
- 1Java,PHP RSA加密解密,分段加解密及RSA签名_rsa2048签名长度
- 2开发安全之:file_get_contents()漏洞利用_file_get_contents漏洞
- 3NLP--词性标注(POS)、依存句法分析(DP)、语义依存分析(SDP)【实践】_否定词表 nlp
- 4VMware 17 Player下CentOS的安装与配置_vmware17虚拟机安装centos
- 5attention_mask,pad_token_id报错_the attention mask and the pad token id were not s
- 6python 安装cv2_python-opencv 人脸检测
- 7Spring详解,代码事例,IOC,AOP,事务。整合MyBatis,JUnit
- 8搭建 Langchain-Chatchat 详细过程
- 9中国信息化系统集成行业协会:预见2022:《2022年中国计算机系统集成行业全景图谱》部分①_2022年度全球计算机系统集成
- 10【无人机三维路径规划matlab仿真 】基于蜣螂优化算法DBO实现复杂山地地形无人机路径规划 论文实验报告皆可参考_无人机路径规划仿真
医学多模态模型总结(一)_pmc-vqa
赞
踩
概念
医学多模态大模型是指利用多种不同的医学数据源和模型,通过深度学习和人工智能技术,构建一个综合性的大型模型,以实现更加准确和全面的医学数据分析和预测。
这种模型可以同时处理多种医学数据类型,如医学图像、病历文本、基因测序数据等,从而更全面地揭示医学数据的内在规律和关联。通过对不同数据源的特征提取和分析,医学多模态大模型可以实现更准确的疾病诊断、治疗方案推荐、预后预测等任务。
例如,在疾病诊断方面,医学多模态大模型可以同时分析医学图像和病历数据,通过深度学习和特征提取技术,自动识别和分类疾病类型,提高诊断的准确性和效率。在治疗方案推荐方面,医学多模态大模型可以综合考虑患者的基因测序数据、病历信息、药物反应等多方面因素,为患者提供个性化的治疗方案。
医学多模态大模型的应用范围非常广泛,可以应用于医疗领域的多个方面,如医学图像分析、疾病预测与预防、个性化治疗等。随着人工智能技术的不断发展和应用,医学多模态大模型将会在更多的领域得到应用,为医学研究和医疗服务带来更多的便利和效益。
模型和方法
模型总结
| 模型名称 | base | 数据集 |
|---|---|---|
| Med-Flamingo | OpenFlamingo-9B | MTB PMC-OA Visual USMLE |
| MedVINT | MedVInT-TD,MedVInT-TE | PMC-VQA, |
| CLIP-ViT w/ GPT2 | CLIP GPT2-XL | |
| MUMC | ROCO 、MedICaT 和 ImageCLEF2022 SLAKE VQA-RAD PathVQA |
Med-Flamingo: a Multimodal Medical Few-shot Learner
贡献
- 我们提出了第一个适用于医学领域的多模态少样本学习器,它有望实现新颖的临床应用,例如基于检索到的多模态上下文的基本原理生成和调节。
- 我们创建了一个新颖的数据集,可以对一般医学领域的多模态少样本学习器进行预训练。
- 我们创建了一个新颖的 USMLE 式评估数据集,将医学 VQA 与复杂的跨专业医学推理相结合。
- 我们强调现有评估策略的缺点,并使用专用的评估应用程序与医疗评估员一起对开放式 VQA 世代进行深入的临床评估研究。
训练数据
提出了一个新的医学数据集,在OpenFlamingo-9B模型上进行训练,训练数据集包括MTB和PMC-OA,其中MTB是作者自己提出来的数据集,是从4721 本教科书构建了一个新的多模态数据集。
评估数据
后面又提出了一个评估数据集,创建了 Visual USMLE,这是一个具有挑战性的多模式问题集,包含 618 个 USMLE 风格的问题,这些问题不仅通过图像进行了增强,还通过案例插图和可能的实验室测量表进行了增强。 Visual USMLE 数据集是通过调整 Amboss 平台的问题(使用许可的用户访问)创建的。为了使可视化 USMLE 问题更具可操作性和实用性,我们将问题改写为开放式问题,而不是多项选择题。这使得基准测试变得更加困难和现实,因为模型必须完全自行提出鉴别诊断和潜在的程序,而不是从少数选择中选择最合理的答案。
USMLE风格主要强调临床医学知识、病人照护和医患关系的处理。它注重临床技能和实际操作能力,要求考生能够理解和应用医学知识,具备诊断、治疗和预防疾病的能力,并能够根据患者的不同需求和情况,提供合适的医疗服务和关怀。
USMLE考试分为三个阶段,每个阶段都包括笔试和面试。第一阶段主要考察基础医学知识,第二阶段主要考察临床医学知识,第三阶段主要考察专业医学知识和临床技能。
此外,USMLE还注重医学伦理和职业道德,要求考生具备高度的职业素养和道德标准,能够遵守医疗伦理和职业道德规范,尊重患者权益,维护医疗质量和安全。
总之,USMLE风格是一种注重临床实践、医学知识和医患关系处理的医学考试风格,旨在评估考生的医学知识和技能水平,以及他们的职业素养和道德标准。
评价指标
不再是使用普通的VQA的评价指标,提出了三个新的评价指标。
- 临床评估分数,由三名医生(包括一名委员会认证的放射科医生)使用我们为本研究开发的人类评估应用程序进行评分。第 4.2 节提供了更多详细信息。
- BERT相似度得分(BERT-sim),生成答案与正确答案之间的F1 BERT得分Zhang等人。
- 精确匹配,生成的答案中与正确答案完全匹配(模标点符号)的部分。该指标相当嘈杂且保守,因为有用的答案可能在词汇上与正确答案不匹配。
PMC-VQA: Visual Instruction Tuning for Medical Visual Question Answering
贡献
- 我们将 MedVQA 问题重新定义为生成学习任务,并提出 MedVInT,这是一种通过视觉指令调整将预训练的视觉编码器与大语言模型对齐而获得的模型;
- 我们引入了一个可扩展的流程,并构建了一个大规模的 MedVQA 数据集 PMC-VQA,该数据集的规模和多样性远远超过了现有数据集,涵盖了各种模式和疾病;
- 我们在 PMC-VQA 上对 MedVInT 进行预训练,并在 VQA-RAD [18] 和 SLAKE [23] 上对其进行微调,实现了最先进的性能并显着优于现有模型;
- 我们提出了一个新的测试集,并为 MedVQA 提出了更具挑战性的基准,以彻底评估 VQA 方法的性能。
训练数据
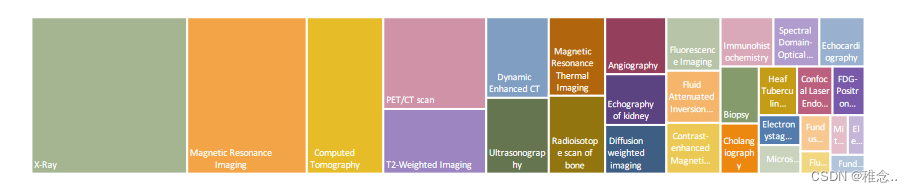
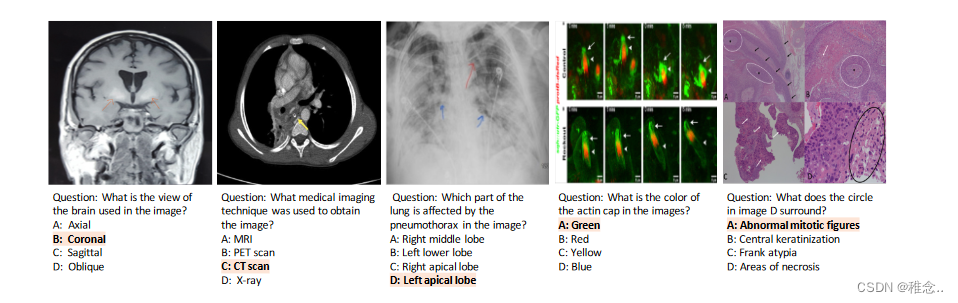

因为作者提出了一个新的数据集,所以训练过程中就是使用的这个数据集。该数据集包含 227k 个图像-问题对,上图 中给出了一些示例,它展示了我们数据集中图像的广泛多样性。如表 所示,PMC-VQA 在数据大小和模态多样性方面优于现有的 MedVQA 数据集。我们数据集中的问题涵盖了一系列困难,从识别图像模式、视角和器官等简单问题到需要专业知识和判断的挑战性问题。此外,我们的数据集包含一些难题,需要能够从复合图中识别特定的目标子图。
我们对 PMC-VQA 数据集的分析可以概括为三个方面:(i)图像:我们显示了 PMC-VQA 中排名前 20 的图形类型。PMC-VQA 中的图像极其多样化,从放射学到信号。 (ii) 问题:我们将问题分为不同的类别根据开始问题的单词来确定类型,我们发现了令人惊讶的各种问题类型,包括“有什么区别…”、“成像类型是什么…”和“哪种类型”图像显示…”。大多数问题的长度为 5 到 15 个单词,有关问题长度分布的详细信息在补充材料中显示。 (iii) 答案:答案中的词语主要包括位置描述、图像模式和特定解剖区域。大多数答案都在 5 个单词左右,比问题短得多。正确选项分布如下:A(24.07%)、B(30.87%)、C(29.09%)、D(15.97%)。
效果
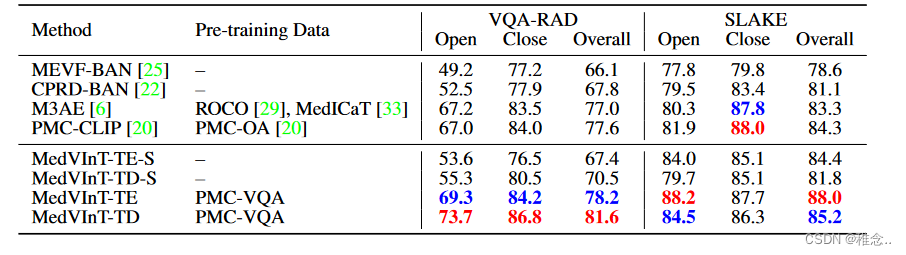
首先展示在之前的公开测试集中的效果
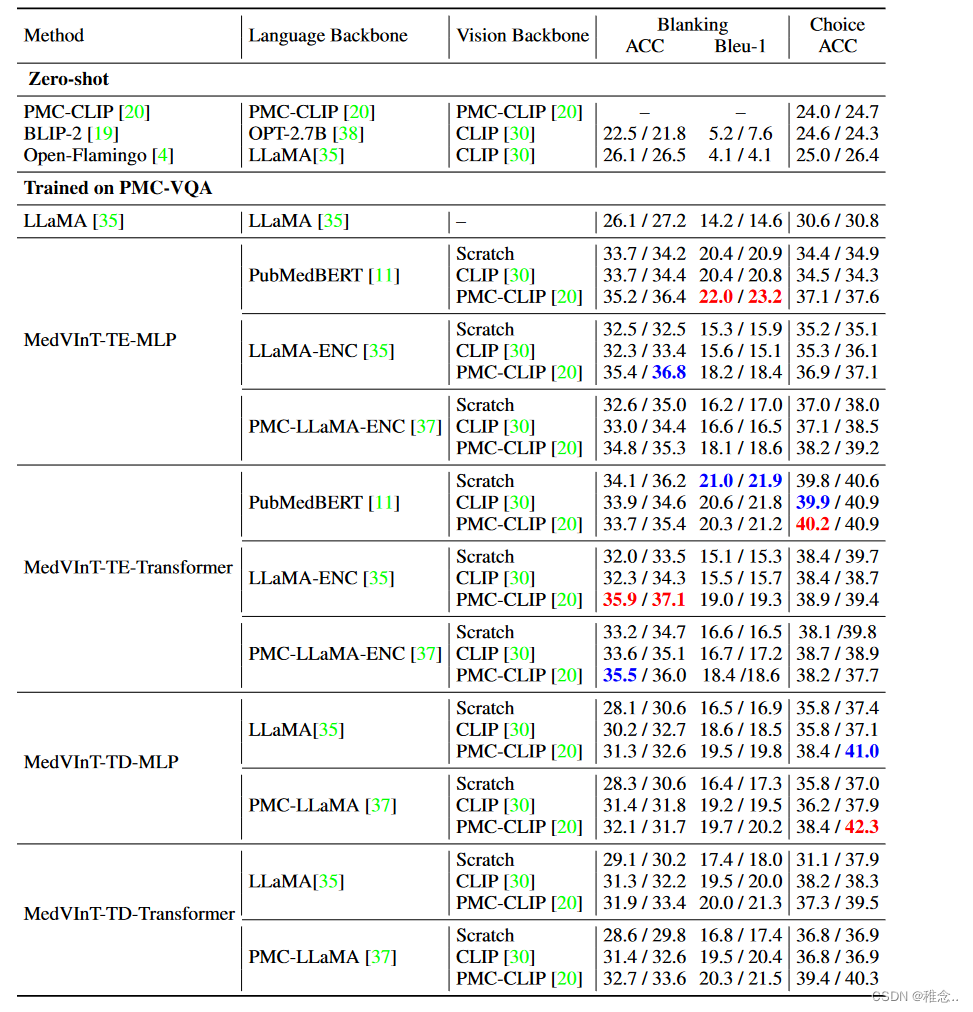
在新的数据集中的效果
Open-Ended Medical Visual Question Answering Through Prefix Tuning of Language Models
贡献
- (i)我们提出了第一个基于大规模语言模型的开放式医学 VQA 方法。
- (ii)我们对语言主干采用参数高效的调整策略,这使我们能够使用小数据集微调大型模型,而不会出现过度拟合的危险。
- (iii) 我们通过对相关基准进行大量实验证明,我们的模型无需大量计算资源即可产生强大的开放式 VQA 性能。
模型架构
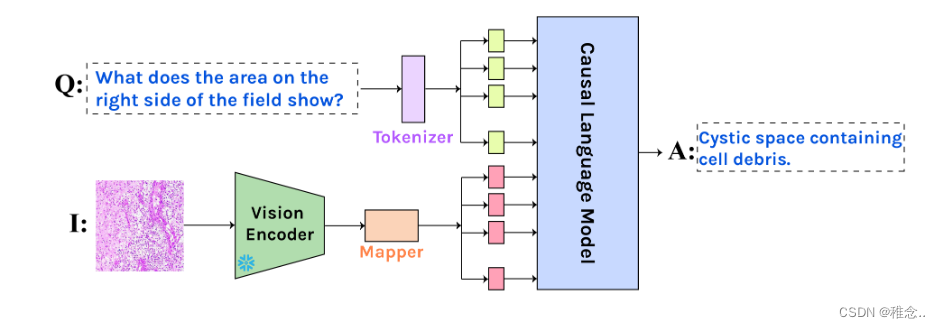
训练策略
由于医学问答数据集的数量较少,为小样本训练,为了实现具备良好的医学问答能力切不干扰模型的泛化能力,采用lora的形式进行训练,只更新LoRA的权重和连接器Mapper,这样训练的参数就大大减少。
实现细节我们使用具有 ViT 主干的预训练 CLIP 模型 [25] 提取视觉特征,维数为 512。映射网络 fM 的 MLP 层的大小为 {512, (lx·e)/2, lx· e}。 lx 的长度设置为 8。长度 lq 和 la 取决于数据集,并由训练集中标记的平均数量加上其标准差的三倍来定义。将零填充添加到序列的右侧以进行批量学习。我们使用以下语言模型:GPT2-XL [26],一种在 WebText [26] 上训练的具有 1.5B 参数的因果语言模型。 BioMedLM [31] 和 BioGPT [21] 都是基于 GPT2 的模型,在 PubMed 和来自 The Pile [8] 的生物医学数据上进行预训练,参数大小分别为 1.5B 和 2.7B。所有模型都能够在单个 NVIDIA RTX 2080ti GPU 上进行训练(平均训练时间约 3 小时)。我们使用 AdamW 优化器,具有 600 个预热步骤和 5e-3 的学习率,并应用容差为 3 的早期停止。
Masked Vision and Language Pre-training with Unimodal and Multimodal Contrastive Losses for Medical Visual Question Answering
贡献
- 我们提出了一种新的自监督视觉语言预训练(VLP)方法,该方法在预训练阶段应用带有单模态和多模态对比损失(MUMC)的蒙版图像和文本建模来解决下游医疗 VQA 任务。
- 我们工作中的单峰和多峰对比损失应用于(1)对齐图像和文本特征; (2)通过同一图像的不同视图的动量对比来学习单峰图像编码器(即不同的视图由不同的图像掩模生成); (3) 通过动量对比学习单峰文本编码器。我们还引入了一种新的屏蔽图像策略,以 25% 的概率随机屏蔽图像的补丁,作为数据增强技术来进一步增强模型的性能。
模型架构
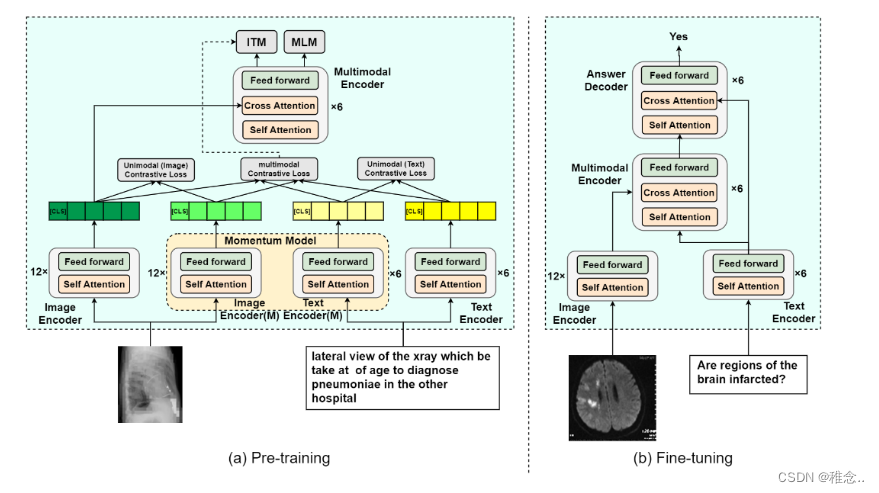
在预训练阶段,网络架构包括图像编码器、文本编码器和多模态编码器,它们都基于 Transformer 架构[15]。如图(a)所示,图像编码器利用12层视觉变换器(ViT)[16]从输入图像中提取视觉特征,而文本编码器采用6层变换器,该变换器由预训练 BERT 的前 6 层 [17]。 BERT 的最后 6 层被用作多模态编码器,并在每一层引入交叉注意力,融合了视觉和语言特征,以促进多模态交互的学习。该模型是在医学图像-标题对上进行训练的。将图像划分为大小为 16 × 16 的块,并随机屏蔽 25% 的块。剩余的未屏蔽图像块由图像编码器转换为嵌入序列。使用 WordPiece [18] 标记器将文本(即图像标题)标记为标记序列,并将其输入到基于 BERT 的文本编码器中。此外,特殊标记 [CLS] 被附加到图像和文本序列的开头。

