
- 1【学习笔记--短文--对比学习1】:深度学习中的正、负采样 & 正、负样例 & 对比学习初涉_对比学习正样本
- 2Transformers快速入门 Quick tour_from transformers import autotokenizer, automodel
- 3基于springboot的毕业设计系统的设计与实现_基于springboot的毕设
- 4C++算法:二分查找(Binary Search)_c++ binary_search
- 5python调javajar包_python调用java的jar包报错127
- 623种PHP开发工具PHP IDE集合
- 7文本情感分析综述
- 8opencv3的sift特征提取方法(1)_opencv3 sift 参数调整
- 9自动编码器 - Autoencoder
- 10通过Jmeter准备压测数据-mysql示例
2020华为云大数据挑战赛之热身赛(top1思路)_华为云大数据挑战赛热身赛_交通流量预测赛题分析
赞
踩
2020华为云大数据挑战赛之热身赛
本文记录一下我在2020华为云大数据挑战赛之热身赛的比赛过程、经验以及遇到的问题。
1 赛题解读
2020华为云大数据挑战赛的热身赛比赛链接:https://competition.huaweicloud.com/information/1000037843/ranking
1.1 赛题说明
本次比赛任务是利用历史数据并结合地图信息,预测深圳市五和张衡交叉路口未来一周周一(2019年2月11日)和周四(2019年2月14日)两天的5:00-21:00通过wuhe_zhangheng路口4个方向的车流量总和。
要求模型输出格式如下:
{“data”:{“resp_data”:{“wuhe_zhangheng”:[1,4,5,6,4…]}}}
从5:00开始每5min的预测数据,第一个数据为5:00-5:05的流量值,最后一个数据为20:55-21:00。两天的数据按时间先后放在一起,总共有384个数据。
小提示:如果不考虑天气、周边活动、节假日等因素,预测结果可能不准确哦。
1.2 数据说明
本次比赛提供4周(2019.1.12 – 2019.2.8)深圳龙岗区坂田街道交通流量历史数据。
车流数据格式如下:

其中,time为上述格式时间字符串,cross为路口名,direction为车流起始方向,leftFlow是左转车流,straightFlow是直行车流。
说明:
(1) 十字路口包含四个方向车流数据,此处未全部列出。
(2) 路口名称分别为:五和路、张衡路、稼先路、隆平路、冲之大道。可以通过但不限于百度地图等地图软件获取地图路网信息。
(3) 因为右转车流不受信号灯控制,因此未做统计。
1.3 评分标准
第一部分(分类问题)
分类问题评价标准:预测的评价还是通过每一个5min预测车流和真实通过车流对比,看看趋势是否一致(比如10月19日的5:00到5:05的真实车流是4,10月20日的5:00到5:05的真实车流为5,那么只要车流预测值大于4,就得100分,最后得分为所有得分求加权平均(权重为该时间段所在小时的车流量占16小时总车流的比重))。
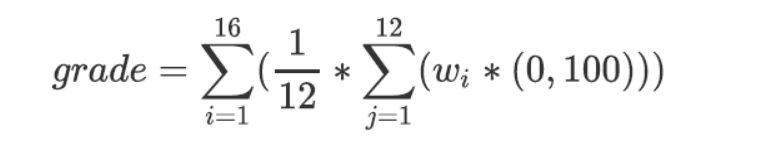
第二部分(回归问题)
回归问题评价标准:预测的评价还是通过每一个5min 预测车流和真实通过车流通过grade公式计算最后得分,加权细则与第一部分相同:

其中wi为权重,xj为真实车流数据,xj拔为预测车流数据,ε为e-9。
最后将两部分分数做归一化处理,第一部分占比40%,第二部分占比60%。
1.4 题目分析
该题目是要通过2019年1月中下旬和2月上旬五个路口的车流量数据来预测其中一个路口在2019年2月11日和2月14日的车流量。其评分标准过于复杂,第一部分的分数描述也不是很清楚,所以我尝试按照这个标准写了一个评分函数,但线上效果和线下效果完全不一致,最终选择了放弃,直接使用mse作为线下的分数验证。
仔细分析一下分数标准的两部分,可以发现回归问题的分数主要依靠每一个区间的误差来判别的,也就是说,就算最终提交的答案所有区间都为同一个数,比如都为50,最终得分应该也有30多。也就是说稍微训练一下的模型,不需要加什么特征,第二部分保底的30分加上第一部分的分数,应该也会有超过50分的线上成绩。
2 数据分析
题目理解清楚后,开始对题目给的数据进行分析。因为要预测的是五和张衡路口,所以先只是提取了这一个路口的车流信息。
2.1 日期问题
第一个想到的就是日期问题,给的数据中包含了过年,情人节这些特殊日子,并且还有一些时间段数据是缺失的。所以先画一个整体的折线图来分析一下。

可以看到,数据集并不平衡,有一大部分数据走势相同,并且也集中,但是也可以看到,2月份以后的数据,开始出现大幅滑坡,说明过年对于车流量影响是非常大的。并且,越靠近过年,整体水平都越来越低。对于我们要预测的2月11日,刚好又是过年后上班第一天,可以猜测车流量并不会太大,而是有可能和过年的前几天数据差不多。
2.2 每一天的走势
随意挑选一天的车流量来看看。

可以发现,早上的早高峰出现在7点以后,到9点开始慢慢下降,然后保持一个水平波动,到下午5点开始晚高峰,晚上也处于一个水平波动,而最后8点30以后又会有一个小高峰。
可以猜想一下,大多数时间的整体走势应该都是一样的,除了周末这种特殊日子。而我们要预测的是星期一和星期四,与周末关系不大,要如何处理可以去尝试一下。
2.3 每一周的车流量变化
对于每一周的每一天,可以画图看一下变化情况。
星期一

星期二

星期三

星期四

星期五

依然是上面的规律,邻近过年,车流量整体水平也就越低,并且每一周的同一天,大体走势是比较类似的,所以可以考虑使用这一个特征来预测走势,也就是把评分标准的第一部分拿高一点,但是这个特征对于车流量的具体值的预测效果却不好,所以我在前期上分的时候,使用了这个特征,后面再提升的时候,选择不再使用这个特征。
3 预测模型
3.1 初始版本(baseline)
这个赛题给了一个baseline,提交上去的分数是35.6483。baseline里面对于每一路口的每一个时间段的各个方向的车流量选择了取一个平均,这其实是不对的,因为我们要求的车流量的总和,所以应该是把各个方向的车流量进行求和,只需要改动这一点,分数就能从35上升到40多。
3.2 我的模型v1.0(score:65.4439)
我第一次上分使用的是xgboost,具体推理代码参照华为云的文档来写就可以了。目标函数的选择我尝试了很多,最终 count::poisson的效果最好,也就是泊松回归。
具体做法:
- 将所有数据中,五和张衡路口的数据都读进来。
- 对每一个时间段,五和张衡路口各个方向的车流量进行求和
- 将有缺失值的天数去掉,将5:00到21:00以内的数据保留,其他的扔掉
- 提取日期特征,将每一个日期都用星期几来表示,比如星期一就用0,星期日就用6.
- 提取节假日特征,如果是节假日为1,不是就为0
- 将5:00到21:00做一个归一化,化成0到1的一个小数
- 对要预测的日期也提取日期特征和节假日特征,并把时间区间归一化。注意情人节并不是节假日,所以应该还是为0,我最开始的时候标为了1,效果非常不好。
score:65.4439
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
我的第一个模型就只是做了这样一个简单的处理,最终线上成绩68.4134
3.3 我的模型v1.1(score:68.5792)
在上一个模型的基础上,我提取了新的特征,晚上是否加班,这个特征是从每一天的数据走势来看的,比如这一天

晚上的车流量整体处于下降趋势,我就判定为不加班
又比如

这一天晚上车流量明显增多了,我就判定为加班。
所以,新的步骤为:
- 将所有数据中,五和张衡路口的数据都读进来。
- 对每一个时间段,五和张衡路口各个方向的车流量进行求和
- 将有缺失值的天数去掉,将5:00到21:00以内的数据保留,其他的扔掉
- 提取日期特征,将每一个日期都用星期几来表示,比如星期一就用0,星期日就用6.
- 提取节假日特征,如果是节假日为1,不是就为0
- 将5:00到21:00做一个归一化,化成0到1的一个小数
- (新增)提取是否加班的特征
- 对要预测的日期也提取日期特征和节假日特征,并把时间区间归一化。注意情人节并不是节假日,所以应该还是为0,我最开始的时候标为了1,效果非常不好。
- (新增)对预测的日期提取是否加班的特征,自我感觉,2月11日第一天上班应该加班的少,2月14日不管加不加班,情人节晚上车流量肯定会增多,所以当成加班处理
score:68.5792
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
最终成绩也是提升了三个点。
3.4 我的模型v1.3(score:69.8996)
对于上一个模型,持续改了很多地方都没有长进,所以又重新审视了一下数据,发现节假日期间车流量明显与我们要预测的日期车流量不会一致,所以根本没有参考价值,所以我选择直接删除掉所有的节假日和周末,节假日这个特征也去掉。再使用上面的模型试一试。
具体步骤和上面一致,只是删掉了节假日这个特征
- 将所有数据中,五和张衡路口的数据都读进来。
- 对每一个时间段,五和张衡路口各个方向的车流量进行求和
- (更改)将有缺失值的天数去掉,把所有节假日和周末都去掉,将5:00到21:00以内的数据保留,其他的扔掉
- 提取日期特征,将每一个日期都用星期几来表示,比如星期一就用0,星期日就用6.
- 将5:00到21:00做一个归一化,化成0到1的一个小数
- 提取是否加班的特征
- 对要预测的日期也提取日期特征,并把时间区间归一化。
- 对预测的日期提取是否加班的特征,自我感觉,2月11日第一天上班应该加班的少,2月14日不管加不加班,情人节晚上车流量肯定会增多,所以当成加班处理
score:69.8996
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
成绩有了一点提升,但不是很明显,所以有了下面更激进的做法。
3.5 我的模型v1.4(score:70.5664)
既然想到可以删除数据,我们要预测的是星期一和星期四,所以我又有了一次大胆的尝试,把除星期一和星期四以外的所有数据都删掉。最终只有5天的数据来进行训练。
- 将所有数据中,五和张衡路口的数据都读进来。
- 对每一个时间段,五和张衡路口各个方向的车流量进行求和
- (更改)将有缺失值的天数去掉,将除周一和周四以外的数据都去掉,将5:00到21:00以内的数据保留,其他的扔掉
- 提取日期特征,将每一个日期都用星期几来表示,比如星期一就用0,星期日就用6.
- 将5:00到21:00做一个归一化,化成0到1的一个小数
- 提取是否加班的特征
- 对要预测的日期也提取日期特征,并把时间区间归一化。
- 对预测的日期提取是否加班的特征,自我感觉,2月11日第一天上班应该加班的少,2月14日不管加不加班,情人节晚上车流量肯定会增多,所以当成加班处理
score:70.5664
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
果然,成绩又上升了一点。
3.6 我的模型v2.1(score:73.2325)
上面的模型几乎已经达到极限了,因为操作过于大胆,导致了上升空间已经不大,所以我开始了新思路的尝试。由于我们最终要预测是2月11日和2月14日,这两天的特征其实是不一样的。因为2月11日是放假回来上班的第一天,所以车流量吧应当不会提升太多,而2月14日又是情人节,就算白天影响不大,但是晚上的车流量应该会有所影响。所以我尝试了新的建模思路————建立两个模型来分别预测这两天的车流量。
因为2月11日的车流量比较小,所以考虑可能和过年前两天的数据差不多,所以我选择只使用过年前5天的数据来作为训练集,训练出来的模型去预测2月11日的情况。而对于2月14日,他的车流量应该会比2月11日更多,所以我使用了过年前一周的数据来作为训练集,训练出来的模型去预测2月14日。其他的步骤和之前的基本一致了。
- 将所有数据中,五和张衡路口的数据都读进来。
- 对每一个时间段,五和张衡路口各个方向的车流量进行求和
- 将有缺失值的天数去掉,将除周一和周四以外的数据都去掉,将5:00到21:00以内的数据保留,其他的扔掉
- (新增)把过年前五天的数据作为训练集1,过年前一周的数据作为训练集2
- 提取日期特征,将每一个日期都用星期几来表示,比如星期一就用0,星期日就用6.
- 将5:00到21:00做一个归一化,化成0到1的一个小数
- 提取是否加班的特征
- 对要预测的日期也提取日期特征,并把时间区间归一化。
- 对预测的日期提取是否加班的特征,自我感觉,2月11日第一天上班应该加班的少,2月14日不管加不加班,情人节晚上车流量肯定会增多,所以当成加班处理
- (新增)分别使用训练集1和训练集2训练处模型1和模型2,然后分别对2月11日和2月14日进行预测
score:73.2325
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
分数一下子提升了3分,看来确实对于2月11日和2月14日这两天的数据,是有一个明显的不同的。
3.7 我的模型v2.2(score:74.2096)
虽然考虑可以分开来训练模型,预测这两天的情况,但是对于2月14日的数据,依然觉得没有把这一天的特征都完全抓住。
偶然间百度看到csdn上的一个大佬写的帖子
https://blog.csdn.net/weixin_43945120/article/details/105868640
他找到了另一个赛题中同时间段深圳其他路口的车流量数据,并且这个时间段就有2月11日和2月14日,虽说路口不一样,但是整体的路况其实可以看出来大概的。所以根据大佬的可视化分析,我看到了2月14日的数据量其实和1月29日的数据非常像,也就是说这两天的车流量水平可能是差不多的。所以我马上进行了尝试,直接把1月29日的车流量作为2月14日的车流量提交上去。
最终得分:72.6425
分数还是变低了,然后我再仔细想了想,这个路口的情人节说不定车流量还会高一点,因为华为总部的附近就有一些商圈。所以我把1月29日的所有数据都乘了1.15倍,2月11日的数据保持和上边的模型一样不动,提交上去。
最终得分:74.2096
果然,成绩一下子又飞涨上去。虽然这种方式不是通过模型来进行预测的,但是这种基于规则的预测方式在很多地方其实还是很有用滴(应该不算作弊),哈哈哈。
3.7 我的模型v2.3(score:75.8)
又经过了几天的尝试,发现上一个模型的效果虽然有了较大提升,但是却失去了提升的空间,我使用上一个模型经过局部拉伸后,最高也只能达到75.4左右的成绩。所以又开始了新模型的尝试。
最终,我在我的模型v2.1的基础上,重新修改了训练集的划分,原本是使用过年前一周的数据来预测第2月14日,过年前5天的数据来预测2月11日。但是我发现预测出来的2月14日车流量明显低了,所以我想很有可能是因为过年前两天的车流量低,导致了最后的预测值也低了。所以我修改了一下训练集,依然是用过年前5天训练2月11日,然后用1月28日到2月1日这5天来训练2月14日,这样做以后,2月14日的车流量明显有了提升,而且成绩也有了不错的提升,达到了74.4695。然后我再借鉴了我的模型v2.2的技巧,把整个数据水平乘了一个系数,做一个拉伸,系数的确定是我根据前面的数据分析来猜测的。我对2月11日的结果乘了一个0.93,对于2月14日的数据乘了一个1.21,最终成绩一下子提升到了75.8。
- 将所有数据中,五和张衡路口的数据都读进来。
- 对每一个时间段,五和张衡路口各个方向的车流量进行求和
- 将有缺失值的天数去掉,将除周一和周四以外的数据都去掉,将5:00到21:00以内的数据保留,其他的扔掉
- 提取日期特征,将每一个日期都用星期几来表示,比如星期一就用0,星期日就用6.
- 将5:00到21:00做一个归一化,化成0到1的一个小数
- 提取是否加班的特征
- 对要预测的日期也提取日期特征,并把时间区间归一化。
- 对预测的日期提取是否加班的特征,自我感觉,2月11日第一天上班应该加班的少,2月14日不管加不加班,情人节晚上车流量肯定会增多,所以当成加班处理
-(修改)过年前5天训练2月11日,1月28日到2月1日这5天来训练2月14日,然后分别对2月11日和2月14日进行预测
score:75.8
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
3.8 我的模型v2.4(score:76.2)
对于上面的结果,我认为依然还可以进行调整,因为局部的拉伸可能对结果影响还是非常大的。所以我挑选了一些高峰期,比如早上,晚上,下午5点左右这些时刻,做了一个局部拉伸。我把2月11日的晚上数据乘了0.98,2月14日晚上的数据乘了1.02。看上去变化很小,结果让人比较吃惊,一下子涨到了76.2。接下来还可以把其他的高峰期的数据,做一些拉伸,最终成绩应该还会有提升。
3.9 我的模型v2.5(score:76.7581 第一名)
根据上面的推测,继续对高峰期做一个局部拉伸。我把2月11日和2月14日晚上(索引值为175到192)的数据,分别乘了0.96和0.12,然后再把傍晚时候(索引值为156到174)的数据,分别乘了1.04和0.98,最终分数达到了76.7581,拿到了第一名的成绩(当然这个拉伸的值是多次提交之后试出来的,所以也是有一定的运气成分)。
个人总结:本次热身赛虽然最终拿到了第一名,但这个题目个人感觉运气成分还是太大,前面的模型训练主要就是在拟合一天车流量的变化情况,来获得分数标准中的分类这一部分的分数。而后面对于预测结果的拉伸,则主要基于规则来提升回归这一部分的分数。本次热身赛的比赛过程,就分享到这里了。争取接下来的正赛做好一点,混个奖项。

