
- 1使用 YOLOv5 进行图像分割的实操案例
- 2本地部署 闻达:一个LLM调用平台_闻达 github
- 3手把手带你在vue中封装axios(含携带token)_vue3 ts axios 携带token
- 4操作系统-Operating-System第二章:启动、中断、异常和系统调用_中断和异常是操作系统第几章
- 5C#发送http请求并封装json结果为对象_http请求json接口c#
- 6ASP.NET Core 3.1系列(18)——EFCore中执行原生SQL语句_ef core 执行sql
- 7解决vue项目打包后index.html标签属性没有双引号的问题_removeattributequotes
- 8手机如何连接VMware虚拟机中的服务器_vm虚拟机局域网手机玩
- 9【你也能从零基础学会网站开发】Web建站之javascript入门篇 认识JavaScript中的Cookie
- 10GUROBI之数学启发式算法Matheuristics_gurobi 设置 heuristics=0.5
TTS | emotional-vits情绪语音合成的实现_emotion vits =环境配置
赞
踩
本文主要介绍了情绪语音合成项目训练自己的数据集的实现过程~
innnky/emotional-vits: 无需情感标注的情感可控语音合成模型,基于VITS (github.com)
目录
0.环境设置
因为我用的是之前设置vits的虚拟环境,这里可能也有写不全的的地方~
- git clone https://github.com/innnky/emotional-vits
- cd emotional-vits
- pip install -r requirements.txt
-
- # MAS 对印发音和文本:Cython-version Monotonoic Alignment Search
- cd monotonic_align
- python setup.py build_ext --inplace
-
-
1.数据预处理
- # 处理数据集
- python preprocess.py --text_index 2 --filelists /jf-training-home/src/emotional-vits/filelists/bea_train.txt /jf-training-home/src/emotional-vits/filelists/val.txt --text_cleaners korean_cleaners
生成文本处理文件

对数据进行16000重采样:
- import os
- import librosa
- import tqdm
- import soundfile as sf
- import time
-
- if __name__ == '__main__':
-
- audioExt = 'WAV'
-
- input_sample = 22050
-
- output_sample = 16000
-
-
- audioDirectory = ['/jf-training-home/src/emotional-vits/dataset/bae_before']
-
-
- outputDirectory = ['/jf-training-home/src/emotional-vits/dataset/bae']
-
- start_time=time.time()
-
- for i, dire in enumerate(audioDirectory):
-
- clean_speech_paths = librosa.util.find_files(
- directory=dire,
- ext=audioExt,
- recurse=True,
- )
-
- for file in tqdm.tqdm(clean_speech_paths, desc='No.{} dataset resampling'.format(i)):
-
- fileName = os.path.basename(file)
-
- y, sr = librosa.load(file, sr=input_sample)
-
- y_16k = librosa.resample(y, orig_sr=sr, target_sr=output_sample)
-
- outputFileName = os.path.join(outputDirectory[i], fileName)
-
- sf.write(outputFileName, y_16k, output_sample)
- end_time=time.time()
- runTime=end_time - start_time
- print("Run Time: {} sec ~".format(runTime))
2..提取情绪
*注意:如果数据集是英文,可以默认提取情绪信息,如果是中文,需要更换预训练权重
!!
修改emotion_extract.py文件的第94行,改为自己的数据集路径
原代码rootpath = "dataset/nene"
改为自己的rootpath = "dataset/bae"
python emotion_extract.py --filelists src/emotional-vits/filelists/bae_train.txt src/emotional-vits/filelists/bae_val.txt如果出现问题参考【PS2】,运行时如图


文件内会生成
3.训练
- #python train_ms.py -c configs/nene.json -m nene --ckptD /path/to/D_xxxx.pth --ckptG /path/to/G_xxxx.pth
-
- python train_ms.py -c configs/bae.json -m emo_bae
如果出现错误,参考【PS3】
开始训练
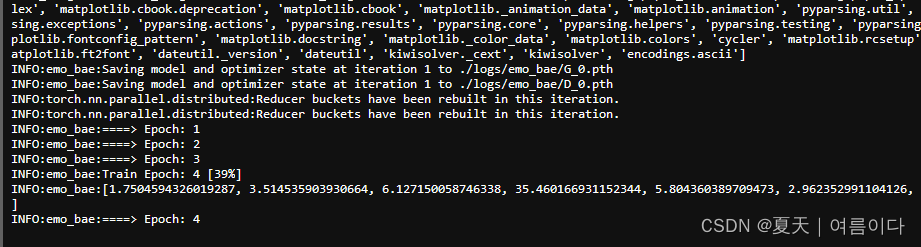
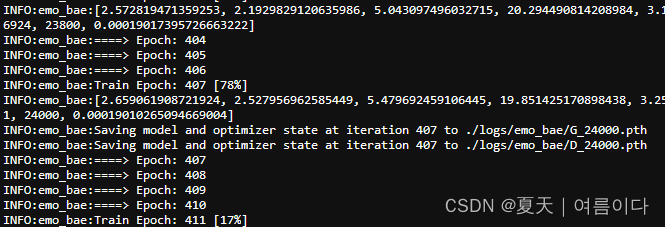
一共3000条数据,8个小时epoch410->step24000
4.推理
推理使用inference.ipynb,修改配置文件,以及权重文件路径
推理结果并不是完整的句子,可能是因为ser预训练加载的是英文的,而训练的数据集并非英文。
过程中遇到的问题与解决【PS】
【PS1】RuntimeError: Given groups=1, weight of size [512, 1, 10], expected input[1, 45140, 1] to have 1 channels, but got 45140 channels instead

解决方案
- pip install transformers==4.25.1
-
- #或者在emotion_extract.py文件77行增加一个维度
- y = y.unsqueeze(0)
然后就解决啦~
【PS2】安装setuptools出错
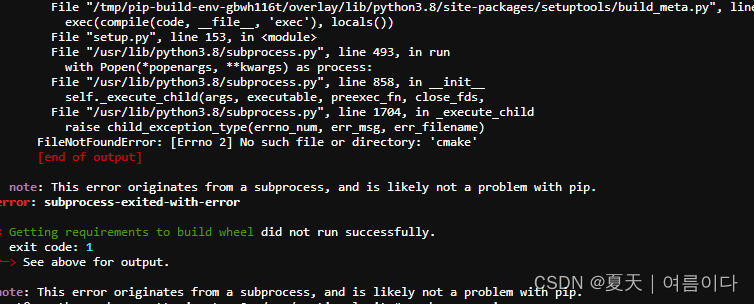
删掉使用日语的库
【PS3】RuntimeError: stft requires the return_complex parameter be given for real inputs, and will further require that return_complex=True in a future PyTorch release.
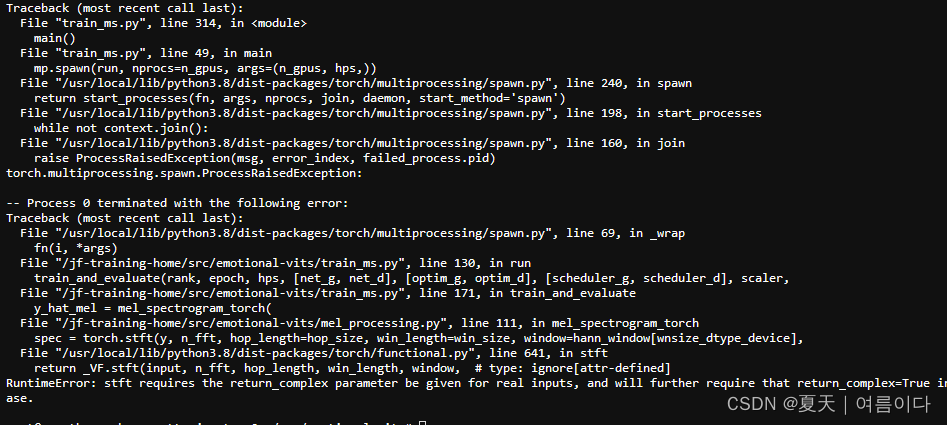
打开emotional-vits/mel_processing.py, 111行

添加了 return_complex=True
然后出现RuntimeError: mat1 and mat2 shapes cannot be multiplied (80x513 and 32x513)
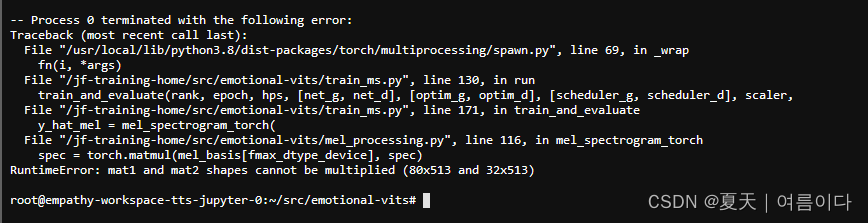
解决办法
pytorch包太新了导致的修改emotional-vits/mel_processing.py,
66行,67行【增加return_complex=False】
104行,105行【onesided=True后增加,return_complex=False】

其他
Q&A
怎么根据Ubuntu进程判断运行的程序?
第一步查询GPU进程
fuser使用
- 安装: sudo apt-get update
- sudo apt-get install psmisc
- 查看显卡占用的进程:
- fuser -v /dev/nvidia*
- 杀掉进程 kill -9 PID

后面都是python,说明都是python命令
通过名称查看进程
ps -ef | grep python 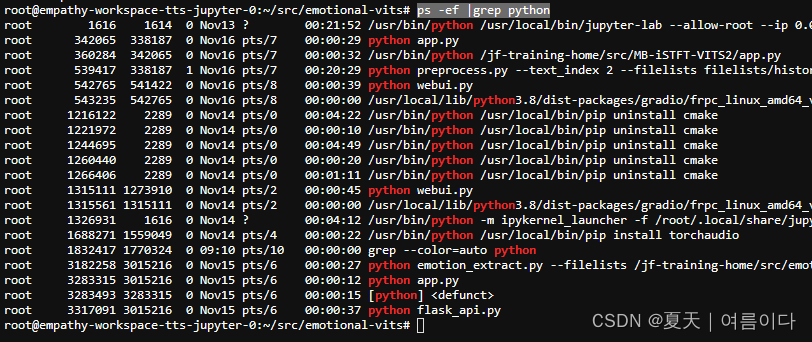
对比删除自己不用的进程就可以啦~

