
- 1Vue3+TypeScript+Pinia初始化项目,vscode报错解决办法!_vscode vue3+ts 老是提示代码错误
- 210大经典数据分析模型,你知道几个?(二)_scp分析模型
- 3python波形图librosa_librosa语音信号处理
- 4阿里云ECS安全组操作介绍_您所选的 1 个实例 至少要属于一个安全组,将不会执行移出安全组操作。
- 5线上问题解决:使用FFmpeg截取视频图片出现旋转问题(亲测解决,必看!!)_ffmpegframegrabber 取视频截图 旋转
- 6Unity之合并多张图片为一张大图(二)_unity 多张序列帧合并1张
- 7C# Socket发送请求及监听_c# seriport持续监听
- 8vLLM部署推理及相关重要参数_vllm prompt 参数
- 9轻松打造自己的聊天机器人:JAVA版ChatGPT_chatgpt-web-java
- 10【Linux】安装Tomcat详细教程(图文教程)_linux安装tomcat
什么是 prompts, completions, tokens and meta-learning /in-context-learning_prompt completion
赞
踩
从字面上看,任何文本都可以用作提示(prompts)——输入一些文本然后得到一些文本。 我们虽然知道 GPT-3 对随机字符串的处理很有趣,但是编写一个有效的提示才能更好的真正的让GPT理解我们要它做什么。
提示(prompts)
Prompt是怎么样让GPT-3知道你想要它做什么事情。 这就像编程,但使用简单的英语。 所以,你必须知道你想要做什么,然后使用文字和纯文本把它表达出来,不需要编写代码。
当你写Prompts时,要记住的主要事情是让 GPT-3 知道接下来应该出现的文本,包括指令(instructions)和例子(examples)等方式提供的上下文(context)帮助模型找出最佳可能的补全(completion) . 另外,编写的质量也很重要——例如,拼写、不清楚的文本和提供的示例数量都会影响补全(completion)的质量。
另一个关键的因素是Prompt的大小。 虽然Prompt可以是任何文本,但提示和生成的补全(Completion)加起来必须少于 2,048 个标记。 我们将在本章稍后部分讨论标记,但那大约是 1,500 字。
因此,提示可以是任何文本,并且没有像编写代码时那样必须遵循的硬性规定。 但是,有一些关于构建提示文本的准则可以帮助获得最佳结果。
提示(Prompts)类型
我们将深入探讨不同提示类型的写法,这些不同的提示类型有如下:
- Zero-shot prompts (零次提示)
- One-shot prompts (一次提示)
- Few-shot prompts (多次提示)

Zero-shot prompts(零次提示)
Zero-shot prompts 是最简单的提示类型。 它仅提供任务描述或让 GPT-3开始的一些文本。 同样,它实际上可以是任何文本:一个问题、故事的开头、指令(instructions)——任何东西,但是你的提示文本越清晰,GPT-3 就越容易理解接下来应该出现什么。 以下是生成电子邮件消息的零次提示(zero-shot prompt)示例。 补全(Completion)将从提示结束的地方开始——在本例中,在 Subject:: 之后
Write an email to my friend Jay from me Steve thanking him for covering my shift this past Friday. Tell him to let me know if I can ever return the favor.
Subject:
以下屏幕截图是来自基于 Web 的测试工具的 Playground 。注意原来的提示文字是粗体,补缺Completion显示为常规文字:
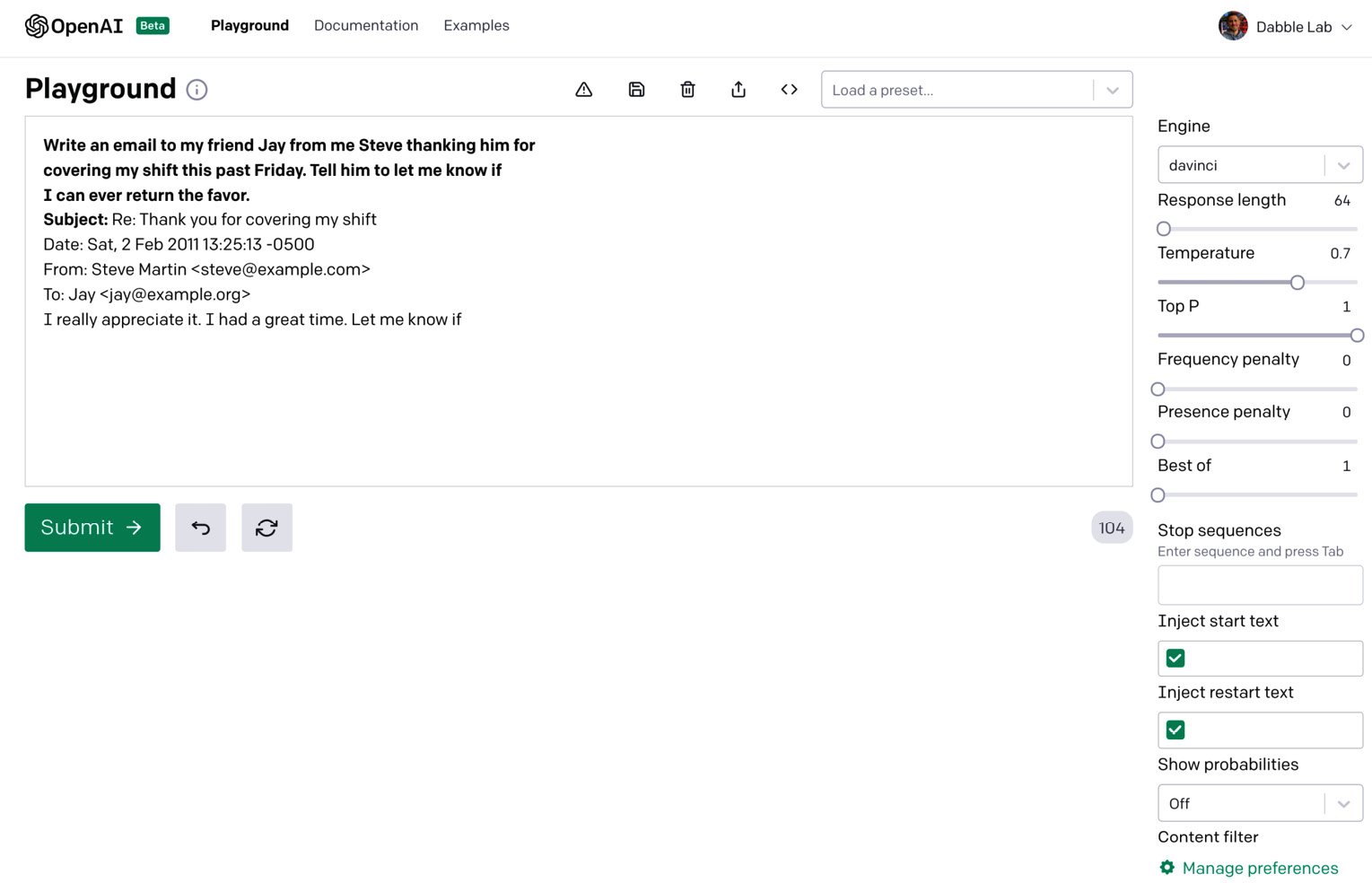
可以看出,零次提示只是几句话或对任务的简短描述,没有任何示例。 有时这就是 GPT-3 完成任务所需的全部。 其他时候,您可能需要包含一个或多个示例。 提供单个示例的提示称为一次提示。
One-shot prompts(一次提示)
One-shot prompt提供了一个示例,GPT-3 可以使用它来学习如何最好地完成任务。 以下是提供任务描述(第一行)和单个示例(第二行)的一次提示的示例:
A list of actors in the movie Star Wars
1. Mark Hamill: Luke Skywalker
仅仅从描述和一个例子中,GPT-3 就知道了任务是什么以及应该完成它。 在此示例中,任务是生成电影《星球大战》中的演员列表。 以下屏幕截图显示了从此提示生成的内容:
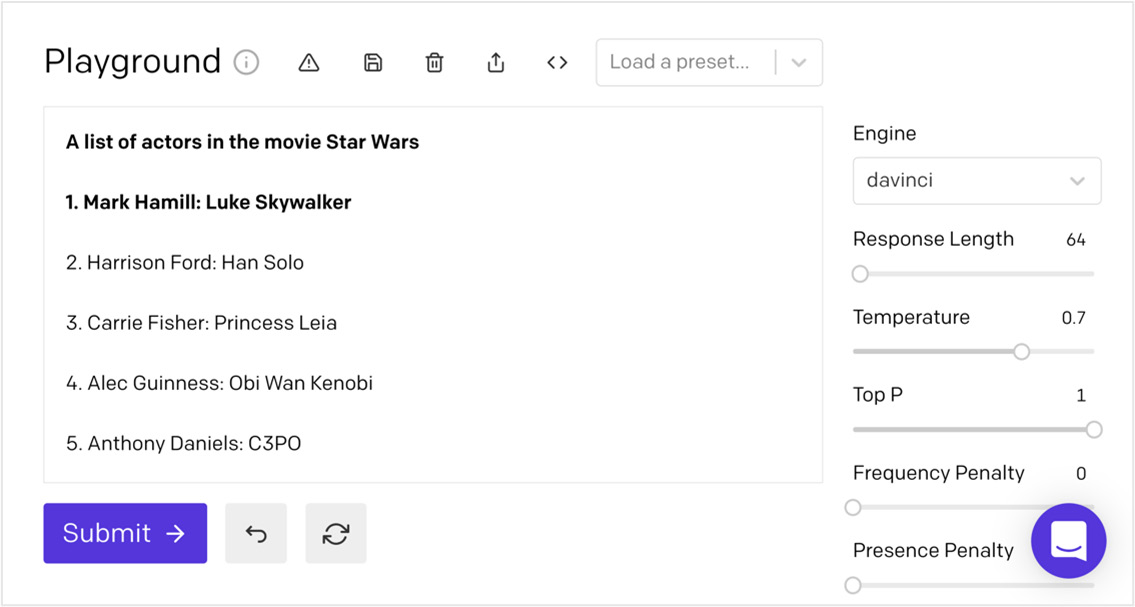
One-shot prompt非常适合列表和普遍理解的模式。 但有时您需要的例子不止一个。 在这种情况下,您将使用几次提示。
few-shot prompt (多次提示)
few-shot prompt 提供了多个示例——通常是 10 到 100 个。多个示例对于显示 GPT-3 应该继续的模式很有用。 Few-shot 提示和更多示例可能会提高完成质量,因为提示为 GPT-3 提供了更多可供学习的内容。
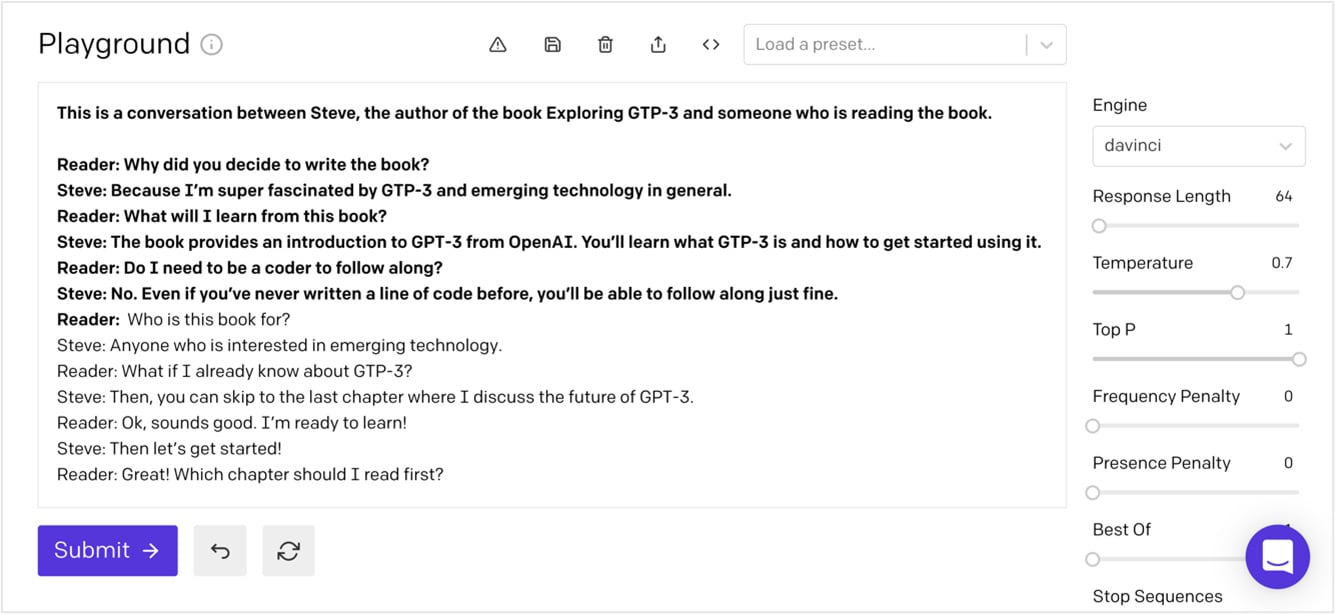
下面是生成模拟对话的多次提示的示例。 注意,这些示例提供了一个来回对话,其中包含对话中可能会说的话:
This is a conversation between Steve, the author of the book Exploring GPT-3 and someone who is reading the book.
Reader: Why did you decide to write the book?
Steve: Because I'm super fascinated by GPT-3 and emerging technology in general.
Reader: What will I learn from this book?
Steve: The book provides an introduction to GPT-3 from OpenAI. You'll learn what GPT-3 is and how to get started using it.
Reader: Do I need to be a coder to follow along?
Steve: No. Even if you've never written a line of code before, you'll be able to follow along just fine.
Reader:
在下面的屏幕截图中,您可以看到 GPT-3 继续在提示中提供的示例中开始的模拟对话:
现在您了解了不同的提示类型,让我们看一些其它的提示示例。
Prompts 示例
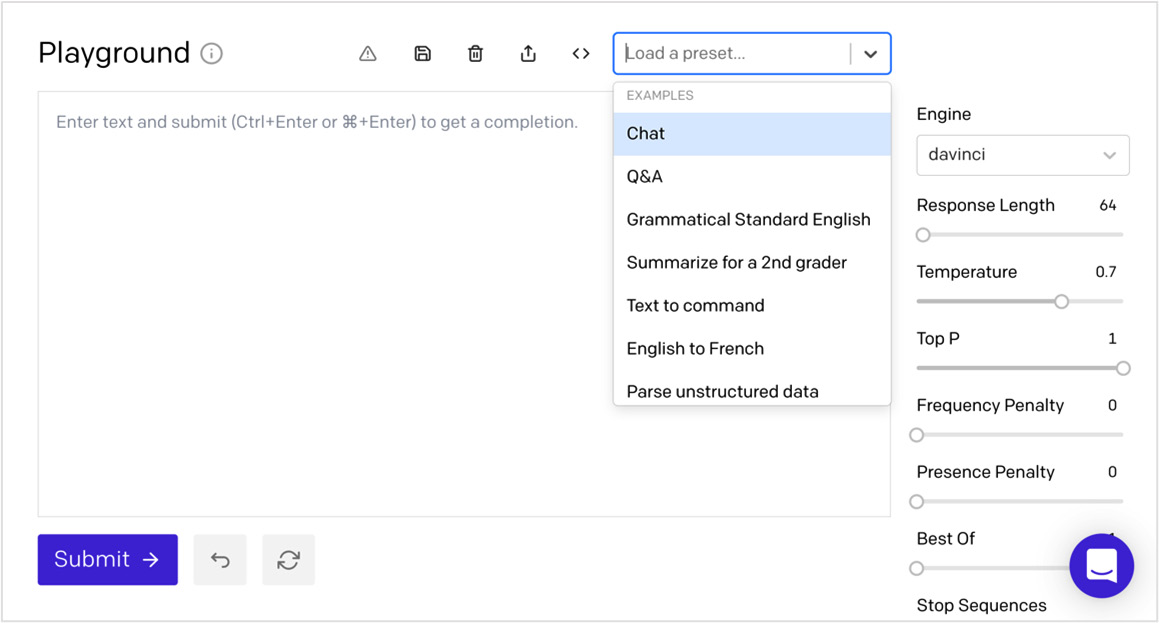
OpenAI API 可以处理各种任务。 可能性范围从生成原创故事到执行复杂的文本分析,以及介于两者之间的一切。 为了熟悉 GPT-3 可以执行的任务种类,OpenAI 提供了许多提示示例。 您可以在 Playground 和 OpenAI 文档中找到示例提示Prompts。
在 Playground 中,示例称为Presets。以下屏幕截图显示了一些可用的Presets:
OpenAI 文档中还提供了提示Prompt的示例。 OpenAI 文档非常出色,包括许多很棒的提示Prompt示例,以及在 Playground 中打开和测试它们的链接。 以下屏幕截图显示了来自 OpenAI 文档的提示示例。 请注意提示示例下方的 Open this example in Playground 链接。 您可以使用该链接在 Playground 中打开提示:
https://platform.openai.com/docs/guides/completion/prompt-design

现在您已经了解了提示,让我们来谈谈 GPT-3 如何使用它们来生成补全。
补全(Completions)
同样,补全(completions)是指根据提示/输入生成并返回的文本。 GPT-3 并未经过正对任何一种类型的 NLP 训练的——它是一种通用语言处理系统。 但是, GPT-3可以使用提示(prompts)完成给定任务。 这称为元学习(Meta-learning)。
Meta-learning
对于大多数 NLP 系统,在训练底层 ML 模型时,提供的数据是用于指导模型如何完成特定NLP任务的。 所以,为了提高对给定NLP任务的效果,模型必须重新训练,得到新版本的模型。 但是GPT-3 不一样,因为它不需要针对任何特定任务进行重训练。它旨在识别提示(Prompts)文本中的模式(patterns)并通过使用底层通用模型来继续模式。 这种方法被称为元学习(Meta-learning),因为提示用于教导 GPT-3 如何生成最佳的补全(completion),而不需要重新训练。 因此,实际上,可以使用不同的提示类型(零提示、一次提示和多次提示)为不同类型的任务对 GPT-3 进行编程,并且您可以在提示中提供大量指令(instuctions)——多达 2,048 个标识符(token)。
标识符(Tokens)
当一个提示输入到 GPT-3 时,它被分解成标识符(Tokens)。 标识符是单词的数字表示(numeric representation),或者更常见的是单词的一部分。 数字用于标识符而不是单词或句子,因为它们可以更有效地处理。 这使 GPT-3 能够处理相对大量的文本。 也就是说,如您所知,提示和生成的补全一起仍然有 2,048 个标识符(大约 1,500 个单词)的限制。
您可以通过估计将在您的提示和补全中使用的标识符数量来保持在标识符数量的限制之内。 平均而言,对于英文单词,每四个字符代表一个标识符。 因此,只需将提示中的字符数与响应长度相加,然后将总和除以四即可。 这将使您大致了解所需的标识符数量。 如果您想要了解许多任务需要多少标识符,这将很有帮助。
获取标识符数量的另一种方法是使用 Playground 中标识符计数指示器。 它位于右下角大文本输入的正下方。 以下屏幕截图中的放大区域显示了标识符数。 如果将鼠标悬停在数字上,您还会看到完成后的总计数。 对于我们的示例,提示 Do or do not。 There is no try。——Yada大师的名言——使用 10 个标识符和 64个补全标识符:
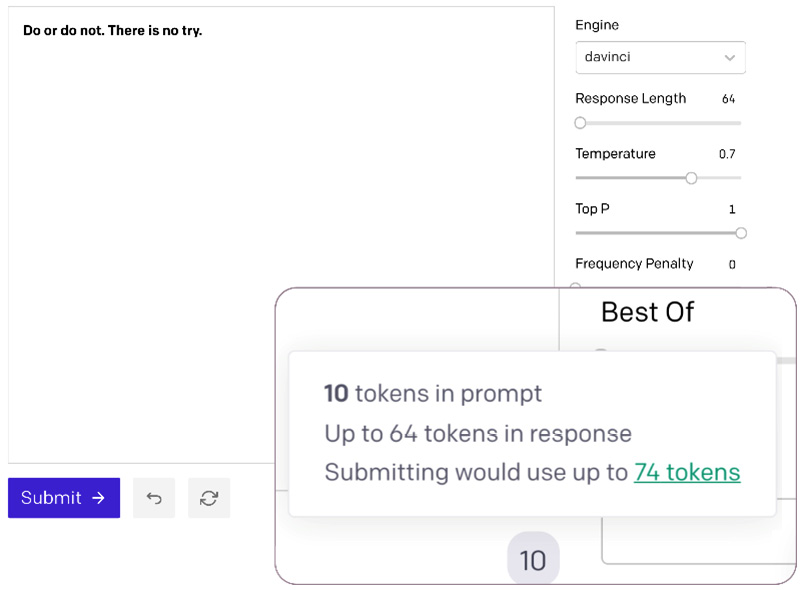
虽然了解标识符对于保持在 2,048 个标识符限制以下很重要,但理解它们也很重要,因为标识符数量可以OpenAI的收费挂钩。 您的帐户可在 https://beta.openai.com/account/usage 获取总体标识符使用情况报告。 以下屏幕截图显示了示例使用情况报告。

除了标识符使用之外,影响与使用 GPT-3 相关的成本的另一件事是您选择处理提示的引擎(engine)。 引擎指的是将要使用的语言模型。 引擎之间的主要区别是相关模型的大小。 较大的模型可以完成更复杂的任务,但较小的模型效率更高。 因此,根据任务的复杂性,您可以通过使用较小的模型来显着降低成本。 以下屏幕截图显示了发布时的模型定价。 如您所见,成本差异可能很大:

其它
Playground相关的参数说明
- temperature: 这会影响您得到的响应的“随机性”。使用什么采样temperature,介于 0 和 2 之间。较高的值(如 0.8)将使输出更加随机,而较低的值(如 0.2)将使输出更加集中和确定。我们通常建议改变这个或 top_p 但不是两者都改变。
- top_p : 一种替代temperature采样的方法,称为核采样,其中模型考虑具有 top_p 概率质量的标记的结果。 所以 0.1 意味着只考虑构成前 10% 概率质量的标记。我们通常建议更改此值或temperature,但不要同时更改两者。
- Maximum length:AI 的响应可以有多长。
- Show Probabilities:这将高亮显示各种单词,以向您展示 AI 如何根据可能性考虑和选择它们。
- Frequency/Presence penalty:改变 AI 重复使用单词或一遍又一遍讨论相同主题的可能性
Mode
- Completion:这是默认模式,它让 AI 在您输入中断的地方补全您的对话。
- insert:此模式使用 [insert] 标签来填充您选择的空白点。
- edit:此模式不是提供全新的内容,而是根据您的规范修改现有内容(例如,“Rewrite this in a pirate voice”或“删除‘like’和其他填充词。”)
- Chat: 聊天模式
ChatGPT与OpenAI Playground 区别
Chat GPT 是一种工具,可让您通过聊天界面与 GPT-3.5 进行实时交互。 您可以通过向它提供提示来使用它来生成文本,它会根据您提供的信息生成文本。
OpenAI Playground 是一种基于 Web 的工具,可让您以更具交互性和灵活性的方式试验 GPT-3 和其他 OpenAI 模型。 它提供了多种选项和设置,您可以使用这些选项和设置来自定义模型的行为,例如模型的大小、输出类型等。
一般来说,如果您只想通过提供提示来快速生成文本,Chat GPT 是一个不错的选择,而 OpenAI Playground 更适合想要尝试不同设置和选项以自定义模型行为的更高级用户。
Chat GPT 使用 GPT 3.5,Playground 使用 GPT 3。但是,Chat GPT 目前处于免费研究预览阶段,您可以免费使用它。 帽子的免费研究预览期过后,您将无法再免费访问该模型。 如果您想继续使用 Chat GPT,则需要注册付费订阅。
Chat GPT 的使用还意味着您的输入和输出将被保存。 所以不要输入个人或敏感信息。
Playground 是一个用户友好的界面,用于与 GPT-3 交互,GPT-3 是 OpenAI 开发的一种基于大规模神经网络的语言生成模型。 另一方面,ChatGPT 是 GPT-3 的较小版本,专为会话语言理解和生成任务而设计。 换句话说,Playground 是使用 GPT-3 的工具,而 ChatGPT 是 GPT-3 的特定版本,针对类似聊天机器人的交互进行了优化。
最后,两者之间的区别在于“Playground”是一个 Playground,而 Chat GPT 是一个独立的应用程序。 一个可以使用参数并查看它如何影响令牌使用和输出性能的空间,因此您可以查看在使用 API 将 GPT 3 实施到您的项目中后要选择的参数。
下面是playground地址,可以自己玩玩, 但是只是刚开始免费。
https://platform.openai.com/playground
提示工程
提示工程(Prompt engineering)是人工智能中的一个概念,特别是自然语言处理(NLP)。 在提示工程中,任务的描述会被嵌入到输入中。例如,不是隐含地给予模型一定的参数,而是以问题的形式直接输入。 提示工程的典型工作方式是将一个或多个任务转换为基于提示的数据集,并通过所谓的“基于提示的学习(prompt-based learning)”来训练语言模型。提示工程可以从一个大型的“冻结”预训练语言模型开始工作,其中只学习了提示的表示方法,即所谓的“前缀调整(prefix-tuning)”或“提示调整(prompt tuning)”。
语言模型GPT-2和GPT-3是提示工程的重要步骤。 2021年,使用多个NLP数据集的多任务提示工程在新任务上显示出良好的性能。在小样本学习的例子中,包含思维链的提示在语言模型中显示出更好的推理能力。零样本学习中,在提示中预留鼓励思考链的语句(如“让我们一步一步地思考”)可能会提高语言模型在多步骤推理问题中的表现。这些工具的广泛可及性由几个开源笔记和社区主导的图像合成项目的发布所推动。
一份关于处理提示的描述报告称,在2022年2月,约有170个数据集的2000多个公共提示可用。
2022年,DALL-E、Stable Diffusion、Midjourney等机器学习模型得到公开发布。这些模型以文本提示为输入,并使用其生成图像,这影响了一个与文生图提示有关的新品种提示工程.
思路链(Chain-of-thought)
思维链提示(Chain-of-thought prompting) (CoT) 通过提示 LLM 生成一系列中间步骤来提高 LLM 的推理能力,这些中间步骤会导致多步骤问题的最终答案。 该技术由谷歌研究人员于 2022 年首次提出。
使用深度学习方法对大量文本进行训练的 LLM 可以生成类似于人类生成文本的输出。 虽然 LLM 在各种自然语言任务上表现出色,但在一些需要逻辑思维和多个步骤才能解决的推理任务上仍然面临困难,例如算术或常识推理问题。 为了应对这一挑战,CoT 提示提示模型在给出多步骤问题的最终答案之前生成中间推理步骤。
例如,给出问题“问:自助餐厅有 23 个苹果。 如果他们用 20 个做午餐,又买了 6 个,他们有多少个苹果?”,CoT 提示可能会促使 LLM 以模仿“A:自助餐厅最初有 23 个苹果”这样的推理步骤来回答 . 他们用了 20 来做午餐。 所以他们有 23 - 20 = 3。他们又买了 6 个苹果,所以他们有 3 + 6 = 9。答案是 9。”
与标准提示方法相比,思维链提示提高了 LLM 在算术和常识任务上的平均表现。 当应用于 540B 参数语言模型 PaLM 时,CoT 提示显着帮助了模型,使其在多个任务上的表现与特定任务微调模型相当,甚至在 GSM8K 数学模型上创下了当时的最新技术水平 推理基准。
CoT 提示是模型规模的一个新兴属性,这意味着它可以更好地与更大、更强大的语言模型一起工作。 可以对 CoT 推理数据集上的模型进行微调,以进一步增强这种能力并激发更好的可解释性。
上下文学习(in-context learning )的一个常见示例是思维链提示(chain-of-thought prompting)
思维链提出的论文有如下两篇
- Wei, Jason; Wang, Xuezhi; Schuurmans, Dale; Bosma, Maarten; Ichter, Brian; Xia, Fei; Chi, Ed H.; Le, Quoc V.; Zhou, Denny (31 October 2022). "Chain-of-Thought Prompting Elicits Reasoning in Large Language Models". arXiv:2201.11903.
- ^ Wei, Jason; Zhou. "Language Models Perform Reasoning via Chain of Thought". ai.googleblog.com. Retrieved 10 March 2023.
恶意利用
提示注入是一系列相关的计算机安全漏洞,通过让经过训练的机器学习模型(如大型语言模型)遵循人类给出的指令来遵循恶意用户提供的指令,这与指令遵循系统的预期操作形成对比,其中机器学习模型只遵循机器学习模型操作员所提供的可信指令(提示).
提示性注入可以被看作是一种使用对抗性提示工程的代码注入攻击。2022年,NCC集团将提示注入定性为AI/ML系统的一类新漏洞。
在2023年左右,提示注入在针对ChatGPT和类似的聊天机器人的次要漏洞中出现,例如揭示系统隐藏的初始提示,或者欺骗聊天机器人参与到违反聊天机器人内容政策的对话。
Meta-learning
元学习:在语言模型的上下文中,模型在训练时发展出广泛的技能和模式识别能力,然后在推理时使用这些能力来快速适应或识别所需的任务。下图中的inner loop和outer loop一起被称为meta-learning.
it means the model develops a broad set of skills and pattern recognition abilities at training time, and then uses those abilities at inference time to rapidly adapt to or recognize the desired task
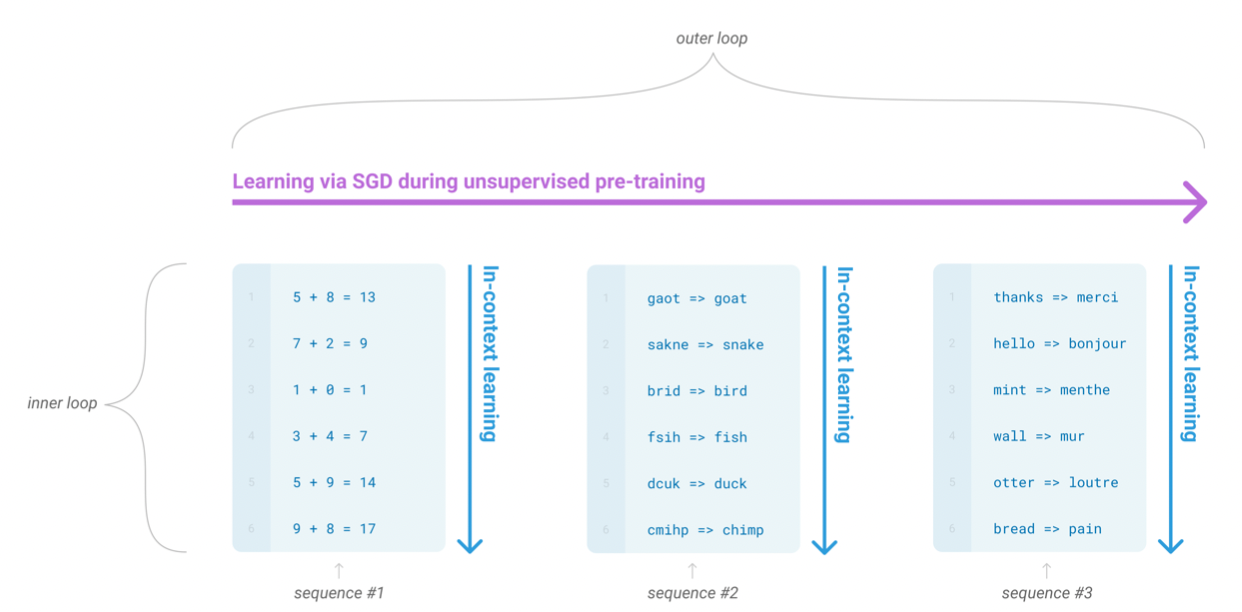
在语言模型的上下文中,这有时被称为“zero-shot transfer”,但这个术语可能有歧义:该方法在不执行梯度更新的意义上是“zero-shot”,但它通常涉及提供推理- 模型的时间演示,所以并不是真正从零示例中学习。 为了避免这种混淆,我们使用术语“meta-learning”来描述一般方法的内循环/外循环结构,使用术语“上下文学习”来指代元学习的内循环。 我们进一步将描述专门化为“zero-shot、“one-shot”或“few-shot”,具体取决于在推理时提供了多少演示。 这些术语旨在对模型是在推理时从头开始学习新任务还是简单地识别训练期间看到的模式这一问题保持不可知——这是一个重要的问题,但“元学习”是旨在涵盖这两种可能性,并简单地描述了内-外循环结构。
1In the context of language models this has sometimes been called “zero-shot transfer”, but this term is potentially ambiguous: the method is “zero-shot” in the sense that no gradient updates are performed, but it often involves providing inference-time demonstrations to the model, so is not truly learning from zero examples. To avoid this confusion, we use the term “meta-learning” to capture the inner-loop / outer-loop structure of the general method, and the term “in context-learning” to refer to the inner loop of meta-learning. We further specialize the description to “zero-shot”, “one-shot”, or “few-shot” depending on how many demonstrations are provided at inference time. These terms are intended to remain agnostic on the question of whether the model learns new tasks from scratch at inference time or simply recognizes patterns seen during training – this is an important issue which we discuss later in the paper, but “meta-learning” is intended to encompass both possibilities, and simply describes the inner-outer loop structure.
in-context learning
我们使用术语“上下文学习(in-context learning)”来描述这个过程的内部循环,它发生在每个序列的前向传递中
in-context learning 就是图中的内部循环(inner loop), 它是指模型在输入的每个序列数据中前向传递过程中学习到的东西。

