
- 1深度学习之Keras_keras高级深度学习.pdf csdn
- 2(含Python源码)Python实现K阶多项式的5种回归算法(regression)_多项式算法实例python
- 3rust编程之道 pdf_哪种编程语言又快又省电?有人对比了27种语言
- 4c++题目魔术卡片_c++魔术卡片
- 5现代雷达系统分析与设计---动目标检测(MTD)_雷达动目标检测
- 6第12章 武装飞船_飞船 bmp
- 7MediaPipe plugin for Unity_mediapipeunityplugin 驱动模型
- 8python-自动化篇-运维-网络-IP
- 9STM32 USB OTG主机模式的实现方法_stm32 usb主机模式
- 10python opencv比较图片相似度
附加整理2_中断implementor id
赞
踩
主从复制可以实现读写分离
mysql优化的常用方法
索引的优化
- 只要列中含有NULL值,就最好不要在此例设置索引,复合索引如果有NULL值,此列在使用时也不会使用索引
- 尽量使用短索引,如果可以,应该制定一个前缀长度
- 对于经常在where子句使用的列,最好设置索引,这样会加快查找速度
- 对于有多个列where或者order by子句的,应该建立复合索引
- 对于like语句,以%或者‘-’开头的不会使用索引,以%结尾会使用索引
- 尽量不要在列上进行运算(函数操作和表达式操作)
- 尽量不要使用not in和<>操作
sql语句的优化
- 查询时,能不要*就不用*,尽量写全字段名
- 大部分情况连接效率远大于子查询
- 多使用explain和profile分析查询语句
- 查看慢查询日志,找出执行时间长的sql语句优化
- 多表连接时,尽量小表驱动大表,即小表 join 大表
- 在千万级分页时使用limit
- 对于经常使用的查询,可以开启缓存
3.表的优化
- 表的字段尽可能用NOT NULL
- 字段长度固定的表查询会更快
- 把数据库的大表按时间或一些标志分成小表
- 将表分区
git fetch和pull区别
因此,与git pull相比git fetch相当于是从远程获取最新版本到本地,但不会自动merge。如果需要有选择的合并git fetch是更好的选择。效果相同时git pull将更为快捷。(合并temp分支到本地的master分支)
JVM类加载时机
1、类加载时机 什么情况下虚拟机需要开始加载一个类呢?虚拟机规范中并没有对此进行强制约束,这点可以交给虚拟机的具体实现来自由把握。
2、类初始化时机 :遇到 new、getstatic、putstatic或invokestatic这四条字节码指令
这四条指令的最常见的Java代码场景是:
-
使用new关键字实例化对象的时候;
-
读取或设置一个类的静态字段(被final修饰,已在编译器把结果放入常量池的静态字段除外)的时候;
-
调用一个类的静态方法的时候。
注意:
- 类的实例化是指创建一个类的实例(对象)的过程;
- 类的初始化是指为类中各个类成员(被static修饰的成员变量)赋初始值的过程,是类生命周期中的一个阶段。
重复类问题探究
本文要讨论的重复类是指类名和包名完全一样,并且不会被不同的类加载器分别加载的情况,也就是说这两个类只会有一个被加载到虚拟机中。
重复类可能引起的问题
重复类会被随机选择一个加载进去,加载完就不会加载另外一个同名重复类了
如果说两个重复类中的内容不一致,则很有可能在系统运行的时候会报错,比如报找不到某个方法的错(java.lang.NoSuchMethodError)。
ArrayBlockingQueue和LinkedBlockingQueue的区别及使用
1. 队列中锁的实现不同
ArrayBlockingQueue实现的队列中的锁是没有分离的,即生产和消费用的是同一个锁;
LinkedBlockingQueue实现的队列中的锁是分离的,即生产用的是putLock,消费是takeLock
2. 在生产或消费时操作不同
ArrayBlockingQueue实现的队列中在生产和消费的时候,是直接将枚举对象插入或移除的;
LinkedBlockingQueue实现的队列中在生产和消费的时候,需要把枚举对象转换为Node<E>进行插入或移除,会影响性能
3. 队列大小初始化方式不同
ArrayBlockingQueue实现的队列中必须指定队列的大小;
LinkedBlockingQueue实现的队列中可以不指定队列的大小,但是默认是Integer.MAX_VALUE
CAP定理和BASE理论
CAP定理
分布式系统的CAP理论:理论首先把分布式系统中的三个特性进行了如下归纳:
CAP原则是NOSQL数据库的基石。Consistency(一致性)。 Availability(可用性)。Partition tolerance(分区容错性)。
- 一致性(C):在分布式系统中的所有数据备份,在同一时刻是否同样的值。(等同于所有节点访问同一份最新的数据副本)
- 可用性(A):在集群中一部分节点故障后,集群整体是否还能响应客户端的读写请求。(对数据更新具备高可用性)
- 分区容忍性(P):以实际效果而言,分区相当于对通信的时限要求。系统如果不能在时限内达成数据一致性,就意味着发生了分区的情况,必须就当前操作在C和A之间做出选择。
一致性与可用性的决择
CAP理论就是说在分布式存储系统中,最多只能实现上面的两点。而由于当前的网络硬件肯定会出现延迟丢包等问题,所以分区容忍性是我们必须需要实现的。所以我们只能在一致性和可用性之间进行权衡,没有NoSQL系统能同时保证这三点。
对于web2.0网站来说,关系数据库的很多主要特性却往往无用武之地
BASE理论
BASE是Basically Available(基本可用)、Soft state(软状态)和Eventually consistent(最终一致性)三个短语的简写,BASE是对CAP中一致性和可用性权衡的结果,其来源于对大规模互联网系统分布式实践的结论,是基于CAP定理逐步演化而来的,其核心思想是即使无法做到强一致性(Strong consistency),但每个应用都可以根据自身的业务特点,采用适当的方式来使系统达到最终一致性(Eventual consistency)。
1、强一致性
这种一致性级别是最符合用户直觉的,它要求系统写入什么,读出来的也会是什么,用户体验好,但实现起来往往对系统的性能影响大
2、弱一致性
这种一致性级别约束了系统在写入成功后,不承诺立即可以读到写入的值,也不久承诺多久之后数据能够达到一致,但会尽可能地保证到某个时间级别(比如秒级别)后,数据能够达到一致状态
3、最终一致性
最终一致性是弱一致性的一个特例,系统会保证在一定时间内,能够达到一个数据一致的状态。这里之所以将最终一致性单独提出来,是因为它是弱一致性中非常推崇的一种一致性模型,也是业界在大型分布式系统的数据一致性上比较推崇的模型
1、基本可用
基本可用是指分布式系统在出现不可预知故障的时候,允许损失部分可用性----注意,这绝不等价于系统不可用。比如:
2、软状态
软状态指允许系统中的数据存在中间状态,并认为该中间状态的存在不会影响系统的整体可用性,即允许系统在不同节点的数据副本之间进行数据同步的过程存在延时
3、最终一致性
最终一致性强调的是所有的数据副本,在经过一段时间的同步之后,最终都能够达到一个一致的状态。因此,最终一致性的本质是需要系统保证最终数据能够达到一致,而不需要实时保证系统数据的强一致性。
四种线程池的使用
newCachedThreadPool创建一个可缓存线程池,如果线程池长度超过处理需要,可灵活回收空闲线程,若无可回收,则新建线程。
newFixedThreadPool 创建一个定长线程池,可控制线程最大并发数,超出的线程会在队列中等待。
newScheduledThreadPool 创建一个定长线程池,支持定时及周期性任务执行。
newSingleThreadExecutor 创建一个单线程化的线程池,它只会用唯一的工作线程来执行任务,保证所有任务按照指定顺序(FIFO, LIFO, 优先级)执行。
- FixedThreadPool是一种容量固定的线程池;
- 阻塞队列采用LinkedBlockingQueue,它是一种无界队列;
- 由于阻塞队列是一个无界队列,因此永远不可能拒绝执行任务;
- 由于采用无界队列,实际线程数将永远维持在nThreads,因此maximumPoolSize和keepAliveTime将无效。
CachedThreadPool是一种可以无限扩容的线程池;
- CachedThreadPool比较适合执行时间片比较小的任务;
- keepAliveTime为60,意味着线程空闲时间超过60s就会被杀死;
- 阻塞队列采用SynchronousQueue,这种阻塞队列没有存储空间,意味着只要有任务到来,就必须得有一个工作线程来处理,如果当前没有空闲线程,那么就再创建一个新的线程。
- ScheduledThreadPool接收SchduledFutureTask类型的任务,提交任务的方式有2种;
1. scheduledAtFixedRate;
2. scheduledWithFixedDelay;
- SchduledFutureTask接收参数:
time:任务开始时间
sequenceNumber:任务序号
period:任务执行的时间间隔
- 阻塞队列采用DelayQueue,它是一种无界队列;
- DelayQueue内部封装了一个PriorityQueue,它会根据time的先后排序,若time相同,则根据sequenceNumber排序;
- 工作线程执行流程:
1. 工作线程会从DelayQueue中取出已经到期的任务去执行;
2. 执行结束后重新设置任务的到期时间,再次放回DelayQueue。
SynchronousQueue
- SynchronousQueue没有容量。与其他BlockingQueue不同,SynchronousQueue是一个不存储元素的BlockingQueue。每一个put操作必须要等待一个take操作,否则不能继续添加元素,反之亦然。
- 因为没有容量,所以对应 peek, contains, clear, isEmpty … 等方法其实是无效的。例如clear是不执行任何操作的,contains始终返回false,peek始终返回null。
- SynchronousQueue分为公平和非公平,默认情况下采用非公平性访问策略,当然也可以通过构造函数来设置为公平性访问策略(为true即可)。
- 若使用 TransferQueue, 则队列中永远会存在一个 dummy node(这点后面详细阐述)。
线程切换过程:
1.虚拟机启动之后,就进入了解释器的死循环,一直解释执行pc指针对应的java字节码。
2. 每个现在对应着一个stack,方面调用的时候,会在其上分配栈帧,由sp,fp等指针指向。
3. 线程调度,其实就是记录下当前线程的pc,sp,fp等寄存器指针,并将这几个指针(pc,sp,fp等,都是全局的)指向下一个将要执行的线程的相应位置。
4. 当恢复上述的几个指针之后,就切换回之前的线程了
二叉树的三种遍历非递归实现
-
package cn.it.cast.dao;
-
-
import java.util.Stack;
-
import java.util.HashMap;
-
-
public
class BinTree{
-
private
char date;
-
private BinTree lchild;
-
private BinTree rchild;
-
-
public BinTree(char c) {
-
date = c;
-
}
-
-
// 先序遍历递归
-
public static void preOrder(BinTree t) {
-
if (t ==
null) {
-
return;
-
}
-
System.out.print(t.date);
-
preOrder(t.lchild);
-
preOrder(t.rchild);
-
}
-
-
// 中序遍历递归
-
public static void InOrder(BinTree t) {
-
if (t ==
null) {
-
return;
-
}
-
InOrder(t.lchild);
-
System.out.print(t.date);
-
InOrder(t.rchild);
-
}
-
-
// 后序遍历递归
-
public static void PostOrder(BinTree t) {
-
if (t ==
null) {
-
return;
-
}
-
PostOrder(t.lchild);
-
PostOrder(t.rchild);
-
System.out.print(t.date);
-
}
-
-
// 先序遍历非递归
-
public static void preOrder2(BinTree t) {
-
Stack<BinTree> s =
new Stack<BinTree>();
-
while (t !=
null || !s.empty()) {
-
while (t !=
null) {
-
System.out.print(t.date);
-
s.push(t);
-
t = t.lchild;
-
}
-
if (!s.empty()) {
-
t = s.pop();
-
t = t.rchild;
-
}
-
}
-
}
-
-
// 中序遍历非递归
-
public static void InOrder2(BinTree t) {
-
Stack<BinTree> s =
new Stack<BinTree>();
-
while (t !=
null || !s.empty()) {
-
while (t !=
null) {
-
s.push(t);
-
t = t.lchild;
-
}
-
if (!s.empty()) {
-
t = s.pop();
-
System.out.print(t.date);
-
t = t.rchild;
-
}
-
}
-
}
-
-
// 后序遍历非递归
-
public static void PostOrder2(BinTree t) {
-
Stack<BinTree> s =
new Stack<BinTree>();
-
Stack<Integer> s2 =
new Stack<Integer>();
-
Integer i =
new Integer(
1);
-
while (t !=
null || !s.empty()) {
-
while (t !=
null) {
-
s.push(t);
-
s2.push(
new Integer(
0));
-
t = t.lchild;
-
}
-
while (!s.empty() && s2.peek().equals(i)) {
-
s2.pop();
-
System.out.print(s.pop().date);
-
}
-
-
if (!s.empty()) {
-
s2.pop();
-
s2.push(
new Integer(
1));
-
t = s.peek();
-
t = t.rchild;
-
}
-
}
-
}
-
-
public static void main(String[] args) {
-
BinTree b1 =
new BinTree(
'a');
-
BinTree b2 =
new BinTree(
'b');
-
BinTree b3 =
new BinTree(
'c');
-
BinTree b4 =
new BinTree(
'd');
-
BinTree b5 =
new BinTree(
'e');
-
-
/**
-
* a
-
* / /
-
* b c
-
* / /
-
* d e
-
*/
-
b1.lchild = b2;
-
b1.rchild = b3;
-
b2.lchild = b4;
-
b2.rchild = b5;
-
-
BinTree.preOrder(b1);
-
System.out.println();
-
BinTree.preOrder2(b1);
-
System.out.println();
-
BinTree.InOrder(b1);
-
System.out.println();
-
BinTree.InOrder2(b1);
-
System.out.println();
-
BinTree.PostOrder(b1);
-
System.out.println();
-
BinTree.PostOrder2(b1);
-
}
-
}
- 1
Spring 框架中都用到了哪些设计模式
代理模式—在AOP和remoting中被用的比较多。
单例模式—在spring配置文件中定义的bean默认为单例模式。
模板方法—用来解决代码重复的问题 比如. RestTemplate, JmsTemplate, JpaTemplate。 前端控制器—Srping提供了DispatcherServlet来对请求进行分发。 视图帮助(View Helper )—Spring提供了一系列的JSP标签,高效宏来辅助将分散的代码整合在视图里。 依赖注入—贯穿于BeanFactory / ApplicationContext接口的核心理念。
工厂模式—BeanFactory用来创建对象的实例。
Builder模式- 自定义配置文件的解析bean是时采用builder模式,一步一步地构建一个beanDefinition
策略模式:Spring 中策略模式使用有多个地方,如 Bean 定义对象的创建以及代理对象的创建等。这里主要看一下代理对象创建的策略模式的实现。 前面已经了解 Spring 的代理方式有两个 Jdk 动态代理和 CGLIB 代理。这两个代理方式的使用正是使用了策略模式。
有1000个数据存在hashmap中,实际的数量是多少,考虑负载因子和扩容
我们有1000个元素new HashMap(1000), 但是理论上来讲new HashMap(1024)更合适,不过上面annegu已经说过,即使是1000,hashmap也自动会将其设置为1024。 但是new HashMap(1024)还不是更合适的,因为0.75*1000 < 1000, 也就是说为了让0.75 * size > 1000, 我们必须这样new HashMap(2048)才最合适
CHM在jdk1.8中主要做了2方面的改进
改进一:取消segments字段,直接采用transient volatile HashEntry<K,V>[] table保存数据,采用table数组元素作为锁,从而实现了对每一行数据进行加锁,进一步减少并发冲突的概率。
改进二:将原先table数组+单向链表的数据结构,变更为table数组+单向链表+红黑树的结构。对于hash表来说,最核心的能力在于将key hash之后能均匀的分布在数组中。如果hash之后散列的很均匀,那么table数组中的每个队列长度主要为0或者1。但实际情况并非总是如此理想,虽然ConcurrentHashMap类默认的加载因子为0.75,但是在数据量过大或者运气不佳的情况下,还是会存在一些队列长度过长的情况,如果还是采用单向列表方式,那么查询某个节点的时间复杂度为O(n);因此,对于个数超过8(默认值)的列表,jdk1.8中采用了红黑树的结构,那么查询的时间复杂度可以降低到O(logN),可以改进性能。
Redis和MySQL的区别
(1)类型上
从类型上来说,mysql是关系型数据库,redis是缓存数据库
(2)作用上
mysql用于持久化的存储数据到硬盘,功能强大,但是速度较慢
redis用于存储使用较为频繁的数据到缓存中,读取速度快
(3)需求上
mysql和redis因为需求的不同,一般都是配合使用。
如何保持MySQL和Redis的一致性?
1、分别处理
针对某些对数据一致性要求不是特别高的情况下,可以将这些数据放入Redis,请求来了直接查询Redis,例如近期回复、历史排名这种实时性不强的业务。而针对那些强实时性的业务,例如虚拟货币、物品购买件数等等,则直接穿透Redis至MySQL上,等到MySQL上写入成功,再同步更新到Redis上去。这样既可以起到Redis的分流大量查询请求的作用,又保证了关键数据的一致性。
2、高并发情况下
此时如果写入请求较多,则直接写入Redis中去,然后间隔一段时间,批量将所有的写入请求,刷新到MySQL中去;如果此时写入请求不多,则可以在每次写入Redis,都立刻将该命令同步至MySQL中去。这两种方法有利有弊,需要根据不同的场景来权衡。
3、基于订阅binlog的同步机制(类似于mysql的主从复制)
阿里巴巴的一款开源框架canal,提供了一种发布/ 订阅模式的同步机制,通过该框架我们可以对MySQL的binlog进行订阅,这样一旦MySQL中产生了新的写入、更新、删除等操作,就可以把binlog相关的消息推送至Redis,Redis再根据binlog中的记录,对Redis进行更新。值得注意的是,binlog需要手动打开,并且不会记录关于MySQL查询的命令和操作。
分布式系统session一致性问题
1.session复制
应用服务器开启web容器的session复制功能,在集群中的几台服务器之间同步session对象,
多个web-server之间相互同步session,这样每个web-server之间都包含全部的session。
2. 客户端存储(cookie)
将session存储到浏览器cookie中。每次请求服务器的时候,将session放在请求中发送给服务器,服务器处理完请求后再将修改后的session响应给客户端。
3. 反向代理hash一致性(确保每个id每次访问一个节点)
反向代理层使用用户ip来做hash,以保证同一个ip的请求落在同一个web-server上
4. 后端统一集中存储(即存储在数据库中)
将session存储在web-server后端的存储层,数据库或者缓存,一般用redis/memchachee缓存。
内存屏障(一个禁止指令重排序的cpu指令)
volatile语义中的内存屏障
- volatile的内存屏障策略非常严格保守,非常悲观且毫无安全感的心态:
在每个volatile写操作前插入StoreStore屏障,在写操作后插入StoreLoad屏障;
在每个volatile读操作前插入LoadLoad屏障,在读操作后插入LoadStore屏障;
- 由于内存屏障的作用,避免了volatile变量和其它指令重排序、线程之间实现了通信,使得volatile表现出了锁的特性。
mysql联合索引原理
非叶子节点是按照最左字段排序的,叶子点根据左边排序之后再顺序排序;解释了最左原则

Mysql行锁和表锁(针对不同的引擎来谈)
InnoDB有三种行锁的算法:
1,Record Lock:单个行记录上的锁。
2,Gap Lock:间隙锁,锁定一个范围,但不包括记录本身。GAP锁的目的,是为了防止同一事务的两次当前读,出现幻读的情况。
3,Next-Key Lock:1+2,锁定一个范围,并且锁定记录本身。对于行的查询,都是采用该方法,主要目的是解决幻读的问题。
因为InnoDB对于行的查询都是采用了Next-Key Lock的算法,锁定的不是单个值,而是一个范围(GAP)。上面索引值有1,3,5,8,11,其记录的GAP的区间如下:是一个左开右闭的空间(原因是默认主键的有序自增的特性,结合后面的例子说明)
(-∞,1],(1,3],(3,5],(5,8],(8,11],(11,+∞)
特别需要注意的是,InnoDB存储引擎还会对辅助索引下一个键值加上gap lock。
例子
- 1
select * from t where a = 8 for update
- 1
该SQL语句锁定的范围是(5,8],下个下个键值范围是(8,11],所以插入5~11之间的值的时候都会被锁定,要求等待。即:插入5,6,7,8,9,10 会被锁住。插入非这个范围内的值都正常。
Mysql limit优化
1.子查询优化法
先找出第一条数据(即通过条件查询查询limit的第一条),然后大于等于这条数据的id就是要获取的数据
select * from Member where MemberID >= (select MemberID from Member limit 1000,1) limit 100
3.反向查找优化法
当偏移超过一半记录数的时候,先用排序,这样偏移就反转了
MySQL 主从同步延迟的原因及解决办法
a. 我们知道因为主服务器要负责更新操作, 他对安全性的要求比从服务器高, 所有有些设置可以修改,比如sync_binlog=1,innodb_flush_log_at_trx_commit = 1 之类的设置,而slave则不需要这么高的数据安全,完全可以讲sync_binlog设置为0或者关闭binlog,innodb_flushlog, innodb_flush_log_at_trx_commit 也 可以设置为0来提高sql的执行效率 这个能很大程度上提高效率。另外就是使用比主库更好的硬件设备作为slave。
b. 就是把,一台从服务器当度作为备份使用, 而不提供查询, 那边他的负载下来了, 执行relay log 里面的SQL效率自然就高了。
c. 增加从服务器喽,这个目的还是分散读的压力, 从而降低服务器负载。
i++的线程安全安全实现
1. 使用AtomicInteger,其中的 public final int getAndIncrement(){} 方法
2. 使用锁
java并发包
分布式锁的三种实现方式
基于数据库的实现方式
基于数据库的实现方式的核心思想是:在数据库中创建一个表,表中包含方法名等字段,并在方法名字段上创建唯一索引,想要执行某个方法,就使用这个方法名向表中插入数据,成功插入则获取锁,执行完成后删除对应的行数据释放锁。
基于Redis的实现方式
选用Redis实现分布式锁原因:
(1)Redis有很高的性能;
(2)Redis命令对此支持较好,实现起来比较方便
基于ZooKeeper的实现方式
ZooKeeper是一个为分布式应用提供一致性服务的开源组件,它内部是一个分层的文件系统目录树结构,规定同一个目录下只能有一个唯一文件名。
图的深度优先和广度优先遍历
图的深度优先搜索(Depth First Search),和树的先序遍历比较类似。
它的思想:假设初始状态是图中所有顶点均未被访问,则从某个顶点v出发,首先访问该顶点,然后依次从它的各个未被访问的邻接点出发深度优先搜索遍历图,直至图中所有和v有路径相通的顶点都被访问到。 若此时尚有其他顶点未被访问到,则另选一个未被访问的顶点作起始点,重复上述过程,直至图中所有顶点都被访问到为止。
显然,深度优先搜索是一个递归的过程。
广度优先搜索算法(Breadth First Search),又称为"宽度优先搜索"或"横向优先搜索",简称BFS。
它的思想是:从图中某顶点v出发,在访问了v之后依次访问v的各个未曾访问过的邻接点,然后分别从这些邻接点出发依次访问它们的邻接点,并使得“先被访问的顶点的邻接点先于后被访问的顶点的邻接点被访问,直至图中所有已被访问的顶点的邻接点都被访问到。如果此时图中尚有顶点未被访问,则需要另选一个未曾被访问过的顶点作为新的起始点,重复上述过程,直至图中所有顶点都被访问到为止。
换句话说,广度优先搜索遍历图的过程是以v为起点,由近至远,依次访问和v有路径相通且路径长度为1,2...的顶点。
树的深度优先遍历需要用到额外的数据结构--->栈;
而广度优先遍历需要队列来辅助;这里以二叉树为例来实现
-
/**
-
* 深度优先遍历,相当于先根遍历
-
* 采用非递归实现
-
* 需要辅助数据结构:栈
-
*/
-
public void depthOrderTraversal(){
-
if(root==
null){
-
System.out.println(
"empty tree");
-
return;
-
}
-
ArrayDeque<TreeNode> stack=
new ArrayDeque<TreeNode>();
-
stack.push(root);
-
while(stack.isEmpty()==
false){
-
TreeNode node=stack.pop();
-
System.out.print(node.value+
" ");
-
if(node.right!=
null){
-
stack.push(node.right);
-
}
-
if(node.left!=
null){
-
stack.push(node.left);
-
}
-
}
-
System.out.print(
"\n");
-
}
- 1
-
public void levelOrderTraversal(){
-
if(root==
null){
-
System.out.println(
"empty tree");
-
return;
-
}
-
ArrayDeque<TreeNode> queue=
new ArrayDeque<TreeNode>();
-
queue.add(root);
-
while(queue.isEmpty()==
false){
-
TreeNode node=queue.remove();
-
System.out.print(node.value+
" ");
-
if(node.left!=
null){
-
queue.add(node.left);
-
}
-
if(node.right!=
null){
-
queue.add(node.right);
-
}
-
}
-
System.out.print(
"\n");
-
}
- 1
HashSet与TreeSet对重复元素的判断不同之处
HashMap 的 put 与 HashSet 的 add
于 HashSet 的 add() 方法添加集合元素时实际上转变为调用 HashMap 的 put() 方法来添加 key-value 对。HashMap 的 put() 方法首先调用.hashCode() 判断返回值相等,如果返回值相等则再通过 equals 比较也返回 true,最终认为key对象是相等的已经在HashMap中存在了。
TreeMap 的 put 与 TreeSet 的 add
TreeMap中调用put方法添加键值时,调用对象的它的 compareTo(或 compare)方法对所有键进行比较,此方法饭回0,则认为两个键就是相等的。 TreeSet添加元素的时候,调用compareTo或compare方法来定位元素的位置,也就是返回compareTo或compare返回0则认为是同一个位置的元素,即相同元素
ArrayList动态扩容
-
/*
-
*增加容量,以确保它至少能容纳
-
*由最小容量参数指定的元素数。
-
* @param mincapacity所需的最小容量
-
*/
-
private void grow(int minCapacity) {
-
// overflow-conscious code
-
int oldCapacity = elementData.length;
-
//>>位运算,右移动一位。 整体相当于newCapacity =oldCapacity + 0.5 * oldCapacity
-
// jdk1.7采用位运算比以前的计算方式更快
-
int newCapacity = oldCapacity + (oldCapacity >>
1);
-
if (newCapacity - minCapacity <
0)
-
newCapacity = minCapacity;
-
//jdk1.7这里增加了对元素个数的最大个数判断,jdk1.7以前是没有最大值判断的,MAX_ARRAY_SIZE 为int最大值减去8(不清楚为什么用这个值做比较)
-
if (newCapacity - MAX_ARRAY_SIZE >
0)
-
newCapacity = hugeCapacity(minCapacity);
-
// 最重要的复制元素方法
-
elementData = Arrays.copyOf(elementData, newCapacity);
-
}
- 1
数据库的分库分表的一些总结(为了应对数据比较多的时候)
Sharding的基本思想就要把一个数据库切分成多个部分放到不同的数据库(server)上,从而缓解单一数据库的性能问题。
不太严格的讲,对于海量数据的数据库,如果是因为表多而数据多,这时候适合使用垂直切分,即把关系紧密(比如同一模块)的表切分出来放在一个server上。
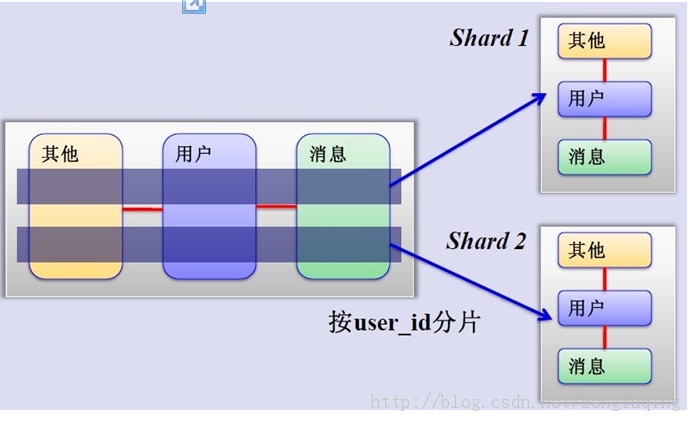
如果表并不多,但每张表的数据非常多,这时候适合水平切分,即把表的数据按某种规则(比如按ID散列)切分到多个数据库(server)上。当然,现实中更多是这两种情况混杂在一起,这时候需要根据实际情况做出选择,也可能会综合使用垂直与水平切分,从而将原有数据库切分成类似矩阵一样可以无限扩充的数据库(server)阵列。
二、数据库架构
1、简单的MySQL主从复制:
2、MySQL垂直分区: 如果把业务切割得足够独立,那把不同业务的数据放到不同的数据库服务器将是一个不错的方案,而且万一其中一个业务崩溃了也不会影响其他业务的正常进行,并且也起到了负载分流的作用,大大提升了数据库的吞吐能力。
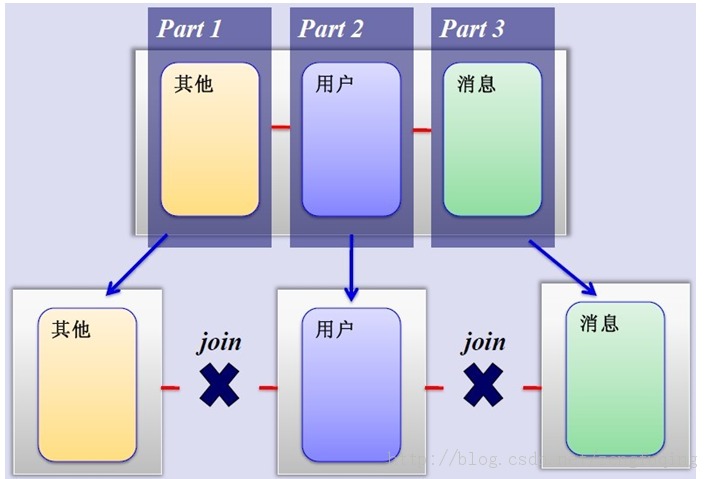
3、MySQL水平分片(Sharding):这是一个非常好的思路,将用户按一定规则(按id哈希)分组,并把该组用户的数据存储到一个数据库分片中,即一个sharding,这样随着用户数量的增加,只要简单地配置一台服务器即可
缓存穿透与缓存雪崩
缓存穿透
什么是缓存穿透?
一般的缓存系统,都是按照key去缓存查询,如果不存在对应的value,就应该去后端系统查找(比如DB)。如果key对应的value是一定不存在的,并且对该key并发请求量很大,就会对后端系统造成很大的压力。这就叫做缓存穿透。
如何避免?
1:对查询结果为空的情况也进行缓存,缓存时间设置短一点,或者该key对应的数据insert了之后清理缓存。
2:对一定不存在的key进行过滤。可以把所有的可能存在的key放到一个大的Bitmap中,查询时通过该bitmap过滤。【感觉应该用的不多吧
缓存雪崩
什么是缓存雪崩?
当缓存服务器重启或者大量缓存集中在某一个时间段失效,这样在失效的时候,也会给后端系统(比如DB)带来很大压力。
如何避免?
1:在缓存失效后,通过加锁或者队列来控制读数据库写缓存的线程数量。比如对某个key只允许一个线程查询数据和写缓存,其他线程等待。
2:不同的key,设置不同的过期时间,让缓存失效的时间点尽量均匀。
3:做二级缓存,A1为原始缓存,A2为拷贝缓存,A1失效时,可以访问A2,A1缓存失效时间设置为短期,A2设置为长期(此点为补充)
缓存数据的淘汰
缓存淘汰的策略有两种:
(1) 定时去清理过期的缓存。
(2)当有用户请求过来时,再判断这个请求所用到的缓存是否过期,过期的话就去底层系统得到新数据并更新缓存。
两者各有优劣,第一种的缺点是维护大量缓存的key是比较麻烦的,第二种的缺点就是每次用户请求过来都要判断缓存失效,逻辑相对比较复杂,具体用哪种方案,大家可以根据自己的应用场景来权衡。
1. 预估失效时间
2. 版本号(必须单调递增,时间戳是最好的选择)
3. 提供手动清理缓存的接口。
redis 学习笔记--hash表的渐进式rehash
redis采用渐进式rehash来解决这个问题。 何为渐进式rehash?
就是把拷贝节点数据的过程平摊到后续的操作中,而不是一次性拷贝。
所谓平摊到后续的操作中,就是对节点操作,例如再次插入,查找,删除,修改时都会进行拷贝。
要想实现这个过程,一个hash结构必须要有以下字段: 两个hash表。一个表拷贝到另一个表的容器 一个标识rehashidx来表明是否在进行rehash中。如果是,那么对节点的操作启动rehash过程。
以下是哈希表渐进式 rehash 的详细步骤:
为 ht[1] 分配空间, 让字典同时持有 ht[0] 和 ht[1] 两个哈希表。
在字典中维持一个索引计数器变量 rehashidx , 并将它的值设置为 0 , 表示 rehash 工作正式开始。
在 rehash 进行期间, 每次对字典执行添加、删除、查找或者更新操作时, 程序除了执行指定的操作以外, 还会顺带将 ht[0] 哈希表在 rehashidx 索引上的所有键值对 rehash 到 ht[1] , 当 rehash 工作完成之后, 程序将 rehashidx 属性的值增一。
随着字典操作的不断执行, 最终在某个时间点上, ht[0] 的所有键值对都会被 rehash 至 ht[1] , 这时程序将 rehashidx 属性的值设为 -1, 表示 rehash 操作已完成。
TreeMap底层是什么?(红黑树)
并行和并发的区别
你吃饭吃到一半,电话来了,你一直到吃完了以后才去接,这就说明你不支持并发也不支持并行。
你吃饭吃到一半,电话来了,你停了下来接了电话,接完后继续吃饭,这说明你支持并发。
你吃饭吃到一半,电话来了,你一边打电话一边吃饭,这说明你支持并行。
并发的关键是你有处理多个任务的能力,不一定要同时。 并行的关键是你有同时处理多个任务的能力。 所以我认为它们最关键的点就是:是否是『同时』。
做并发编程之前,必须首先理解什么是并发,什么是并行,什么是并发编程,什么是并行编程。 并发(concurrency)和并行(parallellism)是:
解释一:并行是指两个或者多个事件在同一时刻发生;而并发是指两个或多个事件在同一时间间隔发生。
解释二:并行是在不同实体上的多个事件,并发是在同一实体上的多个事件。
解释三:在一台处理器上“同时”处理多个任务,在多台处理器上同时处理多个任务。如hadoop分布式集群 所以并发编程的目标是充分的利用处理器的每一个核,以达到最高的处理性能。
静态方法和实例方法的区别及使用场景
1、(静态)成员变量存放在data segment区(数据区),字符串常量也存放在该区
2、非静态变量,new出来的对象存放在堆内存,所有局部变量和引用地址存放在栈内存
3、方法(包括静态方法)存放在code segment(方法块),存放代码片段,且只存放一次
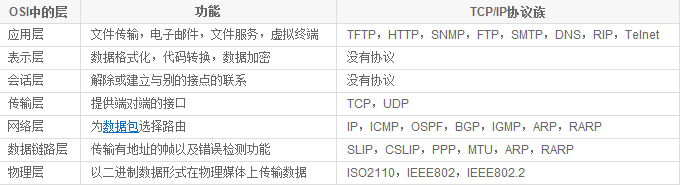
网络七层及其协议
动态代理机制底层
1.动态代理可以由cglib/java Proxy/Aspectj/instrumentation等多种形式实现;
2.动态代理的本质是对class字节码进行动态构建或者修改;
a.修改的工具有ASM(= =比较难用,还是需要知道JVM指令)/javavssist(已经进行封装)
3.多种实现方式的区别在于对字节码切入方式不同.可选方式:
a.java代理/Cglib是基于动态构建接口实现类字节
b.AspectJ是借助eclipse工具在编译时织入代理字节
c.instrumentation是基于javaagent在类装载时,修改class织入代理字节
d.使用自定义classloader在装载时,织入代理字节

Spring bean 生命周期
Spring上下文中的Bean也类似,如下
1、实例化一个Bean--也就是我们常说的new;
2、按照Spring上下文对实例化的Bean进行配置--也就是IOC注入;
3、如果这个Bean已经实现了BeanNameAware接口,会调用它实现的setBeanName(String)方法,此处传递的就是Spring配置文件中Bean的id值
4、如果这个Bean已经实现了BeanFactoryAware接口,会调用它实现的setBeanFactory(setBeanFactory(BeanFactory)传递的是Spring工厂自身(可以用这个方式来获取其它Bean,只需在Spring配置文件中配置一个普通的Bean就可以);
5、如果这个Bean已经实现了ApplicationContextAware接口,会调用setApplicationContext(ApplicationContext)方法,传入Spring上下文(同样这个方式也可以实现步骤4的内容,但比4更好,因为ApplicationContext是BeanFactory的子接口,有更多的实现方法);
6、如果这个Bean关联了BeanPostProcessor接口,将会调用postProcessBeforeInitialization(Object obj, String s)方法,BeanPostProcessor经常被用作是Bean内容的更改,并且由于这个是在Bean初始化结束时调用那个的方法,也可以被应用于内存或缓存技术;
7、如果Bean在Spring配置文件中配置了init-method属性会自动调用其配置的初始化方法。
8、如果这个Bean关联了BeanPostProcessor接口,将会调用postProcessAfterInitialization(Object obj, String s)方法、;
注:以上工作完成以后就可以应用这个Bean了,那这个Bean是一个Singleton的,所以一般情况下我们调用同一个id的Bean会是在内容地址相同的实例,当然在Spring配置文件中也可以配置非Singleton,这里我们不做赘述。
9、当Bean不再需要时,会经过清理阶段,如果Bean实现了DisposableBean这个接口,会调用那个其实现的destroy()方法;
10、最后,如果这个Bean的Spring配置中配置了destroy-method属性,会自动调用其配置的销毁方法。
以上10步骤可以作为面试或者笔试的模板,另外我们这里描述的是应用Spring上下文Bean的生命周期,如果应用Spring的工厂也就是BeanFactory的话去掉第5步就Ok
完全二叉树与满二叉树的区别
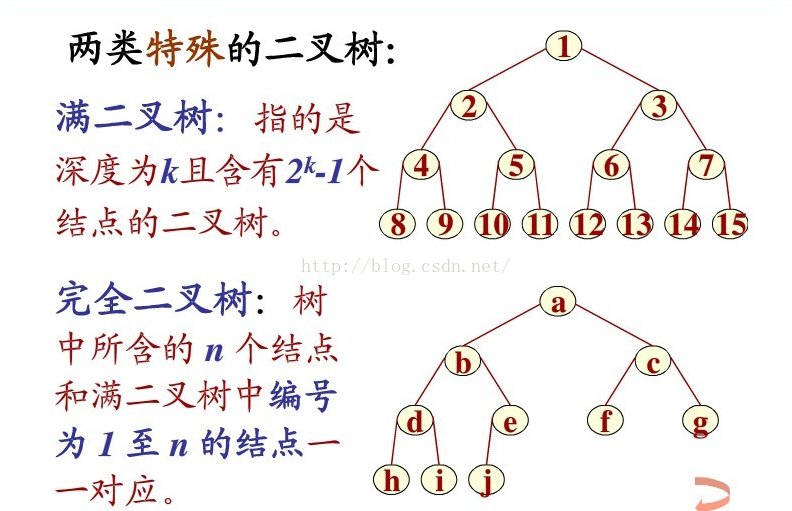
平衡二叉树,是一种二叉排序树,其中每个结点的左子树和右子树的高度差至多等于1。它是一种高度平衡的二叉排序树。高度平衡?意思是说,要么它是一棵空树,要么它的左子树和右子树都是平衡二叉树,且左子树和右子树的深度之差的绝对值不超过1。
Java数据库连接库JDBC用到哪种设计模式?
桥接模式:
定义 :将抽象部分与它的实现部分分离,使它们都可以独立地变化。
意图 :将抽象与实现解耦。
桥接模式所涉及的角色
1. Abstraction :定义抽象接口,拥有一个Implementor类型的对象引用
2. RefinedAbstraction :扩展Abstraction中的接口定义
3. Implementor :是具体实现的接口,Implementor和RefinedAbstraction接口并不一定完全一致,实际上这两个接口可以完全不一样Implementor提供具体操作方法,而Abstraction提供更高层次的调用
4. ConcreteImplementor :实现Implementor接口,给出具体实现
Jdk中的桥接模式:JDBC
JDBC连接 数据库 的时候,在各个数据库之间进行切换,基本不需要动太多的代码,甚至丝毫不动,原因就是JDBC提供了统一接口,每个数据库提供各自的实现,用一个叫做数据库驱动的程序来桥接就行了
JDBC:Statement与PreparedStatement的联系与区别
使用PreparedStatement有几个好处 :
1. 在执行可变参数的一条SQL时,PreparedStatement比Statement的效率高,因为DBMS预编译一条SQL当然会比多次编译一条SQL的效率要高。
2. 安全性好,有效防止Sql注入等问题。
3.对于多次重复执行的语句,使用PreparedStament效率会更高一点,并且在这种情况下也比较适合使用batch;
4.代码的可读性和可维护性。
如何避免幻读
准备的理解是,当隔离级别是可重复读,且禁用innodb_locks_unsafe_for_binlog的情况下,在搜索和扫描index的时候使用的next-key locks可以避免幻读。
关键点在于,是InnoDB默认对一个普通的查询也会加next-key locks,还是说需要应用自己来加锁呢?如果单看这一句,可能会以为InnoDB对普通的查询也加了锁,如果是,那和序列化(SERIALIZABLE)的区别又在哪里呢?
我的理解是说,InnoDB提供了next-key locks,但需要应用程序自己去加锁。manual里提供一个例子:
SELECT * FROM child WHERE id > 100 FOR UPDATE;
这样,InnoDB会给id大于100的行(假如child表里有一行id为102),以及100-102,102+的gap都加上锁。
可以使用show innodb status来查看是否给表加上了锁。
什么是MVCC? 多版本并发控制。InnoDB为每行记录添加了一个版本号(系统版本号),每当修改数据时,版本号加一。 在读取事务开始时,系统会给事务一个当前版本号,事务会读取版本号<=当前版本号的数据,这时就算另一个事务插入一个数据,并立马提交,新插入这条数据的版本号会比读取事务的版本号高,因此读取事务读的数据还是不会变。
例如: 此时books表中有5条数据,版本号为1
事务A,系统版本号2:select * from books;因为1<=2所以此时会读取5条数据。
事务B,系统版本号3:insert into books ...,插入一条数据,新插入的数据版本号为3,而其他的数据的版本号仍然是2,插入完成之后commit,事务结束。
事务A,系统版本号2:再次select * from books;只能读取<=2的数据,事务B新插入的那条数据版本号为3,因此读不出来,解决了幻读的问题。
++num和num++哪个执行速度更快,++num为什么会比num++速度快
num++在执行过程中是需要经历两个过程的,首先是将num读到寄存器,再将num对应的内存地址的值进行加一操作,调用的时候是使用的是寄存器中的值,而不是直接用地址中的值。
++num在执行的时候是直接对num所对应的内存地址进行加一操作,调用的时候是直接使用该内存地址中的值进行操作。 所以在使用++num时速度会相对来说要快那么一点点。
i=i+1与i+=1的区别及效率
1.x=x+1,x+=1及x++的效率哪个最高?为什么? x=x+1最低,因为它的执行如下。
(1)读取右x的地址;
(2)x+1;
(3)读取左x的地址;
(4)将右值传给左边的x(编译器并不认为左右x的地址相同)。
2. x+=1其次,它的执行如下。
(1)读取x的地址;
(2)x+1;
(3)将得到的值传给x(因为x的地址已经读出)。
3. x++最高,它的执行如下。
(1)读取右x的地址;
(2)x自增1.
2.x=x+1,和 x+=1; 在什么情况下不成立 而且 x=x+1 是错误的; (类型隐式转换) short x=1; x+=1; x=x+1; //因为 x是 short 类型 .当它+1 会自动转变成int 当是等于又 是 short 类型..所以会报错;
3.x=x+1,和 x+=1; 在什么情况下不成立 而且 x+=1 是错误的; Object x=”abc”; String y=”def”; x+=y; x=x+y
Collection与Collections的区别
Collection是集合类的上级接口,继承与他有关的接口主要有List和Set
Collections是针对集合类的一个帮助类,他提供一系列静态方法实现对各种集合的搜索、排序、线程安全等操作
Collections用法:
1) 排序(Sort) 使用sort方法可以根据元素的自然顺序 对指定列表按升序进行排序。列表中的所有元素都必须实现 Comparable 接口。此列表内的所有元素都必须是使用指定比较器可相互比较的
2) 混排(Shuffling) 混排算法所做的正好与 sort 相反: 它打乱在一个 List 中可能有的任何排列的踪迹。也就是说,基于随机源的输入重排该 List,这样的排列具有相同的可能性(假设随机源是公正的)。这个算法在实现一个碰运气的游戏中是非常有用的。例如,它可被用来混排代表一副牌的 Card 对象的一个 List .另外,在生成测试案例时,它也是十分有用的。
3) 反转(Reverse) 使用Reverse方法可以根据元素的自然顺序 对指定列表按降序进行排序。
4) 替换所有的元素(Fill) 使用指定元素替换指定列表中的所有元素。
5) 拷贝(Copy) 用两个参数,一个目标 List 和一个源 List, 将源的元素拷贝到目标,并覆盖它的内容。目标 List 至少与源一样长。如果它更长,则在目标 List 中的剩余元素不受影响。 Collections.copy(list,li): 后面一个参数是目标列表 ,前一个是源列表
6) 返回Collections中最小元素(min) 根据指定比较器产生的顺序,返回给定 collection 的最小元素。collection 中的所有元素都必须是通过指定比较器可相互比较的
7) 返回Collections中最大元素(max) 根据指定比较器产生的顺序,返回给定 collection 的最大元素。collection 中的所有元素都必须是通过指定比较器可相互比较的
8) lastIndexOfSubList 返回指定源列表中最后一次出现指定目标列表的起始位置,即按从后到前的顺序返回子List在父List中的索引位置。
11)static int binarySearch(List list,Object key) 使用二分搜索查找key对象的索引值,因为使用的二分查找,所以前提是必须有序。
12)static Object max(Collection coll) 根据元素自然顺序,返回集合中的最大元素
13)static Object max(Collection coll,Compare comp) 根据Comparator指定的顺序,返回给定集合中的最小元素
14)static Object min(Collection coll) 根据元素自然顺序,返回集合中的最大元素
15)static Object min(Collection coll,Compare comp) 根据Comparator指定的顺序,返回给定集合中的最小元素
16)static void fill(List list,Object obj) 使用指定元素替换指定集合中的所有元素
17)static int frequency(Collection c,Object o) 返回指定元素在集合中出现在次数
18)static int indexOfSubList(List source, List target) 返回子List对象在父List对象中第一次出现的位置索引; 如果父List中没有出现这样的子List,则返回-1
19)static int lastIndexOfSubList(List source,List target) 返回子List对象在父List对象中最后一次出现的位置索引,如果父List中没有出现这样的子List,刚返回-1
20)static boolean replaceAll(List list,Object oldVal,Object newVal) 使用一个新值newVal替换List对象所有旧值oldVal
21)synchronizedXXX(new XXX) Collections类为集合类们提供的同步控制方法
22)emptyXXX() 返回一个空的、不可变的集合对象,此处的集合既可以是List,也可以是Set,还可以是Map。
23)singletonXXX() 返回一个只包含指定对象(只有一个或一项元素)的、不可变的集合对象,此处集合既可以是List,也可以是Set,还可以是Map。
24)unmodificableXXX() 指定返回集合对象的不可变视图,此处的集合既可以是Lsit,也可以是Set,Map
分布式环境下,怎么保证线程安全
避免并发
时间戳
串行化
数据库
行锁
统一触发途径
阻塞队列(BlockingQueue)的实现原理
在Java中,BlockingQueue是一个接口,它的实现类有ArrayBlockingQueue、DelayQueue、 LinkedBlockingDeque、LinkedBlockingQueue、PriorityBlockingQueue、SynchronousQueue等,它们的区别主要体现在存储结构上或对元素操作上的不同,但是对于take与put操作的原理,却是类似的。下面的源码以ArrayBlockingQueue为例。
BlockingQueue内部有一个ReentrantLock,其生成了两个Condition
可以看见,put(E)与take()是同步的,在put操作中,当队列满了,会阻塞put操作,直到队列中有空闲的位置。而在take操作中,当队列为空时,会阻塞take操作,直到队列中有新的元素。 而这里使用两个Condition,则可以避免调用signal()时,会唤醒相同的put或take操作。
- add():队列已满时,再添加会抛出异常——对应remove()
- offer():添加元素后,会返回一个boolean值,看是否添加成功。若队列已满,再添加不会抛异常,但是返回false,表示添加失败——对应poll()
- put():队列已满,再添加会阻塞——对应take()
Redis的setnx都是原子性操作
使用SETNX实现分布式锁

MySQL从其他数据表或者查询结果中创建数据表
从其他数据表中创建数据表,可以使用如下命令: create table ... like ...
1 该语句将创建一个新的数据表作为原始数据表的一份空白副本。
它将把原始数据表的所有列属性都会一摸一样的复制过来,但是数据表的内容是空的。如果我们想填充它,可以使用如下命令: Insert into .. select ..
从查询结果中创建数据表 使用如下命令,从一个select语句中创建新的数据表。
create table ... select ...
1 该语句优点是不仅仅创建了数据表,还复制了数据表中的数据。缺点是该语句不会复制所有的数据 列属性,如索引、auto_increment等。因为结果集本身就不带索引等。
海量数据排序——如果有1TB的数据需要排序,但只有32GB的内存如何排序处理?
1、外排序
外排序采用分块的方法(分而治之),首先将数据分块,对块内数据按选择一种高效的内排序策略进行排序。然后采用归并排序的思想对于所有的块进行排序,得到所有数据的一个有序序列
例如,考虑一个1G文件,可用内存100M的排序方法。首先将文件分成10个100M,并依次载入内存中进行排序,最后结果存入硬盘。得到的是10个分别排序的文件。接着从每个文件载入9M的数据到输入缓存区,输出缓存区大小为10M。对输入缓存区的数据进行归并排序,输出缓存区写满之后写在硬盘上,缓存区清空继续写接下来的数据。对于输入缓存区,当一个块的9M数据全部使用完,载入该块接下来的9M数据,一直到所有的9个块的所有数据都已经被载入到内存中被处理过。最后我们得到的是一个1G的排序好的存在硬盘上的文件。

合理设置线程池大小
任务的性质:
CPU密集型任务、IO密集型任务、混合型任务。
任务的优先级:高、中、低。
任务的执行时间:长、中、短。
任务的依赖性:是否依赖其他系统资源,如数据库连接等。
若任务对其他系统资源有依赖,如某个任务依赖数据库的连接返回的结果,这时候等待的时间越长,则CPU空闲的时间越长,那么线程数量应设置得越大,才能更好的利用CPU。 当然具体合理线程池值大小,需要结合系统实际情况,在大量的尝试下比较才能得出,以上只是前人总结的规律。
最佳线程数目 = (线程等待时间与线程CPU时间之比 + 1)* CPU数目
可以得出一个结论: 线程等待时间所占比例越高,需要越多线程。线程CPU时间所占比例越高,需要越少线程。 以上公式与之前的CPU和IO密集型任务设置线程数基本吻合。
并发编程网上的一个问题 高并发、任务执行时间短的业务怎样使用线程池?并发不高、任务执行时间长的业务怎样使用线程池?并发高、业务执行时间长的业务怎样使用线程池?
(1)高并发、任务执行时间短的业务,线程池线程数可以设置为CPU核数+1,减少线程上下文的切换 (2)并发不高、任务执行时间长的业务要区分开看:
a)假如是业务时间长集中在IO操作上,也就是IO密集型的任务,因为IO操作并不占用CPU,所以不要让所有的CPU闲下来,可以适当加大线程池中的线程数目,让CPU处理更多的业务
b)假如是业务时间长集中在计算操作上,也就是计算密集型任务,这个就没办法了,和(1)一样吧,线程池中的线程数设置得少一些,减少线程上下文的切换
(3)并发高、业务执行时间长,解决这种类型任务的关键不在于线程池而在于整体架构的设计,看看这些业务里面某些数据是否能做缓存是第一步,增加服务器是第二步,至于线程池的设置,设置参考(2)。最后,业务执行时间长的问题,也可能需要分析一下,看看能不能使用中间件对任务进行拆分和解耦。
CMS 垃圾回收(比之前记的多了两个阶段)
初始标记 :在这个阶段,需要虚拟机停顿正在执行的任务,官方的叫法STW(Stop The Word)。这个过程从垃圾回收的”根对象”开始,只扫描到能够和”根对象”直接关联的对象,并作标记。所以这个过程虽然暂停了整个JVM,但是很快就完成了。
并发标记 :这个阶段紧随初始标记阶段,在初始标记的基础上继续向下追溯标记。并发标记阶段,应用程序的线程和并发标记的线程并发执行,所以用户不会感受到停顿。
并发预清理 :并发预清理阶段仍然是并发的。在这个阶段,虚拟机查找在执行并发标记阶段新进入老年代的对象(可能会有一些对象从新生代晋升到老年代, 或者有一些对象被分配到老年代)。通过重新扫描,减少下一个阶段”重新标记”的工作,因为下一个阶段会Stop The World。
重新标记 :这个阶段会暂停虚拟机,收集器线程扫描在CMS堆中剩余的对象。扫描从”跟对象”开始向下追溯,并处理对象关联。
并发清理 :清理垃圾对象,这个阶段收集器线程和应用程序线程并发执行。
并发重置 :这个阶段,重置CMS收集器的数据结构,等待下一次垃圾回收。
BitMap
一个byte是占8个bit,如果每一个bit的值就是有或者没有,也就是二进制的0或者1,如果用bit的位置代表数组值有还是没有,那么0代表该数值没有出现过,1代表该数组值出现过。不也能描述数据了吗?如下图:
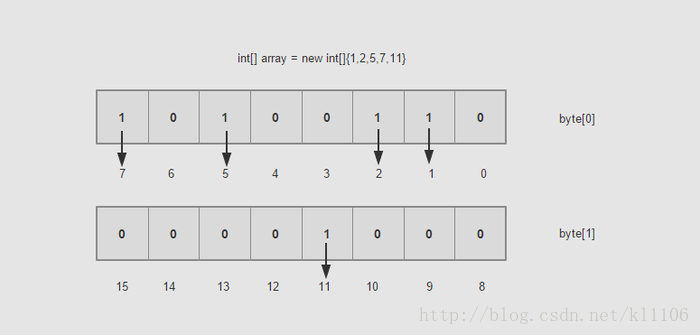
是不是很神奇,那么现在假如10亿的数据所需的空间就是3.72G/32了吧,一个占用32bit的数据现在只占用了1bit,节省了不少的空间,排序就更不用说了,一切显得那么顺利。这样的数据之间没有关联性,要是读取的,你可以用多线程的方式去读取。时间复杂度方面也是O(Max/n),其中Max为byte[]数组的大小,n为线程大小。
硬中断和软中断
硬中断和软中断的区别 软中断是执行中断指令产生的,而硬中断是由外设引发的。
硬中断的中断号是由中断控制器提供的,软中断的中断号由指令直接指出,无需使用中断控制器。
硬中断是可屏蔽的,软中断不可屏蔽。 硬中断处理程序要确保它能快速地完成任务,这样程序执行时才不会等待较长时间,称为上半部。
软中断处理硬中断未完成的工作,是一种推后执行的机制,属于下半部。
匿名内部类 是否可以继承其它类,是否可以实现接口
可以继承其他类或实现其他接口
equals的默认实现(直接比较两者的引用)
IOC的实现原理—反射与工厂模式
我们可以把IOC容器的工作模式看做是工厂模式的升华,可以把IOC容器看作是一个工厂,这个工厂里要生产的对象都在配置文件中给出定义,然后利用编程语言提供的反射机制,根据配置文件中给出的类名生成相应的对象。从实现来看,IOC是把以前在工厂方法里写死的对象生成代码,改变为由配置文件来定义,也就是把工厂和对象生成这两者独立分隔开来,目的就是提高灵活性和可维护性。
Java中反射的实现方式
第一种:通过Object类的getClass方法 Class cla = foo.getClass();
第二种:通过对象实例方法获取对象 Class cla = foo.class();
第三种:通过Class.forName方式 Class cla = Class.forName("xx.xx.Foo")
Spring框架中,一旦把一个Bean纳入Spring IOC容器之中,这个Bean的生命周期就会交由容器进行管理,一般担当管理角色的是BeanFactory或者ApplicationContext,
二叉树除了用链表还能用数组表示。
Static 静态类
1.静态内部类跟静态方法一样,只能访问静态的成员变量和方法,不能访问非静态的方法和属性,但是普通内部类可以访问任意外部类的成员变量和方法
2.静态内部类可以声明普通成员变量和方法,而普通内部类不能声明static成员变量和方法。
3.静态内部类可以单独初始化:
静态内部类使用场景一般是当外部类需要使用内部类,而内部类无需外部类资源,并且内部类可以单独创建的时候会考虑采用静态内部类的设计.
分布式事务中2PC与3PC的区别
2PC
2PC,也就是两段提交:
1)第一阶段参与值接收到开始事务的请求之后,返回accept或者abort,如果返回accept,就预先执行事务,并记录相关的日志和undo。
2)第二阶段coordinator发起commit,participant接受后返回commit或者abort。

第二阶段协调者和参与者挂了,挂了的这个参与者在挂之前已经执行了操作。但是由于他挂了,没有人知道他执行了什么操作。 这种情况下,新的协调者被选出来之后,如果他想负起协调者的责任的话他就只能按照之前那种情况来执行commit或者roolback操作。这样新的协调者和所有没挂掉的参与者就保持了数据的一致性,我们假定他们执行了commit。
但是,这个时候,那个挂掉的参与者恢复了怎么办,因为他之前已经执行完了之前的事务,如果他执行的是commit那还好,和其他的机器保持一致了,万一他执行的是roolback操作那?这不就导致数据的不一致性了么?虽然这个时候可以再通过手段让他和协调者通信,再想办法把数据搞成一致的,但是,这段时间内他的数据状态已经是不一致的了!
3PC
3PC,是三段提交:
1)第一阶段接受到开始事务的请求之后,根据participant的情况,返回accpert或者abort。
2)第二阶段coordinator发起pre-commit请求,participant prepare to commit或者abort或者超时commit,commit即会执行事务,并记录相关的日志和undo。
3)第三阶段coordinator发起commit请求,participant commit或者abort或者超时commit。
所以,2PC协议中,如果出现协调者和参与者都挂了的情况,有可能导致数据不一致。 为了解决这个问题,衍生除了3PC。我们接下来看看3PC是如何解决这个问题的。
3PC最关键要解决的就是协调者和参与者同时挂掉的问题,所以3PC把2PC的准备阶段再次一分为二,这样三阶段提交就有CanCommit、PreCommit、DoCommit三个阶段。在第一阶段,只是询问所有参与者是否可可以执行事务操作,并不在本阶段执行事务操作。当协调者收到所有的参与者都返回YES时,在第二阶段才执行事务操作,然后在第三阶段在执行commit或者rollback。
简单概括一下就是,如果挂掉的那台机器已经执行了commit,那么协调者可以从所有未挂掉的参与者的状态中分析出来,并执行commit。如果挂掉的那个参与者执行了rollback,那么协调者和其他的参与者执行的肯定也是rollback操作。 所以,再多引入一个阶段之后,3PC解决了2PC中存在的那种由于协调者和参与者同时挂掉有可能导致的数据一致性问题。
3PC存在的问题 在doCommit阶段,如果参与者无法及时接收到来自协调者的doCommit或者rebort请求时,会在等待超时之后,会继续进行事务的提交。 所以,由于网络原因,协调者发送的abort响应没有及时被参与者接收到,那么参与者在等待超时之后执行了commit操作。这样就和其他接到abort命令并执行回滚的参与者之间存在数据不一致的情况。
单链表的两种实现方式
第一种: 递归
-
static Node reverseLinkedList(Node node) {
-
if (node ==
null || node.next ==
null) {
-
return node;
-
}
else {
-
Node headNode = reverseLinkedList(node.next);
-
node.next.next = node;
-
node.next =
null;
-
return headNode;
-
}
-
}
-
- 1
第二种: 遍历
-
static Node reverseLinkedList(Node node) {
-
Node previousNode =
null;
-
Node currentNode = node;
-
Node headNode =
null;
-
while (currentNode !=
null) {
-
Node nextNode = currentNode.next;
-
if (nextNode ==
null) {
-
headNode = currentNode;
-
}
-
currentNode.next = previousNode;
-
previousNode = currentNode;
-
currentNode = nextNode;
-
}
-
return headNode;
-
}
-
- 1
缓存--基于linkedHashMap实现LRU缓存淘汰策略
LinkedHashMap 内部也有维护一个双向队列,在初始化时也会给定一个缓存大小的阈值。初始化时自定义是否需要删除最近不常使用的数据,如果是则会按照实现二中的方式管理数据。
其实主要代码就是重写了 LinkedHashMap 的 removeEldestEntry 方法:
-
protected boolean removeEldestEntry(Map.Entry<K,V> eldest) {
-
return
false;
-
}
- 1
-
package LinkedHashMap实现LRU;
-
-
import java.util.ArrayList;
-
import java.util.Collection;
-
import java.util.LinkedHashMap;
-
import java.util.Map;
-
import java.util.Map.Entry;
-
-
public
class LRULinkedMap<K, V> {
-
-
/**
-
* 最大缓存大小
-
*/
-
private
int cacheSize;
-
-
private LinkedHashMap<K, V> cacheMap;
-
-
public LRULinkedMap(int cacheSize){
-
this.cacheSize = cacheSize;
-
-
cacheMap =
new LinkedHashMap(
16,
0.75F,
true){
-
-
@Override
-
protected boolean removeEldestEntry(Entry eldest) {
-
if(cacheSize +
1 == cacheMap.size()){
-
return
true;
-
}
else{
-
return
false;
-
}
-
}
-
};
-
}
-
-
public void put(K key, V value){
-
cacheMap.put(key, value);
-
}
-
-
public V get(K key){
-
return cacheMap.get(key);
-
}
-
-
public Collection<Map.Entry<K, V>> getAll(){
-
return
new ArrayList<Map.Entry<K, V>>(cacheMap.entrySet());
-
}
-
-
public static void main(String[] args) {
-
LRULinkedMap<String, Integer> map =
new LRULinkedMap<>(
3);
-
map.put(
"key1",
1);
-
map.put(
"key2",
2);
-
map.put(
"key3",
3);
-
-
for (Map.Entry<String, Integer> e : map.getAll()){
-
System.out.println(e.getKey()+
"====>"+e.getValue());
-
}
-
System.out.println(
"\n");
-
map.put(
"key4",
4);
-
for (Map.Entry<String, Integer> e : map.getAll()){
-
System.out.println(e.getKey()+
"====>"+e.getValue());
-
}
-
-
}
-
-
}
- 1
final方法不能被覆盖,可被重载(方法名相同而参数不同)
finalize 方法
之所以要使用finalize(),是存在着垃圾回收器不能处理的特殊情况。假定你的对象(并非使用new方法)获得了一块“特殊”的内存区域,由于垃圾回收器只知道那些显示地经由new分配的内存空间,所以它不知道该如何释放这块“特殊”的内存区域,那么这个时候java允许在类中定义一个由finalize()方法。
特殊的区域例如:
1)由于在分配内存的时候可能采用了类似 C语言的做法,而非JAVA的通常new做法。这种情况主要发生在native method中,比如native method调用了C/C++方法malloc()函数系列来分配存储空间,但是除非调用free()函数,否则这些内存空间将不会得到释放,那么这个时候就可能造成内存泄漏。但是由于free()方法是在C/C++中的函数,所以finalize()中可以用本地方法来调用它。以释放这些“特殊”的内存空间。
2)又或者打开的文件资源,这些资源不属于垃圾回收器的回收范围。
tcp连接之半连接攻击和全连接攻击总结
半连接就是通过不断地构造客户端的SYN连接数据包发向服务端,等到服务端的半连接队列满的时候,后续的正常用户的连接请求将会被丢弃,从而无法连接到服务端。此为半连接攻击方式。根据服务端的半连接队列的大小,不同主机的抵抗这种SYN攻击的能力也是不一样。
可以通过拓展半连接队列的大小,来进行补救,但缺点是,不能无限制的增加,这样会耗费过多的服务端资源,导致服务端性能地下。这种方式几乎不可取。现主要通syn cookie或者syn中继机制来防范半连接攻,部位半连接分配核心内存的方式来防范。
全连接攻击是通过消费服务端进程数和连接数,只连接而不进行发送数据的一种攻击方式。当客户端连接到服务端,仅仅只是连接,此时服务端会为每一个连接创建一个进程来处理客户端发送的数据。但是客户端只是连接而不发送数据,此时服务端会一直阻塞在recv或者read的状态,如此一来,多个连接,服务端的每个连接都是出于阻塞状态从而导致服务端的崩溃。
可以通过不为全连接分配进程处理的方式来防范全连接攻击,具体的情况是当收到数据之后,在为其分配一个处理线程。具体的处理方式在accept返回之前是不分配处理线程的。直到接收相关的数据之后才为之提供一个处理过程。
submit 和 execute的区别
execute(Runnable x) 没有返回值。可以执行任务,但无法判断任务是否成功完成。——实现Runnable接口
submit(Runnable x) 返回一个future。可以用这个future来判断任务是否成功完成。——实现Callable接口
多线程中Future与FutureTask的区别和联系
<T> Future<T> submit(Callable<T> task);
<T> Future<T> submit(Runnable task, T result);
Future<?> submit(Runnable task);
第一个方法:submit提交一个实现Callable接口的任务,并且返回封装了异步计算结果的Future。
第二个方法:submit提交一个实现Runnable接口的任务,并且指定了在调用Future的get方法时返回的result对象。(不常用)
第三个方法:submit提交一个实现Runnable接口的任务,并且返回封装了异步计算结果的Future。
因此我们只要创建好我们的线程对象(实现Callable接口或者Runnable接口),然后通过上面3个方法提交给线程池去执行即可。还有点要注意的是,除了我们自己实现Callable对象外,我们还可以使用工厂类Executors来把一个Runnable对象包装成Callable对象。Executors工厂类提供的方法如下:
interrupt(),isInterrupted()和interrupted()
① interrupt():中断本线程
myThread.interrupt();//中断的是调用interrupt()方法的线程
小结:阻塞于wait/join/sleep的线程,中断状态会被清除掉,同时收到著名的InterruptedException;而其他情况中断状态都被设置,并不一定收到异常。
② isInterrupted():检测本线程是否已经中断
myThread.isInterrupted();//判断本线程myThread是否中断
如果已经中断,则返回true,否则false。中断状态不受该方法的影响。
如果中断调用时线程已经不处于活动状态,则返回false。
③ interrupted():检测当前线程是否已经中断
Thread.interrupted();//判断该语句所在线程是否中断
如果已经中断,则返回true,否则false,并清除中断状态。换言之,如果该方法被连续调用两次,第二次必将返回false,除非在第一次与第二次的瞬间线程再次被中断。
如果中断调用时线程已经不处于活动状态,则返回false。
父类引用指向子类对象
我们可以看到多态中的成员访问特点:
- 成员变量
- 编译看左边,运行看左边
- 构造方法
- 子类的构造都会默认访问父类构造
- 成员方法
- 编译看左边,运行看右边
- 静态方法
- 编译看左边,运行看左边
- 所以静态方法不能算方法的重写
Java内存使用情况查看工具
一、jstat查看 gc实时执行情况
二、jmap查看各个代的内存使用
三、jstack和 jinfo分析java core文件
四、jstack查看进程所包含的线程情况.
五、jps查看当前系统Java运行的进程PID
数据库冗余的利与弊?
在设计数据库时,某一字段属于一个表,但它又同时出现在另一个或多个表,且完全等同于它在其本来所属表的意义表示,那么这个字段就是一个冗余字段。
1,尽量遵循范式理论的规约,尽可能少的冗余字段,让数据库设计看起来精致、优雅、让人心醉。
2,合理的加入冗余字段这个润滑剂,减少join,让数据库执行性能更高更快。
(即空间和时间的转换关系)
关于AOP无法切入同类调用方法的问题
一个类有a,b两个方法,a中调用了b,如果用动态代理拦截了b,那么调用a方法时,a中对b调用会被拦截么?
-
public
class Bean1 implements Bean {
-
public void a() {System.out.println(
'a');b();}
-
public void b() {System.out.println(
'b');}
-
}
-
-
public
class Test implements InvocationHandler {
-
public Bean bean;
-
public Test(Bean bean) {
this.bean = bean;}
-
@Override
-
public Object invoke(Object proxy, Method method, Object[] args) throws Throwable {
-
if (method.getName().equals(
'b')) {
-
System.out.println(
'c');
-
}
-
return method.invoke(bean, args);
-
}
-
public static void main(String[] args) {
-
Bean b =
new Bean1();
-
Test t =
new Test(b);
-
Bean proxy = (Bean) Proxy.newProxyInstance(Test.class.getClassLoader(),
new Class[] { Bean.class }, t);
-
proxy.a();
-
proxy.b();
-
}
-
}
- 1
上述代码创建了Bean1的实例b的代理,拦截Bean上的b()方法,执行该方法前打印出 ‘c’。但调用proxy.a()方法并不会打印出c,只打印了a,和b。直接调用proxy.b()则会打印出c和b。
Java中创建(实例化)对象的五种方式
1、用new语句创建对象,这是最常见的创建对象的方法。
2、通过工厂方法返回对象,如:String str = String.valueOf(23);
3、运用反射手段,调用java.lang.Class或者java.lang.reflect.Constructor类的newInstance()实例方法。如:Object obj = Class.forName("java.lang.Object").newInstance();
4、调用对象的clone()方法。
5、通过I/O流(包括反序列化),如运用反序列化手段,调用java.io.ObjectInputStream对象的 readObject()方法。
innodb中mvcc的理解
MVCC(Multi-Version Concurrency Control)即多版本并发控制。
MySQL的大多数事务型(如InnoDB,Falcon等)存储引擎实现的都不是简单的行级锁。基于提升并发性能的考虑,他们一般都同时实现了MVCC。当前不仅仅是MySQL,其它数据库系统(如Oracle,PostgreSQL)也都实现了MVCC。值得注意的是MVCC并没有一个统一的实现标准,所以不同的数据库,不同的存储引擎的实现都不尽相同。
MVCC优缺点
MVCC在大多数情况下代替了行锁,实现了对读的非阻塞,读不加锁,读写不冲突。缺点是每行记录都需要额外的存储空间,需要做更多的行维护和检查工作。
可以解决幻读的问题
MVCC的实现原理
undo log
为了便于理解MVCC的实现原理,这里简单介绍一下undo log的工作过程
在不考虑redo log 的情况下利用undo log工作的简化过程为:
| 序号 | 动作 |
|---|---|
| 1 | 开始事务 |
| 2 | 记录数据行数据快照到undo log |
| 3 | 更新数据 |
| 4 | 将undo log写到磁盘 |
| 5 | 将数据写到磁盘 |
| 6 | 提交事务 |
1)为了保证数据的持久性数据要在事务提交之前持久化
2)undo log的持久化必须在在数据持久化之前,这样才能保证系统崩溃时,可以用undo log来回滚事务
Innodb中的隐藏列
Innodb通过undo log保存了已更改行的旧版本的信息的快照。
InnoDB的内部实现中为每一行数据增加了三个隐藏列用于实现MVCC。
| 列名 | 长度(字节) | 作用 |
|---|---|---|
| DB_TRX_ID | 6 | 插入或更新行的最后一个事务的事务标识符。(删除视为更新,将其标记为已删除) |
| DB_ROLL_PTR | 7 | 写入回滚段的撤消日志记录(若行已更新,则撤消日志记录包含在更新行之前重建行内容所需的信息) |
| DB_ROW_ID | 6 | 行标识(隐藏单调自增id) |
结构
MVCC工作过程
MVCC只在READ COMMITED 和 REPEATABLE READ 两个隔离级别下工作。READ UNCOMMITTED总是读取最新的数据行,而不是符合当前事务版本的数据行。而SERIALIZABLE 则会对所有读取的行都加锁
SELECT
InnoDB 会根据两个条件来检查每行记录:
- InnoDB只查找版本(DB_TRX_ID)早于当前事务版本的数据行(行的系统版本号<=事务的系统版本号,这样可以确保数据行要么是在开始之前已经存在了,要么是事务自身插入或修改过的)
- 行的删除版本号(DB_ROLL_PTR)要么未定义(未更新过),要么大于当前事务版本号(在当前事务开始之后更新的)。这样可以确保事务读取到的行,在事务开始之前未被删除。
INSERT
InnoDB为新插入的每一行保存当前系统版本号作为行版本号
DELETE
InnoDB为删除的每一行保存当前的系统版本号作为行删除标识
UPDATE
InnoDB为插入一行新记录,保存当前系统版本号作为行版本号,同时保存当前系统版本号到原来的行作为行删除标识
1.3 MVCC实现
MVCC是通过保存数据在某个时间点的快照来实现的. 不同存储引擎的MVCC. 不同存储引擎的MVCC实现是不同的,典型的有乐观并发控制和悲观并发控制.
MVCC 具体实现分析
下面,我们通过InnoDB的MVCC实现来分析MVCC使怎样进行并发控制的.
InnoDB的MVCC,是通过在每行记录后面保存两个隐藏的列来实现的,这两个列,分别保存了这个行的创建时间,一个保存的是行的删除时间。这里存储的并不是实际的时间值,而是系统版本号(可以理解为事务的ID),没开始一个新的事务,系统版本号就会自动递增,事务开始时刻的系统版本号会作为事务的ID.下面看一下在REPEATABLE READ隔离级别下,MVCC具体是如何操作的.
假设1
假设在执行这个事务ID为2的过程中,刚执行到(1),这时,有另一个事务ID为3往这个表里插入了一条数据;
第三个事务ID为3;
-
start
transaction;
-
insert
into yang
values(
NULL,
'tian');
-
commit;
- 1
- 1
- 2
- 3
这时表中的数据如下:
| id | name | 创建时间(事务ID) | 删除时间(事务ID) |
|---|---|---|---|
| 1 | yang | 1 | undefined |
| 2 | long | 1 | undefined |
| 3 | fei | 1 | undefined |
| 4 | tian | 3 | undefined |
然后接着执行事务2中的(2),由于id=4的数据的创建时间(事务ID为3),执行当前事务的ID为2,而InnoDB只会查找事务ID小于等于当前事务ID的数据行,所以id=4的数据行并不会在执行事务2中的(2)被检索出来,在事务2中的两条select 语句检索出来的数据都只会下表:
| id | name | 创建时间(事务ID) | 删除时间(事务ID) |
|---|---|---|---|
| 1 | yang | 1 | undefined |
| 2 | long | 1 | undefined |
| 3 | fei | 1 | undefined |
假设2
假设在执行这个事务ID为2的过程中,刚执行到(1),假设事务执行完事务3后,接着又执行了事务4;
第四个事务:
-
start
transaction;
-
delete
from yang
where
id=
1;
-
commit;
- 1
- 1
- 2
- 3
此时数据库中的表如下:
| id | name | 创建时间(事务ID) | 删除时间(事务ID) |
|---|---|---|---|
| 1 | yang | 1 | 4 |
| 2 | long | 1 | undefined |
| 3 | fei | 1 | undefined |
| 4 | tian | 3 | undefined |
接着执行事务ID为2的事务(2),根据SELECT 检索条件可以知道,它会检索创建时间(创建事务的ID)小于当前事务ID的行和删除时间(删除事务的ID)大于当前事务的行,而id=4的行上面已经说过,而id=1的行由于删除时间(删除事务的ID)大于当前事务的ID,所以事务2的(2)select * from yang也会把id=1的数据检索出来.所以,事务2中的两条select 语句检索出来的数据都如下:
| id | name | 创建时间(事务ID) | 删除时间(事务ID) |
|---|---|---|---|
| 1 | yang | 1 | 4 |
| 2 | long | 1 | undefined |
| 3 | fei | 1 | undefined |
UPDATE
InnoDB执行UPDATE,实际上是新插入了一行记录,并保存其创建时间为当前事务的ID,同时保存当前事务ID到要UPDATE的行的删除时间.
假设3
假设在执行完事务2的(1)后又执行,其它用户执行了事务3,4,这时,又有一个用户对这张表执行了UPDATE操作:
第5个事务:
-
start
transaction;
-
update yang
set
name=
'Long'
where
id=
2;
-
commit;
- 1
- 1
- 2
- 3
根据update的更新原则:会生成新的一行,并在原来要修改的列的删除时间列上添加本事务ID,得到表如下:
| id | name | 创建时间(事务ID) | 删除时间(事务ID) |
|---|---|---|---|
| 1 | yang | 1 | 4 |
| 2 | long | 1 | 5 |
| 3 | fei | 1 | undefined |
| 4 | tian | 3 | undefined |
| 2 | Long | 5 | undefined |
继续执行事务2的(2),根据select 语句的检索条件,得到下表:
| id | name | 创建时间(事务ID) | 删除时间(事务ID) |
|---|---|---|---|
| 1 | yang | 1 | 4 |
| 2 | long | 1 | 5 |
| 3 | fei | 1 | undefined |
还是和事务2中(1)select 得到相同的结果.
Redis哨兵模式
简介
Redis-Sentinel是官方推荐的高可用解决方案,当redis在做master-slave的高可用方案时,假如master宕机了,redis本身(以及其很多客户端)都没有实现自动进行主备切换,而redis-sentinel本身也是独立运行的进程,可以部署在其他与redis集群可通讯的机器中监控redis集群。
功能
1、不时地监控redis是否按照预期良好地运行;
2、如果发现某个redis节点运行出现状况,能够通知另外一个进程(例如它的客户端);
3、能够进行自动切换。当一个master节点不可用时,能够选举出master的多个slave(如果有超过一个slave的话)中的一个来作为新的master,其它的slave节点会将它所追随的master的地址改为被提升为master的slave的新地址。
4、哨兵为客户端提供服务发现,客户端链接哨兵,哨兵提供当前master的地址然后提供服务,如果出现切换,也就是master挂了,哨兵会提供客户端一个新地址。
spring传播行为
PROPAGATION_REQUIRED--支持当前事务,如果当前没有事务,就新建一个事务。这是最常见的选择。
PROPAGATION_SUPPORTS--支持当前事务,如果当前没有事务,就以非事务方式执行。
PROPAGATION_MANDATORY--支持当前事务,如果当前没有事务,就抛出异常。
PROPAGATION_REQUIRES_NEW--新建事务,如果当前存在事务,把当前事务挂起。
PROPAGATION_NOT_SUPPORTED--以非事务方式执行操作,如果当前存在事务,就把当前事务挂起。
java线程通信的三种方式
1、传统的线程通信。
在synchronized修饰的同步方法或者修饰的同步代码块中使用Object类提供的wait(),notify()和notifyAll()3个方法进行线程通信。
关于这3个方法的解释:
- wait():导致当前线程等待,直到其他线程调用该同步监视器的notify()方法或notifyAll()方法来唤醒该线程。
- notify():唤醒在此同步监视器上等待的单个线程。
- notifyAll():唤醒在此同步监视器上等待的所有线程。
2、使用Condition控制线程通信。
当程序使用Lock对象来保证同步,系统不存在隐式的同步监视器,只能用Condition类来控制线程通信。
- await():类似于隐式同步监视器上的wait()方法,导致当前线程等待,直到其他线程调用该Condition的signal()方法或signalAll()方法来唤醒该线程。
- signal():唤醒在此Lock对象上等待的单个线程。如果所有的线程都在该Lock对象上等待,则会选择唤醒其中一个线程。选择是任意性的。
- signalAll():唤醒在此Lock对象上等待的所有线程,只有当前线程放弃对该Lock对象的锁定后,才可以执行被唤醒的线程。
3、使用阻塞队列(BlockingQueue)控制线程通信(也实现了生产者消费者模式)
BlockingQueue提供如下两个支持阻塞的方法:
- put(E e):尝试把E元素放入BlockingQueue中,如果该队列的元素已满,则阻塞该线程。
- take():尝试从BlockingQueue的头部取出元素,如果该队列的元素已空,则阻塞该线程。
top k 问题(寻找出最大的10000个数)
全部排序
然后在排序后的集合中进行查找,最快的排序算法的时间复杂度一般为O(nlogn),如快速排序。但是在32位的机器上,每个float类型占4个字节,1亿个浮点数就要占用400MB的存储空间,对于一些可用内存小于400M的计算机而言,很显然是不能一次将全部数据读入内存进行排序的。其实即使内存能够满足要求(我机器内存都是8GB),该方法也并不高效,因为题目的目的是寻找出最大的10000个数即可,而排序却是将所有的元素都排序了,做了很多的无用功。
第二种方法为局部淘汰法,
该方法与排序方法类似,用一个容器保存前10000个数,然后将剩余的所有数字——与容器内的最小数字相比,如果所有后续的元素都比容器内的10000个数还小,那么容器内这个10000个数就是最大10000个数。如果某一后续元素比容器内最小数字大,则删掉容器内最小元素,并将该元素插入容器,最后遍历完这1亿个数,得到的结果容器中保存的数即为最终结果了。此时的时间复杂度为O(n+m^2),其中m为容器的大小,即10000。
第三种方法是分治法
将1亿个数据分成100份,每份100万个数据,找到每份数据中最大的10000个,最后在剩下的100*10000个数据里面找出最大的10000个。如果100万数据选择足够理想,那么可以过滤掉1亿数据里面99%的数据。100万个数据里面查找最大的10000个数据的方法如下:用快速排序的方法,将数据分为2堆,如果大的那堆个数N大于10000个,继续对大堆快速排序一次分成2堆,如果大堆个数N小于10000个,就在小的那堆里面快速排序一次,找第10000-n大的数字;递归以上过程,就可以找到第1w大的数。参考上面的找出第1w大数字,就可以类似的方法找到前10000大数字了。此种方法需要每次的内存空间为10^6*4=4MB,一共需要101次这样的比较。
第四种方法是Hash法。
如果这1亿个书里面有很多重复的数,先通过Hash法,把这1亿个数字去重复,这样如果重复率很高的话,会减少很大的内存用量,从而缩小运算空间,然后通过分治法或最小堆法查找最大的10000个数。
第五种方法采用最小堆。
首先读入前10000个数来创建大小为10000的最小堆,建堆的时间复杂度为O(mlogm)(m为数组的大小即为10000),然后遍历后续的数字,并于堆顶(最小)数字进行比较。如果比最小的数小,则继续读取后续数字;如果比堆顶数字大,则替换堆顶元素并重新调整堆为最小堆。整个过程直至1亿个数全部遍历完为止。然后按照中序遍历的方式输出当前堆中的所有10000个数字。该算法的时间复杂度为O(nmlogm),空间复杂度是10000(常数)。
把一个数组中的空格移动到最后
算法解释
此算法的精髓在于:在循环遍历中将0元素全部集中起来,整体向后移位,但是由于连续的0元素都是相等的,因此就算往前移位,也只需要将最前面的0元素和连续0元素的结束位置的后一位元素进行调换,相当于整个0元素块都向后移动了一位。
由于数组中可能有多个0,因此,第一次循环的时候,就将第一个0元素找出,并且记录当前0元素的游标(此时0元素开始的游标和结束的游标相等),第二次循环的时候,直接从0元素结束的游标的后一位开始循环遍历,如果循环遍历过程中,遇到了0元素,则将0元素的结束游标+1;如果没有遇到0元素,则将0元素开始位置和当前位置的数进行置换,并且将0元素的开始游标和结束游标都+1。
符号引用与直接引用
符号引用 :符号引用以一组符号来描述所引用的目标。符号引用可以是任何形式的字面量,只要使用时能无歧义地定位到目标即可,符号引用和虚拟机的布局无关。个人理解为:在编译的时候一个每个java类都会被编译成一个class文件,但在编译的时候虚拟机并不知道所引用类的地址,多以就用符号引用来代替,而在这个解析阶段就是为了把这个符号引用转化成为真正的地址的阶段。即直接引用。
最长回文子串
一、O(n^3)时间复杂度方法——暴力求解
1.思想:
1)从最长的子串开始,遍历所有该原字符串的子串;
2)每找出一个字符串,就判断该字符串是否为回文;
3)子串为回文时,则找到了最长的回文子串,因此结束;反之,则继续遍历。
2.时间复杂度解释:
遍历字符串子串:嵌套一个循环、O(n^2);
判断是否为回文:再次嵌套一个循环、O(n^3)。
二、O(n^2)时间复杂度方法——从中心向外扩散
1.思想:
1)将子串分为单核和双核的情况,单核即指子串长度为奇数,双核则为偶数;
2)遍历每个除最后一个位置的字符index(字符位置),单核:初始low = 初始high = index,low和high均不超过原字符串的下限和上限;判断low和high处的字符是否相等,相等则low++、high++(双核:初始high = 初始low+1 = index + 1);
3)每次low与high处的字符相等时,都将当前最长的回文子串长度与high-low+1比较。后者大时,将最长的回文子串改为low与high之间的;
4)重复执行2)、3),直至high-low+1 等于原字符串长度或者遍历到最后一个字符,取当前截取到的回文子串,该子串即为最长的回文子串。
2.时间复杂度解释:
遍历字符:一层循环、O(n-1);
找以当前字符为中心的最长回文子串:嵌套两个独立循环、O(2n*(n-1)) = O(n^2)。
三、O(n)时间复杂度方法——Manacher算法
1.思想:
1)将原字符串S的每个字符间都插入一个永远不会在S中出现的字符(本例中用“#”表示),在S的首尾也插入该字符,使得到的新字符串S_new长度为2*S.length()+1,保证Len的长度为奇数(下例中空格不表示字符,仅美观作用);
例:S: a a b a b b a
S_new: # a # a # b # a # b # b # a #
2)根据S_new求出以每个字符为中心的最长回文子串的最右端字符距离该字符的距离,存入Len数组中,即S_new[i]—S_new[r]为S_new[i]的最长回文子串的右段(S_new[2i-r]—S_new[r]为以S_new[i]为中心的最长回文子串),Len[i] = r - i + 1;
S_new: # a # a # b # a # b # b # a #
Len: 1 2 3 2 1 4 1 4 1 2 5 2 1 2 1
Len数组性质:Len[i] - 1即为以Len[i]为中心的最长回文子串在S中的长度。在S_new中,以S_new[i]为中心的最长回文子串长度为2Len[i] - 1,由于在S_new中是在每个字符两侧都有新字符“#”,观察可知“#”的数量一定是比原字符多1的,即有Len[i]个,因此真实的回文子串长度为Len[i] - 1,最长回文子串长度为Math.max(Len) - 1。
3)Len数组求解(线性复杂度(O(n))):
a.遍历S_new数组,i为当前遍历到的位置,即求解以S_new[i]为中心的最长回文子串的Len[i];
b.设置两个参数:sub_midd = Len.indexOf(Math.max(Len)表示在i之前所得到的Len数组中的最大值所在位置、sub_side = sub_midd + Len[sub_midd] - 1表示以sub_midd为中心的最长回文子串的最右端在S_new中的位置。起始sub_midd和sub_side设为0,从S_new中的第一个字母开始计算,每次计算后都需要更新sub_midd和sub_side;
c.当i < sub_side时,取i关于sub_midd的对称点j(j = 2sub_midd - i,由于i <= sub_side,因此2sub_midd - sub_side <= j <= sub_midd);当Len[j] < sub_side - i时,即以S_new[j]为中心的最长回文子串是在以S_new[sub_midd]为中心的最长回文子串的内部,再由于i、j关于sub_midd对称,可知Len[i] = Len[j];
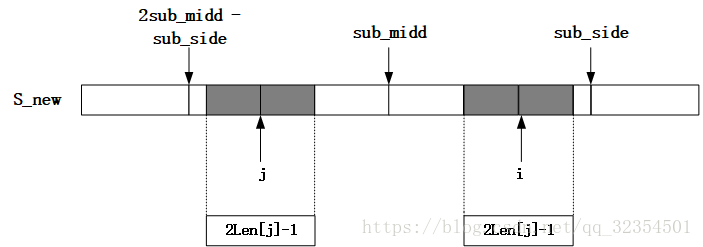
当Len[j] >= sub.side - i时说明以S_new[i]为中心的回文串可能延伸到sub_side之外,而大于sub_side的部分还没有进行匹配,所以要从sub_side+1位置开始进行匹配,直到匹配失败以后,从而更新sub_side和对应的sub_midd以及Len[i];
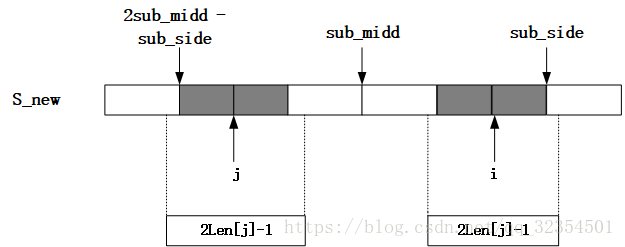
d.当i > sub_side时,则说明以S_new[i]为中心的最长回文子串还没开始匹配寻找,因此需要一个一个进行匹配寻找,结束后更新sub_side和对应的sub_midd以及Len[i]。
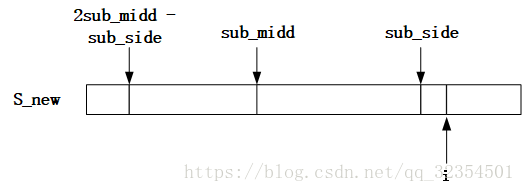
2.时间复杂度解释:
算法只有遇到还没匹配的位置时才进行匹配,已经匹配过的位置不再进行匹配,因此大大的减少了重复匹配的步骤,对于S_new中的每个字符只进行一次匹配。所以该算法的时间复杂度为O(2n+1)—>O(n)(n为原字符串的长度),所以其时间复杂度依旧是线性的。
mysql死锁的原因以及解决方法
死锁的第一种情况
一个用户A 访问表A(锁住了表A),然后又访问表B;另一个用户B 访问表B(锁住了表B),然后企图访问表A;这时用户A由于用户B已经锁住表B,它必须等待用户B释放表B才能继续,同样用户B要等用户A释放表A才能继续,这就死锁就产生了。
解决方法:
这种死锁比较常见,是由于程序的BUG产生的,除了调整的程序的逻辑没有其它的办法。仔细分析程序的逻辑,对于数据库的多表操作时,尽量按照相同的顺序进 行处理,尽量避免同时锁定两个资源,如操作A和B两张表时,总是按先A后B的顺序处理, 必须同时锁定两个资源时,要保证在任何时刻都应该按照相同的顺序来锁定资源。
死锁的第二种情况
用户A查询一条纪录,然后修改该条纪录;这时用户B修改该条纪录,这时用户A的事务里锁的性质由查询的共享锁企图上升到独占锁,而用户B里的独占锁由于A 有共享锁存在所以必须等A释放掉共享锁,而A由于B的独占锁而无法上升的独占锁也就不可能释放共享锁,于是出现了死锁。这种死锁比较隐蔽,但在稍大点的项 目中经常发生。如在某项目中,页面上的按钮点击后,没有使按钮立刻失效,使得用户会多次快速点击同一按钮,这样同一段代码对数据库同一条记录进行多次操 作,很容易就出现这种死锁的情况。(b需要等待a释放共享锁以后才能加排他锁,而a需要拿到排他锁才能释放共享锁,故而形成死锁。看你就没仔细阅读作者的文章。)
解决方法:
1、对于按钮等控件,点击后使其立刻失效,不让用户重复点击,避免对同时对同一条记录操作。
2、使用乐观锁进行控制。乐观锁大多是基于数据版本(Version)记录机制实现。即为数据增加一个版本标识,在基于数据库表的版本解决方案中,一般是 通过为数据库表增加一个“version”字段来实现。读取出数据时,将此版本号一同读出,之后更新时,对此版本号加一。此时,将提交数据的版本数据与数 据库表对应记录的当前版本信息进行比对,如果提交的数据版本号大于数据库表当前版本号,则予以更新,否则认为是过期数据。乐观锁机制避免了长事务中的数据 库加锁开销(用户A和用户B操作过程中,都没有对数据库数据加锁),大大提升了大并发量下的系统整体性能表现。Hibernate 在其数据访问引擎中内置了乐观锁实现。需要注意的是,由于乐观锁机制是在我们的系统中实现,来自外部系统的用户更新操作不受我们系统的控制,因此可能会造 成脏数据被更新到数据库中。
3、使用悲观锁进行控制。悲观锁大多数情况下依靠数据库的锁机制实现,如Oracle的Select … for update语句,以保证操作最大程度的独占性。但随之而来的就是数据库性能的大量开销,特别是对长事务而言,这样的开销往往无法承受。如一个金融系统, 当某个操作员读取用户的数据,并在读出的用户数据的基础上进行修改时(如更改用户账户余额),如果采用悲观锁机制,也就意味着整个操作过程中(从操作员读 出数据、开始修改直至提交修改结果的全过程,甚至还包括操作员中途去煮咖啡的时间),数据库记录始终处于加锁状态,可以想见,如果面对成百上千个并发,这 样的情况将导致灾难性的后果。所以,采用悲观锁进行控制时一定要考虑清楚。
死锁的第三种情况
如果在事务中执行了一条不满足条件的update语句,则执行全表扫描,把行级锁上升为表级锁,多个这样的事务执行后,就很容易产生死锁和阻塞。类似的情 况还有当表中的数据量非常庞大而索引建的过少或不合适的时候,使得经常发生全表扫描,最终应用系统会越来越慢,最终发生阻塞或死锁。
解决方法:
SQL语句中不要使用太复杂的关联多表的查询;使用“执行计划”对SQL语句进行分析,对于有全表扫描的SQL语句,建立相应的索引进行优化。
线程池拒绝策略
ThreadPoolExcetor 的最后一个参数指定了拒绝策略,JDK提供了四种拒绝策略:
AbortPolicy 策略、CallerRunsPolicy策略、 DiscardOledestPolicy策略、DiscardPolicy策略。
AbortPolicy策略:该策略会直接抛出异常,阻止系统正常工作。
CallerRunsPolicy 策略:只要线程池未关闭,该策略直接在调用者线程中,运行当前的被丢弃的任务。
DiscardOleddestPolicy策略: 该策略将丢弃最老的一个请求,也就是即将被执行的任务,并尝试再次提交当前任务。
DiscardPolicy策略:该策略默默的丢弃无法处理的任务,不予任何处理。
mysql索引失效的几种情况(全)
1.WHERE字句的查询条件里有不等于号(WHERE column!=…),MYSQL将无法使用索引
2.类似地,如果WHERE字句的查询条件里使用了函数(如:WHERE DAY(column)=…),MYSQL将无法使用索引
3.在JOIN操作中(需要从多个数据表提取数据时),MYSQL只有在主键和外键的数据类型相同时才能使用索引,否则即使建立了索引也不会使用
4.如果WHERE子句的查询条件里使用了比较操作符LIKE和REGEXP,MYSQL只有在搜索模板的第一个字符不是通配符的情况下才能使用索引。比如说,如果查询条件是LIKE 'abc%',MYSQL将使用索引;如果条件是LIKE '%abc',MYSQL将不使用索引。
5.在ORDER BY操作中,MYSQL只有在排序条件不是一个查询条件表达式的情况下才使用索引。尽管如此,在涉及多个数据表的查询里,即使有索引可用,那些索引在加快ORDER BY操作方面也没什么作用。
6.如果某个数据列里包含着许多重复的值,就算为它建立了索引也不会有很好的效果。比如说,如果某个数据列里包含了净是些诸如“0/1”或“Y/N”等值,就没有必要为它创建一个索引。
7.索引有用的情况下就太多了。基本只要建立了索引,除了上面提到的索引不会使用的情况下之外,其他情况只要是使用在WHERE条件里,ORDER BY 字段,联表字段,一般都是有效的。 建立索引要的就是有效果。 不然还用它干吗? 如果不能确定在某个字段上建立的索引是否有效果,只要实际进行测试下比较下执行时间就知道。
8.如果条件中有or(并且其中有or的条件是不带索引的),即使其中有条件带索引也不会使用(这也是为什么尽量少用or的原因)。注意:要想使用or,又想让索引生效,只能将or条件中的每个列都加上索引
9.如果列类型是字符串,那一定要在条件中将数据使用引号引用起来,否则不使用索引
10.如果mysql估计使用全表扫描要比使用索引快,则不使用索引
链表的倒数第k个节点
为了能够只遍历一次就能找到倒数第k个节点,可以定义两个指针:
(1)第一个指针从链表的头指针开始遍历向前走k-1,第二个指针保持不动;
(2)从第k步开始,第二个指针也开始从链表的头指针开始遍历;
(3)由于两个指针的距离保持在k-1,当第一个(走在前面的)指针到达链表的尾结点时,第二个指针(走在后面的)指针正好是倒数第k个结点。
Java 8中基本数据类型占用字节数
8中基本数据类型为:
4种整形:byte(取值-128~127),short(取值-32768~32767),int,long
2种浮点类型:float,double(3.14F位浮点型,没有F默认为double)
1种Unicode编码的字符单元的字符型:char
1中Boolean类型:boolean
8中类型所占字节和位数如下:
| 类型 | 占用字节 | 占用位数 |
|---|---|---|
| byte | 1 | 8 |
| short | 2 | 16 |
| int | 4 | 32 |
| long | 8 | 64 |
| float | 4 | 32 |
| double | 8 | 64 |
| char | 2 | 16 |
| boolean | 1 | 8 |
TCP/IP协议族四层模型简述
从上层到底层为:应用层,传输层,网络层, 数据链路层。
TCP和UDP协议的比较
1: 面向报文
面向报文的传输方式是应用层交给UDP多长的报文,UDP就照样发送,即一次发送一个报文。因此,应用程序必须选择合适大小的报文。若报文太长,则IP层需要分片,降低效率。若太短,会是IP太小。UDP对应用层交下来的报文,既不合并,也不拆分,而是保留这些报文的边界。这也就是说,应用层交给UDP多长的报文,UDP就照样发送,即一次发送一个报文。
2: 面向字节流
面向字节流的话,虽然应用程序和TCP的交互是一次一个数据块(大小不等),但TCP把应用程序看成是一连串的无结构的字节流。TCP有一个缓冲,当应用程序传送的数据块太长,TCP就可以把它划分短一些再传送。如果应用程序一次只发送一个字节,TCP也可以等待积累有足够多的字节后再构成报文段发送出去。
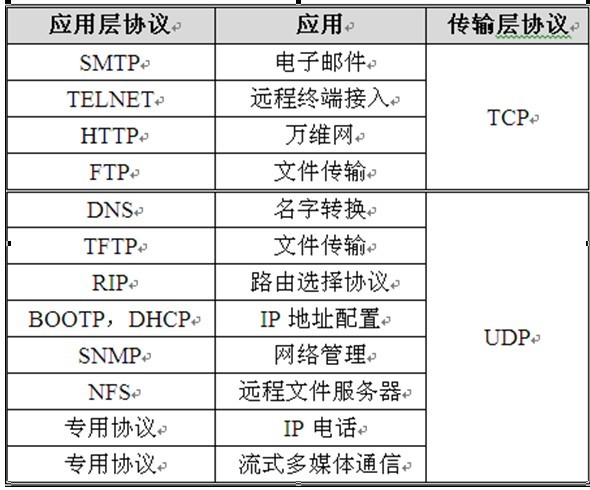
TCP和UDP最主要的区别是TCP是可靠传输的,UDP是不可靠传输的。所以如果我们的发送消息之类的场景,因为你要确保用户的消息不会丢失,需要使用TCP协议。如果你是在进行视频聊天或者看直播,那你可以使用UDP协议,因为即使几个画面丢失了,对用户来说影响也不是很大。哪些应用层协议使用TCP,哪些使用UDP的话,你自己去查一下,懒得打字了。
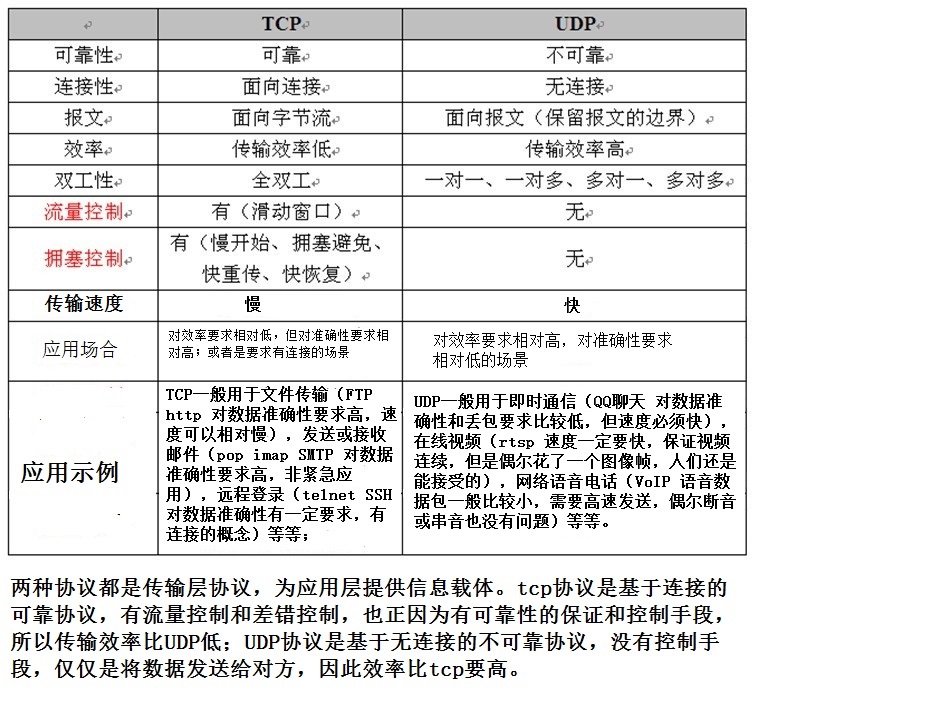
TCP滑动窗口协议
滑动窗口协议(Sliding Window Protocol),属于TCP协议的一种应用,用于网络数据传输时的流量控制,以避免拥塞的发生。该协议允许发送方在停止并等待确认前发送多个数据分组。由于发送方不必每发一个分组就停下来等待确认,因此该协议可以加速数据的传输,提高网络吞吐量。
(1)发送方不必发送一个全窗口大小的数据。
(2)来自接收方的一个报文段确认数据并把窗口向右边滑动,这是因为窗口的大小是相对于确认序号的。
(3)窗口的大小可以减小,但是窗口的右边沿却不能够向左移动。
(4)接收方在发送一个ACK前不必等待窗口被填满。
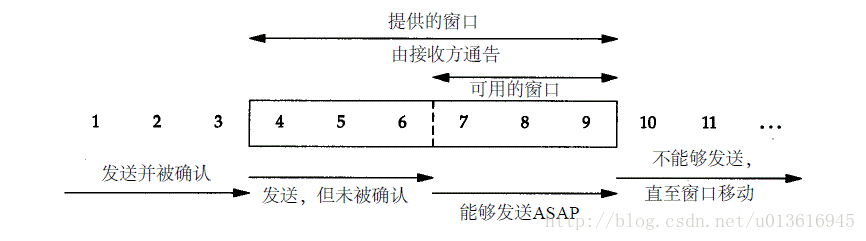
TCP的滑动窗口主要有两个作用,一是提供TCP的可靠性,二是提供TCP的流控特性。同时滑动窗口机制还体现了TCP面向字节流的设计思路。
可靠:对发送的数据进行确认
流控制:窗口大小随链路变化。
一、tcp窗口机制
tcp中窗口大小是指tcp协议一次传输多少个数据。因为TCP是一个面向连接的可靠的传输协议,既然是可靠的就需要对传输的数据进行确认。TCP的窗口机制有两种,一种是固定窗口大小,另一种是滑动窗口。数据在传输时,TCP会对所有数据进行编号,发送方在发送过程中始终保持着一个窗口,只有落在发送窗口内的数据帧才允许被发送;同时接受方也始终保持着一个接收窗口,只有落在窗口内的数据才会被接收。这样通过改变发送窗口和接收窗口的大小就可以实现流量控制。
二、tcp窗口大小
tcp的窗口滑动技术通过动态改变窗口的大小来调节两台主机之间数据传输。每个TCP/IP主机支持全双工数据传输,因此TCP有两个滑动窗口,一个用于接收数据,一个用于发送数据。接收方设备要求窗口大小为0时,表明接收方已经接收了全部数据,或者接收方应用程序没有时间读取数据,要求暂停发送。
TCP在传送数据时,第一次发数据发送方的窗口大小是由链路带宽决定的,但是接受方在接收到发送方的数据后,返回ack确认报文,同时也告诉了发送方自己的窗口大小,此时发送发第二次发送数据时,会改变自己的窗口大小和接受方一致。
当窗口过大时,会导致不必要的数据来拥塞我们的链路,但是窗口太小时,会造成很大的延时,比如为1时,发送方没发送一个数据,接受方就会返回一个ack报文,在发送方未接收到接受方的确认报文ack之前不会进行下一次发送。当链路变好了或者变差了这个窗口还会发生变话,并不是第一次协商好了以后就永远不变了。
三、窗口滑动协议
是TCP使用的一种流量控制方法。该协议允许发送方在停止并等待接收确认报文前可以连续发送多个分组。由于发送方不必每发一个分组就停下来等待确认,因此该协议可以加速数据的传输。 只有在接收窗口向前滑动时(与此同时也发送了确认),发送窗口才有可能向前滑动。收发两端的窗口按照以上规律不断地向前滑动,因此这种协议又称为滑动窗口协议。
慢启动:
定义:
慢启动是一种TCP拥塞控制机制,基本思想是TCP开始在一个网络中传输数据或发现数据丢失并开始重发时,首先慢慢的对网路实际容量进行试探,避免由于发送了过量的数据而导致阻塞。
过程:
慢启动为发送方的TCP增加了另一个窗口:拥塞窗口。TCP发送方在初始阶段不是线性地增加其发送速率,而是以指数的速度增加,即每过一个RTT将拥塞窗口值翻倍(初始值为1个报文段)。TCP发送方继续以指数速度增加其发送速率,直到发生一个丢包事件,此时拥塞窗口值将被降为一半。发送方取拥塞窗口与通告窗口的最小值为发送上限。拥塞窗口是发送方使用的流量控制,而通告窗口则是接收方使用的流量控制。
快重传(Fast Retransmit)
-
要求接收方每收到一个失序的报文段后就立即发出重复确认而不是等待自己发送数据时才捎带确认
-
发送方只要一连收到三个重复确认就立即重传对方尚未收到的报文段,而不必等待设置的重传计时器到期
什么是https协议?https协议用到了哪种密钥?
https是在http上面套了一层ssl,用来实现安全连接。用到的密钥有对称密钥和非对称密钥。目前基本上大一点的网站,都会使用https
(一)对称加密(Symmetric Cryptography)*
对称密钥加密,又称私钥加密,即信息的发送方和接收方用一个密钥去加密和解密数据。它的最大优势是加/解密速度快,适合于对大数据量进行加密,对称加密的一大缺点是密钥的管理与分配,换句话说,如何把密钥发送到需要解密你的消息的人的手里是一个问题。在发送密钥的过程中,密钥有很大的风险会被黑客们拦截。现实中通常的做法是将对称加密的密钥进行非对称加密,然后传送给需要它的人。
对称加密通常使用的是相对较小的密钥,一般小于256 bit。因为密钥越大,加密越强,但加密与解密的过程越慢。如果你只用1 bit来做这个密钥,那黑客们可以先试着用0来解密,不行的话就再用1解;但如果你的密钥有1 MB大,黑客们可能永远也无法破解,但加密和解密的过程要花费很长的时间。密钥的大小既要照顾到安全性,也要照顾到效率,是一个trade-off。
(二)非对称加密(Asymmetric Cryptography)*
非对称密钥加密系统,又称公钥密钥加密。非对称加密为数据的加密与解密提供了一个非常安全的方法,它使用了一对密钥,公钥(public key)和私钥(private key)。私钥只能由一方安全保管,不能外泄,而公钥则可以发给任何请求它的人。非对称加密使用这对密钥中的一个进行加密,而解密则需要另一个密钥。比如,你向银行请求公钥,银行将公钥发给你,你使用公钥对消息加密,那么只有私钥的持有人--银行才能对你的消息解密。与对称加密不同的是,银行不需要将私钥通过网络发送出去,因此安全性大大提高。 目前最常用的非对称加密算法是RSA算法。公钥机制灵活,但加密和解密速度却比对称密钥加密慢得多。
什么是左连接,什么是右连接,什么是全连接,什么是内连接?
1.内连接
1.1.等值连接:在连接条件中使用等于号(=)运算符比较被连接列的列值,其查询结果中列出被连接表中的所有列,包括其中的重复列。
1.2.不等值连接:在连接条件使用除等于运算符以外的其它比较运算符比较被连接的列的列值。这些运算符包括>、>=、<=、<、!>、!<和<>。
1.3.自然连接:在连接条件中使用等于(=)运算符比较被连接列的列值,但它使用选择列表指出查询结果集合中所包括的列,并删除连接表中的重复列。
2.外连接
2.1.左联接:是以左表为基准,将a.stuid = b.stuid的数据进行连接,然后将左表没有的对应项显示,右表的列为NULL
2.2.右连接:是以右表为基准,将a.stuid = b.stuid的数据进行连接,然以将右表没有的对应项显示,左表的列为NULL
2.3.全连接:完整外部联接返回左表和右表中的所有行。当某行在另一个表中没有匹配行时,则另一个表的选择列表列包含空值。如果表之间有匹配行,则整个结果集行包含基表的数据值。
3.交叉连接
交叉连接:交叉联接返回左表中的所有行,左表中的每一行与右表中的所有行组合。交叉联接也称作笛卡尔积。
SQL注入
防止SQL注入,在jdbc中一种有效的方法就是使用prepareStatement,prepareStatement其实就是使用了预编译的方式来防止SQL注入的。
缓存过期策略
1.FIFO(First In First out):先见先出,淘汰最先近来的页面,新进来的页面最迟被淘汰,完全符合队列。
2.LRU(Least recently used):最近最少使用,淘汰最近不使用的页面
3.LFU(Least frequently used): 最近使用次数最少, 淘汰使用次数最少的页面
ConcurrentModifyException的产生原因及如何避免(即fail-fast)
如果不符合条件则将该对象从集合中移除。这种情况很容易产生ConcurrentModificationExceptionException,这个异常会导致程序停止继续运行,所以遇到这个异常必须要处理来保证程序正确运行。
二.在单线程环境下的解决办法
在Itr类中也给出了一个remove()方法:
在这个方法中,删除元素实际上调用的就是list.remove()方法,但是它多了一个操作:
expectedModCount = modCount;
-
public
class Test {
-
public static void main(String[] args) {
-
ArrayList<Integer> list =
new ArrayList<Integer>();
-
list.add(
2);
-
Iterator<Integer> iterator = list.iterator();
-
while(iterator.hasNext()){
-
Integer integer = iterator.next();
-
if(integer==
2)
-
iterator.remove();
//注意这个地方
-
}
-
}
-
}
- 1
多线程还是会有问题
有可能有朋友说ArrayList是非线程安全的容器,换成Vector就没问题了,实际上换成Vector还是会出现这种错误。
原因在于,虽然Vector的方法采用了synchronized进行了同步,但是实际上通过Iterator访问的情况下,每个线程里面返回的是不同的iterator,也即是说expectedModCount是每个线程私有。假若此时有2个线程,线程1在进行遍历,线程2在进行修改,那么很有可能导致线程2修改后导致Vector中的modCount自增了,线程2的expectedModCount也自增了,但是线程1的expectedModCount没有自增,此时线程1遍历时就会出现expectedModCount不等于modCount的情况了。
因此一般有2种解决办法:
1)在使用iterator迭代的时候使用synchronized或者Lock进行同步;
2)使用并发容器CopyOnWriteArrayList代替ArrayList和Vector。
TIME_WAIT多了有什么问题?
为什么一定要有TIME_WAIT的状态?能否直接进入CLOSEED?不能,TCP是建立在不可靠网络上的可靠协议,主动方发送的ACK包可能延迟,从而触发被动方的FIN包重传,这一来一去,就是2MSL的时间。因此,必须要有这个状态,以保证TCP的可靠性。否则,如果当重传的FIN包到达后,可能导致两个问题:
1. 旧连接已经不在,只能返回RST包,被动关闭的一方无法关闭TCP连接
2. 新连接已经建立,FIN包可能对新连接有干扰。
所以,TIME_WAIT不能没有,但不能太多,该考虑限制它的数量。
spring加载配置文件三办法
1、把applicationContext.xml直接放在WEB-INF/classes下,spring会采用默认的加载方式
2、采用在web.xml中配置ContextLoaderListenera或ContextLoaderServlet指定加载路径方式。它们两个有着同样的功能,都实现在了org.springframework.web.context.ContextLoader类,都要定义contextConfigLocation参数。区别在于listener不能在Servlet 2.2兼容的容器中使用。
代码
<context-param>
<param-name>contextConfigLocation</param-name>
<param-value>
/WEB-INF/daoContext.xml,
/WEB-INF/config/appContext1.xml,
/WEB-INF/config/appContext2.xml
</param-value>
</context-param>
<listener>
<listener-class>org.springframework.web.context.ContextLoaderListener</listener-class>
</listener>
<!-- 另一种是使用ContextLoaderServlet
<servlet>
<servlet-name>context</servlet-name>
<servlet-class>org.springframework.web.context.ContextLoaderServlet</servlet-class>
<load-on-startup>1</load-on-startup>
</servlet>
-->
3 通过ClassPathXmlApplicationContext或XmlWebApplicationContext代码动态加载!
浏览器中网址访问过程(详细)
(1)浏览器本身是一个客户端,当你输入URL的时候,首先浏览器会去请求DNS服务器,通过DNS获取相应的域名对应的IP
(2)然后通过IP地址找到IP对应的服务器后,要求建立TCP连接
(3)浏览器发送完HTTP Request(请求)包后,服务器接收到请求包之后才开始处理请求包
(4)在服务器收到请求之后,服务器调用自身服务,返回HTTP Response(响应)包
(5)客户端收到来自服务器的响应后开始渲染这个Response包里的主体(body),等收到全部的内容随后断开与该服务器之间的TCP连接。
1. DNS解析
具体的查找过程和策略可以分为下面这几步:
(1)在浏览器中输入www.google.cn域名,操作系统会先检查自己本地的hosts文件是否有这个网址映射关系,如果有,就先调用这个IP地址映射,完成域名解析。
(2)如果hosts里没有这个域名的映射,则查找本地DNS解析器缓存,是否有这个网址映射关系,如果有,直接返回,完成域名解析。
(3)如果hosts与本地DNS解析器缓存都没有相应的网址映射关系,首先会找TCP/IP参数中设置的首选DNS服务器,在此我们叫它本地DNS服务器,此服务器收到查询时,如果要查询的域名,包含在本地配置区域资源中,则返回解析结果给客户机,完成域名解析,此解析具有权威性。
(4)如果要查询的域名,不由本地DNS服务器区域解析,但该服务器已缓存了此网址映射关系,则调用这个IP地址映射,完成域名解析,此解析不具有权威性。
(5)如果本地DNS服务器本地区域文件与缓存解析都失效,则根据本地DNS服务器的设置(是否设置转发器)进行查询,如果未用转发模式,本地DNS就把请求发至13台根DNS,根DNS服务器收到请求后会判断这个域名(.com)是谁来授权管理,并会返回一个负责该顶级域名服务器的一个IP。本地DNS服务器收到IP信息后,将会联系负责.com域的这台服务器。这台负责.com域的服务器收到请求后,如果自己无法解析,它就会找一个管理.com域的下一级DNS服务器地址(google.com)给本地DNS服务器。当本地DNS服务器收到这个地址后,就会找google.com域服务器,重复上面的动作,进行查询,直至找到www.google.com主机。
(6)如果用的是转发模式,此DNS服务器就会把请求转发至上一级DNS服务器,由上一级服务器进行解析,上一级服务器如果不能解析,或找根DNS或把转请求转至上上级,以此循环。不管是本地DNS服务器用是是转发,还是根提示,最后都是把结果返回给本地DNS服务器,由此DNS服务器再返回给客户机。
2. Socket建立连接
当我们输入这样一个请求时,首先要建立一个socket连接,因为socket是通过ip和端口建立的,所以之前还有一个DNS解析过程,把www.google.com变成ip,如果url里不包含端口号,则会使用该协议的默认端口号。
3. 发送HTTP请求
连接成功建立后,开始向web服务器发送请求,当浏览器向Web服务器发出请求时,它向服务器传递了一个数据块,也就是请求信息,HTTP请求信息由3部分组成:
(1)请求方法URI协议/版本
(2)请求头(Request Header)
(3)请求正文
3.1 请求方法URI协议/版本
请求的第一行是“方法URL议/版本”:GET/sample.jsp HTTP/1.1``/sample.jsp
以上代码中“GET”代表请求方法,表示URI,HTTP/1.1“`代表协议和协议的版本。
根据HTTP标准,HTTP请求可以使用多种请求方法。例如:HTTP1.1支持7种请求方法:GET、POST、HEAD、OPTIONS、PUT、DELETE和TARCE。在Internet应用中,最常用的方法是GET和POST。
URL完整地指定了要访问的网络资源,通常只要给出相对于服务器的根目录的相对目录即可,因此总是以“/”开头,最后,协议版本声明了通信过程中使用HTTP的版本。
3.2 请求头(Request Header)
请求头包含许多有关的客户端环境和请求正文的有用信息。例如,请求头可以声明浏览器所用的语言,请求正文的长度等。
- 1
3.3 请求正文
请求头和请求正文之间是一个空行,这个行非常重要,它表示请求头已经结束,接下来的是请求正文。请求正文中可以包含客户提交的查询字符串信息:
username=jinqiao&password=1234
在以上的例子的HTTP请求中,请求的正文只有一行内容。当然,在实际应用中,HTTP请求正文可以包含更多的内容。
3.4 HTTP请求方法:GET方法与POST方法
3.4.1 GET方法
GET方法是默认的HTTP请求方法,我们日常用GET方法来提交表单数据,然而用GET方法提交的表单数据只经过了简单的编码,同时它将作为URL的一部分向Web服务器发送,因此,如果使用GET方法来提交表单数据就存在着安全隐患上。例如Http://127.0.0.1/login.jsp?Name=zhangshi&Age=30&Submit=%cc%E+%BD%BB
从上面的URL请求中,很容易就可以辩认出表单提交的内容。(?之后的内容)另外由于GET方法提交的数据是作为URL请求的一部分所以提交的数据量不能太大
3.4.2 POST方法
POST方法是GET方法的一个替代方法,它主要是向Web服务器提交表单数据,尤其是大批量的数据。POST方法克服了GET方法的一些缺点。通过POST方法提交表单数据时,数据不是作为URL请求的一部分而是作为标准数据传送给Web服务器,这就克服了GET方法中的信息无法保密和数据量太小的缺点。因此,出于安全的考虑以及对用户隐私的尊重,通常表单提交时采用POST方法。
3.5 各种HTTP请求的含义
GET
通过请求URI得到资源
POST
用于添加新的内容
PUT
用于修改某个内容
DELETE
删除某个内容
CONNECT
用于代理进行传输,如使用SSL
OPTIONS
询问可以执行哪些方法
PATCH
部分文档更改
PROPFIND
查看属性
PROPPATCH
设置属性
MKCOL
创建集合(文件夹)
COPY
拷贝
MOVE
移动
LOCK
加锁
UNLOCK
解锁
TRACE
用于远程诊断服务器
HEAD
类似于GET, 但是不返回body信息,用于检查对象是否存在,以及得到对象的元数据
4.1 HTTP响应报文头
HTTP应答与HTTP请求相似,HTTP响应也由3个部分构成,分别是:
(1)协议状态版本代码描述
(2)响应头(Response Header)
(3)响应正文
下面是一个HTTP响应的例子:
-
HTTP/
1.1
200 OK
-
Server:Apache Tomcat/
5.0
.12
-
Date:Mon,
6Oct2003
13:
23:
42 GMT
-
Content-Length:
112
-
-
<html>
-
<head>
-
<title>HTTP响应示例
<title>
-
</head>
-
<body>
-
Hello HTTP!
-
</body>
-
</html>
- 1
协议状态代码描述HTTP响应的第一行类似于HTTP请求的第一行,它表示通信所用的协议是HTTP1.1服务器已经成功的处理了客户端发出的请求(200表示成功):HTTP/1.1 200 OK
响应头(Response Header)响应头也和请求头一样包含许多有用的信息,例如服务器类型、日期时间、内容类型和长度等:
-
Server:Apache Tomcat/
5.0
.12
-
Date:Mon,
6Oct2003
13:
13:
33 GMT
-
Content-Type:text/html
-
Last-Moified:Mon,
6
Oct
2003
13:
23:
42 GMT
-
Content-Length:
112
- 1
响应正文响应正文就是服务器返回的HTML页面:
-
<html>
-
<head>
-
<title>HTTP响应示例
<title>
-
</head>
-
<body>
-
Hello HTTP!
-
</body>
-
</html>
- 1
响应头和正文之间也必须用空行分隔。
4.2 HTTP应答码
HTTP应答码也称为状态码,它反映了Web服务器处理HTTP请求状态。HTTP应答码由3位数字构成,其中首位数字定义了应答码的类型:
1XX-信息类(Information),表示收到Web浏览器请求,正在进一步的处理中
2XX-成功类(Successful),表示用户请求被正确接收,理解和处理例如:200 OK
3XX - 重定向类(Redirection),表示请求没有成功,客户必须采取进一步的动作。
4XX - 客户端错误(Client Error),表示客户端提交的请求有错误 例如:404 NOT Found,意味着请求中所引用的文档不存在。
5XX - 服务器错误(Server Error)表示服务器不能完成对请求的处理:如 500
对于我们Web开发人员来说掌握HTTP应答码有助于提高Web应用程序调试的效率和准确性。
5. 关闭连接
当应答结束后,Web浏览器与Web服务器必须断开,以保证其它Web浏览器能够与Web服务器建立连接。
决定Java堆的大小以及内存占用
约束
有多少物理内存可以供JVM使用?是部署多个JVM或者单个JVM?对做出的决定有重要影响。下面列出了一些要点可以帮助决定有多少物理内存可以供使用。
1、一个机器上面只是部署一个JVM,且就一个应用使用?如果是这种情况,那么机器的所有物理内存可以供JVM使用。
2、一个机器上部署了多个JVM?或者一个机器上部署了多个应用?如果是这两个中的任何一种情况,你就必须要决定每一个JVM或者应用需要分配多少内存了。
无论是前面的哪种情况,都需要给操作系统留出一些内存。
无序数组的中位数
快速中位数算法,类似于快速排序,采用的是分而治之的思想。基本思路是:任意挑一个元素,以该元素为支点,将数组分成两部分,左部分是小于等于支点的,右部分是大于支点的。如果你的运气爆棚,左部分正好是(n-1)/2个元素,那么支点的那个数就是中位数。
算法的核心是使用最小堆(heap),你想到了吗?首先将数组的前(n+1)/2个元素建立一个最小堆。然后,对于下一个元素,和堆顶的元素比较,如果小于等于,丢弃之,接着看下一个元素。如果大于,则用该元素取代堆顶,再调整堆,接着看下一个元素。重复这个步骤,直到数组为空。当数组都遍历完了,那么,堆顶的元素即是中位数。可以看出,长度为(n+1)/2的最小堆是解决方案的精华之处。(即取数组中较大的一半的数)
Linux下用netstat查看网络状态、端口状态
netstat [选项]
命令中各选项的含义如下:
-a 显示所有socket,包括正在监听的。
-c 每隔1秒就重新显示一遍,直到用户中断它。
-i 显示所有网络接口的信息,格式同“ifconfig -e”。
-n 以网络IP地址代替名称,显示出网络连接情形。
-r 显示核心路由表,格式同“route -e”。
-t 显示TCP协议的连接情况。
-u 显示UDP协议的连接情况。
-v 显示正在进行的工作。
用LinkedHashMap实现LRU缓存算法
-
import java.util.*;
-
-
//扩展一下LinkedHashMap这个类,让他实现LRU算法
-
-
class LRULinkedHashMap<K,V> extends LinkedHashMap<K,V>{
-
-
//定义缓存的容量
-
-
private
int capacity;
-
-
private
static
final
long serialVersionUID =
1L;
-
-
//带参数的构造器
-
-
LRULinkedHashMap(
int capacity){
-
-
//调用LinkedHashMap的构造器,传入以下参数
-
super(
16,
0.75f,
true);
-
//传入指定的缓存最大容量
-
-
this.capacity=capacity;
-
}
-
//实现LRU的关键方法,如果map里面的元素个数大于了缓存最大容量,则删除链表的顶端元素
-
@Override
-
public boolean removeEldestEntry(Map.Entry<K, V> eldest){
-
-
System.out.println(eldest.getKey() +
"=" + eldest.getValue());
-
-
return size()>capacity;
-
}
-
-
}
- 1
几种阻塞队列介绍
BlockingQueue
获取元素的时候等待队列里有元素,否则阻塞
保存元素的时候等待队列里有空间,否则阻塞
用来简化生产者消费者在多线程环境下的开发
ArrayBlockingQueue
FIFO、数组实现
有界阻塞队列,一旦指定了队列的长度,则队列的大小不能被改变
在生产者消费者例子中,如果生产者生产实体放入队列超过了队列的长度,则在offer(或者put,add)的时候会被阻塞,直到队列的实体数量< 队列的初始size为止。不过可以设置超时时间,超时后队列还未空出位置,则offer失败。
如果消费者发现队列里没有可被消费的实体时也会被阻塞,直到有实体被生产出来放入队列位置,不过可以设置等待的超时时间,超过时间后会返回null
DelayQueue
有界阻塞延时队列,当队列里的元素延时期未到时,通过take方法不能获取,会被阻塞,直到有元素延时到期为止。
如:
1.obj 5s 延时到期
2.obj 6s 延时到期
3.obj 9s 延时到期
那么在take的时候,需要等待5秒钟才能获取第一个obj,再过1s后可以获取第二个obj,再过3s后可以获得第三个obj
这个队列可以用来处理session过期失效的场景,比如session在创建的时候设置延时到期时间为30分钟,放入延时队列里,然后通过一个线程来获取这个队列元素,只要能被获取到的,表示已经是过期的session,被获取的session可以肯定超过30分钟了,这时对session进行失效。
LinkedBlockingQueue
FIFO、Node链表结构
可以通过构造方法设置capacity来使得阻塞队列是有界的,也可以不设置,则为无界队列
其他功能类似ArrayBlockingQueue
PriorityBlockingQueue
无界限队列,相当于PriorityQueue + BlockingQueue
插入的对象必须是可比较的,或者通过构造方法实现插入对象的比较器Comparator<? super E>
队列里的元素按Comparator<? super E> comparator比较结果排序,PriorityBlockingQueue可以用来处理一些有优先级的事物。比如短信发送优先级队列,队列里已经有某企业的100000条短信,这时候又来了一个100条紧急短信,优先级别比较高,可以通过PriorityBlockingQueue来轻松实现这样的功能。这样这个100条可以被优先发送
SynchronousQueue
无内部容量的阻塞队列,put必须等待take,同样take必须等待put。比较适合两个线程间的数据传递。异步转同步的场景不太适用,因为对于异步线程来说在处理完事务后进行put,但是必须等待put的值被取走。
快速找到未知长度单链表的中间节点
这里我们快慢指针的方法来解决这个问题,快指针每次走2个结点,慢指针每次走1个结点,当快指针走完链表,慢指针刚好走到中间,这就是快慢指针的核心思想。
JAVA BIO与NIO、AIO的区别(这个容易理解)
一、BIO
同步阻塞
服务器实现模式:一个连接一个线程,即客户端有连接请求时服务器端就需要启动一个线程进行处理,如果这个连接不做任何事情会造成不必要的线程开销。
在JDK1.4出来之前,我们建立网络连接的时候采用BIO模式,需要先在服务端启动一个ServerSocket,然后在客户端启动Socket来对服务端进行通信,默认情况下服务端需要对每个请求建立一堆线程等待请求,而客户端发送请求后,先咨询服务端是否有线程相应,如果没有则会一直等待或者遭到拒绝请求,如果有的话,客户端会线程会等待请求结束后才继续执行。
二、NIO
同步非阻塞
服务器实现模式为一个请求一个线程,但客户端发送的连接请求都会注册到多路复用器上,多路复用器轮询到连接有I/O请求时才启动一个线程进行处理。
NIO本身是基于事件驱动思想来完成的,其主要想解决的是BIO的大并发问题: 在使用同步I/O的网络应用中,如果要同时处理多个客户端请求,或是在客户端要同时和多个服务器进行通讯,就必须使用多线程来处理。也就是说,将每一个客户端请求分配给一个线程来单独处理。这样做虽然可以达到我们的要求,但同时又会带来另外一个问题。由于每创建一个线程,就要为这个线程分配一定的内存空间(也叫工作存储器),而且操作系统本身也对线程的总数有一定的限制。如果客户端的请求过多,服务端程序可能会因为不堪重负而拒绝客户端的请求,甚至服务器可能会因此而瘫痪。
NIO基于Reactor,当socket有流可读或可写入socket时,操作系统会相应的通知引用程序进行处理,应用再将流读取到缓冲区或写入操作系统。 也就是说,这个时候,已经不是一个连接就要对应一个处理线程了,而是有效的请求,对应一个线程,当连接没有数据时,是没有工作线程来处理的。
BIO与NIO一个比较重要的不同,是我们使用BIO的时候往往会引入多线程,每个连接一个单独的线程;而NIO则是使用单线程或者只使用少量的多线程,每个连接共用一个线程。
AIO模型
异步非阻塞
服务器实现模式为一个有效请求一个线程,客户端的I/O请求都是由OS先完成了再通知服务器应用去启动线程进行处理,
java OOM问题排查
MyBatis 提供了查询缓存来缓存数据,以提高查询的性能。MyBatis 的缓存分为一级缓存和二级缓存。
- 一级缓存是 SqlSession 级别的缓存
- 二级缓存是 mapper 级别的缓存,多个 SqlSession 共享
一级缓存
一级缓存是 SqlSession 级别的缓存,是基于 HashMap 的本地缓存。不同的 SqlSession 之间的缓存数据区域互不影响。
一级缓存的作用域是 SqlSession 范围,当同一个 SqlSession 执行两次相同的 sql 语句时,第一次执行完后会将数据库中查询的数据写到缓存,第二次查询时直接从缓存获取不用去数据库查询。当 SqlSession 执行 insert、update、delete 操做并提交到数据库时,会清空缓存,保证缓存中的信息是最新的。
MyBatis 默认开启一级缓存。
二级缓存
二级缓存是 mapper 级别的缓存,同样是基于 HashMap 进行存储,多个 SqlSession 可以共用二级缓存,其作用域是 mapper 的同一个 namespace。不同的 SqlSession 两次执行相同的 namespace 下的 sql 语句,会执行相同的 sql,第二次查询只会查询第一次查询时读取数据库后写到缓存的数据,不会再去数据库查询。
MyBatis 默认没有开启二级缓存,开启只需在配置文件中写入如下代码:
-
<settings>
-
<setting name="cacheEnabled" value="true"/>
-
</settings>
- 1
switch支持的数据类型
switch表达式后面的数据类型只能是byte,short,char,int四种整形类型,枚举类型和java.lang.String类型(从java 7才允许)
单例模式的两种推荐写法
双重检查[推荐用]
-
public
class Singleton {
-
-
private
static
volatile Singleton singleton;
-
-
private Singleton() {}
-
-
public static Singleton getInstance() {
-
if (singleton ==
null) {
-
synchronized (Singleton.class) {
-
if (singleton ==
null) {
-
singleton =
new Singleton();
-
}
-
}
-
}
-
return singleton;
-
}
-
}
- 1
静态内部类[推荐用]
-
public
class Singleton {
-
-
private Singleton() {}
-
-
private
static
class SingletonInstance {
-
private
static
final Singleton INSTANCE =
new Singleton();
-
}
-
-
public static Singleton getInstance() {
-
return SingletonInstance.INSTANCE;
-
}
-
}
- 1
这种方式跟饿汉式方式采用的机制类似,但又有不同。两者都是采用了类装载的机制来保证初始化实例时只有一个线程。不同的地方在饿汉式方式是只要Singleton类被装载就会实例化,没有Lazy-Loading的作用,而静态内部类方式在Singleton类被装载时并不会立即实例化,而是在需要实例化时,调用getInstance方法,才会装载SingletonInstance类,从而完成Singleton的实例化。
类的静态属性只会在第一次加载类的时候初始化,所以在这里,JVM帮助我们保证了线程的安全性,在类进行初始化时,别的线程是无法进入的。
继承和组合的区别
| 组 合 关 系 | 继 承 关 系 |
| 优点:不破坏封装,整体类与局部类之间松耦合,彼此相对独立 | 缺点:破坏封装,子类与父类之间紧密耦合,子类依赖于父类的实现,子类缺乏独立性 |
| 优点:具有较好的可扩展性 | 缺点:支持扩展,但是往往以增加系统结构的复杂度为代价 |
| 优点:支持动态组合。在运行时,整体对象可以选择不同类型的局部对象 | 缺点:不支持动态继承。在运行时,子类无法选择不同的父类 |
| 优点:整体类可以对局部类进行包装,封装局部类的接口,提供新的接口 | 缺点:子类不能改变父类的接口 |
| 缺点:整体类不能自动获得和局部类同样的接口 | 优点:子类能自动继承父类的接口 |
| 缺点:创建整体类的对象时,需要创建所有局部类的对象 | 优点:创建子类的对象时,无须创建父类的对象 |
java线程中的interrupt,isInterrupt,interrupted方法
在java的线程Thread类中有三个方法,比较容易混淆,在这里解释一下
(1)interrupt:置线程的中断状态
(2)isInterrupt:线程是否中断
(3)interrupted:返回线程的上次的中断状态,并清除中断状态
1. thread.isInterrupt()和Thread.interrupted()都返回当前线程interrupt的状态
thread.isInterrupt()是非静态函数,作用目标是“线程实例”,一般用法如下,
TestInterrupt t = new TestInterrupt();t.start();System.out.println(t.isInterrupt());
而Thread.interrupted()是静态函数,作用目标是“当前线程”System.out.println(Thread.interrupted());
并且它会把当前线程的interrupt状态“复位”,假设当前线程的isInterrupt状态为true,它会返回true,但过后isInterrupt的状态会复位为false。之后调用(Thread)t.isInterrupt或Thread.interrupted都会返回false
分布式一致性算法2PC和3PC
2PC
2PC,二阶段提交协议,即将事务的提交过程分为两个阶段来进行处理:准备阶段和提交阶段。事务的发起者称协调者,事务的执行者称参与者。
阶段1:准备阶段
1、协调者向所有参与者发送事务内容,询问是否可以提交事务,并等待所有参与者答复。
2、各参与者执行事务操作,将Undo和Redo信息记入事务日志中(但不提交事务)。
3、如参与者执行成功,给协调者反馈YES,即可以提交;如执行失败,给协调者反馈NO,即不可提交。
阶段2:提交阶段
此阶段分两种情况:所有参与者均反馈YES、或任何一个参与者反馈NO。
所有参与者均反馈YES时,即提交事务。
任何一个参与者反馈NO时,即中断事务。
提交事务:(所有参与者均反馈YES)
1、协调者向所有参与者发出正式提交事务的请求(即Commit请求)。
2、参与者执行Commit请求,并释放整个事务期间占用的资源。
3、各参与者向协调者反馈Ack完成的消息。
4、协调者收到所有参与者反馈的Ack消息后,即完成事务提交。
2PC的缺陷
1、同步阻塞:最大的问题即同步阻塞,即:所有参与事务的逻辑均处于阻塞状态。
2、单点:协调者存在单点问题,如果协调者出现故障,参与者将一直处于锁定状态。
3、脑裂:在阶段2中,如果只有部分参与者接收并执行了Commit请求,会导致节点数据不一致。
由于2PC存在如上同步阻塞、单点、脑裂问题,因此又出现了2PC的改进方案,即3PC。
3PC
3PC,三阶段提交协议,是2PC的改进版本,即将事务的提交过程分为CanCommit、PreCommit、do Commit三个阶段来进行处理。
阶段1:CanCommit
1、协调者向所有参与者发出包含事务内容的CanCommit请求,询问是否可以提交事务,并等待所有参与者答复。
2、参与者收到CanCommit请求后,如果认为可以执行事务操作,则反馈YES并进入预备状态,否则反馈NO。
阶段2:PreCommit
此阶段分两种情况:
1、所有参与者均反馈YES,即执行事务预提交。
2、任何一个参与者反馈NO,或者等待超时后协调者尚无法收到所有参与者的反馈,即中断事务。
事务预提交:(所有参与者均反馈YES时)
1、协调者向所有参与者发出PreCommit请求,进入准备阶段。
2、参与者收到PreCommit请求后,执行事务操作,将Undo和Redo信息记入事务日志中(但不提交事务)。
3、各参与者向协调者反馈Ack响应或No响应,并等待最终指令。
中断事务:(任何一个参与者反馈NO,或者等待超时后协调者尚无法收到所有参与者的反馈时)
1、协调者向所有参与者发出abort请求。
2、无论收到协调者发出的abort请求,或者在等待协调者请求过程中出现超时,参与者均会中断事务。
阶段3:do Commit
此阶段也存在两种情况:
1、所有参与者均反馈Ack响应,即执行真正的事务提交。
2、任何一个参与者反馈NO,或者等待超时后协调者尚无法收到所有参与者的反馈,即中断事务。
提交事务:(所有参与者均反馈Ack响应时)
1、如果协调者处于工作状态,则向所有参与者发出do Commit请求。
2、参与者收到do Commit请求后,会正式执行事务提交,并释放整个事务期间占用的资源。
3、各参与者向协调者反馈Ack完成的消息。
4、协调者收到所有参与者反馈的Ack消息后,即完成事务提交。
中断事务:(任何一个参与者反馈NO,或者等待超时后协调者尚无法收到所有参与者的反馈时)
1、如果协调者处于工作状态,向所有参与者发出abort请求。
2、参与者使用阶段1中的Undo信息执行回滚操作,并释放整个事务期间占用的资源。
3、各参与者向协调者反馈Ack完成的消息。
4、协调者收到所有参与者反馈的Ack消息后,即完成事务中断。
3PC的优点和缺陷
优点:降低了阻塞范围,在等待超时后协调者或参与者会中断事务。避免了协调者单点问题,阶段3中协调者出现问题时,参与者会继续提交事务。
缺陷:脑裂问题依然存在,即在参与者收到PreCommit请求后等待最终指令,如果此时协调者无法与参与者正常通信,会导致参与者继续提交事务,造成数据不一致。
后记
无论2PC或3PC,均无法彻底解决分布式一致性问题。
解决一致性问题,唯有Paxos,后续将单独总结。
分布式事务的处理
本地事务数据库们使用SQL Server来举例,我们知道我们在使用 SQL Server 数据库是由两个文件组成的,一个数据库文件和一个日志文件,通常情况下,日志文件都要比数据库文件大很多。数据库进行任何写入操作的时候都是要先写日志的,同样的道理,我们在执行事务的时候数据库首先会记录下这个事务的redo操作日志,然后才开始真正操作数据库,在操作之前首先会把日志文件写入磁盘,那么当突然断电的时候,即使操作没有完成,在重新启动数据库时候,数据库会根据当前数据的情况进行undo回滚或者是redo前滚,这样就保证了数据的强一致性。
CAP定理
- 一致性(Consistency) : 客户端知道一系列的操作都会同时发生(生效)
- 可用性(Availability) : 每个操作都必须以可预期的响应结束
- 分区容错性(Partition tolerance) : 即使出现单个组件无法可用,操作依然可以完成
BASE理论
在分布式系统中,我们往往追求的是可用性,它的重要程序比一致性要高,那么如何实现高可用性呢? 前人已经给我们提出来了另外一个理论,就是BASE理论,它是用来对CAP定理进行进一步扩充的。BASE理论指的是:
- Basically Available(基本可用)
- Soft state(软状态)
- Eventually consistent(最终一致性)
BASE理论是对CAP中的一致性和可用性进行一个权衡的结果,理论的核心思想就是:我们无法做到强一致,但每个应用都可以根据自身的业务特点,采用适当的方式来使系统达到最终一致性(Eventual consistency)。
分布式事务解决方案
两阶段提交(2PC)
优点: 尽量保证了数据的强一致,适合对数据强一致要求很高的关键领域。(其实也不能100%保证强一致)
缺点: 实现复杂,牺牲了可用性,对性能影响较大,不适合高并发高性能场景,如果分布式系统跨接口调用,目前 .NET 界还没有实现方案。
二、补偿事务(TCC)
TCC 其实就是采用的补偿机制,其核心思想是:针对每个操作,都要注册一个与其对应的确认和补偿(撤销)操作。它分为三个阶段:
-
Try 阶段主要是对业务系统做检测及资源预留
-
Confirm 阶段主要是对业务系统做确认提交,Try阶段执行成功并开始执行 Confirm阶段时,默认 Confirm阶段是不会出错的。即:只要Try成功,Confirm一定成功。
-
Cancel 阶段主要是在业务执行错误,需要回滚的状态下执行的业务取消,预留资源释放。
举个例子,假入 Bob 要向 Smith 转账,思路大概是:
我们有一个本地方法,里面依次调用
1、首先在 Try 阶段,要先调用远程接口把 Smith 和 Bob 的钱给冻结起来。
2、在 Confirm 阶段,执行远程调用的转账的操作,转账成功进行解冻。
3、如果第2步执行成功,那么转账成功,如果第二步执行失败,则调用远程冻结接口对应的解冻方法 (Cancel)。
优点: 跟2PC比起来,实现以及流程相对简单了一些,但数据的一致性比2PC也要差一些
缺点: 缺点还是比较明显的,在2,3步中都有可能失败。TCC属于应用层的一种补偿方式,所以需要程序员在实现的时候多写很多补偿的代码,在一些场景中,一些业务流程可能用TCC不太好定义及处理。
三、本地消息表(异步确保)
本地消息表这种实现方式应该是业界使用最多的,其核心思想是将分布式事务拆分成本地事务进行处理,这种思路是来源于ebay。我们可以从下面的流程图中看出其中的一些细节:

基本思路就是:
消息生产方,需要额外建一个消息表,并记录消息发送状态。消息表和业务数据要在一个事务里提交,也就是说他们要在一个数据库里面。然后消息会经过MQ发送到消息的消费方。如果消息发送失败,会进行重试发送。
消息消费方,需要处理这个消息,并完成自己的业务逻辑。此时如果本地事务处理成功,表明已经处理成功了,如果处理失败,那么就会重试执行。如果是业务上面的失败,可以给生产方发送一个业务补偿消息,通知生产方进行回滚等操作。
生产方和消费方定时扫描本地消息表,把还没处理完成的消息或者失败的消息再发送一遍。如果有靠谱的自动对账补账逻辑,这种方案还是非常实用的。
这种方案遵循BASE理论,采用的是最终一致性,笔者认为是这几种方案里面比较适合实际业务场景的,即不会出现像2PC那样复杂的实现(当调用链很长的时候,2PC的可用性是非常低的),也不会像TCC那样可能出现确认或者回滚不了的情况。
优点: 一种非常经典的实现,避免了分布式事务,实现了最终一致性。在 .NET中 有现成的解决方案。
缺点: 消息表会耦合到业务系统中,如果没有封装好的解决方案,会有很多杂活需要处理。
四、MQ 事务消息
有一些第三方的MQ是支持事务消息的,比如RocketMQ,他们支持事务消息的方式也是类似于采用的二阶段提交,但是市面上一些主流的MQ都是不支持事务消息的,比如 RabbitMQ 和 Kafka 都不支持。
以阿里的 RocketMQ 中间件为例,其思路大致为:
第一阶段Prepared消息,会拿到消息的地址。
第二阶段执行本地事务,第三阶段通过第一阶段拿到的地址去访问消息,并修改状态。
也就是说在业务方法内要想消息队列提交两次请求,一次发送消息和一次确认消息。如果确认消息发送失败了RocketMQ会定期扫描消息集群中的事务消息,这时候发现了Prepared消息,它会向消息发送者确认,所以生产方需要实现一个check接口,RocketMQ会根据发送端设置的策略来决定是回滚还是继续发送确认消息。这样就保证了消息发送与本地事务同时成功或同时失败。
优点: 实现了最终一致性,不需要依赖本地数据库事务。
缺点: 实现难度大,主流MQ不支持,没有.NET客户端,RocketMQ事务消息部分代码也未开源。
虚拟机中堆区,栈区和静态区
JAVA的JVM的内存可分为3个区:堆(heap)、栈(stack)和方法区(method)
堆区:
1.存储的全部是对象,每个对象都包含一个与之对应的class的信息。(class的目的是得到操作指令)
2.jvm只有一个堆区(heap)被所有线程共享,堆中不存放基本类型和对象引用,只存放对象本身.
3.一般由程序员分配释放, 若程序员不释放,程序结束时可能由OS回收 。
栈区:
1.每个线程包含一个栈区,栈中只保存基础数据类型的对象和自定义对象的引用(不是对象),对象都存放在堆区中
2.每个栈中的数据(原始类型和对象引用)都是私有的,其他栈不能访问。
3.栈分为3个部分:基本类型变量区、执行环境上下文、操作指令区(存放操作指令)。
4.由编译器自动分配释放 ,存放函数的参数值,局部变量的值等.
静态区/方法区:
1.方法区又叫静态区,跟堆一样,被所有的线程共享。方法区包含所有的class和static变量。
2.方法区中包含的都是在整个程序中永远唯一的元素,如class,static变量。
3.—,全局变量和静态变量的存储是放在一块的,初始化的全局变量和静态变量在一块区域, 未初始化的全局变量和未初始化的静态变量在相邻的另一块区域。
volatile不保证原子性
当多个线程对volatile变量进行自增时,不保证原子性
可能会有疑问,不对啊,前面不是保证一个变量在修改volatile变量时,会让缓存行无效吗?然后其他线程去读就会读到新的值,对,这个没错。这个就是上面的happens-before规则中的volatile变量规则,但是要注意,线程1从主内存中读取inc的值 x++ 实际就是 x+1的操作
但是因为不是原子性的操作所以 线程1 读取了inc的值后 可能线程又执行了 线程2读取 inc的值也是10 并且+1 刷回主内存中让 线程1发现 inc的值发生了改变 使线程1放弃本地区域的inc值 重新从主内存中读取 但是 可能线程2在做完+1的操作后 要刷回主内存中时 线程1又执行了 此时 线程2虽然做了+1操作 但是可能并没有刷回主内存中 所以线程1发现的是主内存中的inc还是10 线程1做了+1 操作 线程2 把本地保存的 2刷入到主内存 线程1把本地保存的2刷入到 主内存 这就导致了 两个线程做+1操作最后值还是11 而这种情况是可能发生的 并不是一定发生 但是这个代码 还是线程不安全的 (即线程2在准备将值刷入主存的时候线程1准备增操作)
进程与线程的区别?
1. 地址空间: 同一进程的所有线程共享本进程的地址空间,而不同的进程之间的地址空间是独立的。
2. 资源拥有: 同一进程的所有线程共享本进程的资源,如内存,CPU,IO等。进程之间的资源是独立的,无法共享。
3. 执行过程:每一个进程可以说就是一个可执行的应用程序,每一个独立的进程都有一个程序执行的入口,顺序执行序列。但是线程不能够独立执行,必须依存在应用程序中,由程序的多线程控制机制进行控制。
4. 健壮性: 因为同一进程的所以线程共享此线程的资源,因此当一个线程发生崩溃时,此进程也会发生崩溃。 但是各个进程之间的资源是独立的,因此当一个进程崩溃时,不会影响其他进程。因此进程比线程健壮。
几种常用的操作系统调度策略
一、先来先服务和短作业(进程)优先调度算法
1.先来先服务调度算法
2.短作业(进程)优先调度算法
二、高优先权优先调度算法
1.优先权调度算法的类型
2.高响应比优先调度算法
三、基于时间片的轮转调度算法
1.时间片轮转法
Array和ArrayList的区别
Array:它是数组,申明数组的时候就要初始化并确定长度,长度不可变,而且它只能存储同一类型的数据,比如申明为String类型的数组,那么它只能存储S听类型数据
ArrayList:它是一个集合,需要先申明,然后再添加数据,长度是根据内容的多少而改变的,ArrayList可以存放不同类型的数据,在存储基本类型数据的时候要使用基本数据类型的包装类
题目描述:Java 中的 LinkedList 是单向链表还是双向链表?
是双向链表
ConcurrentHashMap 从Java7 到 Java8的改变
https://blog.csdn.net/fouy_yun/article/details/77816587
一:单链表八个以上红黑树
二:去除了显示锁(代码中加锁片段用的是synchronized关键字,而不是像1.7中的ReentrantLock。这一点也说明了,synchronized在新版本的JDK中优化的程度和ReentrantLock差不多了。)
Java7中,Segment继承于ReentrantLock使用了显示锁,在Segment的实例方法中,每个更新操作内部又使用Unsafe来处理更新。这显然是一种浪费。显示锁、Unsafe 这二者都是可以保证对对象的原子操作。使用一个即可。
使用Node数组替代了Segment数组来存储数据。Node数组中不再使用显示锁,而是Unsafe的乐观锁机制。
三:头插变成尾插*
四:从上面代码可以看出来,JDK1.8中新增了一个mappingCount()的API。这个API与size()不同的就是返回值是Long类型,这样就不受Integer.MAX_VALUE的大小限制了。
两个方法都同时调用了,sumCount()方法。对于每个table[i]都有一个CounterCell与之对应,上面方法做了求和之后就返回了。从而可以看出,size()和mappingCount()返回的都是一个估计值。(这一点与JDK1.7里面的实现不同,1.7里面使用了加锁的方式实现。这里面也可以看出JDK1.8牺牲了精度,来换取更高的效率。)
get方法未加锁
Segment予以保留,仅用来处理对象流的读写。
- 不采用segment而采用node,锁住node来实现减小锁粒度。
- 设计了MOVED状态 当resize的中过程中 线程2还在put数据,线程2会帮助resize。
- 使用3个CAS操作来确保node的一些操作的原子性,这种方式代替了锁。
- sizeCtl的不同值来代表不同含义,起到了控制的作用。(sizeCtl)代表数组的大小
sizeCtl用于table[]的初始化和扩容操作,不同值的代表状态如下:
- -1:table[]正在初始化。
- -N:表示有N-1个线程正在进行扩容操作。
具体
1.8的ConcurrentHashMap摒弃了1.7的Segment设计,而是在1.8HashMap的基础上实现了线程安全的版本,即也是采用的数组+链表+红黑树的形式。
数组可以扩容,链表可以转化为红黑树。
有一个重要的参数sizeCtl,代表数组的大小(但是还有其他权值及其含义,后面详细讲)
用户可以设置一个初始容量initialCapacity给ConcurrentHashMap,sizeCtl=大于(1.5倍initialCapacity+1)的最小的2的幂次。如initialCapacity=20,则sizeCtl=32,如initialCapacity=24,则sizeCtl=64。
初始化的时候,会按照sizeCtl的大小创建出对应大小的数组。
put过程
1、如果数组还未初始化,那么进行初始化,这里会进行初始化,这里会通过一个CAS操作将sizeCtl设置为-1,设置成功的,可以进行初始化操作;
2、根据key的hash值找到对应的桶,如果桶还不存在,那么通过一个CAS操作来设置桶的第一个元素,失败的继续执行下面的逻辑,即向桶中插入或更新;
3、如果找到的桶存在,但是桶的第一元素的hash值是-1,说明此时桶正在进行迁移操作,这一块会在下面的扩容中详细谈及;
4、如果找到的桶存在,那么要么是链表结构,要么是红黑树结构,此时需要获取该桶的锁,在锁定的情况下执行链表或红黑树的插入或更新。
如果桶中的第一个元素的hash值大于0,说明是链表结构,则对链表插入或者更新;
如果桶中的第一个元素是TreeBin,说明是红黑树结构,则按照红黑树的方式进行插入或者更新。
在锁的保护下,插入或者更新完毕后,如果是链表结构,需要判断链表中元素的数量是否超过8(默认),一旦超过,就需要考虑进行数组扩容,或者是链表转红黑树。
扩容过程
一旦链表中的元素个数超过8个,那么可以执行数组扩容或者是链表转为红黑树,这里依据的策略跟HashMap依据的策略是一致的。
当数组长度还未达到64个时,优先数组的扩容,否则选择链表转为红黑树。
扩容还是采用2倍扩容的方式。
第一个执行的线程会首先设置sizeCtl属性为一个负值,然后执行transfer(tab,null),其他晚进来的线程会检查当前扩容是否已经完成,没完成则帮助其进行扩容,完成了则直接退出。
该ConcurrentHashMap的扩容操作可以允许多个线程并发进行,那么就要处理好任务的分配工作。每个线程获取一部分桶的迁移任务,如果当前线程的任务完成,查看是否还有未迁移的桶,若有则继续领取任务执行,若没有则退出。在退出时需要检查是否还有其他线程在参与迁移工作,如果有则自己什么也不做直接退出,如果没有了则执行最后的收尾工作。
问题1:当前线程如何感知其他线程也在参与迁移工作?
靠sizeCtl的值,它初始值是一个负值=(rs<<RESIZE_STAMP_SHIFT)+2,每当一个线程参与进来执行迁移工作时,则该值进行CAS自增,该线程的任务执行完毕要退出时对该值进行CAS自减操作,所以当sizeCtl的值等于上述初值则说明了此时未有其他线程还在执行迁移工作,可以去执行收尾工作了。
问题2:任务按照何规则进行分片?
上述stride表示每个分片的大小,目前有最低要求16,即每个分片至少有16个桶。stride的计算依赖于CPU的核数,如果只有1个核,那么此时就不用分片了,即stride=n/其他情况就是(n>>>3)/NCPU。
问题3:如何记录已经分出去的任务?
ConcurrentHashMap含有一个属性trnasferIndex(初值为最后一个桶),表示从transferIndex开始到后面所有的桶的迁移任务已经被分配出去了。所以每次线程领取扩容任务,则需要对该属性进行CAS的减操作,即一般是transferIndex-stride。
问题4:每个线程如何处理分到的部分桶的迁移工作?
1、第一个获取到分片的线程会创建一个新的数组,容量是之前的2倍。
2、遍历自己所分到的桶:
(1)桶中元素不存在,则通过CAS操作设置桶中的第一个元素为ForwardingNode,其hash值为MOVED(-1),同时该元素含有新的数组引用;
(2)此时若其他线程进行put操作,发现第一个元素的hash值为-1则代表正在进行扩容操作(并且表明该桶已经完成扩容操作了,可以直接在新的数组中重新进行hash和插入操作),该线程就可以去参与进去,或者没有任务则不用参与,此时可以去直接操作新的数组了;
(3)桶中元素存在且hash值为-1,则说明该桶已经被处理了(本不会出现多个线程重叠的情况,这里主要是该线程在执行完所有的任务后再次进行检查,再次核对)
(4)桶中为链表或者红黑树结构,则需要获取桶锁,防止其他线程对该桶进行put操作,然后处理方式同HashMap的处理方式一样,对桶中元素分为2类,分别代表当前桶中和要迁移到新桶中的元素。设置完毕后代表桶迁移工作已经完成,旧数组中该桶可以设成ForwardingNode了。
get过程
1、根据key计算出hash值,找到对应的数组index;
2、如果该index位置无元素则直接返回null;
3、如果该元素有元素:
(1)如果第一个元素的hash值小于0,则该节点可能为ForwardingNode或者红黑树节点TreeBin;
(2)如果是ForwardingNode(表示当前正在扩容),使用新的数组来进行查找;
(3)如果是红黑树节点TreeBin,使用红黑树的查找方式来进行查找;
(4)如果第一个元素的hash值大于等于0,则为链表结构,依次遍历即可找到对应的元素。
unsafe类
Unsafe被JDK广泛应用于java.nio和并发包等实现中,这个不安全的类提供了一个观察HotSpot JVM内部结构并且可以对其进行修改,但是不建议在生产环境中使用。
objectFieldOffset:能够获取到指定实例变量的在对象内存中的偏移量
compareAndSwapInt:通过比较并替换的机制,修改指定偏移量内存的值
park:挂起某一线程
unpark:唤醒某一线程
Two Sum和Three Sum
Two Sum通过两个指针,没有什么疑问
Three Sum通过三个指针进行操作(需要先固定一个指针,再进行重复去除)
这里使用了三个指针。
先对数组进行排序。确定左侧固定的指针,然后移动右侧两个直至找到三个值和为0.如果当前三个指针的值小于0,则将中间的指针右移至下一个不同的值,如果小于0,则将最右侧指针左移至下一个不重复的值。一旦右侧和中间的指针重合,移动左侧指针至下一个不重复的值,并且初始化中间和右侧的指针
数据库索引之稠密索引和稀疏索引
稠密索引:
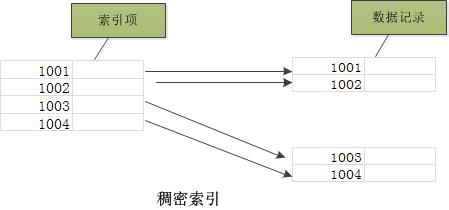
如果记录是排好序的,我们就可以在记录上建立稠密索引。如上图所示:在稠密索引中文件中的每个搜索码值都对应一个索引值。索引项包括索引值以及指向该搜索码值的第一条数据记录的指针。由于该索引符合聚集索引,因此记录根据相同的码值排序。
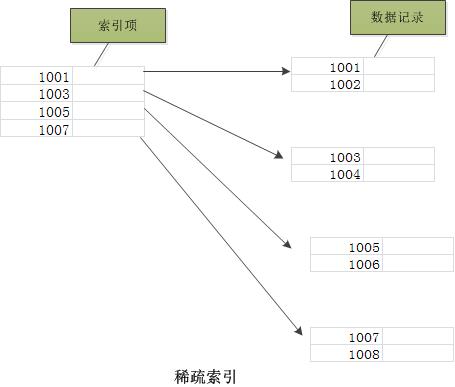
如上图所示:在稀疏索引中,只为索引码的某些值建立索引项。同理因为稀疏索引也是聚集索引。每一个索引项包括索引值以及指向该搜索码值的第一条数据记录的指针。
两者优缺点:
1.稠密索引比稀疏索引更快地定位一条记录。
2.稀疏索引所占空间小,并且插入和删除时所需的维护开销也小。
比如B+树非叶子节点就是稀疏索引,叶子节点就是稠密索引。
线程安全的单例模式为什么用volatile
1 memory=allocate();// 分配内存 相当于c的malloc
2 ctorInstanc(memory) //初始化对象
3 s=memory //设置s指向刚分配的地址
上面的代码在编译器运行时,可能会出现重排序 从1-2-3 排序为1-3-2
如此在多线程下就会出现问题
例如现在有2个线程A,B
线程A在执行第5行代码时,B线程进来,而此时A执行了 1和3,没有执行2,此时B线程判断s不为null 直接返回一个未初始化的对象,就会出现问题
编译型语言与解释型语言的区别及各自的优缺点
编译型语言在程序执行之前,有一个单独的编译过程,将程序翻译成机器语言就不用再进行翻译了。
解释型语言,是在运行的时候将程序翻译成机器语言,所以运行速度相对于编C/C++ 等都是编译型语言,而Java,C#等都是解释型语言。
什么是JMM?(即Java内存模型)
JMM(Java Memory Model):Java内存模型,JVM中规范通过JMM来屏蔽掉各种硬件之间和操作系统之间的访问差异,以实现Java程序在各个平台下都能达到一致的内存访问效果(平台无关性)。
垃圾回收器
Serial收集器
ParNew收集器
Parallel Scavenge收集器
CMS收集器
G1收集器
与GC相关的常用参数
- -Xmx: 设置堆内存的最大值。
- -Xms: 设置堆内存的初始值。
- -Xmn: 设置新生代的大小。
- -Xss: 设置栈的大小。、
G1垃圾收集器的特点
1、并行于并发:G1能充分利用CPU、多核环境下的硬件优势,使用多个CPU(CPU或者CPU核心)来缩短stop-The-World停顿时间。部分其他收集器原本需要停顿Java线程执行的GC动作,G1收集器仍然可以通过并发的方式让java程序继续执行。
2、分代收集:虽然G1可以不需要其他收集器配合就能独立管理整个GC堆,但是还是保留了分代的概念。它能够采用不同的方式去处理新创建的对象和已经存活了一段时间,熬过多次GC的旧对象以获取更好的收集效果。
3、空间整合:与CMS的“标记--清理”算法不同,G1从整体来看是基于“标记整理”算法实现的收集器;从局部上来看是基于“复制”算法实现的。
4、可预测的停顿:这是G1相对于CMS的另一个大优势,降低停顿时间是G1和CMS共同的关注点,但G1除了追求低停顿外,还能建立可预测的停顿时间模型,能让使用者明确指定在一个长度为M毫秒的时间片段内,
RPC(远程过程调用)
它是一种通过网络从远程计算机程序上请求服务,而不需要了解底层网络技术的协议。
1)服务消费方(client)调用以本地调用方式调用服务;
2)client stub接收到调用后负责将方法、参数等组装成能够进行网络传输的消息体(编码);
3)client stub找到服务地址,并将消息发送到服务端;
4)server stub收到消息后进行解码;
5)server stub根据解码结果调用本地的服务;
6)本地服务执行并将结果返回给server stub;
7)server stub将返回结果打包成消息(编码)并发送至消费方;
8)client stub接收到消息,并进行解码;
9)服务消费方得到最终结果。
RPC的目标就是要2~8这些步骤都封装起来,让用户对这些细节透明。
第二步,就是序列化与反序列化。
序列化:将数据结构或对象转换成二进制串的过程,也就是编码的过程。
反序列化:将在序列化过程中所生成的二进制串转换成数据结构或者对象的过程。
为什么需要序列化:转换为二进制串后便于网络传输。
序列化方案在选择的时候,主要看三点:
1)通用性,比如是否能支持Map等复杂的数据结构;
2)性能,包括时间复杂度和空间复杂度,由于RPC框架将会被公司几乎所有服务使用,如果序列化上能节约一点时间,对整个公司的收益都将非常可观,同理如果序列化上能节约一点内存,网络带宽也能省下不少;
3)可扩展性,对互联网公司而言,业务变化快,如果序列化协议具有良好的可扩展性,支持自动增加新的业务字段,删除老的字段,而不影响老的服务,这将大大提供系统的健壮性。
线上Java程序导致服务器CPU占用率过高的问题排除过程
1、故障现象
客服同事反馈平台系统运行缓慢,网页卡顿严重,多次重启系统后问题依然存在,使用top命令查看服务器情况,发现CPU占用率过高。
2、CPU占用过高问题定位
2.1、定位问题进程
使用top命令查看资源占用情况,发现pid为14063的进程占用了大量的CPU资源,CPU占用率高达776.1%,内存占用率也达到了29.8%
- 1
2.2、定位问题线程
使用ps -mp pid -o THREAD,tid,time命令查看该进程的线程情况,发现该进程的多个线程占用率很高
从输出信息可以看出,14065~14072之间的线程CPU占用率都很高
挑选TID为14065的线程,查看该线程的堆栈情况,先将线程id转为16进制,使用printf “%x\n” tid命令进行转换
再使用jstack命令打印线程堆栈信息,命令格式:jstack pid |grep tid -A 30
-
[ylp
@ylp-web-
01 ~]$ jstack
14063 |grep
36f1 -A
30
-
"GC task thread#0 (ParallelGC)" prio=
10 tid=
0x00007fa35001e800 nid=
0x36f1 runnable
-
"GC task thread#1 (ParallelGC)" prio=
10 tid=
0x00007fa350020800 nid=
0x36f2 runnable
-
"GC task thread#2 (ParallelGC)" prio=
10 tid=
0x00007fa350022800 nid=
0x36f3 runnable
-
"GC task thread#3 (ParallelGC)" prio=
10 tid=
0x00007fa350024000 nid=
0x36f4 runnable
-
"GC task thread#4 (ParallelGC)" prio=
10 tid=
0x00007fa350026000 nid=
0x36f5 runnable
-
"GC task thread#5 (ParallelGC)" prio=
10 tid=
0x00007fa350028000 nid=
0x36f6 runnable
-
"GC task thread#6 (ParallelGC)" prio=
10 tid=
0x00007fa350029800 nid=
0x36f7 runnable
-
"GC task thread#7 (ParallelGC)" prio=
10 tid=
0x00007fa35002b800 nid=
0x36f8 runnable
-
"VM Periodic Task Thread" prio=
10 tid=
0x00007fa3500a8800 nid=
0x3700 waiting on condition
-
-
JNI global references:
392
- 1
3、内存问题定位
3.1、使用jstat -gcutil命令查看进程的内存情况
- 1
从输出信息可以看出,Eden区内存占用100%,Old区内存占用99.99%,Full GC的次数高达220次,并且频繁Full GC,Full GC的持续时间也特别长,平均每次Full GC耗时6.8秒(1505.439/220)。根据这些信息,基本可以确定是程序代码上出现了问题,可能存在不合理创建对象的地方
3.2、分析堆栈
使用jstack命令查看进程的堆栈情况
把jstack.out文件从服务器拿到本地后,用编辑器查找带有项目目录并且线程状态是RUNABLE的相关信息,从图中可以看出ActivityUtil.java类的447行正在使用HashMap.put()方法
这段代码会从数据库中获取配置,并根据数据库中remain的值进行循环,在循环中会一直对HashMap进行put操作。查询数据库中的配置,发现remain的数量巨大
synchronized锁优化
前文解释了synchronized的实现和运用,了解monitor的作用,但是由于monitor监视器锁的操作是基于操作系统的底层Mutex Lock实现的,对所要加锁线程加上互斥锁,但是加锁时间相比其他指令就长很多了,因此将这种基于互斥锁的加锁机制成为重量级锁。
而在JDK1.6之后,对synchronized优化,根据不同情形出现了偏向锁、轻量锁、对象锁,自旋锁(或自适应自旋锁)等,因此,现在的synchronized可以说是一个几种锁过程的封装。
JMM8个原子操作
- Lock: 作用于主内存MainMemory,锁住变量所在的MainMemory部分,不允许其他线程访问,排他访问。
- unlock:与lock对应,解锁。
- read:作用于主内存上,把主内存上的某个数据传输到workingMemory上,以便后续的load指令使用。
- load: 作用于workingMemory上,把从主内存传输的数据移动到workingMemory对应的变量副本上。
- use :作用于workingMemroy,它把workingMemroy中的变量副本的值传递给java执行引擎。jvm每当执行到需要使用某个变量时都会执行这个操作。
- assign: 作用于workingMemory,把执行引擎中的某个值赋给workingMemory中的某个变量副本。JMV每当遇到一个赋值的字节码指令时,都会执行这个操作。
- store: 作用于workingMemory,把workingMemory中的某个变量值传输到主内存中,以便后续执行write操作。
-
write:作用于主内存,把store操作传输过来的数据放入主内存中写入。
锁优化
高效 并发是从JDK1.5到JDK1.6的一个重要改进,目前的优化技术有 适应性自旋、锁消除、锁粗化、轻量级锁和偏向锁 等 这些技术是为了在线程之间更高效地共享数据,以解决竞争问题,从而提高程序的执行效率。
自旋锁与自适应锁:
如果物理机器上有一个以上的处理器,能让两个或两个 以上的线程同时并行执行,就可以让后面请求锁的那个线程稍微等待一下,但不放弃处理器的执行时间,看看持有线程的锁 是否很快就会释放锁,为了让线程等待,只需要让线程执行一个忙循环即自旋,这就是自旋锁。
如果所被占用的时间很短,自旋等待的效果就会非常的好,反之,自旋的线程只会白白得消耗处理器资源,而不会做任何有用的工作,反而带来性能上的浪费,因此,自选锁等待的时间必须要有一定的限制,如果自旋锁超过了限定的次数仍然没有成功获得锁,就应当使用传统的方式挂起锁了,默认次数是10。
锁消除:
锁消除是Java虚拟机在JIT编译时,通过对运行上下文的扫描,去除不可能存在共享资源竞争的锁,通过锁消除,可以节省毫无意义的请求锁时间。
锁粗化:
如果一系列的连续操作都是对同一对象反复加锁和解锁,甚至加锁操作时出现在循环体中,那即是没有线程竞争,频繁地进行互斥同步操作也会导致不必要的性能损耗,如果虚拟机探测到有这样一串零碎的操作都对同一个对象加锁,将会把加锁同步范围扩展到整个操作序列的外部,就 扩展到第一个append()操作之前直至最后一个append()操作之后,这样只需要加锁一次就好。
轻量级锁:
轻量级锁是JDK1,6中加入的新型锁机制,它是在没有多线程竞争的前提下,减少传统的重量级锁使用操作系统互斥量产生的性能消耗。
偏向锁:
在JVM1.6中引入了偏向锁,偏向锁主要解决无竞争下的锁性能问题,首先我们看下无竞争下锁存在什么问题:
现在几乎所有的锁都是可重入的,也即已经获得锁的线程可以多次锁住/解锁监视对象,按照之前的HotSpot设计,每次加锁/解锁都会涉及到一些CAS操作(比如对等待队列的CAS 操作), CAS操作会延迟本地调用,因此偏向锁的想法是一旦线程第一次获得了监视对象,之后让监视对象“偏向”这个线程,之后的多次调用则可以避免CAS操作,说白了就是置个 变量,如果发现为true则无需再走各种加锁/解锁流程。
Spring boot 热加载
在pom文件中添加依赖(optional-->true表示覆盖父级项目中的引用):
<dependency>
<groupId> org.springframework.boot </ groupId>
<artifactId> spring-boot-devtools </ artifactId>
<optional> true </ optional>
</ dependency>
Java双亲委派模型破坏
双亲委派模型的第一次“被破坏”其实发生在双亲委派模型出现之前--即JDK1.2发布之前。在loadClass()方法的逻辑里,如果父类加载器加载失败,则会调用自己的findClass()方法来完成加载,这样就可以保证新写出来的类加载器是符合双亲委派模型的。
双亲委派模型的第二次“被破坏”是引入了一个不太优雅的设计:线程上下文件类加载器(Thread Context ClassLoader)。这个类加载器可以通过java.lang.Thread类的setContextClassLoader()方法进行设置,如果创建线程时还未设置,它将会从父线程中继承一个;如果在应用程序的全局范围内都没有设置过,那么这个类加载器默认就是应用程序类加载器。了有线程上下文类加载器,JNDI服务使用这个线程上下文类加载器去加载所需要的SPI代码,也就是父类加载器请求子类加载器去完成类加载动作,这种行为实际上就是打通了双亲委派模型的层次结构来逆向使用类加载器
双亲委派模型的第三次“被破坏”是由于用户对程序的动态性的追求导致的,例如OSGi的出现。在OSGi环境下,类加载器不再是双亲委派模型中的树状结构,而是进一步发展为网状结构。
类加载器中findClass与loadClass的区别?
findClass()用于写类加载逻辑、loadClass()方法的逻辑里如果父类加载器加载失败则会调用自己的findClass()方法完成加载,保证了双亲委派规则。
1、如果不想打破双亲委派模型,那么只需要重写findClass方法即可
2、如果想打破双亲委派模型,那么就重写整个loadClass方法
通过TCP协议建立连接的两方,如果一方突然发生故障(比如断电)断开了连接
-
TCP协议会自动检测连接是否断开,经过一段时间后另外一段会收到TCP连接断开的通知- 1
-
如果设置了TCP_KEEPALIVE,那么对端能够马上收到断开的信息- 1
-
可以自己实现心跳检测的方法来确定对方是不是已经断开连接- 1
TCP中KEEPALIVE机制是默认不打开的,需要通过setsockopt将SOL_SOCKET.SO_KEEPALIVE设置为1则是打开,打开后会定时向连接对方发送ACK包(linux下默认是7200s 即2小时发生一次发送一次握手信息),如果在发送ACK包后对方不回应才能检测道对方的断开信息
注解Spring多数据源配置
第一步:创建一个DynamicDataSource的类,继承AbstractRoutingDataSource并重写determineCurrentLookupKey方法
第二步:创建DynamicDataSourceHolder用于持有当前线程中使用的数据源标识
第三步:配置多个数据源和第一步里创建的DynamicDataSource的bean
到这里已经可以使用多数据源了,在操作数据库之前只要DynamicDataSourceHolder.setDataSource("dataSource2")
@DataSource使用这个注解可以直接配置想要的数据源
@DataSource("dataSource3")
- 1
- 2
创建线程和创建进程的开销
对操作系统来说,创建一个线程的代价是十分昂贵的, 需要给它
分配内存、
列入调度,
同时在线程切换的时候还要执行内存换页,
CPU 的缓存被
清空,切换回来的时候还要重新从内存中读取信息,破坏了数据的局部性。
线程也有自己的资源,比如栈,私有数据等等。说他使用而不拥有资源指的是使用的是进程的打开文件句柄,进程的全局数据,进程的地址空间等等,这些都属于进程,而不属于线程,进程内个线程共享。
进程切换比线程切换开销大是因为进程切换时要切页表,而且往往伴随着页调度,因为进程的数据段代码段要换出去,以便把将要执行的进程的内容换进来。本来进程的内容就是线程的超集。而且线程只需要保存线程的上下文(相关寄存器状态和栈的信息)就好了,动作很小
类是在什么时候加载到内存中的
加载Loading, 验证Verification, 准备Preparation, 解析Resolution, 初始化Initialization, 使用Using和卸载Unloading.
除解析阶段外,其他几个阶段的顺序都是固定的。解析阶段在某些情况下可以在初始化阶段之后再开始,这是为了支持JAVA语言的运行时绑定(动态绑定/晚期绑定)
虚拟机规范严格规定了有且只有四种情况必须对类进行初始化(加载,验证,准备自动在之前开始)
- 遇到new,getstatic,putstatic,invokestatic这4条字节码指令时,如果类没有进行初始化,则先初始化。这4个字节码常见的出现场景是:使用new关键字实例化对象的时候,读取或设置静态字段(被final修饰,已在编译期把结果放入常量池的静态字段除外)的时候,以及调用一个类的静态方法的时候。
- 反射调用时
- 初始化一个类时,如果其父类还未初始化,则先出发父类初始化。
- 当虚拟机启动时,用户需要指定一个要执行的主类,虚拟机会先初始化这个主类
这4种情况称为对类的主动引用,其他情况称为被动引用。
类加载的过程
加载
在加载阶段,虚拟机需要完成以下三件事情:
- 通过一个类的全限定名来获取定义此类的二进制字节流。
- 将这个字节流所代表的静态存储结构转化为方法区的运行时数据结构
- 在JAVA堆中生成一个代表着各类的java.lang.Class对象,作为方法区这些数据的访问入口
验证
验证是连接阶段的第一步,这一阶段的目的是为了确保Class文件的字节流中包含的信息符合当前虚拟机的要求,并却不会危害虚拟机自身的安全。
一些在编译层面上可以控制的事情(比如超边界访问数组,跨类型进行类型对象转换存在时,编译器是拒绝工作的)可以通过直接修改class文件的方式进行破解,这就是验证阶段存在的原因。
按照虚拟机规范,如果验证到输入的字节流不符合Class文件的存储格式,就抛出一个java.lang.VerifyError异常或其子类异常。
大致分成4个阶段的验证过程:文件格式验证、元数据验证、字节码验证和符号引用验证
准备
准备阶段是正式为类变量分配内存并设置类变量初始值的阶段,这些内存都将在方法区中进行分配。这个时候内存分配的仅包括类变量(static变量),不包括实例变量,实例变量将会在对象实例化时随着对象一起分配在java堆中。其次是这里所说的初始值“通常情况下”是数据类型的零值(随后在初始化阶段生成定义的初值)。如果该变量被final修饰,将在编译时生成ConstantValue,这样在准备阶段将直接设置成该初值。
解析
解析阶段是虚拟机将常量池内的符号引用替换为直接引用的过程。
符号引用在CLASS文件中它以CONSTANT_CLASS_INFO, CONSTANT_FIELDREF_INTO, CONSTANT_METHODREF_INFO等类型的常量出现
符号引用:(Symbolic References)符号引用以一组符号来描述所引用的目标,可以是任何形式的字面量,引用的目标并不一定已经加载到内存中,与虚拟机内存布局无关。
直接引用:(Direct References)直接引用可以是直接指向目标的指针,相对偏移量,或是一个能间接定位到目标的句柄。与虚拟机内存布局相关。
初始化
是类加载过程的最后一步,初始化阶段才真正开始执行类中定义的JAVA程序代码
准备阶段中,变量已经赋过一次系统要求的初始值,而在初始化阶段,则是根据程序员通过程序制定的计划来赋值
或者说,初始化阶段是执行类构造器<clinit>()方法的过程
多线程中static和volatile的区别
1. volatile是告诉编译器,每次取这个变量的值都需要从主存中取,而不是用自己线程工作内存中的缓存.
2. static 是说这个变量,在主存中所有此类的实例用的是同一份,各个线程创建时需要从主存同一个位置拷贝到自己工作内存中去(而不是拷贝此类不同实例中的这个变量的值),也就是说只能保证线程创建时,变量的值是相同来源的,运行时还是使用各自工作内存中的值,依然会有不同步的问题.
何时使用聚集索引或非聚集索引?(继续查找)
涉及频繁的update的列最好用非聚集索引,因为频繁的update会频繁的改变索引结构
- 使用聚集索引的查询效率要比非聚集索引的效率要高,但是如果需要频繁去改变聚集索引的值,写入性能并不高,因为需要移动对应数据的物理位置。
- 非聚集索引在查询的时候可以的话就避免二次查询,这样性能会大幅提升。
- 不是所有的表都适合建立索引,只有数据量大表才适合建立索引,且建立在选择性高的列上面性能会更好。
关系型数据库和Nosql数据库的对比
关系型数据库
<1>关系数据库的特点是:
- 数据关系模型基于关系模型,结构化存储,完整性约束。
- 基于二维表及其之间的联系,需要连接、并、交、差、除等数据操作。
- 采用结构化的查询语言(SQL)做数据读写。
- 操作需要数据的一致性,需要事务甚至是强一致性。
<2>优点:
- 保持数据的一致性(事务处理)
- 可以进行join等复杂查询。
- 通用化,技术成熟。
<3>缺点:
- 数据读写必须经过sql解析,大量数据、高并发下读写性能不足。
- 对数据做读写,或修改数据结构时需要加锁,影响并发操作。
- 无法适应非结构化存储。
- 扩展困难。
- 昂贵、复杂。
NoSQL数据库
<1>NoSQL数据库的特点是:
- 非结构化的存储。
- 基于多维关系模型。
- 具有特有的使用场景。
<2>优点:
- 高并发,大数据下读写能力较强。
- 基本支持分布式,易于扩展,可伸缩。
- 简单,弱结构化存储。
<3>缺点:
- join等复杂操作能力较弱。
- 事务支持较弱。
- 通用性差。
- 无完整约束复杂业务场景支持较差。
算法题:一个很长的字符串,找到该字符串的最长没有重复字符的子串
用hashmap记录字符以及下标,当出现重复字符时更新初始位置并结算长度,若长度大于之前记录的长度,则更新最长
长度并记录字串
Java 注解的作用与使用以及底层原理
- 1.生成文档。这是最常见的,也是java 最早提供的注解。常用的有@see @param @return 等;
- 2.跟踪代码依赖性,实现替代配置文件功能。比较常见的是spring 2.5 开始的基于注解配置。作用就是减少配置。现在的框架基本都使用了这种配置来减少配置文件的数量;
- 3.在编译时进行格式检查。如@Override放在方法前,如果你这个方法并不是覆盖了超类方法,则编译时就能检查出;
注解的底层也是使用反射实现的,我们可以自定义一个注解来体会下。注解和接口有点类似,不过申明注解类需要加上@interface,注解类里面,只支持基本类型、String及枚举类型,里面所有属性被定义成方法,并允许提供默认值。
- 要用好注解,必须熟悉java 的反射机制,从上面的例子可以看出,注解的解析完全依赖于反射。
- 不要滥用注解。平常我们编程过程很少接触和使用注解,只有做设计,且不想让设计有过多的配置时
四个元注解分别是:@Target,@Retention,@Documented,@Inherited ,再次强调下元注解是java API提供,是专门用来定义注解的注解
- 1
红黑树和B树应用场景有何不同?
二者都是有序数据结构,可用作数据容器。红黑树多用在内部排序,即全放在内存中的,微软STL的map和set的内部实现就是红黑树。B树多用在内存里放不下,大部分数据存储在外存上时。因为B树层数少,因此可以确保每次操作,读取磁盘的次数尽可能的少。
在数据较小,可以完全放到内存中时,红黑树的时间复杂度比B树低。反之,数据量较大,外存中占主要部分时,B树因其读磁盘次数少,而具有更快的速度。
map 就是采用红黑树存储的,红黑树(RB Tree)是平衡二叉树,其优点就是树到叶子节点深度一致,查找的效率也就一样,为logN.在实行查找,插入,删除的效率都一致
B树的定义为“在计算机科学中,B树(B-tree)是一种树状数据结构,它能够存储数据、对其进行排序并允许以O(log n)的时间复杂度运行进行查找、顺序读取、插入和删除的数据结构
1. 二叉查找树 (Binary Search Tree)
BST效率总结 :
查找最好时间复杂度O(logN),最坏时间复杂度O(N)。
插入删除操作算法简单,时间复杂度与查找差不多。
2. 平衡二叉查找树 ( Balanced Binary Search Tree )
二叉查找树在最差情况下竟然和顺序查找效率相当,这是无法仍受的。事实也证明,当存储数据足够大的时候,树的结构对某些关键字的查找效率影响很大。当然,造成这种情况的主要原因就是BST不够平衡(左右子树高度差太大)。既然如此,那么我们就需要通过一定的算法,将不平衡树改变成平衡树。因此,AVL树就诞生了。
AVL效率总结:
查找的时间复杂度维持在O(logN),不会出现最差情况
AVL树在执行每个插入操作时最多需要1次旋转,其时间复杂度在O(logN)左右。
AVL树在执行删除时代价稍大,执行每个删除操作的时间复杂度需要O(2logN)。
3. 红黑树 (Red-Black Tree )
查找 效率最好情况下时间复杂度为O(logN),但在最坏情况下比AVL要差一些,但也远远好于BST。
插入和删除操作改变树的平衡性的概率要远远小于AVL(RBT不是高度平衡的)。因此需要的旋转操作的可能性要小,而且一旦需要旋转,插入一个结点最多只需要旋转2次,删除最多只需要旋转3次(小于AVL的删除操作所需要的旋转次数)。虽然变色操作的时间复杂度在O(logN),但是实际上,这种操作由于简单所需要的代价很小。
4. B~树/B+树 (B-Tree )
B-Tree效率总结:
由于考虑磁盘储存结构,B树的查找、删除、插入的代价都远远要小于任何二叉结构树(读写磁盘次数的降低)。
动态查找树结构的对比:
(1) 平衡二叉树和红黑树 [AVL PK RBT]
AVL 和RBT 都是二叉查找树的优化。其性能要远远好于二叉查找树。他们之间都有自己的优势,其应用上也有不同。
结构对比: AVL的结构高度平衡,RBT的结构基本平衡。平衡度AVL > RBT.
查找对比: AVL 查找时间复杂度最好,最坏情况都是O(logN)。RBT 查找时间复杂度最好为O(logN),最坏情况下比AVL略差。
插入删除对比:
1. AVL的插入和删除结点很容易造成树结构的不平衡,而RBT的平衡度要求较低。因此在大量数据插入的情况下,RBT需要通过旋转变色操作来重新达到平衡的频度要小于AVL。
2. 如果需要平衡处理时,RBT比AVL多一种变色操作,而且变色的时间复杂度在O(logN)数量级上。但是由于操作简单,所以在实践中这种变色仍然是非常快速的。
3. 当插入一个结点都引起了树的不平衡,AVL和RBT都最多需要2次旋转操作。但删除一个结点引起不平衡后,AVL最多需要logN 次旋转操作,而RBT最多只需要3次。因此两者插入一个结点的代价差不多,但删除一个结点的代价RBT要低一些。
4. AVL和RBT的插入删除代价主要还是消耗在查找待操作的结点上。因此时间复杂度基本上都是与O(logN) 成正比的。
总体评价:大量数据实践证明,RBT的总体统计性能要好于平衡二叉树。
(2) B-树和B+树 [ B-Tree PK B+Tree]
B+树是B-树的一种变体,在磁盘查找结构中,B+树更适合文件系统的磁盘存储结构。
结构对比:
B-树是平衡多路查找树,所有结点中都包含了待查关键字的有效信息(比如文件磁盘指针)。每个结点若有n个关键字,则有n+1个指向其他结点的指针。
B+树相比B-树的特点:
1. 数据只出现在叶子结点,B-树每个结点都包含了数据;
2. 叶子结点之间用指针连接;
3. B+树的高度一般是3;
查找对比:
1. 在相同数量的待查数据下,B+树查找过程中需要调用的磁盘IO操作要少于普通B-树。由于B+树所在的磁盘存储背景下,因此B+树的查找性能要好于B-树。
2. B+树的查找效率更加稳定,因为所有叶子结点都处于同一层中,而且查找所有关键字都必须走完从根结点到叶子结点的全部历程。因此同一颗B+树中,任何关键字的查找比较次数都是一样的。而B树就不一定了,可能查找到某一个非终结点就结束了。
插入删除对比: B+树与B-树在插入删除操作中的效率是差不多的。
总体评价:在应用背景下,特别是文件结构存储中。B+树的应用要更多,其效率也要比B-树好。
TreeSet()原理
1、TreeSet()是使用二叉树(红黑树)的原理对新add()的对象按照指定的顺序排序(升序、降序),每增加一个对象都会进行排序,将对象插入的二叉树指定的位置。
2、Integer和String对象都可以进行默认的TreeSet排序,而自定义类的对象是不可以的,自己定义的类必须实现Comparable接口,并且覆写相应的compareTo()函数,才可以正常使用。
3、在覆写compare()函数时,要返回相应的值才能使TreeSet按照一定的规则来排序(升序,this.对象 < 指定对象的条件下返回-1)
线程池的shutdown()和shutdowNow()
shutDown()
当线程池调用该方法时,线程池的状态则立刻变成SHUTDOWN状态。此时,则不能再往线程池中添加任何任务,否则将会抛出RejectedExecutionException异常。但是,此时线程池不会立刻退出,直到添加到线程池中的任务都已经处理完成,才会退出。
shutdownNow()
根据JDK文档描述,大致意思是:执行该方法,线程池的状态立刻变成STOP状态,并试图停止所有正在执行的线程,不再处理还在池队列中等待的任务,当然,它会返回那些未执行的任务。
它试图终止线程的方法是通过调用Thread.interrupt()方法来实现的,但是大家知道,这种方法的作用有限,如果线程中没有sleep 、wait、Condition、定时锁等应用, interrupt()方法是无法中断当前的线程的。所以,ShutdownNow()并不代表线程池就一定立即就能退出,它可能必须要等待所有正在执行的任务都执行完成了才能退出。
java线程池---编写自己的线程池
-
public
interface ThreadPool<Job extends Runnable>{
-
//执行一个任务(Job),这个Job必须实现Runnable
-
void execute(Job job);
-
//关闭线程池
-
void shutdown();
-
//增加工作者线程,即用来执行任务的线程
-
void addWorkers(int num);
-
//减少工作者线程
-
void removeWorker(int num);
-
//获取正在等待执行的任务数量
-
void getJobSize();
-
}
- 1
-
public
class DefaultThreadPool<Job extends Runnable> implements ThreadPool<Job>{
-
-
// 线程池维护工作者线程的最大数量
-
private
static
final
int MAX_WORKER_NUMBERS =
10;
-
// 线程池维护工作者线程的默认值
-
private
static
final
int DEFAULT_WORKER_NUMBERS =
5;
-
// 线程池维护工作者线程的最小数量
-
private
static
final
int MIN_WORKER_NUMBERS =
1;
-
// 维护一个工作列表,里面加入客户端发起的工作
-
private
final LinkedList<Job> jobs =
new LinkedList<Job>();
-
// 工作者线程的列表
-
private
final List<Worker> workers = Collections.synchronizedList(
new ArrayList<Worker>());
-
// 工作者线程的数量
-
private
int workerNum;
-
// 每个工作者线程编号生成
-
private AtomicLong threadNum =
new AtomicLong();
-
-
//生成线程池
-
public DefaultThreadPool() {
-
this.workerNum = DEFAULT_WORKER_NUMBERS;
-
initializeWorkers(
this.workerNum);
-
}
-
-
public DefaultThreadPool(int num) {
-
if (num > MAX_WORKER_NUMBERS) {
-
this.workerNum =DEFAULT_WORKER_NUMBERS;
-
}
else {
-
this.workerNum = num;
-
}
-
initializeWorkers(
this.workerNum);
-
}
-
//初始化每个工作者线程
-
private void initializeWorkers(int num) {
-
for (
int i =
0; i < num; i++) {
-
Worker worker =
new Worker();
-
//添加到工作者线程的列表
-
workers.add(worker);
-
//启动工作者线程
-
Thread thread =
new Thread(worker);
-
thread.start();
-
}
-
}
-
-
public void execute(Job job) {
-
if (job !=
null) {
-
//根据线程的"等待/通知机制"这里必须对jobs加锁
-
synchronized (jobs) {
-
jobs.addLast(job);
-
jobs.notify();
-
- 1

