
- 1pthread_create 所需要的时间_pthread_create耗时
- 2Linux系统Docker部署StackEdit Markdown并实现公网访问本地编辑器
- 3springboot 多环境配置,请您过目_springprofile name="dev
- 4使用 GitHub Actions 自动化部署 全栈个人博客项目_actions/checkout@v3
- 5高并发系统设计的15个锦囊
- 6南邮数据库系统实验(1)_南邮数据库实验
- 7Nuxt3打包部署到nginx服务器_服务器部署nuxt3nginx
- 8景联文科技GPT教育题库:AI教育大模型的强大数据引擎
- 9YUM源服务器的内网部署_内网yum源
- 10failure: repodata/repomd.xml 和 Loaded plugins: fastestmirror 问题解决_loaded plugins: fastestmirror, langpacks file cont
数据库课设社区卫生服务管理系统_深度解析腾讯自研数据库CynosDB备份与回档...
赞
踩
点击上方蓝字每天学习数据库
作者介绍:林锦,腾讯云数据库团队高级工程师,曾任云计算初创公司系统架构师,从事分布式系统研发7年,2017年加入腾讯云,从事NewSQL研发工作,目前主要负责CynosDB for PostgreSQL开发工作。
写在前面:本文主要讲解 CynosDB for PostgreSQL的备份和回档机制及流程,包括数据库实例备份、备份策略、备份流程、内部备份调度、定期快照生成、回档新实例、故障异常、优缺点等。
概述
当前信息时代,数据已成为企业最重要的资产之一,数据丢失引起的后果非常严重,甚至关系到企业的生死存亡,而数据丢失产生缘由包括:
1.物理错误:自然灾害(谷歌数据中心雷击导致0.000001%数据永久丢失),硬件故障(如腾讯云 磁盘静默错误),运营商网络故障等。
2.逻辑错误:人工出错,软件BUG,病毒等。
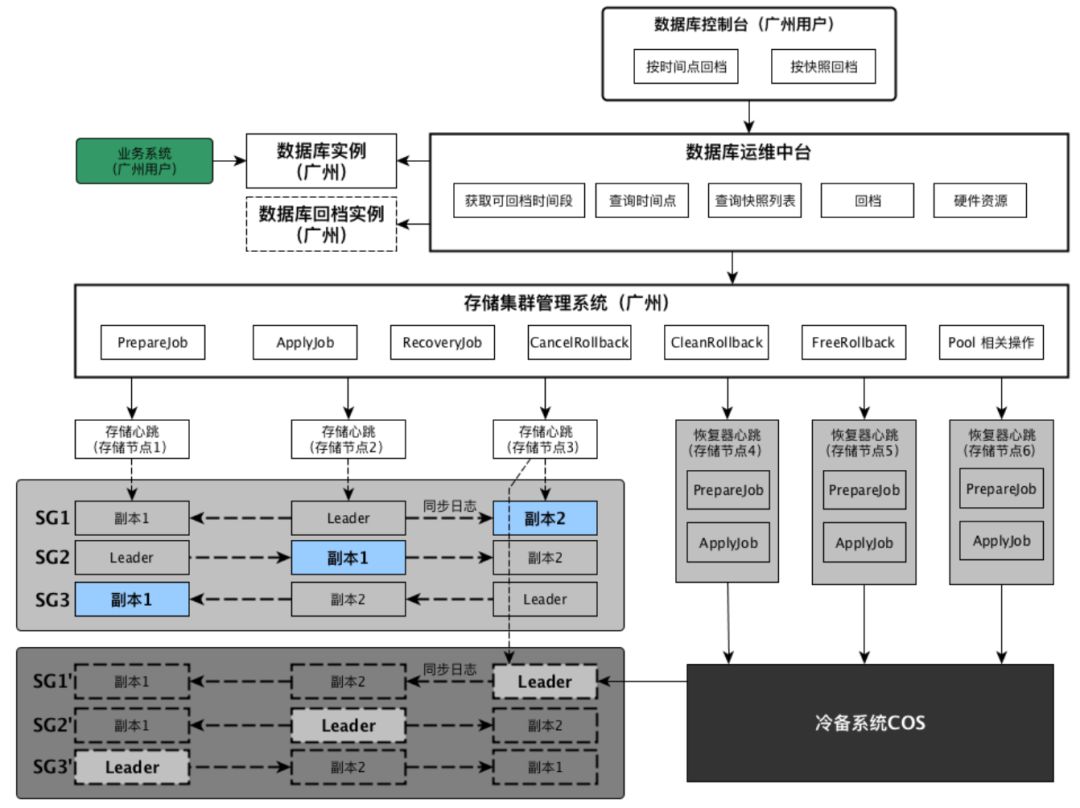
解决数据丢失的方式大多采用冗余或副本,而副本有两种状态:当前状态和历史状态(快照或镜像),如何实现和使用这两种状态的副本,传统数据库系统都提供相应的工具或方案,CynosDB是新一代高性能高可用的企业级分布式云数据库,采用共享存储架构,作为腾讯云NewSQL数据库家族成员之一,包括数据库实例,数据库控制台,数据库运维中台,集群管理系统,分布式存储与恢复系统,冷备系统等, 各个部分相互之间的联系如下图所示:
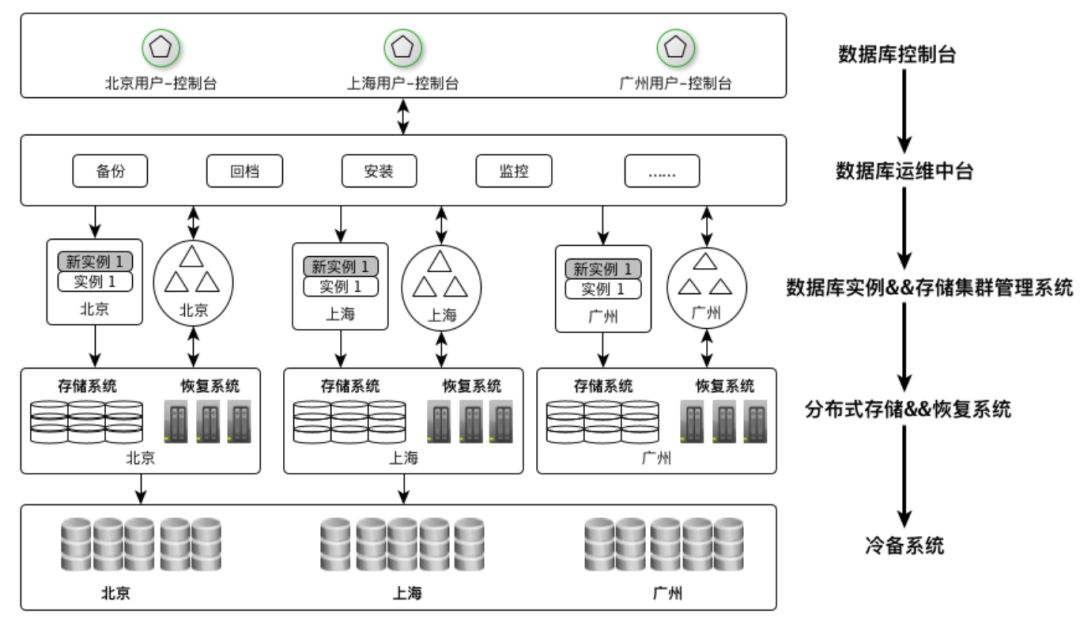
CynosDB for PostgreSQL 系统层次结构
说明:
数据库控制台:用户可以通过 数据库控制台 设置数据库实例的备份策略(包括保留备份时长,备份频率等),查询快照列表,按快照回档和按时刻回档等操作。
数据库运维中台:统一管理各个数据库实例安装,配置,监控,备份和回档等操作,负责接收各个数据库控制台发送备份和回档操作请求,然后转发给相应区域(北京,上海,广州等)的存储集群管理系统进行备份和回档调度。
数据库实例:将定期备份数据库实例本地资源(配置信息和 fsm文件),以及定期清理过期的备份信息。
存储集群管理系统:其负责主要包括如下三个方面:
1)负责启动每个数据库实例上对应Pool下每个SegmentGroup的日志流服务,并根据Segment运行状态(存储系统通过心跳上报)来检测日志流服务的健康状况,当发生异常时将在SegmentGroup内切换到另一个Follower 进行日志流备份。
2)负责根据数据库实例设置的备份策略定期生成快照和清理快照。
3)根据回档请求在线上重构新的数据库实例。分布式存储系统:负责每个SegmentGroup的日志流异步备份,当日志流发生异常时,将上报给 存储集群管理系统 由其统一调度。
分布式恢复系统:根据 存储集群管理系统的调度任务,定期生成和清理每个数据库实例的快照,与分布式存储系统是独立部署,不会影响在线业务,通过定期生成快照,可加速数据库实例回档。
冷备系统(对象存储COS系统):负责存储各个数据库实例的配置,快照和增量日志。
CynosDB 在系统规划之初 就把 数据安全 作为第一设计要素:采用 多副本 + 持续日志流备份 + 定期生成快照 + 按时刻和快照回档 等方式来完成备份和回档:
多副本:每个数据库实例对应一个Pool,每个Pool由1个或多个Segment Group组成,每个Segment Group由三个Segment组成(其中有一个是Leader,两个为Follower),这Segment上的数据就是副本(当前状态),多副本一致性采用 CynosRaft 库实现的。
持续日志流备份:在每个SegmentGroup 上选择一个合适的Follower进行日志流 异步 持续备份(不阻塞Leader处理相关请求)。
定期生成快照:在 分布式恢复系统 中定期构建每个SegmentGroup的快照(历史状态)并保存到冷备系统。
回档(按时刻 && 快照):选择 时刻 最近的快照 + 快照时间到指定时刻的增量日志 在 分布式恢复系统 上产生新快照 或 直接选择 快照 ,然后在线上系统根据快照重构新数据库实例。
相关概念和名词解释:
恢复点(RPO): 表示CynosDB 数据可恢复到的时间点(单位秒),即当前时间点到用户备份策略设置的保留时长的任意时间点。
恢复时间(RTO): 表示CynosDB 接收到回档请求后,回档到指定恢复点的时间长度,回档过程不中断原有业务。
备份保留时长(Retention):表示CynosDB 保留备份数据的有效时间,默认7天。
备份类型:CynosDB 包括全备份(数据快照备份) 和 增量备份(数据日志备份)。
备份流程
分3个阶段:启动备份,设置备份策略,定期快照。
启动备份:存储集群管理系统 根据该Pool的规模(SegmentGroup数),逐个打开SegmentGroup的备份功能,一个SegmentGroup备份启动如下:
选择备份的Segment: 在一个SegmentGroup的多个segment中(除leader外)选择一个Segment.
发送启动日志流命令给 存储系统:通过 该Segment所在的存储节点 上报的 “心跳”,通过 响应心跳来 下发 “启动日志流备份” 命令。存储节点根据命令 将启动 日志流服务,如果是首次启动则生成一个初始快照,上传到COS(初始快照大小为0,只是标记快照开始,后续通过备份服务以此为基础 产生新的快照),分别通过 GRPC 向集群管理系统 报告 “生成快照” 成功 和 “启动日志” 成功。如启动失败则报告失败,集群管理系统将选择另外的副本进行启动备份功能。
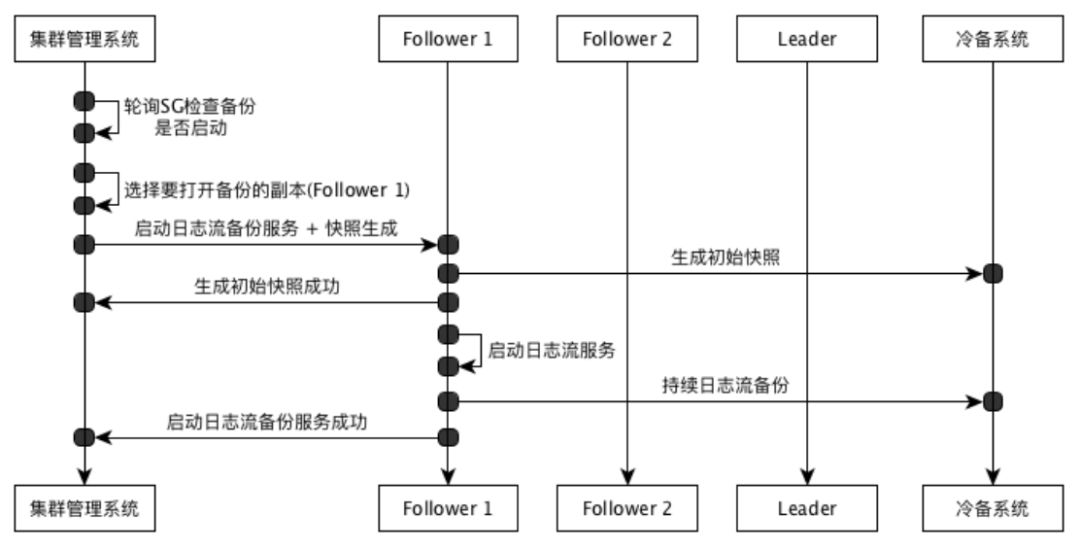
启动日志流流程
设置备份: 用户通过 ”数据库控制台” 的 “自动备份设置” 面板 设置 某个数据库实例的备份策略 给 数据库运维中台。数据库运维中台 根据数据库实例所在的区域,把该备份策略 转发给该区域所在的 “存储集群管理系统”,存储集群管理系统 接收该请求,保存该备份策略到对应的pool,返回设置成功。
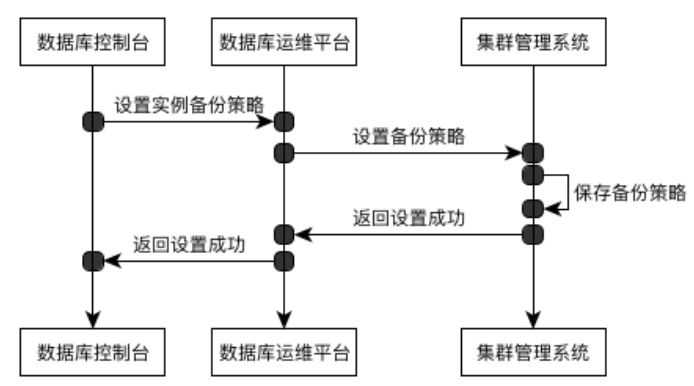
设置备份策略流程
定期快照:存储集群管理系统 内部调度将按照该策略自动产生快照,并在备份保留期后进行释放,已节省用户存储空间,而恢复系统中由1个或多个的恢复器组成,恢复器设计成 无状态 的,可根据当前快照任务的规模进行扩展,生成快照的的调度任务包括:
查询任务(PrepareJob): 主要检查 当前时间点 是否 能生成快照,检测该实例的所有SegmentGroup是否可Apply到一致的VDL。
应用日志任务(SGApplyJob): 某个SegmentGroup的 日志流 应用到 某个时刻的快照上,应用到一致的VDL后,产生新快照,并保存到冷备系统,过程如下:
按时间点下发SGApplyJob:PrepareJob 的结果中每个SegmentGroup都对应一个恢复器,构建SGApplyJob响应,通过 “恢复器心跳” 下发 apply 任务。
执行SGApplyJob: 恢复器 接收到 ApplyJob请求后,根据请求参数从COS系统获取PrepareJob结果文件中偏移位置的信息,解析出快照和日志备份在cos上的路径信息,再次从cos中下载快照和日志文件,然后在本地进行日志Apply操作,应用到快照上,但Apply完成后 向存储集群管理系统 报告 SGApplyJob 完成,报告信息包括本次Apply后的VDL。
检查PoolApplyJob: 将检查 每个SGApplyJob结果,计算所有SGApply的VDL是否一致,如不一致,则在 PrepareJob 返回的 [可回档开始的VDL, 可回档结束的VDL] 的区间内 找出本次返回所有Apply VDL中最大的一个VDL,然后再次下发SGApplyJob 给 恢复器进行Apply, 为 按vdl下发ApplyJob。
按VDL下发SGApplyJob:当检查ApplyJob 结果时,发现并非所有的SegmentGroup都Apply到 一致的VDL, 再次下发没有补齐VDL的 ApplyJob 给 恢复器,恢复器 执行ApplyJob 应用到指定的VDL。
完成ApplyJob: 当检查完所有的SGApplyJob的结果后,VDL都一致, 更新内部状态信息。
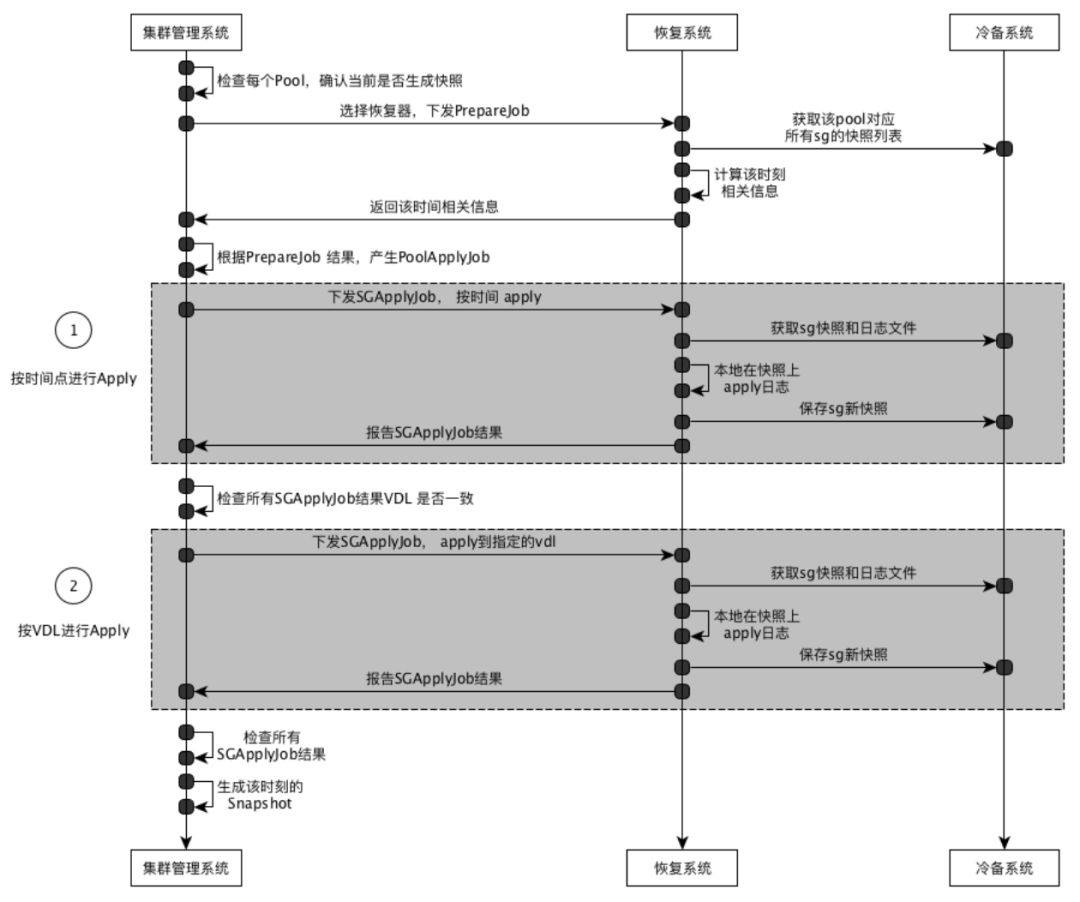
定期生成快照流程
说明:在合并快照时,先按时间点进行Apply, 而数据库一致性是通过VDL保证的,由于时间点的粒度是秒,存在同一秒内的VDL有不同的情况,所以需要在按时间点Apply后 检查一下该时刻的所有SegmentGroup的快照是否处于一致的VDL,如不一致,需计算出一致的VDL,然后再次下发 按VDL进行Apply,已使该实例的所有SegmentGroup都达到一致的状态点。
回档流程
回档流程
按快照回档: 从已生成的快照进行回档,回档过程是在线上系统重构新数据库实例来完成,一个快照可多次回档,超过保留期将被释放。
用户在数据库控制台 选择快照列表界面时,数据库运维中台 将向 该数据库实例对应区域的 集群管理系统 发起 获取该实例的快照列表请求,集群管理系统接收到请求后,查询该实例的快照列表返回给 运维中台,然后运维中台 返回给 数据库控制台 展示给用户。
用户选择 一个快照,回档机型等相关信息,发给 运维中台 进行回档,运维中台 将向 集群管理系统 发起 回档作业RollbackJob 请求,集群管理系统接收到请求后,识别回档类型为 按快照回档,则选择相应的快照,并在该实例对应Pool下产生一个恢复作业RecoveryJob,返回 运维中台 请求已接收,而 集群管理系统 对 RecoveryJob进行调度:
根据回档请求中的new pool id 创建一个新的pool,并从 源pool 复制相关的属性信息。
根据PoolApplyJob 中的每个SGApplyJob 创建对应的新的SegmentGroup。
创建新的SegmentGroup:
1)分配一个Segment,作为leader,集群管理系统 选择一个存储节点,下发分配segment请求,存储节点分配成功后,报告申请成功。
2)启动SegmentGroup, 从 SGApplyJob 中获取 该SegmentGroup apply后的快照路径 作为启动参数之一,通过 存储节点心跳 下发启动SegmentGroup 给 存储节点。
3)存储节点 收到 启动SegmentGroup 命令,检查是否需要下载cos 快照,如需要则下载到本地,然后启动Segment Group,然后向 集群管理系统 报告启动成功。
4)添加副本过程:分配segment (通过 store 心跳 下发分配segment) + 加入到 Segment Group (通过 Segment Group 心跳 加入新分配的Segment)
检查每个SGApplyJob 对应的SegmentGroup是否创建成功,如成功 则更新 RecoveryJob 状态。
集群管理系统 调度定期检查 RecoveryJob状态,如完成,则更新 RollbackJob的状态。
运维中台 定期查询该 该RollbackJob的状态,如恢复成功,则 准备 相应机型 构造新数据库实例。
新数据库实例 先格式化,格式化过程将 从 冷备系统下载 fsm文件,并从 存储系统中读取之前备份的配置信息。
完成格式化后,启动 新数据库实例,完成回档。
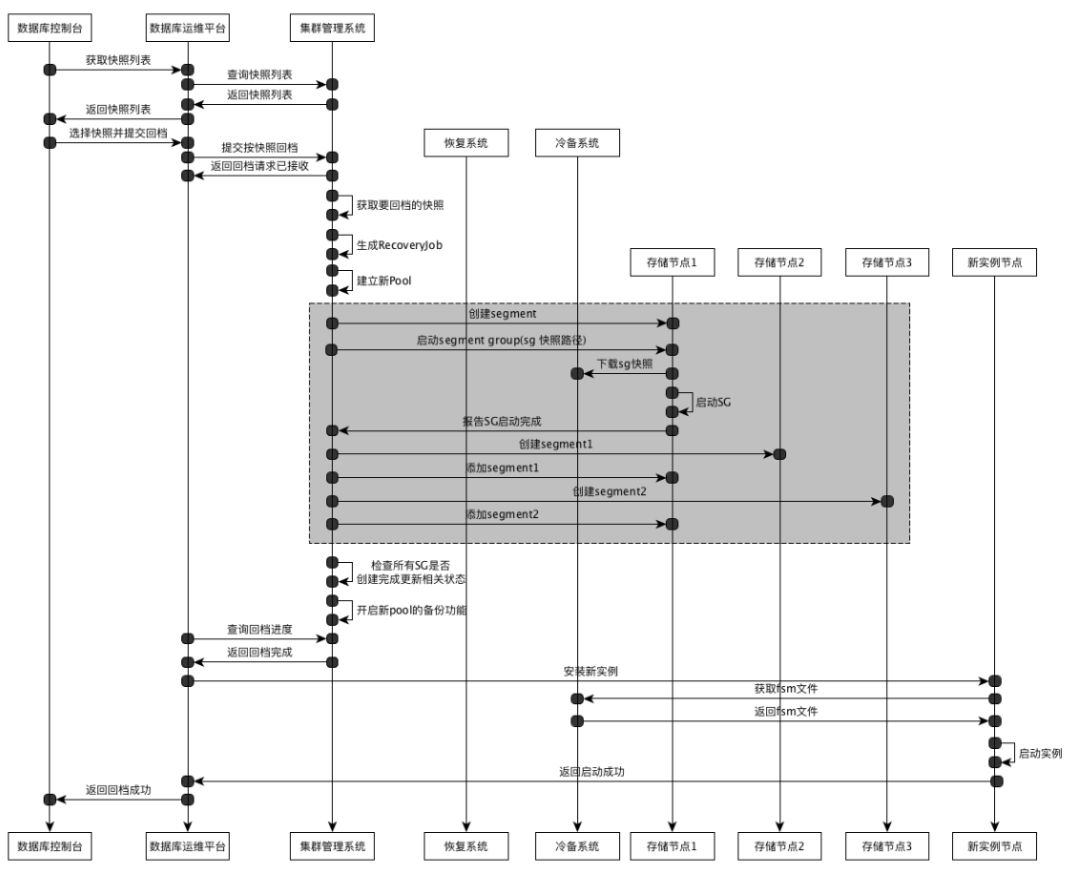
按快照回档流程
按时间点回档:从备份保留期内选择一个时间点进行回档,回档过程将产生该时间点的快照,下次直接从快照恢复,提高回档效率,其内部分两个阶段:一个快照生成阶段,一个是恢复阶段(恢复可参考 快照回档流程)。
用户在数据库控制台 选择 按时间点回档 界面时,数据库运维中台 将向 集群管理系统 发起 查询该数据库实例对应pool可回档时间段, 集群管理系统返回该Pool可回档时间段,数据库运维中台 向 数据库控制台 发送可回档时间段。
用户在 可回档时间段内 选择一个可回档时间点,提交给 运维中台,运维中台 将向 该数据库实例对应区域的 集群管理系统 发起 PrepareJob 请求,集群管理系统在该实例对应Pool下产生一个PrepareJob 进行调度,返回 运维中台 正在查询中。
运维中台 定期查询该 PrepareJob的状态,如成功,则向控制台反馈成功,如失败,则向控制台反馈 建议可回档时间点。
用户在数据库控制台 选择 将要回档的机型等信息,并提交 回档请求 给 运维中台,运维中台 将向 集群管理系统 发起 RollbackJob 请求,集群管理系统接收到请求后,识别 回档类型,为 按时间点 回档,则产生一个 ApplyJob 根据之前的PrepareJob的结果 进行 日志Apply. ApplyJob 成功后,将识别该ApplyJob的类型,如为 时间点回档,则产生一个 RecoveryJob 作业进行调度,当完成RecoveryJob后,更新RollbackJob 状态。
运维中台 定期查询该RollbackJob的状态,如恢复成功,则 准备 相应机型 构造新数据库实例,新数据库实例 先格式化,格式化过程将 从 冷备系统下载 fsm文件,并从 源实例对应的存储系统中读取之前备份的配置信息,完成后启动 数据库实例。
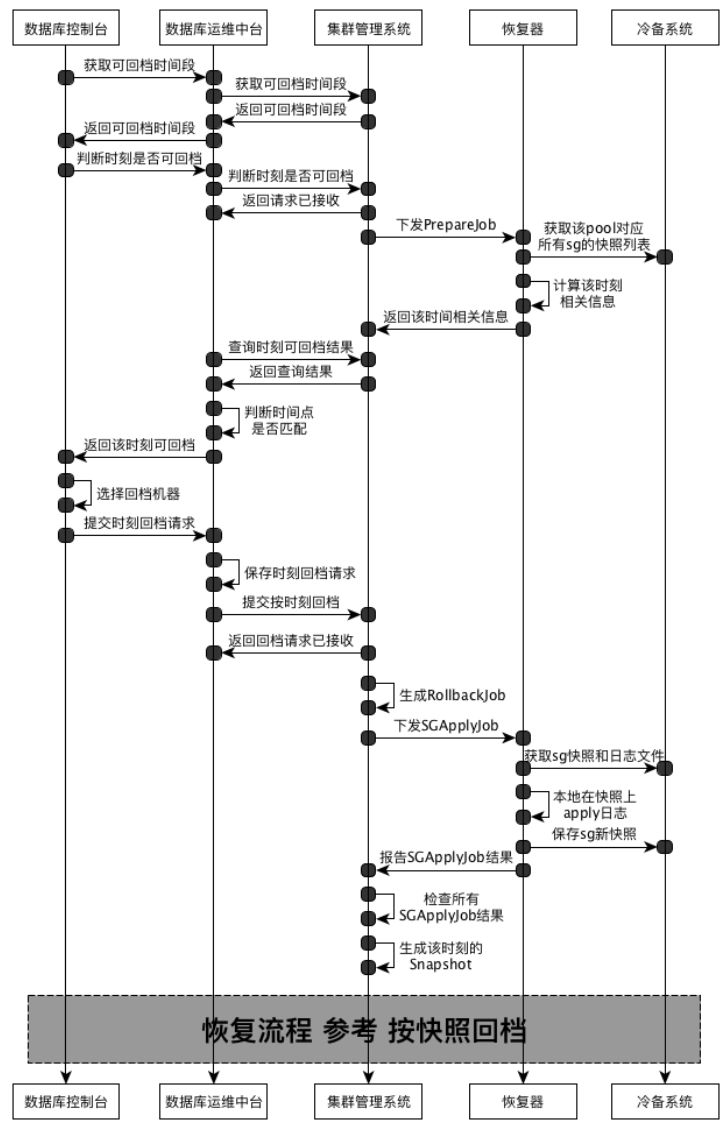
按时间点回档流程
故障处理
SegmentGroup 副本离线
由于某种原因,一个SegmentGroup 中的Leader 发现无法与 某个 副本通信,则通过 SegmentGroup的心跳信息 向 集群管理系统 报告 某个 副本已经 down了,集群管理系统 将 增加一个副本,移除故障的副本,如果该故障副本已启动备份功能,则检查该副本所在的存储节点 是否存在 心跳 信息,如存在 则下发 停止备份功能(快照和日志流备份),然后重新选择一个新的副本来启动 备份功能。SegmentGroup 切主
当一个SegmentGroup 发生切主时,通过SegmentGroup的心跳信息,判断新的leader是否启动了备份功能,如已启动备份功能,则下发停止该备份功能,然后重新选择一个副本来启动备份。存储节点离线
集群管理系统 巡检 某个Pool的所有SegmentGroup 过程,如果存在某个SegmentGroup中的某个Segment所在的存储节点已离线(通过检查该存储节点的心跳时间已超出 配置的超时时间)则将 增加 一个 新副本,移除该故障副本,如该故障副本已启动备份功能,则重新 选择一个新副本来启动备份功能。存储节点升级
集群管理系统 巡检 某个Pool的所有SegmentGroup 过程,如果存在某个SegmentGroup中的某个Segment所在的存储节点需升级,将 增加 一个 新副本,移除该故障副本,如该故障副本已启动备份功能,则 下发停止 备份功能,然后重新选择一个新副本来启动备份功能。快照服务故障
当某个快照服务发生故障,则通过 GRPC 主动向 集群管理系统 报告快照 故障,集群管理系统接收到请求后,检查日志流服务是否启动,如启动则下发 停止日志流备份功能,停止成功后,重新选择一个新的副本来启动该SG的备份功能。日志流服务故障
当某个日志流服务发生故障(如日志流备份磁盘满),则通过 GRPC 主动向 集群管理系统 报告日志流 故障,集群管理系统接收到请求后,检查快照服务是否启动,如启动则下发 停止快照服务,停止成功后,则重新选择一个新的副本来启动该SG的备份功能。
优缺点
优点
快照备份不影响在线业务。
数据库可回档备份保留期内任意时刻,单位秒。
缺点
带宽浪费:生成快照时需从冷备系统下载旧快照和日志文件,在本地进行应用,生成新快照,然后上传到冷备系统。
回档时间长:由于需从冷备系统下载快照到在线系统进行实例重构过程。
注意点
节点升级 比 节点离线 多一个 下发停止 备份功能的步骤。而 副本离线则需根据 副本所在的存储节点是否可以通信 进行判断是否要 下发 停止 备份功能。
由于故障不可避免,当故障发生时,将存在该期间的日志流备份丢失,将导致无法回档到故障时间范围内的某个时间点。
往期推荐
《丁奇:索引存储顺序和order by不一致怎么办?》

免费试用
包括云数据库MySQL在内的40+款热门云产品,实名认证的企业用户可免费试用!1000M内存50G数据盘的MySQL可免费体验30天,点击左下角“阅读原文”立即领取~
好文和朋友一起看!


