
热门标签
热门文章
- 1Activity异常被关闭的两种情况_是谁关闭了activity
- 2cxjky.com forum.php,webshell/xiao.php.txt at master · tennc/webshell · GitHub
- 3在eclipse中使用git创建本地库,以及托管项目到GitHub超详细教程_path within repository
- 4洛谷P1182数列分段
- 5YOLOv8 Ultralytics:最先进的 YOLO 模型——简介+实战教程
- 6第二阶段
- 7Android混淆那些事_unsupported version number [55.0] (maximum 54.0, j
- 8gradle 下载安装及 Android Studio 的 gradle 配置_gradle安装与配置 android studio
- 9ntfs for mac如何使用
- 10dmp查看器_dmp文件查看器
当前位置: article > 正文
数字人创作+SadTalker+GTX1080_sadtalker 对显卡的要求
作者:IT小白 | 2024-03-18 05:49:17
赞
踩
sadtalker 对显卡的要求
https://github.com/OpenTalker/SadTalker
SadTalker模型是一个使用图片与音频文件自动合成人物说话动画的开源模型,我们自己给模型一张图片以及一段音频文件,模型会根据音频文件把传递的图片进行人脸的相应动作,比如张嘴,眨眼,移动头部等动作。
SadTalker,它从音频中生成 3DMM 的 3D 运动系数(头部姿势、表情),并隐式调制一种新颖的 3D 感知面部渲染,用于生成说话的头部运动视频。
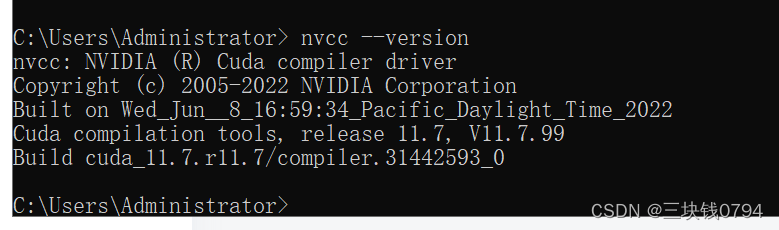
检查cuda版本,我这里是11.7
- 通过终端或者命令行窗口,我们可以使用以下命令来查看CUDA的版本号:
- nvcc --version
- git clone https://github.com/Winfredy/SadTalker.git
-
- cd SadTalker
-
- conda create -n sadtalker python=3.8
-
- conda activate sadtalker
-
- ###这里和github 不一样
- pip install torch torchvision torchaudio==0.12.1 --extra-index-url https://download.pytorch.org/whl/cu117
-
-
- conda install ffmpeg
-
- pip install -r requirements.txt
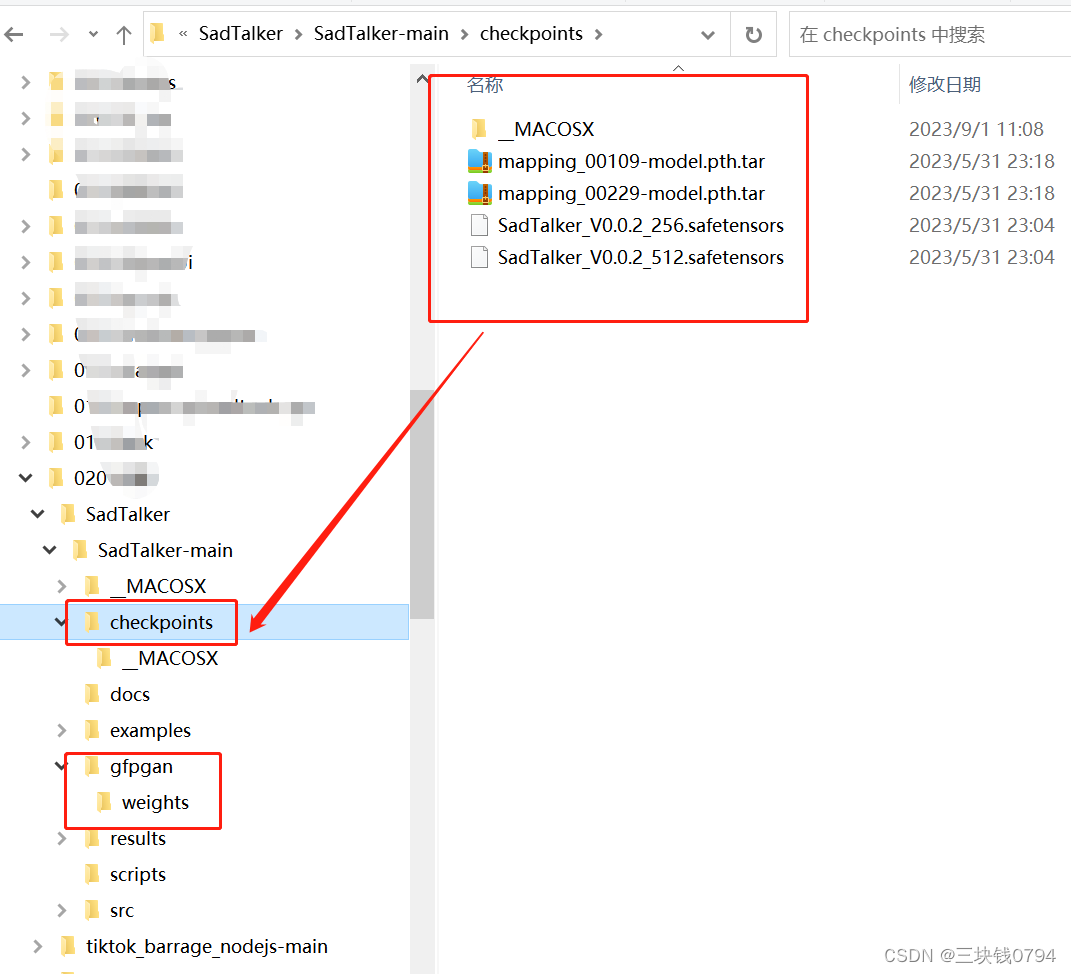
模型下载
Google Driver: download our pre-trained model from this link (main checkpoints) and gfpgan (offline patch)
Github Release Page: download all the files from the lastest github release page, and then, put it in ./checkpoints.
百度云盘: we provided the downloaded model in checkpoints, 提取码: sadt. And gfpgan, 提取码: sadt.
检查是否安装成功
- import torch
- torch.cuda.is_available() # cuda是否可用
-
- print(torch.version.cuda) # 查看pytorch 对应的cuda版本
-
- print(torch.__version__) # 查看pytorch版本
-
- torch.cuda.device_count() # 返回gpu数量
-
- torch.cuda.get_device_name(0) # 返回gpu名字,设备索引默认从0开始;
-
- torch.cuda.current_device() # 返回当前设备索引
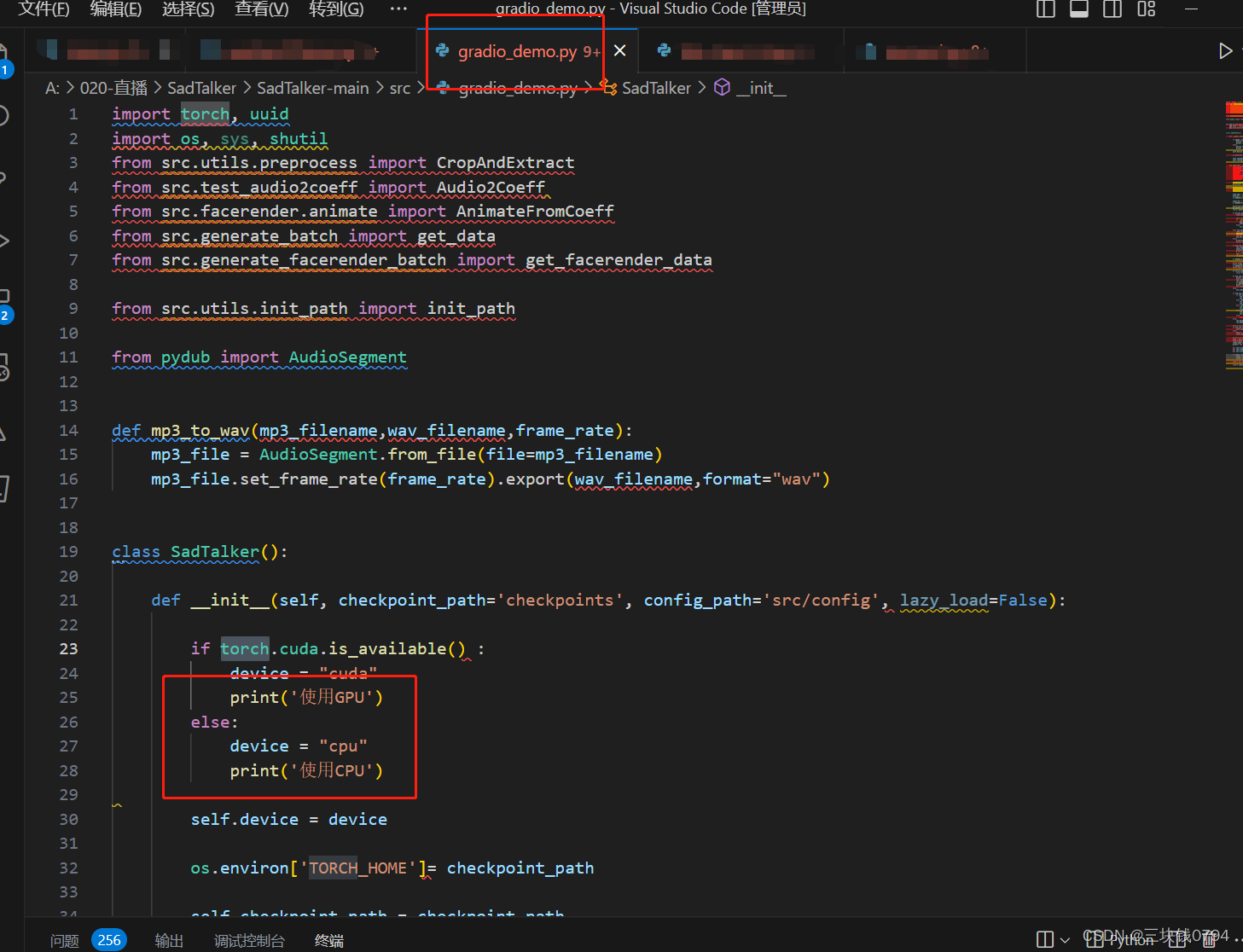
修改一下代码

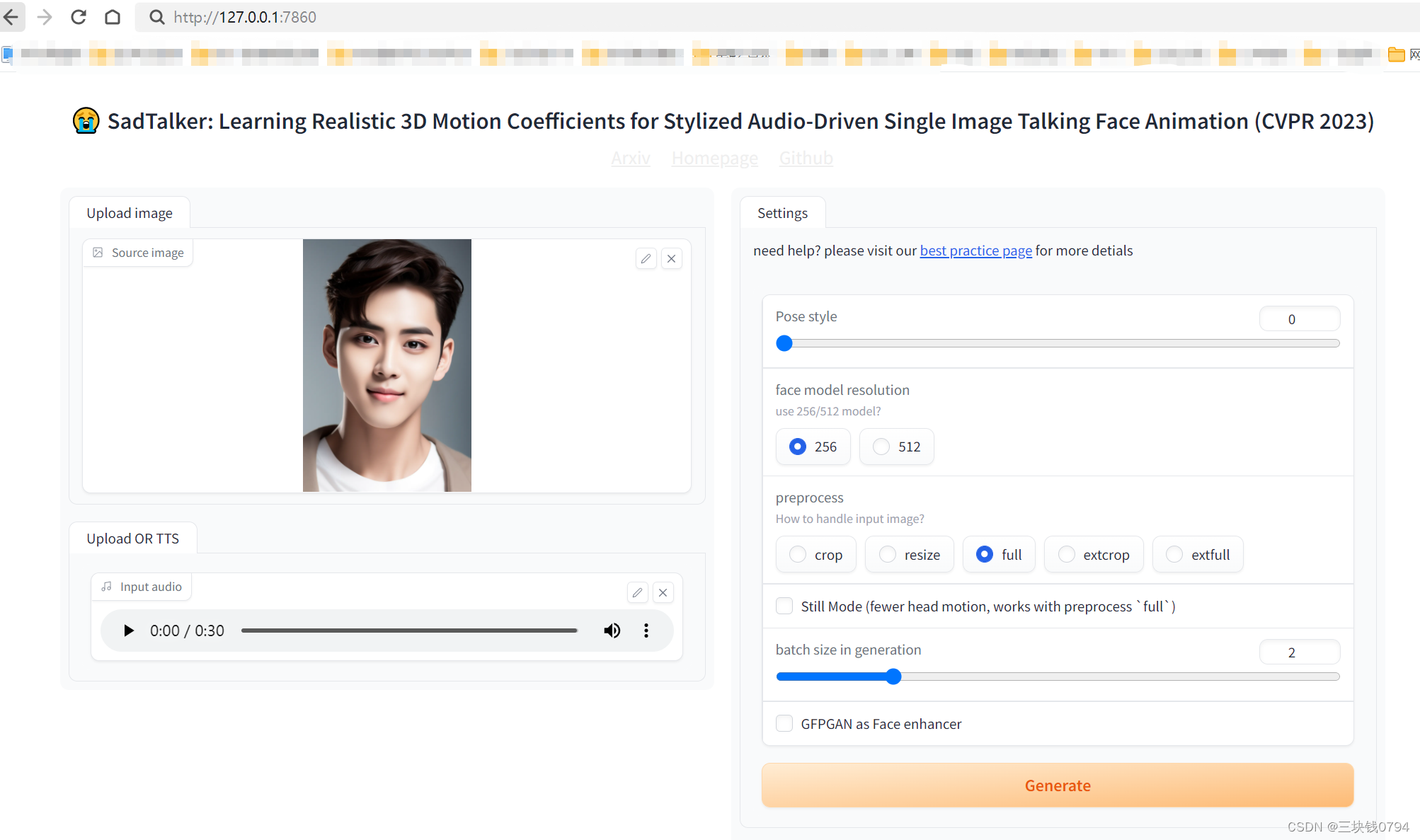
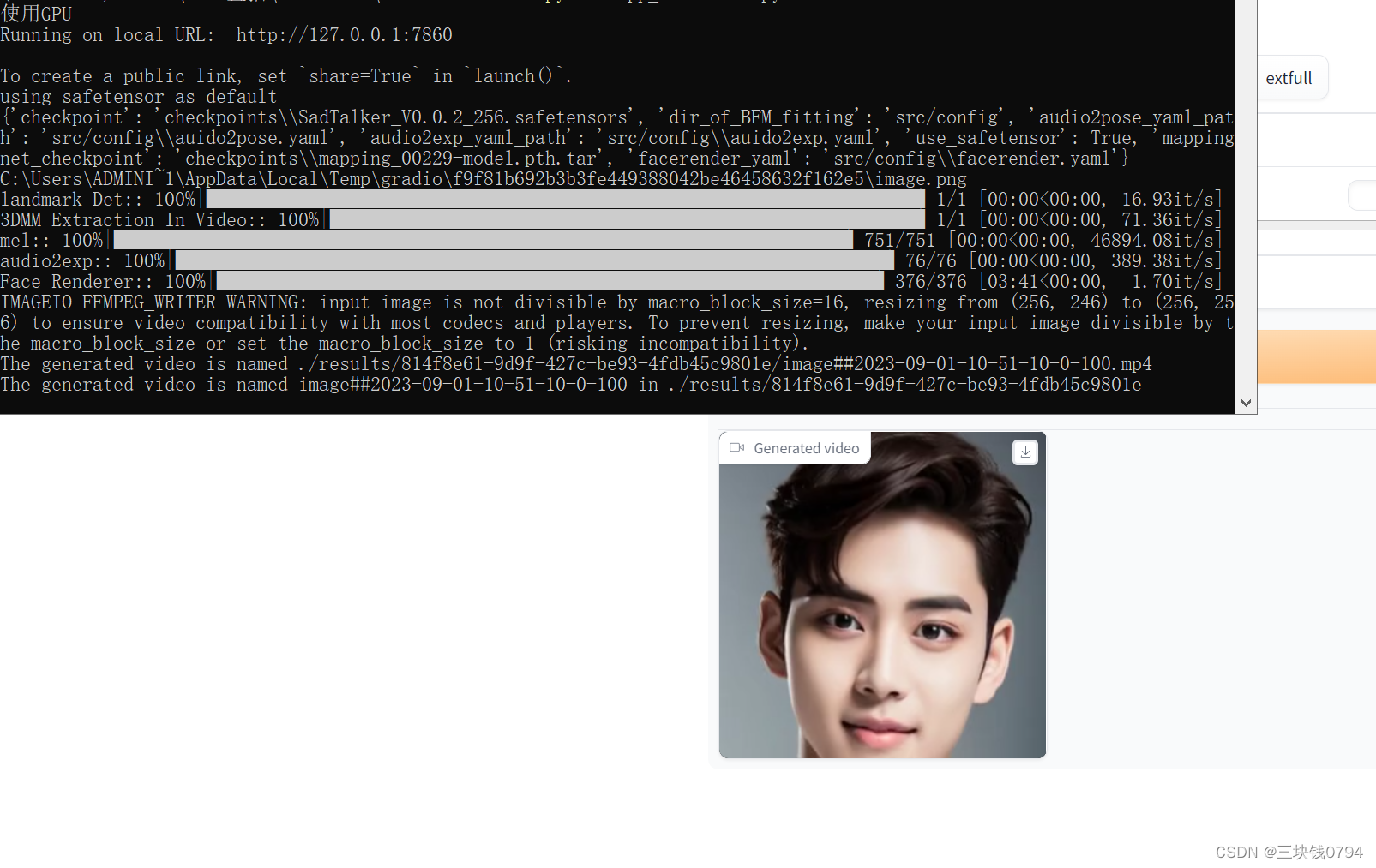
运行

声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/IT小白/article/detail/260801
推荐阅读
相关标签

