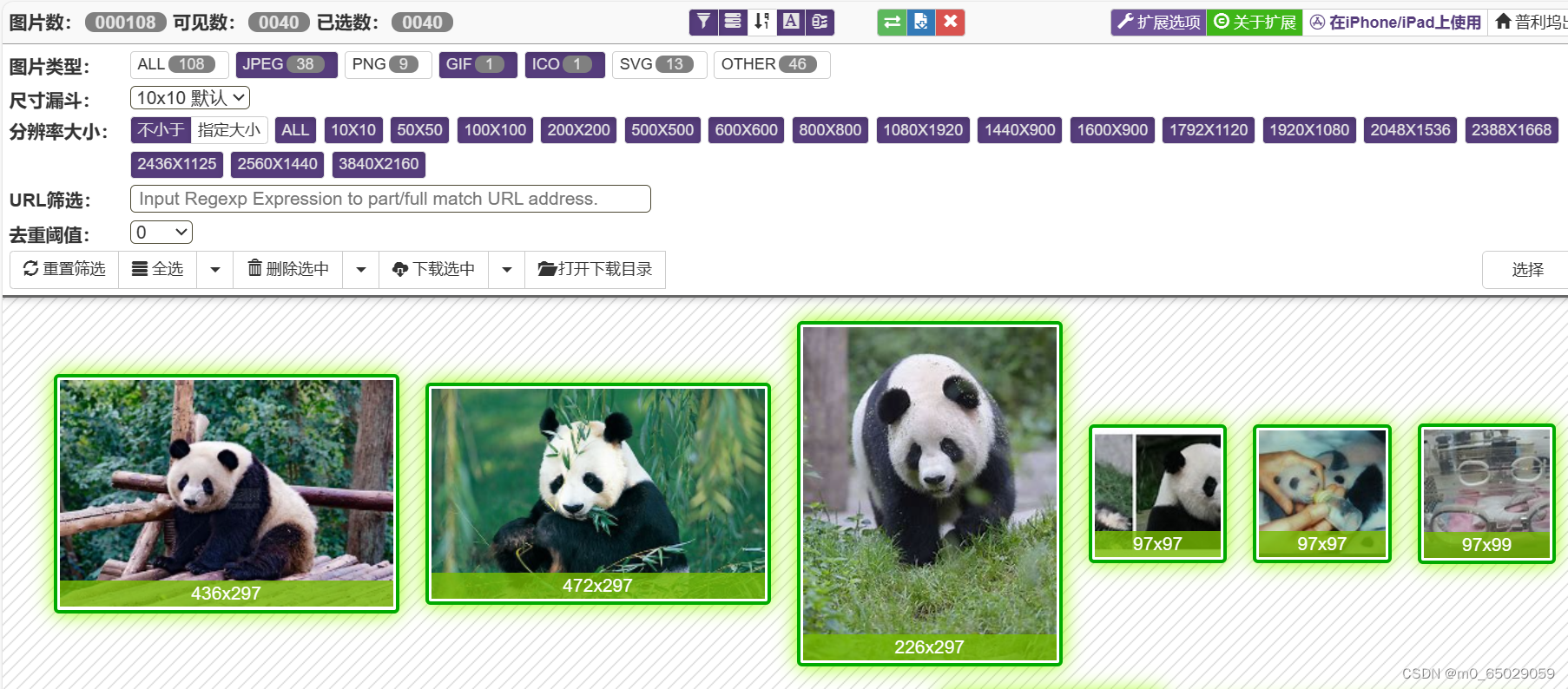
2.2下载训练的图片集
- 在网页搜索自己想要标注的jpg图片通过图片下载扩展批量下载至“yolov4-pytorch-master\yolov4-pytorch-master\VOCdevkit\VOC2007\JPEGImages”中
- 注意:下载图片不得少于100张
- 下载的图片必须是jpg格式的图片
2.3利用label标注图片集
推荐阅读
相关标签

