- 1物联网的应用涉及生活的方方面面,在这里介绍一下物联网的多种应用场景_物联网已深入到现在生活的方方面面,根据课程所学,就某一应用场景提出你的应用
- 2pytorch实现LSTM(附code)
- 3单台服务器最大支持多少连接数_一台服务器并发多少正常
- 4自己动手实现网页版的远程桌面_网页版windows远程桌面
- 5学生成绩智能分析系统—教师端的设计与实现_学生成绩管理系统教师端
- 6CSDN原力等级和创作等级升级详解
- 71265:【例9.9】最长公共子序列_1265:【例9.9】最长公共子序列
- 8离线安装python包_python离线安装
- 9核密度分析
- 10pyechart 与jupyter 交互式,图表显示空白的解决方案_jupyter notebook pyechart图像显示空白
【音视频流媒体】2、WebRTC 直播超详细介绍_webrtc直播框架
赞
踩
文章目录
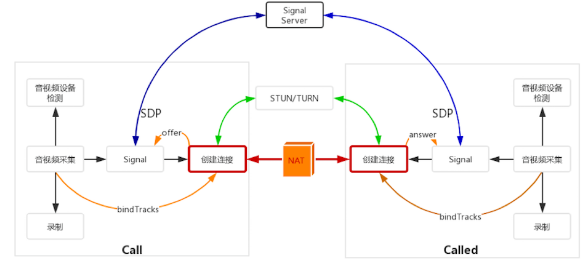
一对一直播框架:
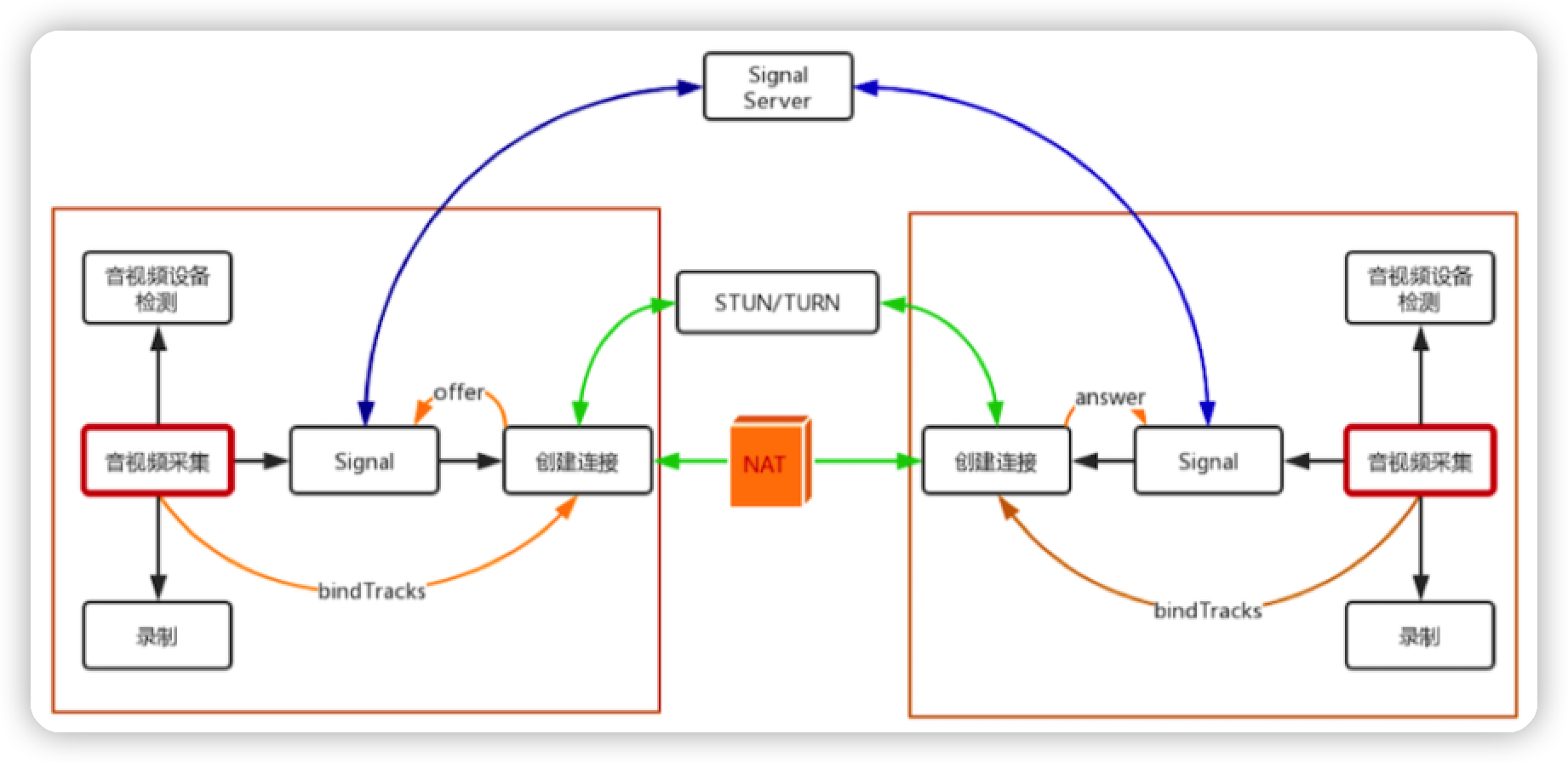
WebRTC终端: 音视频采集, 编解码, NAT穿越, 音视频数据传输
Signal服务器: 信令处理(如加入房间, 离开房间, 传递媒体协商消息)
STUN/TURN服务器: 获取WebRTC终端在公网的IP地址, NAT穿越失败后的数据中转.
音视频设别采集
访问摄Web像头
<!DOCTYPE html>
<html>
<head>
<title>Realtime communication with WebRTC</title>
<link rel="stylesheet" , href="css/client.css" />
</head>
<body>
<h1>Realtime communication with WebRTC </h1>
<video autoplay playsinline></video>
<script src="js/client.js"></script>
</body>
</html>
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
"use strict";
const mediaStreamContrains = {
video: true,
};
const localVideo = document.querySelector("video");
function gotLocalMediaStream(mediaStream) {
localVideo.srcObject = mediaStream;
}
function handleLocalMediaStreamError(error) {
console.log("navigator.getUserMedia error: ", error);
}
navigator.mediaDevices
.getUserMedia(mediaStreamContrains)
.then(gotLocalMediaStream)
.catch(handleLocalMediaStreamError);
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
js中var promise = navigator.mediaDevices.getUserMedia(constraints);可访问摄像头和麦克风, 其中mediaStreamContrains可设置采集的参数(如只采集视频, 分辨率等)
html中<video>标签的autoplay控制自动播放, playsinline在html5页面而不是系统播放器内播放视频
音频
奈奎斯特定理: 模数转换过程中, 当采样率>信号最高频率的2倍时, 采用后的数字信号就完整的保留了原始信号的信息.
人类的听觉频率范围是20Hz~20KHz, 故8kHz采样率可满足人们需求.
为了追求高保真,一般采样率设置为40KHz,使可完整保留原始信号.(如一般听数字音乐都是44.1K,48K的采样率)
模拟数据,经采样, 量化,编码,最终得到数字信号.
- 采样: 时间轴, 对信号数字化
- 量化: 幅度轴, 对信号数字化
- 编码:
量化,编码过程中,采样大小决定每个采样最大可表示的范围.若采样大小为8bit则最大值是2^8-1,若采样大小是16bit则最大值为2^16-1
用浏览器自拍
<body>
<video autoplay playsinline id="player"></video>
<script src="./js/picture.js"></script>
<button id="taskPicture">截屏</button>
<canvas id="picture"></canvas>
<div>
<select id="filter">
<option value="none">None</option>
<option value="blur">blur</option>
<option value="grayscale">Grayscale</option>
<option value="invert">Invert</option>
<option value="sepia">sepia</option>
</select>
<button id="save">下载</button>
</div>
</body>
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
点击截屏按钮时, 将当前video标签的内容, 放入canvas的drawImage
点击下载按钮时, 用canvas.toDataURL将图片内容转为url, 用浏览器下载它
// 截屏
document.querySelector("button#takePicture").onclick = function () {
picture
.getContext("2d")
.drawImage(videoplay, 0, 0, picture.width, picture.height);
};
// 下载
document.querySelector("button#save").onclick = function () {
downLoad(canvas.toDataURL("image/jpeg"));
};
function downLoad(url) {
var oA = document.createElement("a");
oA.download = "photo"; // 设置下载的文件名,默认是'下载'
oA.href = url;
document.body.appendChild(oA);
oA.click();
oA.remove(); // 下载之后把创建的元素删除
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
录制
- 回放: 有3种方式: 边录边看, 录完即可看, 录完一段时间后可看
- 录制: 有如下方式
- 直接录制: 分别将音频和视频存到不同的二进制文件中, 文件中的每块数据如下, 之后再把音视频整合为多媒体文件(如flv或mp4)
- 缺点: 录完, 还需音视频合流, 不及时
- 直接录制: 分别将音频和视频存到不同的二进制文件中, 文件中的每块数据如下, 之后再把音视频整合为多媒体文件(如flv或mp4)
struct data
int media_type; // 数据类型,0: 音频 1: 视频
int64_t ts; // timestamp,记录数据收到的时间
int data_size; // 数据大小
char* data; // 指定具体的数据
} media_data;
- 1
- 2
- 3
- 4
- 5
- 6
- 直接录制多媒体格式, 如flv, 因可在flv文件的任何位置读写, 故不用等待所有原始数据都存储或才合流,转码了, 是实时的
- 1
- WebRTC会帮我们处理网络丢包,网络乱序,媒体格式问题
js的二进制数据类型
ArrayBuffer
通用的, 固定长度的, 二进制缓冲区, 可用于存图, 存视频等
不能直接对ArrayBuffer对象直接访问, 其类似于java的抽象类, 在物理内存中并不存在此对象, 需要用其封装类实例化后才能访问
ArrayBuffer只是描述有此空间存放二进制数据, 但计算机内存中并没有为其真正的分配空间; 只有当具体类型化后, 其才能真正存在于内存中
// 下例中, 生成的buffer不能直接访问, 必须把buffer作为参数, 传给具体类型的新对象(如Uint32Array或DataView时), 此新对象才可被访问
let buffer = new ArrayBuffer(16);
let view = new Uint32Array(buffer);
或
let buffer = new Uint8Array([255, 255, 255, 255]).buffer;
let dataView = new DataView(buffer);
// 其定义如下
/**
* Represents a raw buffer of binary data, which is used to store data for the
* different typed arrays. ArrayBuffers cannot be read from or written to directly,
* but can be passed to a typed array or DataView Object to interpret the raw
* buffer as needed.
*/
interface ArrayBuffer {
/**
* Read-only. The length of the ArrayBuffer (in bytes).
*/
readonly byteLength: number;
/**
* Returns a section of an ArrayBuffer.
*/
slice(begin: number, end?: number): ArrayBuffer;
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
ArrayBufferView
ArrayBufferView是指Int8Array, Uint8Array, DataView等类型的总称, 这些类型都是用ArrayBuffer类实现的(真正在内存中分批空间)
Blob
Binary Large Object是js的二进制对象类型, WebRTC用其存录好的音视频文件, 其底层用ArrayBuffer封装类实现
// 其中array可以是ArrayBuffer, ArrayBufferView, Blob, DOMString等类型, option指定存储成的媒体类型
var aBlob = new Blob(array, options);
/** A file-like object of immutable, raw data. Blobs represent data that isn't necessarily in a JavaScript-native format. The File interface is based on Blob, inheriting blob functionality and expanding it to support files on the user's system. */
interface Blob {
readonly size: number;
readonly type: string;
arrayBuffer(): Promise<ArrayBuffer>;
slice(start?: number, end?: number, contentType?: string): Blob;
stream(): ReadableStream<Uint8Array>;
text(): Promise<string>;
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
录本地音视频
var mediaRecorder = new MediaRecorder(stream[, options]);
stream: 通过getUserMedia获取的本地视频流, 或通过RTCPeerConnection获取的远程视频流
options: 指定的视频格式,编解码器,码率, 如mimeType: `video/Webml;codecs=vp8`
当midiaRecorder捕获到数据时触发ondataavailable事件, 我们若实现此事件的逻辑, 即可通过它录音视频
- 1
- 2
- 3
- 4
- 5
下面是例子
<html>
<body>
<div>
<video id="capture">auto play playsinline</video>
<button id="record">Start Record</button>
<button id="recplay" disabled>Play</button>
<button id="download" disabled>Download</button>
<video id="replay">autoplay playsinline</video>
</div>
<script type="text/javascript" src="js/record.js"></script>
</body>
</html>
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
console.log("hi");
const mediaStreamContrains = {
video: {
frameRate: { min: 20 },
width: { min: 640, ideal: 1280 },
height: { min: 360, ideal: 720 },
aspectRatio: 16 / 9,
facingMode: "user",
},
audio: {
echoCancellation: false,
noiseSuppression: true,
autoGainControl: true,
},
};
console.log("mediaStreamContrains", mediaStreamContrains);
const localVideo = document.querySelector("#capture");
const recvideo = document.querySelector("#replay");
console.log("localVideo", localVideo);
console.log("recvideo", recvideo);
var stream;
function gotLocalMediaStream(mediaStream) {
localVideo.srcObject = stream = mediaStream;
}
function handleLocalMediaStreamError(error) {
console.log("navigator.getUserMedia error: ", error);
}
navigator.mediaDevices
.getUserMedia(mediaStreamContrains)
.then(gotLocalMediaStream)
.catch(handleLocalMediaStreamError);
// navigator.mediaDevices.enumerateDevices().then((list) => {
// console.log("origin:", list);
// })
var buffer;
var btn_record = document.querySelector("#record");
var btn_play = document.querySelector("#recplay");
var btn_download = document.querySelector("#download");
console.log("btn_record", btn_record);
console.log("btn_play", btn_play);
console.log("btn_download", btn_download);
btn_record.addEventListener("click", function () {
console.log("startRecord");
startRecord();
});
btn_play.addEventListener("click", function () {
play();
});
btn_download.addEventListener("click", function () {
download();
});
// 当该函数被触发后,将数据压入到 blob 中
function handleDataAvailable(e) {
if (e && e.data && e.data.size > 0) {
buffer.push(e.data);
btn_play.removeAttribute("disabled");
}
}
var mediaRecorder;
function startRecord() {
buffer = [];
// 设置录制下来的多媒体格式
var options = {
mimeType: "video/webm;codecs=h264",
};
// 判断浏览器是否支持录制
if (!MediaRecorder.isTypeSupported(options.mimeType)) {
console.error(`${options.mimeType} is not supported!`);
return;
}
try {
// 创建录制对象
mediaRecorder = new MediaRecorder(window.stream, options);
} catch (e) {
console.error("Failed to create MediaRecorder:", e);
return;
}
btn_record.setAttribute("disabled", true);
// 当有音视频数据来了之后触发该事件
mediaRecorder.ondataavailable = handleDataAvailable;
// 开始录制
mediaRecorder.start(10);
}
function play() {
mediaRecorder.ondataavailable = null;
var blob = new Blob(buffer, { type: "video/webm" });
recvideo.src = window.URL.createObjectURL(blob);
recvideo.srcObject = null;
recvideo.controls = true;
recvideo.play();
btn_record.removeAttribute("disabled");
btn_download.removeAttribute("disabled");
}
function download() {
var blob = new Blob(buffer, { type: "video/webm" });
var url = window.URL.createObjectURL(blob);
var a = document.createElement("a");
a.href = url;
a.style.display = "none";
a.download = "aaa.webm";
a.click();
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
- 101
- 102
- 103
- 104
- 105
- 106
- 107
- 108
- 109
- 110
- 111
- 112
- 113
- 114
- 115
- 116
html先加载dom元素,再加载js文件
js文件先开启摄像头, 再通过getElementById获取button
当点击btn_record时, 新建MediaRecorder, 在ondataavaliable事件的回调函数内写逻辑: 开始录制并存入自建的buffer数组
当点击btn_play时, 将buffer数组放入video标签.src并play()
当点击btn_download时, 将buffer数组用window.URL.createObjectURL放入a标签.href使可下载
实际操作时可分为多个小粒度的buffer数组, 提升可靠性
共享远程桌面
- 共享者
- 每秒抓3次屏幕帧, 取各帧差值并压缩;
- 若第一次抓屏幕或两帧变化率>80%时则做全屏的帧内压缩
- 把压缩后的数据传给观看端, 观看端解码
- 远程控制者
- 当鼠标点击共享桌面某位置时, 计算出鼠标点击的位置, 通过信令以参数形式发给共享端
- 共享端模拟本地点击事件, 调os的API完成操作
- 桌面采集: DirectX
- 数据编码: H264或VP8
- 传输: 流媒体传输协议
- 解码: H264或VP8
- 渲染: OpenGL/Direct3D做GPU渲染
抓取桌面
// 得到桌面数据流
function getDeskStream(stream) {
localStream = stream;
}
// 抓取桌面
function shareDesktop() {
// 只有在 PC 下才能抓取桌面
if (IsPC()) {
// 开始捕获桌面数据
navigator.mediaDevices
.getDisplayMedia({ video: true })
.then(getDeskStream)
.catch(handleError);
return true;
}
return false;
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
展示桌面
把获取到的stream, 放入video标签即可
<video autoplay playsinline id="deskVideo"></video>
- 1
var deskVideo = document.querySelect("video/deskVideo");
function getDeskStream(stream){
localStream = stream;
deskVideo.srcObject = stream;
}
- 1
- 2
- 3
- 4
- 5
录制桌面
获取到的stream, 传入MediaRecorder, 实现ondataavailable事件
var buffer;
function handleDataAvailable(e){
if(e && e.data && e.data.size > 0){
buffer.push(e.data);
}
}
function startRecord(){
// 定义一个数组,用于缓存桌面数据,最终将数据存储到文件中
buffer = [];
var options = {
mimeType: 'video/webm;codecs=vp8'
}
if(!MediaRecorder.isTypeSupported(options.mimeType)){
console.error(`${options.mimeType} is not supported!`);
return;
}
try{
// 创建录制对象,用于将桌面数据录制下来
mediaRecorder = new MediaRecorder(localStream, options);
}catch(e){
console.error('Failed to create MediaRecorder:', e);
return;
}
// 当捕获到桌面数据后,该事件触发
mediaRecorder.ondataavailable = handleDataAvailable;
mediaRecorder.start(10);
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
RTP与RTCP
极端网络情况下, TCP为了传输可靠性, 会发送=>确认; 超时=>重发不断反复
例如s(sender)向r(receiver)发送, s启动一个timer
当r收到数据后向s回复ACK,这样数据不断从s发往r
当r未收到数据则s的timer会超时,s会重发并reset timer. 其中timer的超时间隔按2的指数增长(第一次1s,第二次2s,第七次64s,第八次128s则会断开tcp连接), 缺点是若重试了n次才成功则延迟很高(例如一百多秒)
所以音视频用UDP协议
在UDP之上, 加RTP头
一个I帧需要几十KB, 以太网最大传输单元是1.5KB, 故I帧需拆分为几十个包, r端再将各包组装为I帧, 需要以下几个标识即可在s端拆包并在r端组包了
- 序号: 标识是第几个包
- 起始标记: 分帧的第一个UDP包
- 结束标记: 分帧的最后一个UDP包
RTP
上述需求就体现在RTP协议里

- sequence number: 标识第几个包
- timestamp: 不同帧的时间戳不同, 一帧内各包的时间戳相同, 其起到上文起始标记和结束标记的作用
- PT: 即PayloadType, 可区分是视频包还是音频包
如下为一组音视频数据的例子, 其中PT=98是视频数据, PT=111是音频数据, 我们可按上述规则组装出视频帧
{{V=2,P=0,X=0,CC=0,M=0,PT:98,seq:13,ts:1122334455,ssrc=2345},
{V=2,P=0,X=0,CC=0,M=0,PT:111,seq:14,ts:1122334455,ssrc=888},
{V=2,P=0,X=0,CC=0,M=0,PT:98,seq:14,ts:1122334455,ssrc=2345},
{V=2,P=0,X=0,CC=0,M=0,PT:111,seq:15,ts:1122334455,ssrc=888},
{V=2,P=0,X=0,CC=0,M=0,PT:98,seq:15,ts:1122334455,ssrc=2345},
{V=2,P=0,X=0,CC=0,M=0,PT:111,seq:16,ts:1122334455,ssrc=888},
{V=2,P=0,X=0,CC=0,M=0,PT:98,seq:16,ts:1122334455,ssrc=2345},
{V=2,P=0,X=0,CC=0,M=0,PT:111,seq:17,ts:1122334455,ssrc=888},
{V=2,P=0,X=0,CC=0,M=0,PT:98,seq:17,ts:1122334455,ssrc=2345},
{V=2,P=0,X=0,CC=0,M=0,PT:111,seq:18,ts:1122334455,ssrc=888},
{V=2,P=0,X=0,CC=0,M=0,PT:98,seq:18,ts:1122334455,ssrc=2345},
{V=2,P=0,X=0,CC=0,M=0,PT:111,seq:19,ts:1122334455,ssrc=888},
{V=2,P=0,X=0,CC=0,M=0,PT:98,seq:19,ts:1122334455,ssrc=2345},
{V=2,P=0,X=0,CC=0,M=0,PT:111,seq:20,ts:1122334455,ssrc=888},
{V=2,P=0,X=0,CC=0,M=1,PT:98,seq:20,ts:1122334455,ssrc=2345}}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
RTCP
用RTP时有丢包, 乱序, 抖动问题
RTCP协议可让s端和r端知道其之间的网络质量, 其有RR(Receiver Report)和SR(Sender Report)两个报文, 是通过交换这两个报文实现的
SR报文

- V=2,指报文的版本。
- P,表示填充位,如果该位置 1,则在 RTCP 报文的最后会有填充字节(内容是按字节对齐的)。
- RC,全称 Report Count,指 RTCP 报文中接收报告的报文块个数。
- PT=200,Payload Type,也就是说 SR 的值为 200。
SDP
Session Description Protocal, 其用文本描述各端(PC端,Mac端,Android端,IOS端)的能力,能力指的是各端支持的音频编解码器是什么,编解码器的参数,传输协议,音视频媒体格式等.
下例是一个SDP片段, 描述了音频流(m=audio),该音频支持的Payload类型包括111,103,104等
其中Payload=111指OPUS编码,采样率48000,双声道
其中Payload=104指ISAC编码,采样率32000,单声道
v=0
o=- 3409821183230872764 2 IN IP4 127.0.0.1
...
m=audio 9 UDP/TLS/RTP/SAVPF 111 103 104 9 0 8 106 105 13 110 112 113 126
...
a=rtpmap:111 opus/48000/2
a=rtpmap:103 ISAC/16000
a=rtpmap:104 ISAC/32000
...
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 交换SDP信息
如下图, 建立连接后,先信令交互(其中最重要的就是SDP交换,目的是让双方知道各自设备的能力,并协商出传输协议和编解码参数,即取交集)
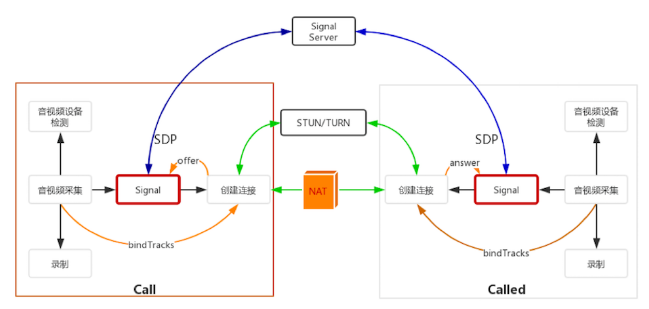
标准SDP规范
SDP的格式
=
v=0
o=- 7017624586836067756 2 IN IP4 127.0.0.1
s=-
t=0 0
...
- 1
- 2
- 3
- 4
- 5
由一个会话描述(从v=0开始), 多个媒体描述(从m=…开始)组成
例子如下, 其有两个媒体描述(视频和音频)
v=0
o=- 7017624586836067756 2 IN IP4 127.0.0.1
s=-
t=0 0
// 下面 m= 开头的两行,是两个媒体流:一个音频,一个视频。
m=audio 9 UDP/TLS/RTP/SAVPF 111 103 104 9 0 8 106 105 13 126
...
m=video 9 UDP/TLS/RTP/SAVPF 96 97 98 99 100 101 102 122 127 121 125 107 108 109 124 120 123 119 114 115 116
...
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
SDP格式
-
会话描述
是会话发起者
v=0是SDP的版本号
o=
s=指一个会话
t=指会话开始时间和结束时间, 两者均为0时表示持久会话 -
媒体描述
m= , 其中transport有RTP和UDP两种
a=或 a=:, 表示媒体属性(如a=rtpmap或a=fmtp)
a=rtpmap: /[/], rtpmap是rtp参数映射表, payload type为负载数据的类型, 编码器为VP8/VP9/OPUS等, 采样率为32000/48000, 编码参数为单声道/双声道等
a=fmtp: , 描述参数格式
下面是具体例子
v=0
o=- 4007659306182774937 2 IN IP4 127.0.0.1
s=-
t=0 0
// 以上表示会话描述
...
// 下面的媒体描述,在媒体描述部分包括音频和视频两路媒体
m=audio 9 UDP/TLS/RTP/SAVPF 111 103 104 9 0 8 106 105 13 110 112 113 126
...
a=rtpmap:111 opus/48000/2 // 对 RTP 数据的描述
a=fmtp:111 minptime=10;useinbandfec=1 // 对格式参数的描述
...
a=rtpmap:103 ISAC/16000
a=rtpmap:104 ISAC/32000
...
// 上面是音频媒体描述,下面是视频媒体描述
m=video 9 UDP/TLS/RTP/SAVPF 96 97 98 99 100 101 102 122 127 121 125 107 108 109 124 120 123 119 114 115 116
...
a=rtpmap:96 VP8/90000
...
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
WebRTC中的SDP
对标准SDP做了调整, 按功能分为如下模块
Session Metadata, 会话元数据
Network Description, 网络描述
Stream Description, 流描述
Security Description, 安全描述
Qos Grouping Description, 服务质量描述
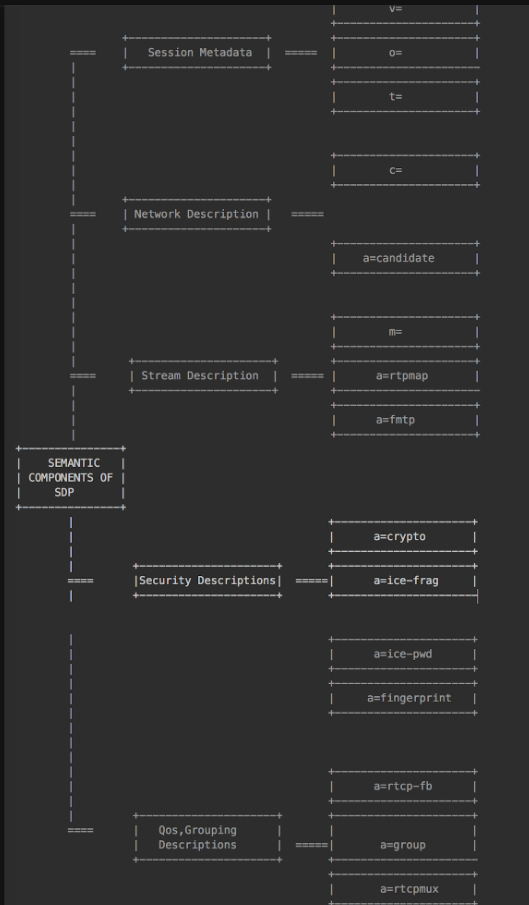
下文为具体例子
...
//======= 安全描述 ============
a=ice-ufrag:1uEe // 进入连通性检测的用户名
a=ice-pwd:RQe+y7SOLQJET+duNJ+Qbk7z// 密码,这两个是用于连通性检测的凭证
a=fingerprint:sha-256 35:6F:40:3D:F6:9B:BA:5B:F6:2A:7F:65:59:60:6D:6B:F9:C7:AE:46:44:B4:E4:73:F8:60:67:4D:58:E2:EB:9C //DTLS 指纹认证,以识别是否是合法用户
...
//======== 服务质量描述 =========
a=rtcp-mux
a=rtcp-rsize
a=rtpmap:96 VP8/90000
a=rtcp-fb:96 goog-remb // 使用 google 的带宽评估算法
a=rtcp-fb:96 transport-cc // 启动防拥塞
a=rtcp-fb:96 ccm fir // 解码出错,请求关键帧
a=rtcp-fb:96 nack // 启用丢包重传功能
a=rtcp-fb:96 nack pli // 与 fir 类似
...
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
真实业务完整例子如下
//============= 会话描述 ====================
v=0
o=- 7017624586836067756 2 IN IP4 127.0.0.1
s=-
t=0 0
...
//================ 媒体描述 =================
//================ 音频媒体 =================
/*
* 音频使用端口 1024 收发数据
* UDP/TLS/RTP/SAVPF 表示使用 dtls/srtp 协议对数据加密传输
* 111、103 ... 表示本会话音频数据的 Payload Type
*/
m=audio 1024 UDP/TLS/RTP/SAVPF 111 103 104 9 0 8 106 105 13 126
//============== 网络描述 ==================
// 指明接收或者发送音频使用的 IP 地址,由于 WebRTC 使用 ICE 传输,这个被忽略。
c=IN IP4 0.0.0.0
// 用来设置 rtcp 地址和端口,WebRTC 不使用
a=rtcp:9 IN IP4 0.0.0.0
...
//============== 音频安全描述 ================
//ICE 协商过程中的安全验证信息
a=ice-ufrag:khLS
a=ice-pwd:cxLzteJaJBou3DspNaPsJhlQ
a=fingerprint:sha-256 FA:14:42:3B:C7:97:1B:E8:AE:0C2:71:03:05:05:16:8F:B9:C7:98:E9:60:43:4B:5B:2C:28:EE:5C:8F3:17
...
//============== 音频流媒体描述 ================
a=rtpmap:111 opus/48000/2
//minptime 代表最小打包时长是 10ms,useinbandfec=1 代表使用 opus 编码内置 fec 特性
a=fmtp:111 minptime=10;useinbandfec=1
...
a=rtpmap:103 ISAC/16000
a=rtpmap:104 ISAC/32000
a=rtpmap:9 G722/8000
...
//================= 视频媒体 =================
m=video 9 UDP/TLS/RTP/SAVPF 100 101 107 116 117 96 97 99 98
...
//================= 网络描述 =================
c=IN IP4 0.0.0.0
a=rtcp:9 IN IP4 0.0.0.0
...
//================= 视频安全描述 =================
a=ice-ufrag:khLS
a=ice-pwd:cxLzteJaJBou3DspNaPsJhlQ
a=fingerprint:sha-256 FA:14:42:3B:C7:97:1B:E8:AE:0C2:71:03:05:05:16:8F:B9:C7:98:E9:60:43:4B:5B:2C:28:EE:5C:8F3:17
...
//================ 视频流描述 ===============
a=mid:video
...
a=rtpmap:100 VP8/90000
//================ 服务质量描述 ===============
a=rtcp-fb:100 ccm fir
a=rtcp-fb:100 nack // 支持丢包重传,参考 rfc4585
a=rtcp-fb:100 nack pli
a=rtcp-fb:100 goog-remb // 支持使用 rtcp 包来控制发送方的码流
a=rtcp-fb:100 transport-cc
...
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
媒体协商
涉及创建连接和信令两部分

- RTCPeerConnection: 媒体协商通过此对象实现
var pcConfig = null;
var pc = new RTCPeerConnection(pcConfig);
- 1
- 2
- 媒体协商的过程
Offer为呼叫方, Anwer为被呼叫方
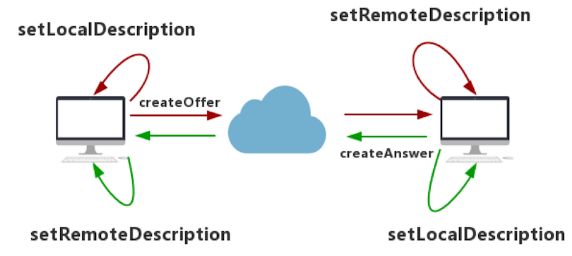
首先,呼叫方创建 Offer 类型的 SDP 消息。创建完成后,调用 setLocalDescriptoin 方法将该 Offer 保存到本地 Local 域,然后通过信令将 Offer 发送给被呼叫方。
被呼叫方收到 Offer 类型的 SDP 消息后,调用 setRemoteDescription 方法将 Offer 保存到它的 Remote 域。作为应答,被呼叫方要创建 Answer 类型的 SDP 消息,Answer 消息创建成功后,再调用 setLocalDescription 方法将 Answer 类型的 SDP 消息保存到本地的 Local 域。最后,被呼叫方将 Answer 消息通过信令发送给呼叫方。至此,被呼叫方的工作就完部完成了。
接下来是呼叫方的收尾工作,呼叫方收到 Answer 类型的消息后,调用 RTCPeerConnecton 对象的 setRemoteDescription 方法,将 Answer 保存到它的 Remote 域。
至此,整个媒体协商过程处理完毕。
当通讯双方拿到彼此的 SDP 信息后,就可以进行媒体协商了。媒体协商的具体过程是在 WebRTC 内部实现的,我们就不去细讲了。你只需要记住本地的 SDP 和远端的 SDP 都设置好后,协商就算成功了。
- 呼叫方创建Offer
function doCall() {
console.log('Sending offer to peer');
pc.createOffer(setLocalAndSendMessage, handleCreateOfferError);
}
function setLocalAndSendMessage(sessionDescription) {
pc.setLocalDescription(sessionDescription);
sendMessage(sessionDescription);
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 被呼叫方收到Offer
socket.on('message', function(message) {
...
} else if (message.type === 'offer') {
pc.setRemoteDescription(new RTCSessionDescription(message));
doAnswer();
} else if (...) {
...
}
....
});
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 被呼叫方创建Answer
function doAnswer() {
pc.createAnswer().then(
setLocalAndSendMessage,
onCreateSessionDescriptionError
);
}
- 1
- 2
- 3
- 4
- 5
- 6
- 呼叫方收到Answer
socket.on('message', function(message) {
...
} else if (message.type === 'answer') {
pc.setRemoteDescription(new RTCSessionDescription(message));
} else if (...) {
...
}
....
});
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 此时, 媒体协商过程完成, 紧接着WebRTC底层库会收集Candidate并做连通性检测, 最终在通话双方建立链路
- 谁先发起呼叫谁就发offer,另一方发answer;这完全由应用层控制;比如第一个人进入房间后,就在哪里等待,当发现第二个人上来的时候它就给对方发offer 就好了。如果两个人同时进入房间,就在服务器端建个队列,让他们顺序进入就好了,非常好处理对吧?另外两端都发offer 那协商必然失败。
- 发送信令用的是socket: 由于信令数据量不大,所以你可选择的协议就比较多了,TCP、HTTP/HTTPS、WS/WSS,都可以,底层实现都是用的socket
建立连接
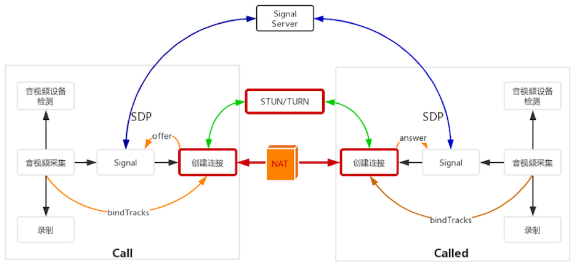
同一网段与不同网段
通信的双方我们称为 A 和 B;
A 为呼叫方,B 为被呼叫方;
C 为中继服务器,也称为 relay 服务器或 TURN 服务器。
- 场景1: 双方处于同一网段
A 与 B 进行通信,假设它们现在处于同一个办公区的同一个网段内。在这种情况下,A 与 B 有两种连通路径:
一种是双方通过内网直接进行连接;
另一种是通过公网,也就是通过公司的网关,从公网绕一圈后再进入公司实现双方的通信。
相较而言,显然第一种连接路径是最好的。 A 与 B 在内网连接就好了,谁会舍近求远呢?
但现实却并非如此简单,要想让 A 与 B 直接在内网连接,首先要解决的问题是: A 与 B 如何才能知道它们是在同一个网段内呢?
这个问题还真不好回答,也正是由于这个问题不太好解决,所以,现在有很多通信类产品在双方通信时,无论是否在同一个内网,它们都统一走了公网。不过,WebRTC 很好的解决了这个问题,后面我们可以看一下它是如何解决这个问题的。
- 场景2: 双方处于不同点
A 与 B 进行通信,它们分别在不同的地点,比如一个在北京,一个在上海,此时 A 与 B 通信必须走公网。但走公网也有两条路径:
一是通过 P2P 的方式双方直接建立连接;
二是通过中继服务器进行中转,即 A 与 B 都先与 C 建立连接,当 A 向 B 发消息时, A 先将数据发给 C,然后 C 再转发给 B;同理, B 向 A 发消息时,B 先将消息发给 C,然后 C 再转给 A。
对于这两条路径你该如何选择呢?对于 WebRTC 来讲,它认为通过中继的方式会增加 A 与 B 之间传输的时长,所以它优先使用 P2P 方式;如果 P2P 方式不通,才会使用中继的方式。
什么是Candidte
表示 WebRTC 与远端通信时使用的协议、IP 地址和端口,一般由以下字段组成:
本地 IP 地址
本地端口号
候选者类型,包括 host、srflx 和 relay
优先级
传输协议
访问服务的用户名
如果用一个结构表示,那么它就如下面所示的样子:
{
IP: xxx.xxx.xxx.xxx,
port: number,
type: host/srflx/relay,
priority: number,
protocol: UDP/TCP,
usernameFragment: string
...
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
每一端都会提供许多候选者,比如你的主机有两块网卡,那么每块网卡的不同端口都是一个候选者。
WebRTC 会按照上面描述的格式对候选者进行排序,然后按优先级从高到低的顺序进行连通性测试,当连通性测试成功后,通信的双方就建立起了连接。
在众多候选者中,host 类型的候选者优先级是最高的。在 WebRTC 中,首先对 host 类型的候选者进行连通性检测,如果它们之间可以互通,则直接建立连接。其实,host 类型之间的连通性检测就是内网之间的连通性检测。WebRTC 就是通过这种方式巧妙地解决了大家认为很困难的问题。
如果 host 类型候选者之间无法建立连接,那么 WebRTC 则会尝试次优先级的候选者,即 srflx 类型的候选者。也就是尝试让通信双方直接通过 P2P 进行连接,如果连接成功就使用 P2P 传输数据;如果失败,就最后尝试使用 relay 方式建立连接。
收集Candidate
host 类型,即本机内网的 IP 和端口;
srflx 类型, 即本机 NAT 映射后的外网的 IP 和端口;
relay 类型,即中继服务器的 IP 和端口。
STUN协议
srflx 类型的 Candidate 实际上就是内网地址和端口经 NAT 映射后的外网地址和端口
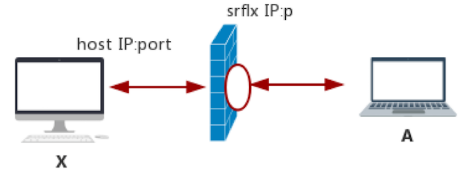
如果主机没有公网地址,是无论如何都无法访问公网上的资源的。例如你要通过百度搜索一些信息,如果你的主机没有公网地址的话,百度搜索到的结果怎么传给你呢?
一般通过STUN协议,输入内网IP,可通过NAT输出公网IP
可通过如下方式搭建
首先在外网搭建一个 STUN 服务器,现在比较流行的 STUN 服务器是 CoTURN,你可以到 GitHub 上自己下载源码编译安装。
当 STUN 服务器安装好后,从内网主机发送一个 binding request 的 STUN 消息到 STUN 服务器。
STUN 服务器收到该请求后,会将请求的 IP 地址和端口填充到 binding response 消息中,然后顺原路将该消息返回给内网主机。此时,收到 binding response 消息的内网主机就可以解析 binding response 消息了,并可以从中得到自己的外网 IP 和端口。
- 1
- 2
- 3
TURN协议
这里需要说明一点,relay 服务是通过 TURN 协议实现的。所以我们经常说的 relay 服务器或 TURN 服务器它们是同一个意思,都是指中继服务器。
ICE
: Interactive Connectivity Establishment, 就是上述讲的获取与各种类型Candidate的过程: 在本机收集所有的 host 类型的 Candidate,通过 STUN 协议收集 srflx 类型的 Candidate,使用 TURN 协议收集 relay 类型的 Candidate。
NAT穿越
NAT解决了如下2个问题
- IPV4地址不够用, 故让多台机器公用同一个公网IP地址, 内部用内网IP通信
- 安全: 主机隐藏在内网, 外面有NAT挡着, 黑客难以获取主机的公网IP和端口
缺点就是每个主机没有自己的公网IP地址, 让互联网变得更麻烦.
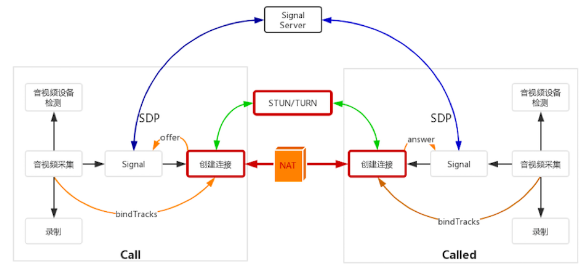
完全锥形NAT
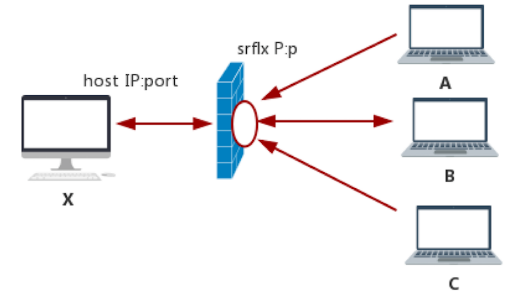
当host主机通过NAT访问外网主机B时, 就会在NAT上打个洞, 所有知道这个洞的主机(如A和C)都可通过此洞与内网主机通信
打洞就是在NAT上建立内外网映射表,即{内网IP,内网port,外网IP,外网port}的4元组
大多数打洞的都是UDP协议, 因为UDP是无连接协议, 没有连接状态, 只要你发数据给它, 它就能收到
而TCP必须三次握手建立连接才能收到数据
IP限制锥形NAT
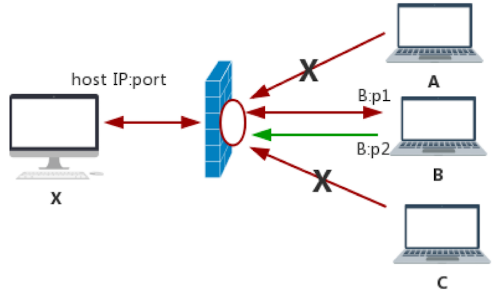
只有被访问的外网IP才可打洞, 否则会被NAT服务器将数据包丢弃, 记录{内网IP,内网port,外网IP,外网port,被访问主机的IP}的5元组
端口限制锥形NAT
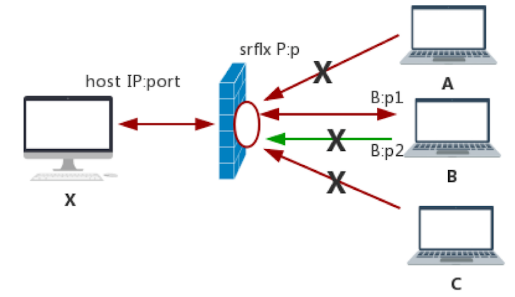
还对端口限制, 记录{内网IP,内网port,外网IP,外网port,被访问主机的IP,被访问主机的Port}的6元组
对称型NAT
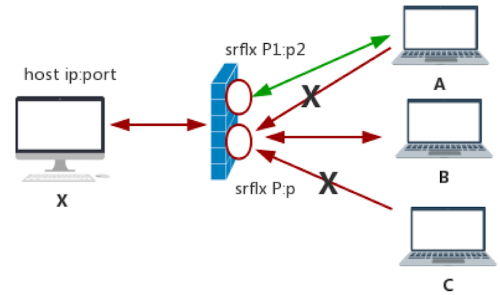
它与端口限制型 NAT 最大的不同在于,如果 host 主机访问 A 时,它会在 NAT 上重新开一个“洞”,而不会使用之前访问 B 时打开的“洞”。也就是说对称型 NAT 对每个连接都使用不同的端口,甚至更换 IP 地址,而端口限制型 NAT 的多个连接则使用同一个端口,这对称型 NAT 与端口限制型 NAT 最大的不同。
它的这种特性为 NAT 穿越造成了很多麻烦,尤其是对称型 NAT 碰到对称型 NAT,或对称型 NAT 遇到端口限制型 NAT 时,基本上双方是无法穿越成功的。
NAT类型检测
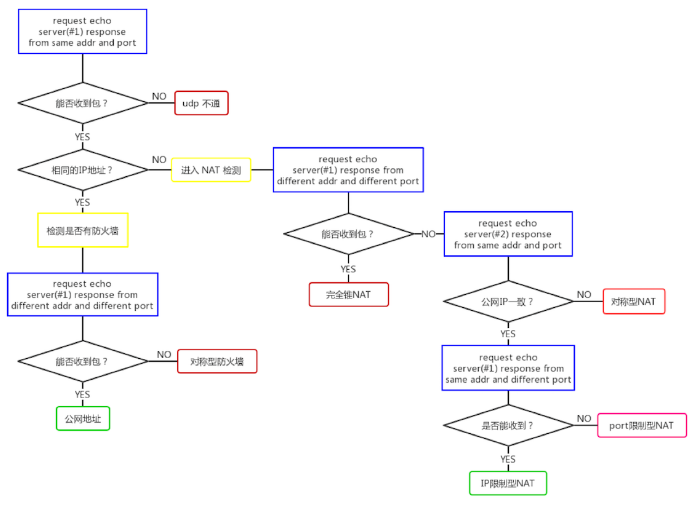
接下来,我们就对上面这张图做下详细的解释。这里需要注意的是,每台服务器都是双网卡的,而每个网卡都有一个自己的公网 IP 地址。
-
第一步,判断是否有 NAT 防护
主机向服务器 #1 的某个 IP 和端口发送一个请求,服务器 #1 收到请求后,会通过同样的 IP 和端口返回一个响应消息。
如果主机收不到服务器 #1 返回的消息,则说明用户的网络限制了 UDP 协议,直接退出。
如果能收到包,则判断返回的主机的外网 IP 地址是否与主机自身的 IP 地址一样。如果一样,说明主机就是一台拥有公网地址的主机;如果不一样,就跳到下面的步骤 6。
如果主机拥有公网 IP,则还需要进一步判断其防火墙类型。所以它会再向服务器 #1 发一次请求,此时,服务器 #1 从另外一个网卡的 IP 和不同端口返回响应消息。
如果主机能收到,说明它是一台没有防护的公网主机;如果收不到,则说明有对称型的防火墙保护着它。
继续分析第 3 步,如果返回的外网 IP 地址与主机自身 IP 不一致,说明主机是处于 NAT 的防护之下,此时就需要对主机的 NAT 防护类型做进一步探测。 -
第二步,探测 NAT 环境
在 NAT 环境下,主机向服务器 #1 发请求,服务器 #1 通过另一个网卡的 IP 和不同端口给主机返回响应消息。
如果此时主机可以收到响应消息,说明它是在一个完全锥型 NAT之下。如果收不到消息还需要再做进一步判断。
如果主机收不到消息,它向服务器 #2(也就是第二台服务器)发请求,服务器 #2 使用收到请求的 IP 地址和端口向主机返回消息。
主机收到消息后,判断从服务器 #2 获取的外网 IP 和端口与之前从服务器 #1 获取的外网 IP 和端口是否一致,如果不一致说明该主机是在对称型 NAT之下。
如果 IP 地址一样,则需要再次发送请求。此时主机向服务器 #1 再次发送请求,服务器 #1 使用同样的 IP 和不同的端口返回响应消息。
此时,如果主机可以收到响应消息说明是IP 限制型 NAT,否则就为端口限制型 NAT。
至此,主机所在的 NAT 类型就被准确地判断出来了。有了主机的 NAT 类型你就很容易判断两个主机之间到底能不能成功地进行 NAT 穿越了。
Nodejs实现简单的信令服务器
WebRTC只约束了客户端, 服务器可以让各大公司根据各自业务实现, 这样更聚焦, 更易推广
所以学习时, 必须自己实现信令服务器,. 否则run不起来
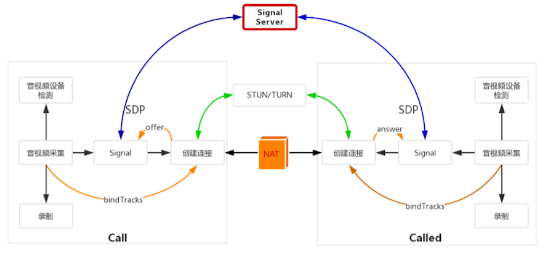
其功能如下
- 房间管理: 如用户AB需通话, 需将他们加入同一房间
- 信令交换: 同一房间内, 交互信令
下图是Nodejs工作原理
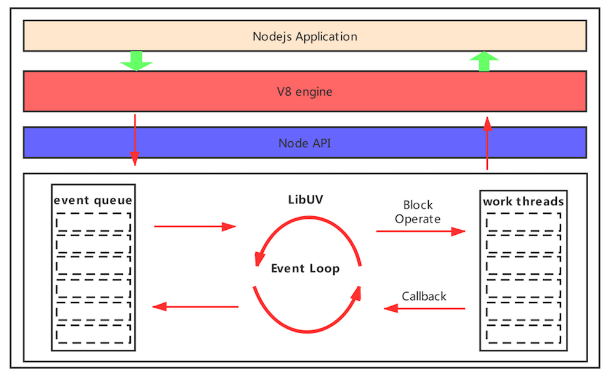
用Nodejs开发http server后, 其会监听端口(底层用libuv处理该端口的http请求)
当有网络请求时,会被放入事件队列, libuv会监听该事件队列, 发现事件时, 若是简单的请求则直接处理返回, 若是复杂的请求则从线程池中取线程做异步处理
处理后有2种可能, 若处理完成则向用户响应, 若需进一步处理则再生成时间并插入事件队列, 循环往复永不停歇

socket.io和Nodejs的关系
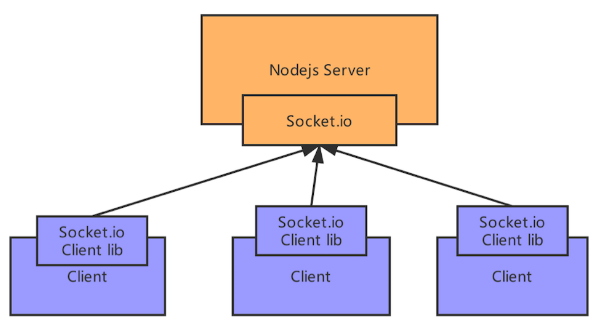
S是server, C是client, 按如下通信
// 发command命令
S: socket.emit('cmd’);
C: socket.on('cmd',function(){...});
// 发command命令, 带data数据
S: socket.emit('action', data);
C: socket.on('action',function(data){...});
// 发command命令, 带2个data数据
S: socket.emit(action,arg1,arg2);
C: socket.on('action',function(arg1,arg2){...});
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
实现客户端
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta http-equiv="X-UA-Compatible" content="IE=edge">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>WebRTC client</title>
</head>
<body>
<script src="/socket.io/socket.io.js"></script>
<script src="js/room_client.js"></script>
</body>
</html>
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
var isInitiator;
room = prompt('Enter room name:'); // 弹出一个输入窗口
const socket = io.connect(); // 与服务端建立 socket 连接
if (room !== '') { // 如果房间不空,则发送 "create or join" 消息
console.log('Joining room ' + room);
socket.emit('create or join', room);
}
socket.on('full', (room) => { // 如果从服务端收到 "full" 消息
console.log('Room ' + room + ' is full');
});
socket.on('empty', (room) => { // 如果从服务端收到 "empty" 消息
isInitiator = true;
console.log('Room ' + room + ' is empty');
});
socket.on('join', (room) => { // 如果从服务端收到 “join" 消息
console.log('Making request to join room ' + room);
console.log('You are the initiator!');
});
socket.on('log', (array) => {
console.log.apply(console, array);
});
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
实现server
const static = require('node-static');
const http = require('http');
const file = new(static.Server )();
const app = http.createServer(function (req, res) {
file.serve(req, res);
}).listen(2013);
const io = require('socket.io').listen(app); // 侦听 2013
io.sockets.on('connection', (socket) => {
// convenience function to log server messages to the client
function log(){
const array = ['>>> Message from server: '];
for (var i = 0; i < arguments.length; i++) {
array.push(arguments[i]);
}
socket.emit('log', array);
}
socket.on('message', (message) => { // 收到 message 时,进行广播
log('Got message:', message);
// for a real app, would be room only (not broadcast)
socket.broadcast.emit('message', message); // 在真实的应用中,应该只在房间内广播
});
socket.on('create or join', (room) => { // 收到 “create or join” 消息
var clientsInRoom = io.sockets.adapter.rooms[room];
var numClients = clientsInRoom ? Object.keys(clientsInRoom.sockets).length : 0; // 房间里的人数
log('Room ' + room + ' has ' + numClients + ' client(s)');
log('Request to create or join room ' + room);
if (numClients === 0){ // 如果房间里没人
socket.join(room);
socket.emit('created', room); // 发送 "created" 消息
} else if (numClients === 1) { // 如果房间里有一个人
io.sockets.in(room).emit('join', room);
socket.join(room);
socket.emit('joined', room); // 发送 “joined”消息
} else { // max two clients
socket.emit('full', room); // 发送 "full" 消息
}
socket.emit('emit(): client ' + socket.id +
' joined room ' + room);
socket.broadcast.emit('broadcast(): client ' + socket.id +
' joined room ' + room);
});
});
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
RTCPeerConnection类
可理解为它是一个功能超强的socket
在本文的例子中,为了最大化地减少额外的工作量,所以我们选择在同一个页面中进行音视频的互通,这样就不需要开发、安装信令服务器了。不过这样也增加了一些理解的难度,所以在阅读下面的内容时,你一定要在脑子中想象:每一个 RTCPeerConnection 就是一个客户端,这样就比较容易理解后面的内容了。
- 在 WebRTC 端与端之间建立连接,包括三个任务:
- 为连接的每个端创建一个 RTCPeerConnection 对象,并且给 RTCPeerConnection 对象添加一个本地流,该流是从 getUserMedia() 获取的;
- 获取本地媒体描述信息,即 SDP 信息,并与对端进行交换;
- 获得网络信息,即 Candidate(IP 地址和端口),并与远端进行交换。
获取本地音视频流
从getUserMedia获取流, 添加到对应的RTCPeerConnection对象中
...
// 创建 RTCPeerConnection 对象
let localPeerConnection = new RTCPeerConnection(servers);
...
// 调用 getUserMedia API 获取音视频流
navigator.mediaDevices.getUserMedia(mediaStreamConstraints).
then(gotLocalMediaStream).
catch(handleLocalMediaStreamError);
// 如果 getUserMedia 获得流,则会回调该函数
// 在该函数中一方面要将获取的音视频流展示出来
// 另一方面是保存到 localSteam
function gotLocalMediaStream(mediaStream) {
...
localVideo.srcObject = mediaStream;
localStream = mediaStream;
...
}
...
// 将音视频流添加到 RTCPeerConnection 对象中
localPeerConnection.addStream(localStream);
...
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
交换媒体信息
我们首先创建 offer 类型的 SDP 信息。A 调用 RTCPeerConnection 的 createOffer() 方法,得到 A 的本地会话描述,即 offer 类型的 SDP 信息:
localPeerConnection.createOffer(offerOptions)
.then(createdOffer).catch(setSessionDescriptionError);
- 1
- 2
如果 createOffer 函数调用成功,会回调 createdOffer 方法,并在 createdOffer 方法中做以下几件事儿。
A 使用 setLocalDescription() 设置本地描述,然后将此会话描述发送给 B。B 使用 setRemoteDescription() 设置 A 给它的描述作为远端描述。
之后,B 调用 RTCPeerConnection 的 createAnswer() 方法获得它本地的媒体描述。然后,再调用 setLocalDescription 方法设置本地描述并将该媒体信息描述发给 A。
A 得到 B 的应答描述后,就调用 setRemoteDescription() 设置远程描述。
代码如下
// 当创建 offer 成功后,会调用该函数
function createdOffer(description) {
...
// 将 offer 保存到本地
localPeerConnection.setLocalDescription(description)
.then(() => {
setLocalDescriptionSuccess(localPeerConnection);
}).catch(setSessionDescriptionError);
...
// 远端 pc 将 offer 保存起来
remotePeerConnection.setRemoteDescription(description)
.then(() => {
setRemoteDescriptionSuccess(remotePeerConnection);
}).catch(setSessionDescriptionError);
...
// 远端 pc 创建 answer
remotePeerConnection.createAnswer()
.then(createdAnswer)
.catch(setSessionDescriptionError);
}
// 当 answer 创建成功后,会回调该函数
function createdAnswer(description) {
...
// 远端保存 answer
remotePeerConnection.setLocalDescription(description)
.then(() => {
setLocalDescriptionSuccess(remotePeerConnection);
}).catch(setSessionDescriptionError);
// 本端 pc 保存 answer
localPeerConnection.setRemoteDescription(description)
.then(() => {
setRemoteDescriptionSuccess(localPeerConnection);
}).catch(setSessionDescriptionError);
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
端和端建立连接
localPeerConnection.onicecandidate= handleConnection(event);
- 1
上面这段代码为 localPeerConnection 对象的 icecandidate 事件添加了一个处理函数,即 handleConnection。
当 Candidate 变为有效时,handleConnection 函数将被调用,具体代码如下:
...
function handleConnection(event) {
// 获取到触发 icecandidate 事件的 RTCPeerConnection 对象
// 获取到具体的 Candidate
const peerConnection = event.target;
const iceCandidate = event.candidate;
if (iceCandidate) {
// 创建 RTCIceCandidate 对象
const newIceCandidate = new RTCIceCandidate(iceCandidate);
// 得到对端的 RTCPeerConnection
const otherPeer = getOtherPeer(peerConnection);
// 将本地获到的 Candidate 添加到远端的 RTCPeerConnection 对象中
otherPeer.addIceCandidate(newIceCandidate)
.then(() => {
handleConnectionSuccess(peerConnection);
}).catch((error) => {
handleConnectionFailure(peerConnection, error);
});
...
}
}
function getOtherPeer(peerConnection) {
return (peerConnection === localPeerConnection) ? remotePeerConnection : localPeerConnection;
}
...
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
显示远端媒体流
收到媒体流后, 放到video标签上显示
localPeerConnection.onaddstream = handleRemoteStreamAdded;
...
function handleRemoteStreamAdded(event) {
console.log('Remote stream added.');
remoteStream = event.stream;
remoteVideo.srcObject = remoteStream;
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
当有数据到来时, 浏览器会收到addstream事件并回调onaddstream函数.
完整代码详见https://github.com/avdance/webrtc_web/tree/master/12_peerconnection
控制传输速率
物理链路质量
- 丢包。这个比较好理解,如果物理链路不好,经常出现丢包,这样就会造成接收端无法组包、解码,从而对音视频服务质量产生影响。
- 延迟。指通信双方在传输数据时,数据在物理链路上花费的时间比较长。对于实时通信来说,200ms 以内的延迟是最好的,这样通话双方的感觉就像是在面对面谈话;如果延迟是在 500 ms 以内,通话双方的体验也还不错,有点像打电话的感觉;如果延迟达到 800ms,还能接受,但有明显的迟滞现像;但如果延迟超过 1 秒,那就不是实时通话了!
- 抖动。指的是数据一会儿快、一会儿慢,很不稳定。如果不加处理的话,你看到的视频效果就是一会儿快播了、一会儿又慢动作,给人一种眩晕的感觉,时间长了会非常难受。不过对于 WebRTC 来讲,它通过内部的 JitterBuffer(可以简单地理解为一块缓冲区)就能很好地解决该问题。
带宽大小
带宽大小指的是每秒钟可以传输多少数据。比如 1M 带宽,它表达的是每秒钟可以传输 1M 个 bit 位,换算成字节就是 1Mbps/8 = 128KBps,也就是说 1M 带宽实际每秒钟只能传输 128K 个 Byte。
当带宽固定的情况下,如何才能让数据传输得更快呢?答案是充分利用带宽。这句话有点抽象,它实际的含义是把带宽尽量占满,但千万别超出带宽的限制。这里还是以 1M 带宽为例,如果每秒都传输 1M 的数据,这样传输数据的速度才是最快,多了、少了都不行。每秒传输的数据少了,就相当于有 100 辆车,本来每次可以走 10 辆,10 趟就走完了,可你却让它一次走 1 辆,这样肯定慢;而每秒传输多了,就会发生网络拥塞,就像每天上下班堵车一样,你说它还能快吗?
传输速率
传输码率是指对网络传输速度的控制。举个例子,假设你发送的每个网络包都是 1500 字节,如果每秒钟发 100 个包,它的传输码率是多少呢?即 100*1.5K = 150K 字节,再换算成带宽的话就是 150KB * 8 = 1.2M。但如果你的带宽是 1M,那每秒钟发 100 个包肯定是多了,这个时候就要控制发包的速度,把它控制在 1M 以内,并尽量地接近 1M,这样数据传输的速度才是最快的。
当然,如果你的压缩码率本来就很小,比如每秒钟只有 500kbps,而你的带宽是 1Mbps,那你还有必要对传输码率进行控制吗?换句话说,一条马路可以一起跑 10 辆车,但你现在只有 3 辆,显然你就没必要再控制同时发车的数量了。
分辨率和帧率
对于 1 帧未压缩过的视频帧,如果它的分辨率是 1280 * 720,存储成 RGB 格式,则这一帧的数据为 1280 * 720 * 3 * 8(3 表示 R、G、B 三种颜色,8 表示将 Byte 换算成 bit),约等于 22Mb;而存成 YUV420P 格式则约等于 11Mb,即 1280 * 720 * 1.5 * 8。
按照上面的公式计算,如果你把视频的分辨率降到 640 * 360,则这一帧的数据就降到了原来的 1/4,这个效果还是非常明显的。所以,如果你想降低码率,最直接的办法就是降分辨率。
传输速率的控制
在 WebRTC 中速率的控制是使用压缩码率的方法来控制的,而不是直接通过传输包的多少来控制的, 如下
var vsender = null; // 定义 video sender 变量
var senders = pc.getSenders(); // 从 RTCPeerConnection 中获得所有的 sender
// 遍历每个 sender
senders.forEach( sender => {
if(sender && sender.track.kind === 'video'){ // 找到视频的 sender
vsender = sender;
}
});
var parameters = vsender.getParameters(); // 取出视频 sender 的参数
if(!parameters.encodings){ // 判断参数里是否有 encoding 域
return;
}
// 通过 在 encoding 中的 maxBitrate 可以限掉传输码率
parameters.encodings[0].maxBitrate = bw * 1000;
// 将调整好的码率重新设置回 sender 中去,这样设置的码率就起效果了。
vsender.setParameters(parameters)
.then(()=>{
console.log('Successed to set parameters!');
}).catch(err => {
console.error(err);
})
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
开关音视频
远端静音
- 播放端不给播放器喂数据
在播放端有两种方法,一种是不让播放器播出来,另一种是不给播放器喂数据,将收到的音频流直接丢弃。在播放端控制的优点是实现简单;缺点是虽然音频没有被使用,但它仍然占用网络带宽,造成带宽的浪费。
video标签的muted可控制
<video id=remote autoplay muted playsinline/>
- 1
var remotevideo = document.querySelector('video#remote');
remotevideo.muted = false;
- 1
- 2
- 播放端丢掉音频流
在收到远端的音视频流后,将远端的 AudioTrack 不添加到要展示的 MediaStream 中,也就是让媒体流中不包含音频流
var remoteVideo = document.querySelector('video#remote');
...
{
// 创建与远端连接的对象
pc = new RTCPeerConnection(pcConfig);
...
// 当有远端流过来时,触发该事件
pc.ontrack = getRemoteStream;
...
}
...
function getRemoteStream(e){
// 得到远端的音视频流
remoteStream = e.streams[0];
// 找到所有的音频流
remoteStream.getAudioTracks().forEach((track)=>{
if (track.kind === 'audio') { // 判断 track 是类型
// 从媒体流中移除音频流
remoteStream.removeTrack(track);
}
});
// 显示视频
remoteVideo.srcObject = e.streams[0];
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
在发送端控制也可以细分成两种方法实现,即停止音频的采集和停止音频的发送。对于 1 对 1 实时直播系统来说,这两种方法的效果是一样的。但对于多对多来说,它们的效果就大相径庭了。因为停止采集音频后,所有接收该音频的用户都不能收到音频了,这显然与需求不符;而停止向某个用户发送音频流,则符合用户的需求。
- 发送端: 关闭采集
向信令服务器发一条静音命令, 远端收到后执行如下代码
// 获取本地音视频流
function gotStream(stream) {
localStream = stream;
localVideo.srcObject = stream;
}
// 获得采集音视频数据时限制条件
function getUserMediaConstraints() {
var constraints = {
"audio": false,
"video": {
"width": {
"min": "640",
"max": "1280"
},
"height": {
"min": "360",
"max": "720"
}
}
};
return constraints;
}
...
// 采集音视频数据
function captureMedia() {
...
if (localStream) {
localStream.getTracks().forEach(track => track.stop());
}
...
// 采集音视频数据的 API
navigator.mediaDevices.getUserMedia(getUserMediaConstraints())
.then(gotStream)
.catch(e => {
...
});
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 发送端: 关闭track传输
在 getUserMedia 函数的回调函数中获得本地媒体流,然后在将其与 RTCPeerConnection 对象进行绑定时,对 track 做判断,如果是音频就不进行绑定,关闭了通道,这样对方就收不到音频数据了,从而达到远端静音的效果
var localStream = null;
// 创建 peerconnection 对象
var pc = new RTCPeerConnection(server);
...
// 获得流
function gotStream(stream){
localStream = stream;
}
...
//peerconnection 与 track 进行绑定
function bindTrack() {
//add all track into peer connection
localStream.getTracks().forEach((track)=>{
if(track.kink !== 'audio') {
pc.addTrack(track, localStream);
}
});
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
自己静音
无论是 1 对 1 实时互动,还是多人实时互动,它的含义都是一样的,就是所有人都不能听到“我”的声音。因此,你只需停止对本端音频数据的采集就可以达到这个效果。
将 constraints 中的 auido 属性设置为 false 就好了
关远端视频
从播放端控制只能使用不给播放器喂数据这一种方法,因为播放器不支持关闭视频播放的功能;
从发送端控制是通过停止向某个用户发送视频数据这一种方法来实现的。而另一个停止采集则不建议使用,因为这样一来,其他端就都看不到你的视频了。
关自己视频
关闭所有视频流的发送来实现该需求。之所以要这样,是因为视频还有本地预览,只要视频设备可用,本地预览就应该一直存在
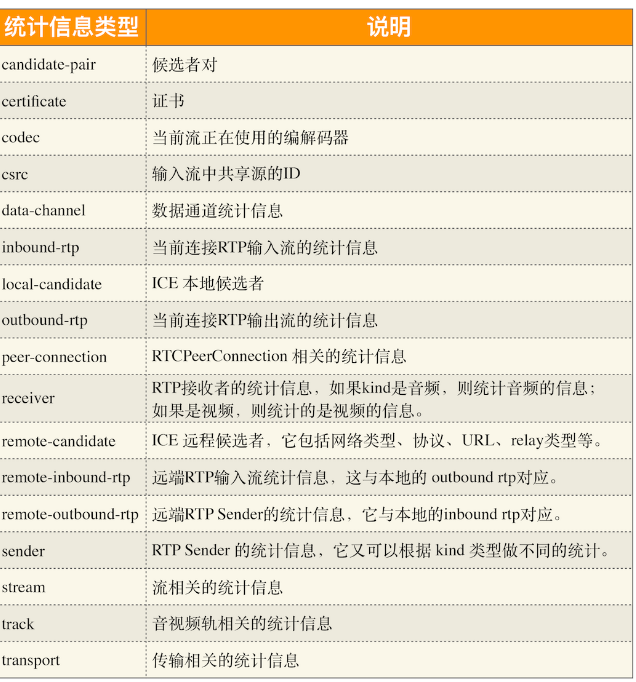
WebRTC中的统计数据
chrome://webrtc-internals
promise = rtcPeerConnection.getStats(selector)
- 1
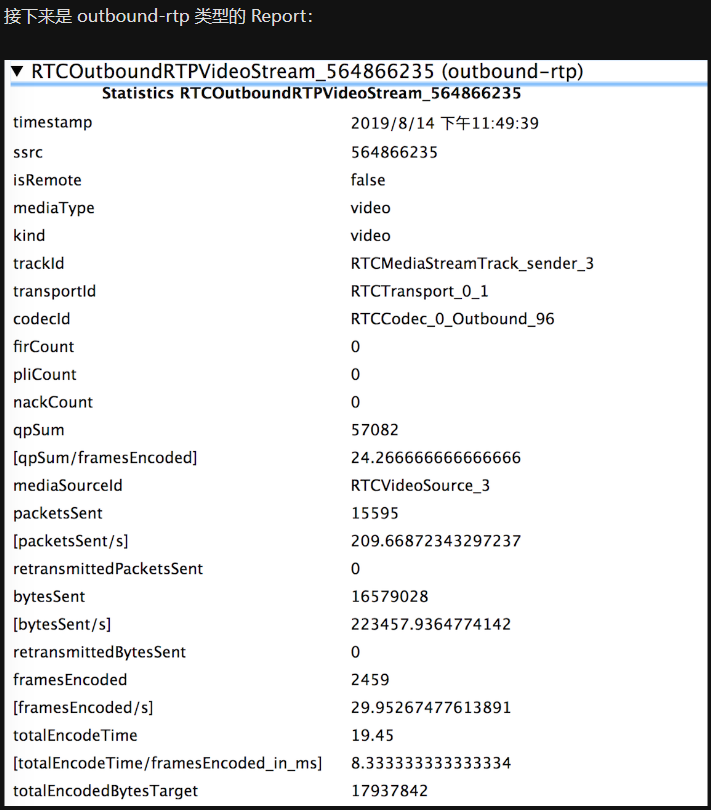
完整例子如下
// 获得速个连接的统计信息
pc.getStats().then(
// 在一个连接中有很多 report
reports => {
// 遍历每个 report
reports.forEach( report => {
// 将每个 report 的详细信息打印出来
console.log(report);
});
}).catch( err=>{
console.error(err);
});
);
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14


RTCRtpSender 对象的 getStats 方法只统计与发送相关的统计信息。
RTCRtpReceiver 对象的 getStats 方法则只统计与接收相关的统计信息。
文本聊天
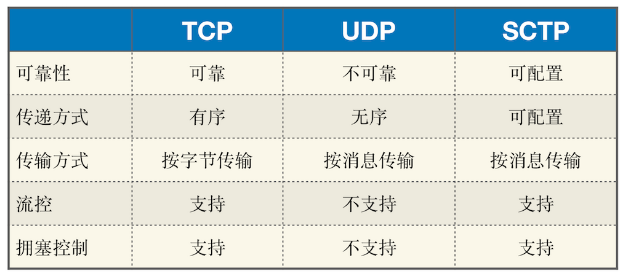
WebRTC使用SCTP协议, 即可在可靠,有序模式,也可在不可靠,无需模式.
传输文件
如果断点续传, 需要增加信令server, 把文件拆分为若干包, 接收端每收到一个包即告知发送端已收到
- 创建RTCDataChannel对象
// 创建 RTCDataChannel 对象的选项
var options = {
ordered: true, // 当 ordered 设置为真后,就可以保证数据的有序到达
maxRetransmits : 30 // maxRetransmits 设置为 30,则保证在有丢包情况下可对丢包重传,并最多尝试重传 30 次
};
// 创建 RTCPeerConnection 对象
var pc = new RTCPeerConnection();
// 创建 RTCDataChannel 对象
var dc = pc.createDataChannel("dc", options);
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 通过RTCDataChannel对象接收数据
要实现 RTCDataChannel 对象的 4 个重要事件(打开、关闭、接收到消息以及出错时接收到事件)的回调函数
每当该函数被调用时,说明被传输文件的一部分数据已经到达了。这时你只需要简单地将收到的这块数据 push 到 receiveBuffer 数组中即可。
当文件的所有数据都收到后,即receivedSize === fileSize条件成立时,你就可以以 receiveBuffer[] 数组为参数创建一个 Blob 对象了。紧接着,再给这个 Blob 对象创建一个下载地址,这样接收端的用户就可以通过该地址获取到文件了
var receiveBuffer = []; // 存放数据的数组
var receiveSize = 0; // 数据大小
...
onmessage = (event) => {
// 每次事件被触发时,说明有数据来了,将收到的数据放到数组中
receiveBuffer.push(event.data);
// 更新已经收到的数据的长度
receivedSize += event.data.byteLength;
// 如果接收到的字节数与文件大小相同,则创建文件
if (receivedSize === fileSize) { //fileSize 是通过信令传过来的
// 创建文件
var received = new Blob(receiveBuffer, {type: 'application/octet-stream'});
// 将 buffer 和 size 清空,为下一次传文件做准备
receiveBuffer = [];
receiveSize = 0;
// 生成下载地址
downloadAnchor.href = URL.createObjectURL(received);
downloadAnchor.download = fileName;
downloadAnchor.textContent =
`Click to download '${fileName}' (${fileSize} bytes)`;
downloadAnchor.style.display = 'block';
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 文件读取和发送
数据的读取是通过 sendData 函数实现的。在该函数中,使用 FileReader 对象每次从文件中读取 16K 的数据,然后再调用 RTCDataChannel 对象的 send 方法将其发送出去。
这段代码中有两个关键点:一是 sendData 整个函数的执行是 readSlice(0) 开始的;二是 FileReader 对象的 onload 事件是在有数据被读入到 FileReader 的缓冲区之后才触发的。
而在这个回调函数中是一个循环,不断地从文件中读取数据、发送数据,直到读到文件结束为止
function sendData(){
var offset = 0; // 偏移量
var chunkSize = 16384; // 每次传输的块大小
var file = fileInput.files[0]; // 要传输的文件,它是通过 HTML 中的 file 获取的
...
// 创建 fileReader 来读取文件
fileReader = new FileReader();
...
fileReader.onload = e => { // 当数据被加载时触发该事件
...
dc.send(e.target.result); // 发送数据
offset += e.target.result.byteLength; // 更改已读数据的偏移量
...
if (offset < file.size) { // 如果文件没有被读完
readSlice(offset); // 读取数据
}
}
var readSlice = o => {
const slice = file.slice(offset, o + chunkSize); // 计算数据位置
fileReader.readAsArrayBuffer(slice); // 读取 16K 数据
};
readSlice(0); // 开始读取数据
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 通过信令传递文件基本信息
接收端是如何知道发送端所要传输的文件大小、类型以及文件名的呢?
解决的办法就是在传输文件之前,发送端先通过信令服务器将要传输文件的基本信息发送给接收端。
下例, 发送端首先获得被传输文件的基本信息,如文件名、文件类型、文件大小等,然后再通过 socket.io 以 JSON 的格式将这些信息发给信令服务器
...
// 获取文件相关的信息
fileName = file.name;
fileSize = file.size;
fileType = file.type;
lastModifyTime = file.lastModified;
// 向信令服务器发送消息
sendMessage(roomid,
{
// 将文件信息以 JSON 格式发磅
type: 'fileinfo',
name: file.name,
size: file.size,
filetype: file.type,
lastmodify: file.lastModified
}
);
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
下例, 信令服务器收到该消息后不做其他处理,直接转发到接收端。
socket.on('message', (roomid, data) => {
...
// 如果是 fileinfo 类型的消息
if(data.hasOwnProperty('type') && data.type === 'fileinfo'){
// 读出文件的基本信息
fileName = data.name;
fileType = data.filetype;
fileSize = data.size;
lastModifyTime = data.lastModify;
...
}
...
});
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
传输安全
- 非对称加密
有一个人叫小 K,他有一把特制的锁,以及两把特制的钥匙——公钥和私钥。这把锁有个非常有意思的特点,那就是:用公钥上了锁,只能用私钥打开;而用私钥上的锁,则只能公钥打开。
这下好了,小 K 正好交了几个异性笔友,他们在书信往来的时候,难免有一些“小秘密”不想让别人知道。因此,小 K 多造了几把公钥,给每个笔友一把,当笔友给他写好的书信用公钥上了锁之后,就只能由小 K 打开,因为只有小 K 有私钥(公钥上的锁只有私钥可以打开),这样就保证了书信内容的安全。
从这个例子中,你可以看到小 K 的笔友使用公钥对内容进行了加密,只有小 K 可以用自己手中的私钥进行解密,这种对同一把锁使用不同钥匙进行加密 / 解密的方式称为非对称加密
- 数字签名
首先我们来讲一下数字签名是解决什么问题的。实际上,数字签名并不是为了防止数据内容被盗取的,而是解决如何能证明数据内容没有窜改的问题。为了让你更好地理解这个问题,我们还是结合具体的例子来说明吧。
还是以前面的小 K 为例,他觉得自己与多个异性交往太累了,并且看破红尘决定出家了。于是他写了一封公开信,告诉他的异性朋友这个决定。但小 K 的朋友们认为这太不可思议了,她们就猜测会不会是其他人冒充小 K 写的这封信呢!
那小 K 该如何证明这封公开信就是他自己写的呢?他想到了一个办法:将信中的内容做个 Hash 值(只要是同样的内容就会产生同样的 Hash 值),并用他的私钥将这个 Hash 值进行了加密。这样他的异性朋友就可以通过她们各自手里的公钥进行解密,然后将解密后的 Hash 值与自己计算的公开信的 Hash 值做对比(这里假设她们都是技术高手哈),发现 Hash 值是一样的,于是确认这封信真的是小 K 写的了。
数字签名实际上就是上面这样一个过程。在互联网上,很多信息都是公开的,但如何能证明这些公开的信息确实是发布人所写的呢?就是使用数字签名。
- 数字证书
实际上,在数字签名中我们是假设小 K 的朋友们手里的公钥都是真的公钥,如果这个假设条件成立的话,那整个流程运行就没有任何问题。但是否有可能她们手里的公钥是假的呢?这种情况还是存在很大可能性的。
那该如何避免这种情况发生呢?为了解决这个问题,数字证书就应运而生了。
小 K 的朋友们为了防止自己手里的公钥被冒充或是假的,就让小 K 去“公证处”(即证书授权中心)对他的公钥进行公证。“公证处”用自己的私钥对小 K 的公钥、身份证、地址、电话等信息做了加密,并生成了一个证书。
这样小 K 的朋友们就可以通过“公证处”的公钥及小 K 在“公证处”生成的证书拿到小 K 的公钥了,从此再也不怕公钥被假冒了。
到这里,从非对称加密,到数字签名,再到数字证书就形成了一整套安全机制。在这个安全机制的保护下,就没人可以非法获得你的隐私数据了。
- X509
了解了互联网的整套安全机制之后,接下来我们再来看一下真实的证书都包括哪些内容。这里我们以 X509 为例。X509 是一种最通用的公钥证书格式。它是由国际电信联盟(ITU-T)制定的国际标准,主要包含了以下内容:
版本号,目前的版本是 3。
证书持有人的公钥、算法(指明密钥属于哪种密码系统)的标识符和其他相关的密钥参数。
证书的序列号,是由 CA 给予每一个证书分配的唯一的数字型编号。
从中你可以看到,最关键的一点是通过 X509 证书你可以拿到“证书持有人公钥”,有了这个公钥你就可以对发布人发布的信息进行确认了。
在真实的场景中,你一般不会去直接处理数字证书,而是通过 OpenSSL 库进行处理,该库的功能特别强大,是专门用于处理数据安全的一套基础库,在下一篇文章中我们会对它做专门介绍。
常见加密算法
- MD5: 摘要算法, 无论输入多长的数据, 都输出128bits的位串
- SHA1: 160位摘要, 比MD5更安全
- HMAC: 用MD5, SHA1对秘钥和输入, 生成摘要
- RSA: 最流行的非对称加密
- ECC: 比RSA更安全, 性能稍差
通过 DTLS 协议就可以有效地解决 A 与 B 之间交换公钥时可能被窃取的问题
DTLS 就是运行在 UDP 协议之上的简化版本的 TLS
下图是DTLS握手过程
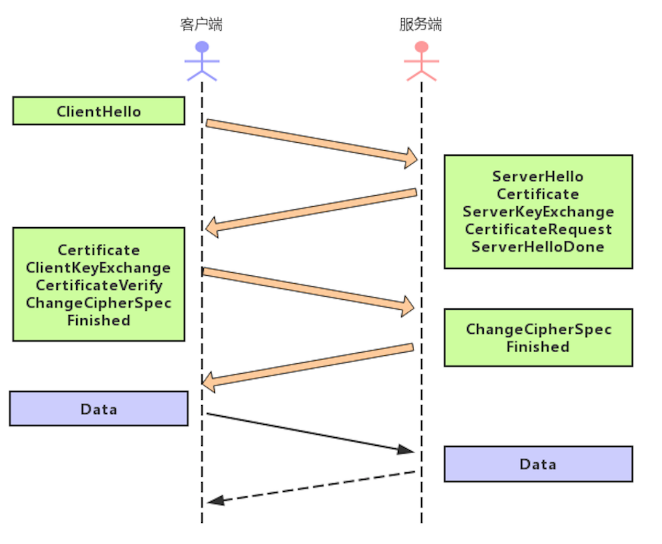
在 WebRTC 中为了更有效地保护音视频数据,所以需要使用 DTLS 协议交换公钥证书,并确认使用的密码算法,这个过程在 DTLS 协议中称为握手协议。
首先 DTLS 协议采用 C/S 模式进行通信,其中发起请求的一端为客户端,接收请求的为服务端。
客户端向服务端发送 ClientHello 消息,服务端收到请求后,回 ServerHello 消息,并将自己的证书发送给客户端,同时请求客户端证书。
客户端收到证书后,将自己的证书发给服务端,并让服务端确认加密算法。
服务端确认加密算法后,发送 Finished 消息,至此握手结束。
DTLS 握手结束之后,通信双方就可以开始相互发送音视频数据了。
WebRTC 使用了非常有名的 libsrtp 库将原来的 RTP/RTCP 协议数据转换成 SRTP/SRTCP 协议数据
一对一音视频直播实战
浏览器上通过 HTTP 请求下来的 JavaScript 脚本是不允话访问音视频设备的, 而HTTPS可以
https://github.com/avdance/webrtc_web/tree/master/23_living
多人音视频架构
多方通信架构无外乎以下三种方案。
- Mesh 方案,即多个终端之间两两进行连接,形成一个网状结构。比如 A、B、C 三个终端进行多对多通信,当 A 想要共享媒体(比如音频、视频)时,它需要分别向 B 和 C 发送数据。同样的道理,B 想要共享媒体,就需要分别向 A、C 发送数据,依次类推。这种方案对各终端的带宽要求比较高。
- MCU(Multipoint Conferencing Unit)方案,该方案由一个服务器和多个终端组成一个星形结构。各终端将自己要共享的音视频流发送给服务器,服务器端会将在同一个房间中的所有终端的音视频流进行混合,最终生成一个混合后的音视频流再发给各个终端,这样各终端就可以看到 / 听到其他终端的音视频了。实际上服务器端就是一个音视频混合器,这种方案服务器的压力会非常大。
- SFU(Selective Forwarding Unit)方案,该方案也是由一个服务器和多个终端组成,但与 MCU 不同的是,SFU 不对音视频进行混流,收到某个终端共享的音视频流后,就直接将该音视频流转发给房间内的其他终端。它实际上就是一个音视频路由转发器。
项目编译
HLS
FFmpeg 生成 HLS 切片
ffmpeg -i test.mp4 -c copy -start_number 0 -hls_time 10 -hls_list_size 0 -hls_segment_filename test%03d.ts index.m3u8
- 1
如下, HLS 必须要有一个.m3u8的索引文件。它是一个播放列表文件,文件的编码必须是 UTF-8 格式
#EXTM3U
#EXT-X-VERSION:3 // 版本信息
#EXT-X-TARGETDURATION:11 // 每个分片的目标时长
#EXT-X-MEDIA-SEQUENCE:0 // 分片起始编号
#EXTINF:10.922578, // 分片实际时长
test000.ts // 分片文件
#EXTINF:9.929578, // 第二个分片实际时长
test001.ts // 第二个分片文件
...
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
在播放 HLS 流时,就有很多开源库可用。在移动端可以使用 Ijkplayer,在浏览器上可以使用 video.js,在 PC 端可以使用 VLC。而服务端的 HLS 切片则是由 CDN 网络完成的,你只需要向 CDN 网络推流就可以了,CDN 网络会直接将上传的流进行 HLS 切片。而在 CDN 网络内部,它就是使用我们上面所介绍的 FFmpeg 开源库编译好的工具来完成切片工作的。
flv
FLV 文件就是由“FLV Header + RTMP 数据”构成的。这也揭开了 FLV 与 RTMP 之间的关系秘密,即 FLV 是在 RTMP 数据之上加了一层“马甲”。
FLV 文件是一个流式的文件格式。该文件中的数据部分是由多个 “PreviousTagSize + Tag”组成的。这样的文件结构有一个天然的好处,就是你可以将音视频数据随时添加到 FLV 文件的末尾,而不会破坏文件的整体结构。
在众多的媒体文件格式中,只有 FLV 具有这样的特点。像 MP4、MOV 等媒体文件格式都是结构化的,也就是说音频数据与视频数据是单独存放的。当服务端接收到音视频数据后,如果不通过 MP4 的文件头,你根本就找不到音频或视频数据存放的位置。
正是由于 FLV 是流式的文件格式,所以它特别适合在音视频录制中使用。这里我们举个例子,在一个在线教育的场景中,老师进入教室后开启了录制功能,服务端收到信令后将接收到的音视数据写入到 FLV 文件。在上课期间,老师是可以随时将录制关掉的,老师关闭录制时,FLV 文件也就结束了。当老师再次开启录制时,一个新的 FLV 文件被创建,然后将收到的音视频数据录制到新的 FLV 文件中。 这样当一节课结束后,可能会产生多个 FLV 文件,然后在收到课结束的消息后,录制程序需要将这几个 FLV 文件进行合并,由于 FLV 文件是基于流的格式,所以合并起来也特别方便,只需要按时间段将后面的 FLV 直接写到前面 FLV 文件的末尾即可。
定义 flv.js
意义: 在没有flash的时代, 可在浏览器播放flv文件.
工作: 转封装
流程: 将flv文件转为BMFF片段(一种MP4格式),交给html5的<video>标签让浏览器的Media Source Extensions将MP4播放.(因video标签支持MP4)
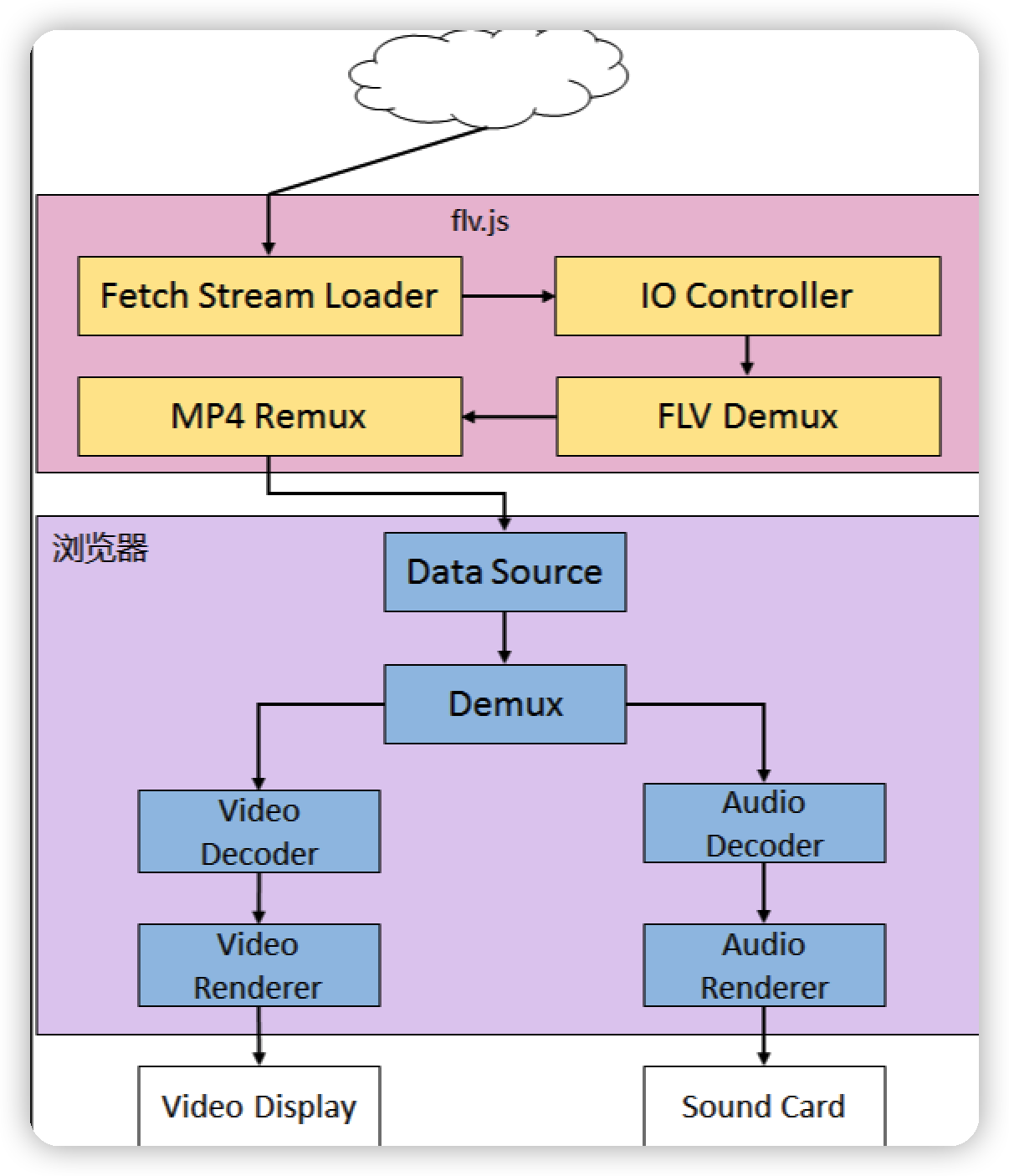
- flv.js详细流程:
- Fetch Stream Loader: 通过URL从互联网获取http-flv流, 即通过http协议下载数据, 并交给IO Controller
- IO Controller: 把数据传给flv demux
- FLV Demux: 去掉FLV文件头, TAG头, 拿到H264/AAC裸流
- MP4 Remux: 在H264/AAC裸流, 添加MP4头, 其多媒体协议格式是BMFF, 其会把封装好的文件传给
浏览器的Data Source对象
- 浏览器详细流程:
- Data Source: 专门接收
媒体数据的对象, 收数据, 传给Demux模块 - Demux: 解封装, 去MP4头, 得到H264/AAC裸流
- Video Decoder: 视频解码, 变为可显示的帧
- Audio Decoder: 音频解码, 变为可播放
- Video Renderer: 显示视频渲染
- Audio Renderer: 播放音频
- Video Display: 视频, 图形显示设备的抽象对象
- Sound Card: 声卡设备的抽象对象
- Data Source: 专门接收
使用 flv.js
yarn init
yarn add flv.js
- 1
- 2
<!-- 引入 flv.js 库 -->
<script src="node_modules/flv.js/dist/flv.js"></script>
<script src="https://cdn.bootcdn.net/ajax/libs/flv.js/1.6.2/flv.js"></script>
<!-- 设置 video 标签 -->
<video id="flv_file" controls autoplay muted>
You Browser doesn't support video tag
</video>
<script>
// 通过 JavaScript 脚本创建 FLV Player
if (flvjs.isSupported()) {
var videoElement = document.getElementById('flv_file');
var flvPlayer = flvjs.createPlayer({
type: 'flv',
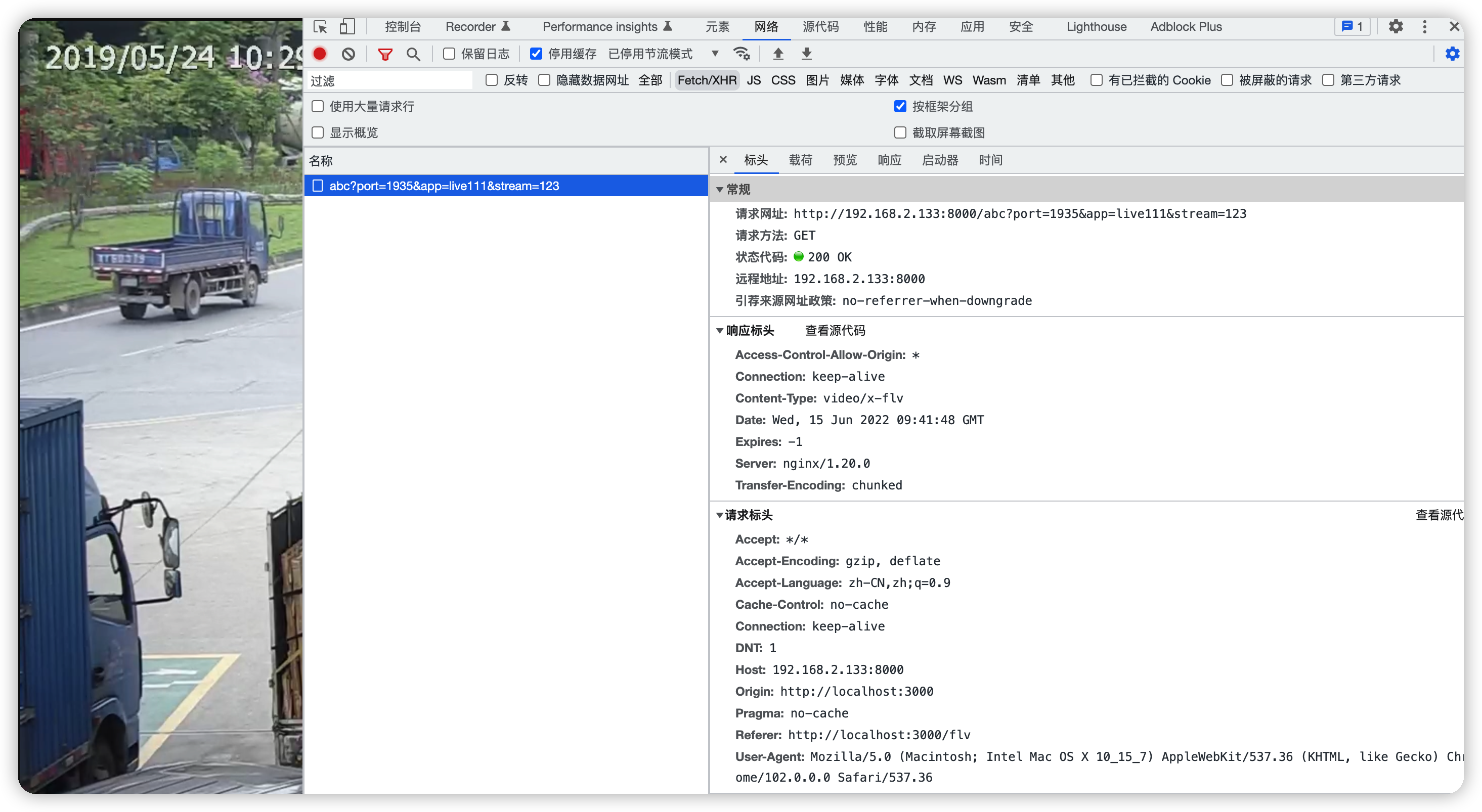
url: 'http://192.168.2.133:8000/abc?port=1935&app=live111&stream=123'
});
flvPlayer.attachMediaElement(videoElement);
flvPlayer.load();
flvPlayer.play();
}
</script>
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
nginx-http-flv-module
- ffmpeg把rtsp转为rtmp推到nginx的rtmp server
- nginx用
nginx-http-flv-module把rtmp转为flv - 浏览器用flv.js的get请求, http协议, get请求, 获取流媒体
ffmpeg安装
wget ffmpeg-4.1.tar.bz2
tar -xvJf ffmpeg-release-amd64-static.tar.xz
/etc/profile中添加export PATH="/root/y/ffmpeg-5.0.1-amd64-static":$PATH
ffmpeg -i test.mp4 ## 测试
- 1
- 2
- 3
- 4
nginx安装
下载nginx
wget http://nginx.org/download/nginx-1.20.0.tar.gz
tar -zxvf nginx-1.20.0.tar.gz
cd nginx-1.20.0
- 1
- 2
- 3
带插件源码编译
wget https://github.com/winshining/nginx-http-flv-module/archive/refs/heads/master.zip
unzip master.zip
cd /root/y/nginx-1.20.0
apt-get install libpcre3 libpcre3-dev zlib1g-dev libssl-dev libxml2-dev libxslt1-dev libgeoip-dev
./configure --add-module=/root/y/nginx-http-flv-module-master --with-http_mp4_module --with-http_flv_module
make && make install(若报错则把objs/Makefile中的-Werror移除)
/etc/profile中添加export PATH="/usr/local/nginx/sbin":$PATH
- 1
- 2
- 3
- 4
- 5
- 6
- 7
安装后路径如下
nginx path prefix: "/usr/local/nginx"
nginx binary file: "/usr/local/nginx/sbin/nginx"
nginx modules path: "/usr/local/nginx/modules"
nginx configuration prefix: "/usr/local/nginx/conf"
nginx configuration file: "/usr/local/nginx/conf/nginx.conf"
nginx pid file: "/usr/local/nginx/logs/nginx.pid"
nginx error log file: "/usr/local/nginx/logs/error.log"
nginx http access log file: "/usr/local/nginx/logs/access.log"
nginx http client request body temporary files: "client_body_temp"
nginx http proxy temporary files: "proxy_temp"
nginx http fastcgi temporary files: "fastcgi_temp"
nginx http uwsgi temporary files: "uwsgi_temp"
nginx http scgi temporary files: "scgi_temp"
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
配置nginx
- /etc/nginx/nginx.conf中添加rtmp的server
rtmp {
server {
listen 1935;
chunk_size 4000;
application live111 {
live on; # 这是
hls on; # 这是打开hls
hls_path /tmp/hls; # 这是存放hls视频片段的文件夹
}
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- /etc/nginx/nginx.conf的http内部添加如下server
http {
server {
listen 8000; # 流地址http的端口号
location /abc { # 这是流地址的appname
flv_live on; # 这是流地址允许flv
add_header Access-Control-Allow-Origin *; # 允许跨域
}
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
启动nginx -c /etc/nginx/nginx.conf
ss -lp | grep 1935检查rtmp server是否已启动
测试推流
测试确认rtsp://192.168.2.165/live/oil1gas可播放
推流 ffmpeg -rtsp_transport tcp -i rtsp://192.168.2.165/live/oil1gas -f flv -r 25 -s 1920*1080 -an rtmp://192.168.2.133:1935/live/123
其中appname是live, streamname是123
测试vlc可播放 rtmp://192.168.2.133:1935/live111/123
在上述nginx.conf中配置的/tmp/hls可看到不断有m3u8片段文件生成, 代表nginx正常工作
- 1
- 2
- 3
- 4
- 5
flv.js测试
npm i -g serve --全局安装serve命令
serve --在当前路径启动http server
- 1
- 2
当前路径写一个flv.html如下, 其中flv.js放到js文件夹下
<!-- 引入 flv.js 库 -->
<script src="js/flv.js"></script>
<!-- 设置 video 标签 -->
<video id="flv_file" controls autoplay muted>
You Browser doesn't support video tag
</video>
<script>
// 通过 JavaScript 脚本创建 FLV Player
if (flvjs.isSupported()) {
var videoElement = document.getElementById('flv_file');
var flvPlayer = flvjs.createPlayer({
type: 'flv',
url: 'http://192.168.2.133:8000/abc?port=1935&app=live&stream=123'
});
flvPlayer.attachMediaElement(videoElement);
flvPlayer.load();
flvPlayer.play();
}
</script>
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
访问http://localhost:3000/flv即可观看