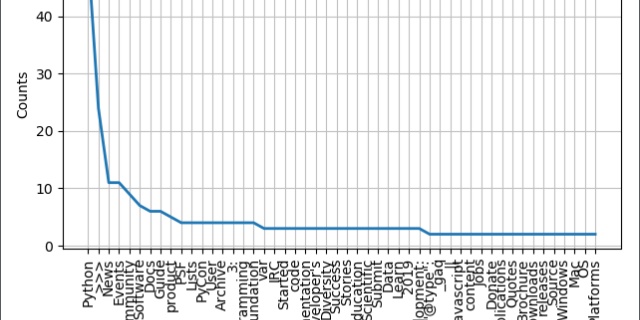
- 1ubuntu18.04 cuda11.7 cudnn11.x pytorch1.11.0_cuda 11.7对应的pytorch
- 2Centos7安装python12+最新openssl_centos python-3.12.0 安装
- 3TCP 协议(二)连接与断开_established状态有ip地址如何断开
- 4Windows下载使用wget命令_windows wget
- 5C++Primer Plus第6版&C Primer Plus第6版 中文版免费分享啦_c++ primer plus 第6版 中文版pdf
- 6LeakyReLU激活函数_leakyrelu函数
- 7初识 Linux — 文件管理_将目录下的子目录mydir中所有文件和子目录的所有者切换为stu,分组切换为stu命
- 8HikariCP--基础--02--配置参数_hikariconfig配置
- 9Dplayer Android播放器,呆呆播放器手机版官方下载
- 10容器管理工具Docker(六):Docker容器镜像加速器及本地容器镜像仓库_本地容器镜像仓库 现任明教教主
sql sever如何进行英文词频统计_英文文本分词、词性标注、词频统计、去停用词一条龙~...
赞
踩
今天的目标是将一段英文文本进行分词、词性标注、词形还原、词频统计、去停用词,最后基于词频制作词云~
Cindy和Bosman的故事又有了一点进展,哈哈哈~本人瞎编的功夫日渐精进~
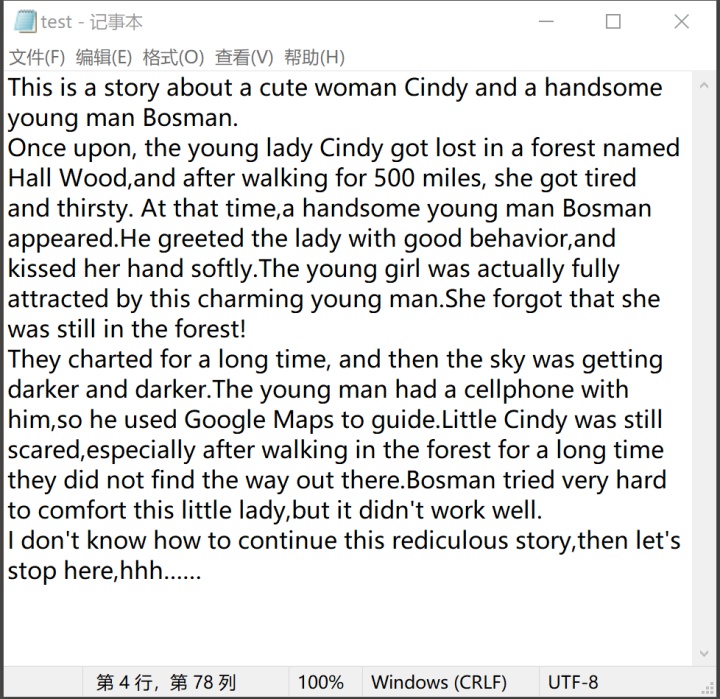
第一步:导入本地语料

成功导入~

第二步:分词

成功分词~

第三步:词性标注
【词性标注是词形还原的基础条件,在词形还原函数中有一个参数需要输入词性】

词性标注结果如下:

第四步:提取名词
需要注意是是,采用nltk库中的pos_tag()方法进行词性标注,得到的词性一般格式为:NN、NNP、JJ、VBD……
这与我们从小背英文单词时所熟悉的n-名词,adj-形容词,adv-副词……不太一样,而做词形还原的这个函数需要的词性表达方式是n、adj、v……这种形式,因此,我们需要对二者进行一个等价转换。
英文词性对照表:
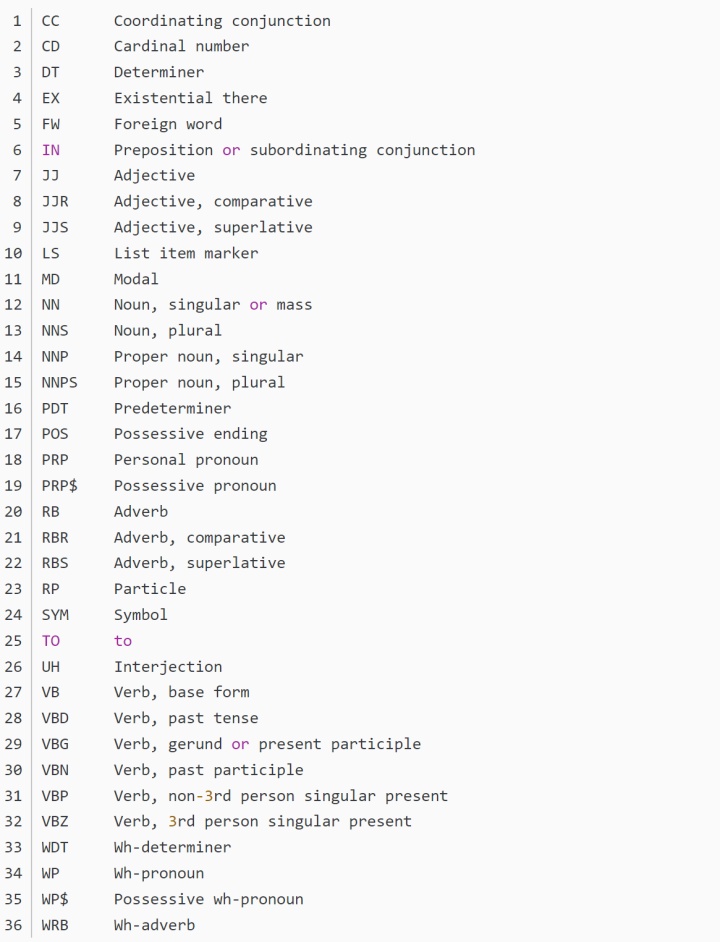
观察上述词性表可以发现一些规律:
①noun-名词一般是以N开头的,如NN、NNS、NNP、NNPS。
②verb-动词一般是以V开头的,如VB、VBD、VBG、VBN、VBP、VBZ。
③adj-形容词一般是以J开头的,如JJ、JJR、JJS。
④adv-副词一般是以RB开头,如RB、RBR、RBS。
以上规律是否足够用呢?其他词性可以不做转换吗?事实上,我也不确定啊,看到网友们都只做了这几个常见的,想想也是,名词可能会因为单复数问题而造成同一个单词分开计数,动词可能因为时态问题,形容词、副词可能因为最高级别和比较级问题……以上所列出的都是常见的问题,那些不常见的对结果影响也不会太大。如果实在不放心,打开wordnet文件夹,可以看到,nltk库在处理时也只考虑了上述最主要的几种情况。
接下来,提取出名词,并且返回结果仅为词,不再包括词性。

注释 :因为tw是列表中嵌套元组,元组中第1个元素是词,第2个元素是词性(tag),因此i表示一个个元组,i[1]表示元组中第2个元素,即词性。
运行效果如下:
['story', 'woman', 'Cindy', 'man', 'Bosman', 'Once', 'lady', 'Cindy', 'forest', 'Hall', 'Wood', 'miles', 'time', 'man', 'Bosman', 'lady', 'behavior', 'hand', 'softly.The', 'girl', 'man.She', 'forest', 'time', 'sky', 'darker', 'darker.The', 'man', 'cellphone', 'Google', 'Maps', 'Cindy', 'forest', 'time', 'way', 'there.Bosman', 'lady', 'story', 'hhh……']我想看看各个名词的词频。为了得到每个名词的词频,需要先计算出所有词的词频。
代码如下:

运行结果如下:
{'This': 1, 'is': 1, 'a': 8, 'story': 2, 'about': 1, 'cute': 1, 'woman': 1, 'Cindy': 3, 'and': 6, 'handsome': 2, 'young': 6, 'man': 3, 'Bosman': 2, '.': 3, 'Once': 1, 'upon': 1, ',': 11, 'the': 6, 'lady': 3, 'got': 2, 'lost': 1, 'in': 3, 'forest': 3, 'named': 1, 'Hall': 1, 'Wood': 1, 'after': 2, 'walking': 2, 'for': 3, '500': 1, 'miles': 1, 'she': 2, 'tired': 1, 'thirsty': 1, 'At': 1, 'that': 2, 'time': 3, 'appeared.He': 1, 'greeted': 1, 'with': 2, 'good': 1, 'behavior': 1, 'kissed': 1, 'her': 1, 'hand': 1, 'softly.The': 1, 'girl': 1, 'was': 4, 'actually': 1, 'fully': 1, 'attracted': 1, 'by': 1, 'this': 3, 'charming': 1, 'man.She': 1, 'forgot': 1, 'still': 2, '!': 1, 'They': 1, 'charted': 1, 'long': 2, 'then': 2, 'sky': 1, 'getting': 1, 'darker': 1, 'darker.The': 1, 'had': 1, 'cellphone': 1, 'him': 1, 'so': 1, 'he': 1, 'used': 1, 'Google': 1, 'Maps': 1, 'to': 3, 'guide.Little': 1, 'scared': 1, 'especially': 1, 'they': 1, 'did': 2, 'not': 1, 'find': 1, 'way': 1, 'out': 1, 'there.Bosman': 1, 'tried': 1, 'very': 1, 'hard': 1, 'comfort': 1, 'little': 1, 'but': 1, 'it': 1, "n't": 2, 'work': 1, 'well': 1, 'I': 1, 'do': 1, 'know': 1, 'how': 1, 'continue': 1, 'rediculous': 1, 'let': 1, "'s": 1, 'stop': 1, 'here': 1, 'hhh……': 1}接下来提取名词的词频:

{'story': 2, 'woman': 1, 'Cindy': 3, 'man': 3, 'Bosman': 2, 'Once': 1, 'lady': 3, 'forest': 3, 'Hall': 1, 'Wood': 1, 'miles': 1, 'time': 3, 'behavior': 1, 'hand': 1, 'softly.The': 1, 'girl': 1, 'man.She': 1, 'sky': 1, 'darker': 1, 'darker.The': 1, 'cellphone': 1, 'Google': 1, 'Maps': 1, 'way': 1, 'there.Bosman': 1, 'hhh……': 1}最后是去掉停用词,仅保留有意义的词及其词频:

运行结果如下:
{'story': 2, 'cute': 1, 'woman': 1, 'Cindy': 3, 'handsome': 2, 'young': 6, 'man': 3, 'Bosman': 2, '.': 3, 'Once': 1, ',': 11, 'lady': 3, 'got': 2, 'lost': 1, 'forest': 3, 'named': 1, 'Hall': 1, 'Wood': 1, 'walking': 2, '500': 1, 'miles': 1, 'tired': 1, 'thirsty': 1, 'At': 1, 'that': 2, 'time': 3, 'appeared.He': 1, 'greeted': 1, 'good': 1, 'behavior': 1, 'kissed': 1, 'hand': 1, 'softly.The': 1, 'girl': 1, 'actually': 1, 'fully': 1, 'attracted': 1, 'this': 3, 'charming': 1, 'man.She': 1, 'forgot': 1, '!': 1, 'They': 1, 'charted': 1, 'long': 2, 'sky': 1, 'getting': 1, 'darker': 1, 'darker.The': 1, 'had': 1, 'cellphone': 1, 'him': 1, 'used': 1, 'Google': 1, 'Maps': 1, 'guide.Little': 1, 'scared': 1, 'especially': 1, 'they': 1, 'find': 1, 'way': 1, 'out': 1, 'there.Bosman': 1, 'tried': 1, 'very': 1, 'hard': 1, 'comfort': 1, 'little': 1, "n't": 2, 'work': 1, 'well': 1, 'I': 1, 'know': 1, 'how': 1, 'continue': 1, 'rediculous': 1, 'let': 1, "'s": 1, 'stop': 1, 'here': 1}可以看到,因为事先没有对文本进行小写转换,部分词虽然在停用词表中,但是仍然没有被识别并踢掉。如At.
参考连接:
NLP入门(三)词形还原(Lemmatization) - 山阴少年 - 博客园www.cnblogs.com NLTK之统计词频,去除停用词,生成词云(一)www.jianshu.com