
热门标签
热门文章
- 1华为OD机试 - 文件缓存系统(Java & JS & Python & C++)_华为od文件缓存系统
- 2集线器 交换机 路由器介绍_集线器路由器交换机的作用和功能
- 3OCR入门教程系列(一):OCR基础导论_ocr文字识别
- 4多模态综述阅读总结
- 5北航计算机考研录取多少人,北航计算机考研近三年报考录取情况
- 6LLMs之ChatGLM:ChatGLM Efficient Tuning(一款高效微调ChatGLM-6B/ChatGLM2-6B的工具【LoRA/P-Tunin】)的简介、安装、使用方法之详细攻略_llama-efficient-tuning怎么训练
- 7GPT提示词工程的学习_gpt的题词工程
- 8通俗易懂理解CA(Coordinate Attention)_ca注意力机制
- 9【Python自然语言处理】文本向量化的六种常见模型讲解(独热编码、词袋模型、词频-逆文档频率模型、N元模型、单词-向量模型、文档-向量模型)_向量化模型
- 10QT 使用ffmpeg播放音视频文件/网络资源_qt通过ffmpeg 获取音视频的时长
当前位置: article > 正文
千言数据集:文本相似度——提取TFIDF以及统计特征,训练和预测_tfidf文本识别 模型训练
作者:IT小白 | 2024-04-07 18:42:20
赞
踩
tfidf文本识别 模型训练
以下学习笔记来源于 Coggle 30 Days of ML(22年1&2月)
链接:https://coggle.club/blog/30days-of-ml-202201
比赛链接:https://aistudio.baidu.com/aistudio/competition/detail/45/0/task-definition
提取TFIDF以及统计特征,训练和预测
导入所需库
import numpy as np
import pandas as pd
import jieba
import Levenshtein #计算编辑距离
from tqdm import tqdm
import warnings
import lightgbm as lgb
from sklearn.model_selection import StratifiedKFold
from sklearn.metrics import roc_auc_score, f1_score, precision_score, recall_score,accuracy_score
import glob
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
读取文件并做相应处理
#读取tsv文件的方法
def read_tsv(input_file,columns):
with open(input_file,"r",encoding="utf-8") as file:
lines = []
count = 1
for line in file:
if len(line.strip().split("\t")) != 1:
lines.append([count]+line.strip().split("\t"))
count += 1
df = pd.DataFrame(lines)
df.columns = columns
return df
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 读取训练数据
bq_train=read_tsv('./bq_corpus/train.tsv',['index','text1','text2','label'])
lcqmc_train=read_tsv('./lcqmc/train.tsv',['index','text1','text2','label'])
pawsx_train=read_tsv('./paws-x-zh/train.tsv',['index','text1','text2','label'])
- 1
- 2
- 3
- 读取预测数据
bq_test=read_tsv('./bq_corpus/test.tsv',['index','text1','text2'])
lcqmc_test=read_tsv('./lcqmc/test.tsv',['index','text1','text2'])
pawsx_test=read_tsv('./paws-x-zh/test.tsv',['index','text1','text2'])
- 1
- 2
- 3
- 一些处理文本的函数
#文本处理,有些可能用不到 import re import string import jieba with open("dict/stop_words.utf8",encoding="utf-8") as f: stopword_list=f.readlines() def tokenize_text(text): tokens=jieba.cut(text) tokens=[token.strip() for token in tokens] return tokens def remove_special_characters(text): tokens=tokenize_text(text) pattern=re.compile('[{}]'.format(re.escape(string.punctuation))) filtered_tokens=filter(None,[pattern.sub('',token) for token in tokens]) filtered_text=''.join(filtered_tokens) return filtered_text #去除停用词 def remove_stopwords(text): tokens=tokenize_text(text) filtered_tokens=[token for token in tokens if token not in stopword_list] filtered_text=''.join(filtered_tokens) return filtered_text def normalize_corpus(corpus,tokenize=False): normalize_corpus=[] for text in corpus: text=remove_special_characters(text) text=remove_stopwords(text) if tokenize: normalize_corpus.append(tokenize_text(text)) else: normalize_corpus.append(text) return normalize_corpus

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 将训练集文本作为语料库
df_train=pd.concat([bq_train,lcqmc_train,pawsx_train])
df_test=pd.concat([bq_test,lcqmc_test,pawsx_test])
corpus=df_train['text1'].values.tolist()+df_train['text2'].values.tolist()
tokenized_corpus=[' '.join(jieba.lcut(text)) for text in corpus]
- 1
- 2
- 3
- 4
统计特征
构建统计特征,包括:
句子A包含的字符个数、句子B包含的字符个数
句子A与句子B的编辑距离
句子A与句子B共有单词的个数
句子A与句子B共有字符的个数
句子A与句子B共有单词的个数 / 句子A字符个数
句子A与句子B共有单词的个数 / 句子B字符个数
#计算编辑距离,可以直接使用Levenshtein的distance计算 def edit_distance(text1,text2): n,m=len(text1),len(text2) import numpy as np dp=np.zeros((n+1,m+1)) for i in range(1,n+1): dp[i][0]=i for j in range(1,m+1): dp[0][j]=j for i in range(1,n+1): for j in range(1,m+1): tmp=int(text1[i-1]!=text2[j-1]) dp[i][j]=min(dp[i-1][j]+1,dp[i][j-1]+1,dp[i-1][j-1]+tmp) return dp[n][m] # 两个列表共有变量的个数 def both_num(list1,list2): dict1,dict2,ans={},{},0 for i in list1: dict1[i]=list1.count(i) for i in list2: dict2[i]=list2.count(i) for k,v in dict1.items(): tmp=0 if k not in list2 else dict2[k] ans+=min(v,tmp) return ans #text1和text2长度差 def len_diff(text1,text2): return abs(len(text1)-len(text2)) # text1和text2共有单词的个数 def both_words_num(text1,text2): a,b=jieba.lcut(text1),jieba.lcut(text2) return both_num(a,b) # text1和text2共有字符的个数 def both_chars_num(text1,text2): a,b=[i for i in text1],[i for i in text2] return both_num(a,b) #text1与text2共有单词的个数 / text1字符个数 def both_words_divideby_char1(text1,text2): return both_words_num(text1,text2)/len(text1) #text1与text2共有单词的个数 / text2字符个数 def both_words_divideby_char2(text1,text2): return both_words_num(text1,text2)/len(text2)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
提取TFIDF特征
计算TFIDF,并对句子A和句子B进行特征转换,计算句子A与句子B的TFIDF向量的内积距离
from sklearn.feature_extraction.text import TfidfVectorizer def tfidf_extractor(corpus,ngram_range=(1,1)): vectorizer=TfidfVectorizer(min_df=1, norm='l2', smooth_idf=True, use_idf=True, ngram_range=ngram_range) features=vectorizer.fit_transform(corpus) return vectorizer,features def participle_text(text): words_list=jieba.lcut(text) return ' '.join(words_list) #得到tfidf特征向量的内积距离 def get_tfidfvec_dis(tfidf_vectorizer,text1,text2): fit_text1=tfidf_vectorizer.transform([participle_text(text1)]) fit_text2=tfidf_vectorizer.transform([participle_text(text2)]) vec1=fit_text1.toarray()[0] vec2=fit_text2.toarray()[0] return np.dot(vec1,vec2) def tfidfvec_dis_list(tfidf_vectorizer,df): dis_list=[] for text1,text2 in zip(df['text1'],df['text2']): dis_list.append(get_tfidfvec_dis(tfidf_vectorizer,text1,text2)) return dis_list
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
tfidf_vectorizer,tfidf_train_features=tfidf_extractor(tokenized_corpus)
- 1
示例:

所有特征
def feature_eng(data):
"""
统计特征
"""
data['len_diff']=[len_diff(t1,t2) for t1,t2 in zip(data['text1'],data['text2'])]
data['both_words']=[both_words_num(t1,t2) for t1,t2 in zip(data['text1'],data['text2'])]
data['both_chars']=[both_chars_num(t1,t2) for t1,t2 in zip(data['text1'],data['text2'])]
data['both_words_div1']=[both_words_divideby_char1(t1,t2) for t1,t2 in zip(data['text1'],data['text2'])]
data['both_words_div2']=[both_words_divideby_char2(t1,t2) for t1,t2 in zip(data['text1'],data['text2'])]
data['tf_idf_dis']=tfidfvec_dis_list(tfidf_vectorizer,data)
data['edit_dis']=[Levenshtein.distance(t1,t2) for t1,t2 in zip(data['text1'],data['text2'])]
return data
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
df_train=feature_eng(df_train)
df_test=feature_eng(df_test)
- 1
- 2
处理完之后的样子:
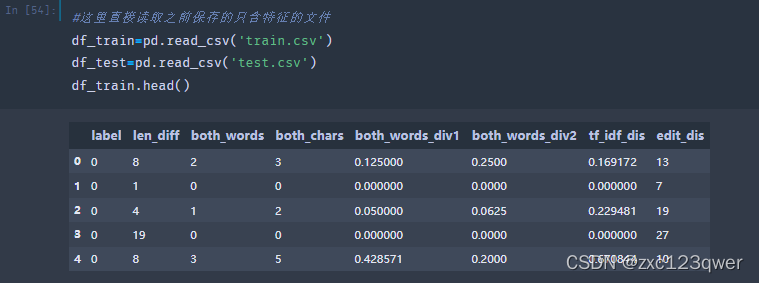
训练并预测
eval_fun = accuracy_score def run_oof(clf, X_train, y_train, X_test, kf): print(clf) preds_train = np.zeros((len(X_train), 2), dtype = np.float64) preds_test = np.zeros((len(X_test), 2), dtype = np.float64) train_loss = []; test_loss = [] i = 1 for train_index, test_index in kf.split(X_train, y_train): x_tr = X_train[train_index]; x_te = X_train[test_index] y_tr = y_train[train_index]; y_te = y_train[test_index] clf.fit(x_tr, y_tr, eval_set = [(x_te, y_te)], verbose = False) train_loss.append(eval_fun(y_tr, np.argmax(clf.predict_proba(x_tr)[:], 1))) test_loss.append(eval_fun(y_te, np.argmax(clf.predict_proba(x_te)[:], 1))) preds_train[test_index] = clf.predict_proba(x_te)[:] preds_test += clf.predict_proba(X_test)[:] print('{0}: Train {1:0.7f} Val {2:0.7f}/{3:0.7f}'.format(i, train_loss[-1], test_loss[-1], np.mean(test_loss))) print('-' * 50) i += 1 print('Train: ', train_loss) print('Val: ', test_loss) print('-' * 50) print('Train{0:0.5f}_Test{1:0.5f}\n\n'.format(np.mean(train_loss), np.mean(test_loss))) preds_test /= n_fold return preds_train, preds_test
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
params = { 'objective':'binary', 'boosting_type':'gbdt', 'metric':'auc', 'n_jobs':-1, 'learning_rate':0.05, 'num_leaves': 2**6, 'max_depth':8, 'tree_learner':'serial', 'colsample_bytree': 0.8, 'subsample_freq':1, 'subsample':0.8, 'num_boost_round':5000, 'max_bin':255, 'verbose':-1, 'seed': 2021, 'bagging_seed': 2021, 'feature_fraction_seed': 2021, 'early_stopping_rounds':100, } n_fold=10 skf = StratifiedKFold(n_splits = n_fold, shuffle = True) train_pred, test_pred = run_oof(lgb.LGBMClassifier(**params), df_train.iloc[:,1:].values, df_train.iloc[:,0].values, df_test.iloc[:,:].values, skf)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
训练过程:
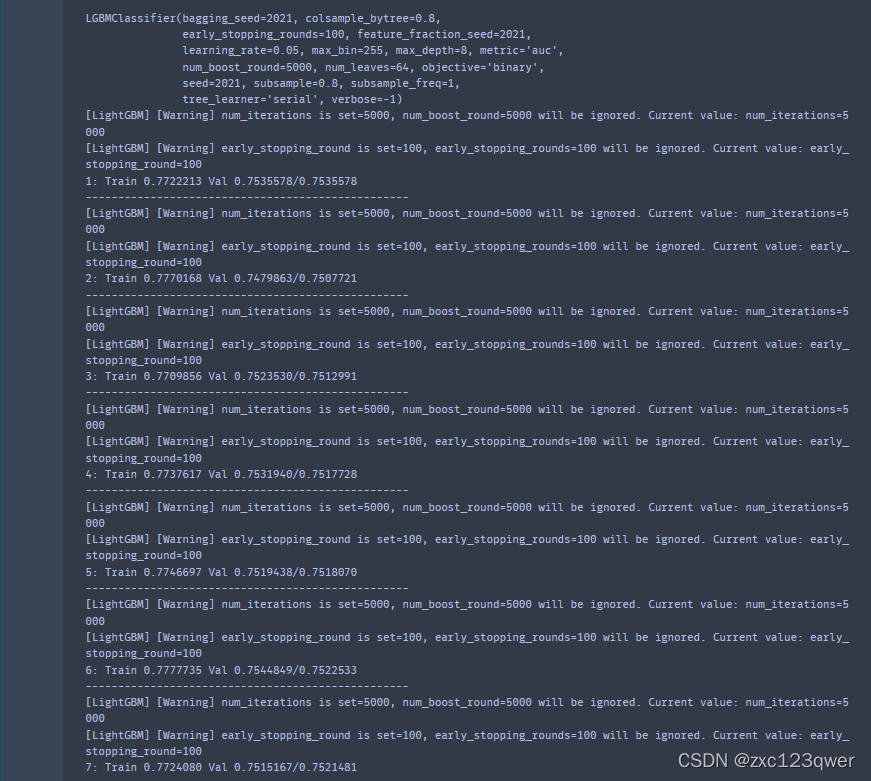
将结果保存到文件,并提交
df_test['prediction']=np.argmax(test_pred, 1)
bq_test['prediction']=df_test['prediction'][:len(bq_test)].tolist()
lcqmc_test['prediction']=df_test['prediction'][len(bq_test):len(bq_test)+len(lcqmc_test)].tolist()
pawsx_test['prediction']=df_test['prediction'][len(bq_test)+len(lcqmc_test):].tolist()
- 1
- 2
- 3
- 4
bq_test['index']=[i for i in range(len(bq_test))]
lcqmc_test['index']=[i for i in range(len(lcqmc_test))]
pawsx_test['index']=[i for i in range(len(pawsx_test))]
bq_test.to_csv('submit/bq_corpus.tsv', sep='\t',
index=False, columns=["index","prediction"], mode="w")
lcqmc_test.to_csv('submit/lcqmc.tsv', sep='\t',
index=False, columns=["index","prediction"], mode="w")
pawsx_test.to_csv('submit/paws-x.tsv', sep='\t',
index=False, columns=["index","prediction"], mode="w")
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10

0.6495的分数,再接再厉。
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/IT小白/article/detail/379940
推荐阅读
相关标签

