
- 1Spring Boot | Spring Boot “整合JPA“
- 2java面试100题(应届生必备)_java应届生面试题
- 3ubuntu/centos vim配置golang开发环境_ubuntu安装vim-go插件
- 4支持中文的Rasa NLU训练服务部署---Rasa_NLU_Chi_rasa训练中文模型
- 5为什么人工智能和Python要一起学?两者有何联系?_人工智能的底层是python吗
- 6CHATGLM3应用指南——本地部署_chatglm3-ggml-q4_0.bin 部署
- 7毕业设计:基于深度学习的电影推荐算法 -- 以豆瓣为例 大数据
- 8Elasticsearch:使用向量搜索来搜索图片及文字_elasticsearch 向量检索
- 9libsvm java 情感分类_自然语言处理系列篇——情感分类
- 10pytorch实战---IMDB情感分析_pytorch imdb
深度学习入门,计算机视觉,推荐系统,自然语言处理理论框架以及学习资料【附知识图谱与链接】_自然语言处理的技术和计算机视觉的技术的定义"的相关网址
赞
踩
理论应用
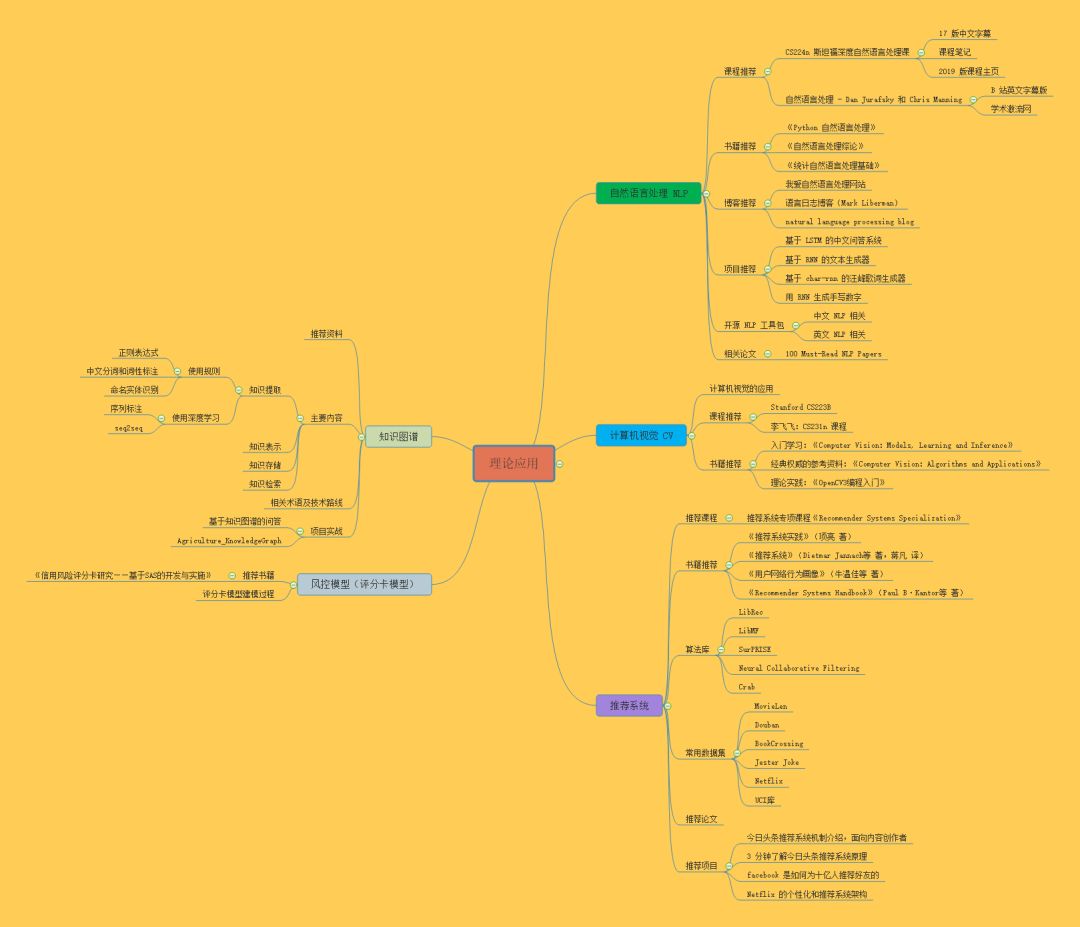
自然语言处理
1 NLP是什么
自然语言处理(NLP,Natural Language Processing)是研究计算机处理人类语言的一门技术,目的是弥补人类交流(自然语言)和计算机理解(机器语言)之间的差距。NLP包含句法语义分析、信息抽取、文本挖掘、机器翻译、信息检索、问答系统和对话系统等领域。
2 课程推荐
CS224n 斯坦福深度自然语言处理课
17版中文字幕:
https://www.bilibili.com/video/av41393758/?p=1
课程笔记:
http://www.hankcs.com/?s=CS224n%E7%AC%94%E8%AE%B0
2019版课程主页:
http://web.stanford.edu/class/cs224n/
自然语言处理 - Dan Jurafsky 和 Chris Manning
B站英文字幕版:
https://www.bilibili.com/video/av35805262/
学术激流网:
http://academictorrents.com/details/d2c8f8f1651740520b7dfab23438d89bc8c0c0ab
3 书籍推荐
Python自然语言处理
入门读物,整本书不仅涉及了语料库的操作,也对传统的基于规则的方法有所涉及。全书包括了分词(tokenization)、词性标注(POS)、语块(Chunk)标注、句法剖析与语义剖析等方面,是nlp中不错的一本实用教程。
自然语言处理综论
By Daniel Jurafsky和James H. Martin
本书十分权威,是经典的NLP教科书,涵盖了经典自然语言处理、统计自然语言处理、语音识别和计算语言学等方面。
统计自然语言处理基础
By Chris Manning和HinrichSchütze
更高级的统计NLP方法,在统计基本部分和n元语法部分介绍得都很不错。
4 博客推荐
我爱自然语言处理
地址:http://www.52nlp.cn/
TFIDF、文档相似度等等在这个网站上都有通俗易懂的解释
语言日志博客(Mark Liberman)
地址:
http://languagelog.ldc.upenn.edu/nll/
natural language processing blog
地址:https://nlpers.blogspot.com/
美国Hal Daumé III维护的一个natural language processing的 博客,经常评论最新学术动态,值得关注。有关于ACL、NAACL等学术会议的参会感想和对论文的点评
5 项目推荐
基于LSTM的中文问答系统
https://github.com/S-H-Y-GitHub/QA
基于RNN的文本生成器
https://github.com/karpathy/char-rnn
基于char-rnn的汪峰歌词生成器
https://github.com/phunterlau/wangfeng-rnn
用RNN生成手写数字
https://github.com/skaae/lasagne-draw
6 开源NLP工具包
中文NLP相关:https://github.com/crownpku/Awesome-Chinese-NLP
英文NLP相关:
NLTK: http://www.nltk.org/
TextBlob: http://textblob.readthedocs.org/en/dev/
Gensim: http://radimrehurek.com/gensim/
Pattern: http://www.clips.ua.ac.be/pattern
Spacy: http://spacy.io
Orange: http://orange.biolab.si/features/
Pineapple: https://github.com/proycon/pynlpl
7 相关论文
100 Must-Read NLP Papers
https://github.com/mhagiwara/100-nlp-papers
计算机视觉
1 计算机视觉的应用
计算机视觉的应用
无人驾驶
无人安防
人脸识别
车辆车牌识别
以图搜图
VR/AR
3D重构
无人机
医学图像分析
其他
2 课程推荐
Stanford CS223B
比较适合基础,适合刚刚入门的同学,跟深度学习的结合相对来说会少一点,不会整门课讲深度学习,而是主要讲计算机视觉,方方面面都会讲到
李飞飞:CS231n课程:
https://mp.weixin.qq.com/s/-NaDpXsxvu4DpXqVNXIAvQ
3 书籍推荐
1.入门学习:
《Computer Vision:Models, Learning and Inference》
2.经典权威的参考资料:
《Computer Vision:Algorithms and Applications》
3.理论实践:
《OpenCV3编程入门》
推荐系统
1 推荐系统是什么
推荐系统就是自动联系用户和物品的一种工具,它能够在信息过载的环境中帮助用户发现令他们感兴趣的信息,也能将信息推送给对它们感兴趣的用户。推荐系统属于资讯过滤的一种应用。
2 推荐课程
推荐系统专项课程**《Recommender Systems Specialization》**
这个系列由4门子课程和1门毕业项目课程组成,包括推荐系统导论,最近邻协同过滤,推荐系统评价,矩阵分解和高级技术等。
观看地址:
https://www.coursera.org/specializations/recommender-systems
3 书籍推荐
《推荐系统实践》(项亮 著)
《推荐系统》(Dietmar Jannach等 著,蒋凡 译)
《用户网络行为画像》(牛温佳等 著)
《Recommender Systems Handbook》(Paul B·Kantor等 著)
4 算法库
LibRec
LibRec是一个Java版本的覆盖了70余个各类型推荐算法的推荐系统开源算法库,由国内的推荐系统大牛郭贵冰创办,目前已更新到2.0版本,它有效地解决了评分预测和物品推荐两大关键的推荐问题。
项目地址: https://github.com/guoguibing/librec
官网地址: https://www.librec.net/
LibMF
C++版本开源推荐系统,主要实现了基于矩阵分解的推荐系统。针对SGD(随即梯度下降)优化方法在并行计算中存在的 locking problem 和 memory discontinuity问题,提出了一种 矩阵分解的高效算法FPSGD(Fast Parallel SGD),根据计算节点的个数来划分评分矩阵block,并分配计算节点。
项目地址:
http://www.csie.ntu.edu.tw/~cjlin/libmf/
SurPRISE
一个Python版本的开源推荐系统,有多种经典推荐算法
项目地址:http://surpriselib.com/
Neural Collaborative Filtering
神经协同过滤推荐算法的Python实现
项目地址:
https://github.com/hexiangnan/neural_collaborative_filtering
Crab
基于Python开发的开源推荐软件,其中实现有item和user的协同过滤
项目地址:http://muricoca.github.io/crab/
5 常用数据集
MovieLen
https://grouplens.org/datasets/movielens/
MovieLens数据集中,用户对自己看过的电影进行评分,分值为1~5。MovieLens包括两个不同大小的库,适用于不同规模的算法。小规模的库是943个独立用户对1 682部电影作的10 000次评分的数据;大规模的库是6 040个独立用户对3 900部电影作的大约100万次评分。适用于传统的推荐任务
Douban
https://www.cse.cuhk.edu.hk/irwin.king.new/pub/data/douban
Douban是豆瓣的匿名数据集,它包含了12万用户和5万条电影数据,是用户对电影的评分信息和用户间的社交信息,适用于社会化推荐任务。
BookCrossing
http://www2.informatik.uni-freiburg.de/~cziegler/BX/
这个数据集是网上的Book-Crossing图书社区的278858个用户对271379本书进行的评分,包括显式和隐式的评分。这些用户的年龄等人口统计学属性(demographic feature)都以匿名的形式保存并供分析。这个数据集是由Cai-Nicolas Ziegler使用爬虫程序在2004年从Book-Crossing图书社区上采集的。
6 推荐论文
经典必读论文整理,包括综述文章、传统经典推荐文章、社会化推荐文章、基于深度学习的推荐系统文章、专门用于解决冷启动的文章、POI相关的论文、利用哈希技术来加速推荐的文章以及推荐系统中经典的探索与利用问题的相关文章等。
项目地址:
https://github.com/hongleizhang/RSPapers
7 推荐项目
1.今日头条推荐系统机制介绍,面向内容创作者。分享人:项亮,今日头条推荐算法架构师:
https://v.qq.com/x/page/f0800qavik7.html?
- 3分钟了解今日头条推荐系统原理
https://v.qq.com/x/page/g05349lb80j.html?
3.facebook是如何为十亿人推荐好友的
https://code.facebook.com/posts/861999383875667/recommending-items-to-more-than-a-billion-people/
4.Netflix的个性化和推荐系统架构
http://techblog.netflix.com/2013/03/system-architectures-for.html
风控模型(评分卡模型)
1 评分卡模型简介
评分卡模型时在银行、互金等公司与借贷相关业务中最常见也是最重要的模型之一。简而言之它的作用就是对客户进行打分,来对客户是否优质进行评判。
根据评分卡模型应用的业务阶段不用,评分卡模型主要分为三大类:A卡(Application score card)申请评分卡、B卡(Behavior score card)行为评分卡、C卡(Collection score card)催收评分卡。其中申请评分卡用于贷前,行为评分卡用于贷中,催收评分卡用于贷后,这三种评分卡在我们的信贷业务的整个生命周期都至关重要。
2 推荐书籍
《信用风险评分卡研究——基于SAS的开发与实施》
3 评分卡模型建模过程
样本选取
确定训练样本、测试样本的观察窗(特征的时间跨度)与表现窗(标签的时间跨度),且样本的标签定义是什么?一般情况下风险评分卡的标签都是考虑客户某一段时间内的延滞情况。
特征准备
原始特征、衍生变量
数据清洗
根据业务需求对缺失值或异常值等进行处理
特征筛选
根据特征的IV值(特征对模型的贡献度)、PSI(特征的稳定性)来进行特征筛选,IV值越大越好(但是一个特征的IV值超过一定阈值可能要考虑是否用到未来数据),PSI越小越好(一般建模时取特征的PSI小于等于0.01)
对特征进行****WOE转换
即对特征进行分箱操作,注意在进行WOE转换时要注重特征的可解释性
建立模型
在建立模型过程中可根据模型和变量的统计量判断模型中包含和不包含每个变量时的模型质量来进行变量的二次筛选。
评分指标
评分卡模型一般关注的指标是KS值(衡量的是好坏样本累计分部之间的差值)、模型的PSI(即模型整体的稳定性)、AUC值等。
知识图谱
1 知识图谱是什么
知识图谱是一种结构化数据的处理方法,它涉及知识的提取、表示、存储、检索等一系列技术。从渊源上讲,它是知识表示与推理、数据库、信息检索、自然语言处理等多种技术发展的融合。
2 推荐资料
为什么需要知识图谱?什么是知识图谱?——KG的前世今生
https://zhuanlan.zhihu.com/p/31726910
什么是知识图谱?
https://zhuanlan.zhihu.com/p/34393554
智能搜索时代:知识图谱有何价值?
https://zhuanlan.zhihu.com/p/35982177?from=1084395010&wm=9848_0009&weiboauthoruid=5249689143
百度王海峰:知识图谱是 AI 的基石
http://www.infoq.com/cn/news/2017/11/Knowledge-map-cornerstone-AI#0-tsina-1-5001-397232819ff9a47a7b7e80a40613cfe1
译文|从知识抽取到RDF知识图谱可视化
http://rdc.hundsun.com/portal/article/907.html?hmsr=toutiao.io&utm_medium=toutiao.io&utm_source=toutiao.io
3 主要内容
3.1 知识提取
构建kg首先需要解决的是数据,知识提取是要解决结构化数据生成的问题。我们可以用自然语言处理的方法,也可以利用规则。
3.1.1 使用规则
正则表达式
正则表达式(Regular Expression, regex)是字符串处 理的基本功。数据爬取、数据清洗、实体提取、关系提取,都离不开regex。
推荐资料入门:
精通正则表达式
regexper 可视化:例 [a-z]*(\d{4}(\D+))
pythex 在线测试正则表达式:
http://pythex.org/
推荐资料进阶:
re2 :
Python wrapper for Google’s RE2 using Cython
https://pypi.python.org/pypi/re2/
Parsley :更人性化的正则表达语法
http://parsley.readthedocs.io/en/latest/tutorial.html
中文分词和词性标注
分词也是后续所有处理的基础,词性(Part of Speech, POS)就是中学大家学过的动词、名词、形容词等等的词的分类。一般的分词工具都会有词性标注的选项。
推荐资料入门:
jieba 中文分词包
https://github.com/fxsjy/jieba
中文词性标记集
https://github.com/memect/kg-beijing/wiki/
推荐资料进阶:
genius 采用 CRF条件随机场算法
https://github.com/duanhongyi/genius
Stanford CoreNLP分词
https://blog.csdn.net/guolindonggld/article/details/72795022
命名实体识别
命名实体识别(NER)是信息提取应用领域的重要基础工具,一般来说,命名实体识别的任务就是识别出待处理文本中三大类(实体类、时间类和数字类)、七小类(人名、机构名、地名、时间、日期、货币和百分比)命名实体。
推荐资料:
Stanford CoreNLP 进行中文命名实体识别
https://blog.csdn.net/guolindonggld/article/details/72795022
3.1.2 使用深度学习
使用自然语言处理的方法,一般是给定schema,从非结构化数据中抽取特定领域的三元组(spo),如最近百度举办的比赛就是使用DL模型进行信息抽取。
序列标注
使用序列生出模型,主要是标记出三元组中subject及object的起始位置,从而抽取信息。
推荐资料:
序列标注问题
https://www.cnblogs.com/jiangxinyang/p/9368482.html
seq2seq
使用seq2seq端到端的模型,主要借鉴文本摘要的思想,将三元组看成是非结构化文本的摘要,从而进行抽取,其中还涉及Attention机制。
推荐资料:
seq2seq详解
https://blog.csdn.net/irving_zhang/article/details/78889364
详解从Seq2Seq模型到Attention模型
https://caicai.science/2018/10/06/attention%E6%80%BB%E8%A7%88/
3.2 知识表示
知识表示(Knowledge Representation,KR,也译为知识表现)是研究如何将结构化数据组织,以便于机器处理和人的理解的方法。
需要熟悉下面内容:
JSON和YAML
json库:
https://docs.python.org/2/library/json.html
PyYAML: 是Python里的Yaml处理库
http://pyyaml.org/wiki/PyYAML
RDF和OWL语义:
http://blog.memect.cn/?p=871
JSON-LD
主页:http://json-ld.org/
3.3 知识存储
需要熟悉常见的图数据库
a.知识链接的方式:字符串、外键、URI
b.PostgreSQL及其JSON扩展
Psycopg包操作PostgreSQL
http://initd.org/psycopg/docs/
c.图数据库 Neo4j和OrientDB
1.Neo4j的Python接口 https://neo4j.com/developer/python/
2.OrientDB:http://orientdb.com/orientdb/
d.RDF数据库Stardog
Stardog官网:http://stardog.com/
3.4 知识检索
需要熟悉常见的检索技术
ElasticSearch教程:
http://joelabrahamsson.com/elasticsearch-101/
4 相关术语及技术路线
本体:
https://www.zhihu.com/question/19558514
RDF:
https://www.w3.org/RDF/
Apache Jena:
https://jena.apache.org/
D2RQ:
http://d2rq.org/getting-started
4.1 Protege构建本体系列
protege:
https://protege.stanford.edu/
protege使用:
https://zhuanlan.zhihu.com/p/32389370
4.2 开发语言
python或java
4.3 图数据库技术
Neo4j:https://neo4j.com/
AllegroGraph:https://franz.com/agraph/allegrograph/
4.4 可视化技术
d3.js:https://d3js.org/
Cytoscape.js:http://js.cytoscape.org/
4.5 分词技术
jieba:https://github.com/fxsjy/jieba
hanlp:https://github.com/hankcs/HanLP
5 项目实战
基于知识图谱的问答:
https://github.com/kangzhun/KnowledgeGraph-QA-Service
Agriculture_KnowledgeGraph:
https://github.com/qq547276542/Agriculture_KnowledgeGraph

